
5 分鐘完全掌握 Python 協(xié)程

1. 協(xié)程相關(guān)的概念
1.1 進(jìn)程和線程
進(jìn)程(Process)是應(yīng)用程序啟動的實(shí)例,擁有代碼、數(shù)據(jù)和文件和獨(dú)立的內(nèi)存空間,是操作系統(tǒng)最小資源管理單元。每個進(jìn)程下面有一個或者多個線程(Thread),來負(fù)責(zé)執(zhí)行程序的計算,是最小的執(zhí)行單元。
重點(diǎn)是:操作系統(tǒng)會負(fù)責(zé)進(jìn)程的資源的分配;控制權(quán)主要在操作系統(tǒng)。另一方面,線程做為任務(wù)的執(zhí)行單元,有新建、可運(yùn)行runnable(調(diào)用start方法,進(jìn)入調(diào)度池,等待獲取cpu使用權(quán))、運(yùn)行running(得到cpu使用權(quán)開始執(zhí)行程序) 阻塞blocked(放棄了cpu 使用權(quán),再次等待) 死亡dead5中不同的狀態(tài)。線程的轉(zhuǎn)態(tài)也是由操作系統(tǒng)進(jìn)行控制。線程如果存在資源共享的情況下,就需要加鎖,比如生產(chǎn)者和消費(fèi)者模式,生產(chǎn)者生產(chǎn)數(shù)據(jù)多共享隊列,消費(fèi)者從共享隊列中消費(fèi)數(shù)據(jù)。
線程和進(jìn)程在得到和放棄cpu使用權(quán)時,cpu使用權(quán)的切換都需損耗性能,因?yàn)槟硞€線程為了能夠在再次獲得cpu使用權(quán)時能繼續(xù)執(zhí)行任務(wù),必須記住上一次執(zhí)行的所有狀態(tài)。另外線程還有鎖的問題。
1.2 并行和并發(fā)
并行和并發(fā),聽起來都像是同時執(zhí)行不同的任務(wù)。但是這個同時的含義是不一樣的。
并行:多核CPU才有可能真正的同時執(zhí)行,就是獨(dú)立的資源來完成不同的任務(wù),沒有先后順序。 并發(fā)(concurrent):是看上去的同時執(zhí)行,實(shí)際微觀層面是順序執(zhí)行,是操作系統(tǒng)對進(jìn)程的調(diào)度以及cpu的快速上下文切換,每個進(jìn)程執(zhí)行一會然后停下來,cpu資源切換到另一個進(jìn)程,只是切換的時間很短,看起來是多個任務(wù)同時在執(zhí)行。要實(shí)現(xiàn)大并發(fā),需要把任務(wù)切成小的任務(wù)。
上面說的多核cpu可能同時執(zhí)行,這里的可能是和操作系統(tǒng)調(diào)度有關(guān),如果操作系統(tǒng)調(diào)度到同一個cpu,那就需要cpu進(jìn)行上下文切換。當(dāng)然多核情況下,操作系統(tǒng)調(diào)度會盡可能考慮不同cpu。
這里的上下文切換可以理解為需要保留不同執(zhí)行任務(wù)的狀態(tài)和數(shù)據(jù)。所有的并發(fā)處理都有排隊等候,喚醒,執(zhí)行至少三個這樣的步驟
1.3 協(xié)程
我們知道線程的提出是為了能夠在多核cpu的情況下,達(dá)到并行的目的。而且線程的執(zhí)行完全是操作系統(tǒng)控制的。而協(xié)程(Coroutine)是線程下的,控制權(quán)在于用戶,本質(zhì)是為了能讓多組過程能不獨(dú)自占用完所有資源,在一個線程內(nèi)交叉執(zhí)行,達(dá)到高并發(fā)的目的。
協(xié)程的優(yōu)勢:
協(xié)程最大的優(yōu)勢就是協(xié)程極高的執(zhí)行效率。因?yàn)樽映绦蚯袚Q不是線程切換,而是由程序自身控制,因此,沒有線程切換的開銷,和多線程比,線程數(shù)量越多,協(xié)程的性能優(yōu)勢就越明顯 第二大優(yōu)勢就是不需要多線程的鎖機(jī)制,因?yàn)橹挥幸粋€線程,也不存在同時寫變量沖突,在協(xié)程中控制共享資源不加鎖,只需要判斷狀態(tài)就好了,所以執(zhí)行效率比多線程高很多。
協(xié)程和線程區(qū)別:
協(xié)程都沒參與多核CPU并行處理,協(xié)程是不并行 線程在多核處理器上是并行在單核處理器是受操作系統(tǒng)調(diào)度的 協(xié)程需要保留上一次調(diào)用的狀態(tài) 線程的狀態(tài)有操作系統(tǒng)來控制
我們姑且也過一遍這些文字上的概念,show your code的時候再聯(lián)系起來,就會更清晰的。
2. python中的線程
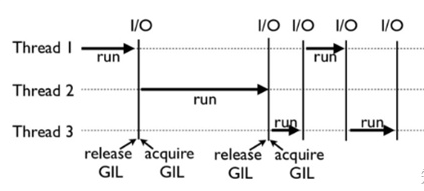
python中的線程由于歷史原因,即使在多核cpu的情況下并不能達(dá)真正的并行。這個原因就是全局解釋器鎖GIL(global interpreter lock),準(zhǔn)確的說GIL不是python的特性,而是cpython引入的一個概念。cpython解釋器在解析多線程時,會上GIL鎖,保證同一時刻只有一個線程獲取CPU使用權(quán)。
為什么需要GIL python中一切都是對象,Cpython中對象的回收,是通過對象的引用計數(shù)來判斷,當(dāng)對象的引用計數(shù)為0時,就會進(jìn)行垃圾回收,自動釋放內(nèi)存。但是如果多線程的情況,引用計數(shù)就變成了一個共享的變量 Cpython是當(dāng)下最流行的Python的解釋器,使用引用計數(shù)來管理內(nèi)存,在Python中,一切都是對象,引用計數(shù)就是指向?qū)ο蟮闹羔様?shù),當(dāng)這個數(shù)字變成0,則會進(jìn)行垃圾回收,自動釋放內(nèi)存。但是問題是Cpython是線程不安全的。
考慮下如果有兩個線程A和B同時引用一個對象obj,這個時候obj的引用計數(shù)為2;A打算撤銷對obj的引用,完成第一步時引用計數(shù)減去1時,這時發(fā)生了線程切換,A掛起等待,還沒執(zhí)行銷毀對象操作。B進(jìn)入運(yùn)行狀態(tài),這個時候B也對obj撤銷引用,并完成引用計數(shù)減1,銷毀對象,這個時候obj的引用數(shù)為0,釋放內(nèi)存。如果此時A重新喚醒,要繼續(xù)銷毀對象,可是這個時候已經(jīng)沒有對象了。所以為了保證不出現(xiàn)數(shù)據(jù)污染,才引入GIL。
每個線程使用前都會去獲取GIL權(quán)限,使用完釋放GIL權(quán)限。釋放線程的時機(jī)由python的另一個機(jī)制check_interval來決定。
在多核cpu時,因?yàn)樾枰@取和釋放GIL鎖,會存在性能上額外的損耗。特別是由于調(diào)度控制的原因,比如一個線程釋放了鎖,調(diào)度接著又分配cpu資源給同一個線程,該線程發(fā)起申請時,又重新獲得GIL,而其他線程實(shí)際上都在等待,白白浪費(fèi)了申請和釋放鎖的操作耗時。
python中的線程比較適合I/O密集型的操作(磁盤IO或者網(wǎng)絡(luò)IO)。
線程的使用
import?os
import?time
import?sys
from?concurrent?import?futures
def?to_do(info):??
????for?i?in?range(100000000):
????????pass
????return?info[0]
MAX_WORKERS?=?10
param_list?=?[]
for?i?in?range(5):
????param_list.append(('text%s'?%?i,?'info%s'?%?i))
workers?=?min(MAX_WORKERS,?len(param_list))
#?with?默認(rèn)會等所有任務(wù)都完成才返回,所以這里會阻塞
with?futures.ThreadPoolExecutor(workers)?as?executor:
????results?=?executor.map(to_do,?sorted(param_list))
#?打印所有
for?result?in?results:
????print(result)
#?非阻塞的方式,適合不需要返回結(jié)果的情況
workers?=?min(MAX_WORKERS,?len(param_list))
executor?=?futures.ThreadPoolExecutor(workers)
results?=?[]
for?idx,?param?in?enumerate(param_list):
????result?=?executor.submit(to_do,?param)
????results.append(result)
????print('result?%s'?%?idx)
#?手動等待所有任務(wù)完成
executor.shutdown()
print('='*10)
for?result?in?results:
????print(result.result())
3. python中的進(jìn)程
python提供的multiprocessing包來規(guī)避GIL的缺點(diǎn),實(shí)現(xiàn)在多核cpu上并行的目的。multiprocessing還提供進(jìn)程之間數(shù)據(jù)和內(nèi)存共享的機(jī)制。這里介紹的concurrent.futures的實(shí)現(xiàn)。用法和線程基本一樣,ThreadPoolExecutor改成ProcessPoolExecutor
import?os
import?time
import?sys
from?concurrent?import?futures
def?to_do(info):??
????for?i?in?range(10000000):
????????pass
????return?info[0]
start_time?=?time.time()
MAX_WORKERS?=?10
param_list?=?[]
for?i?in?range(5):
????param_list.append(('text%s'?%?i,?'info%s'?%?i))
workers?=?min(MAX_WORKERS,?len(param_list))
#?with?默認(rèn)會等所有任務(wù)都完成才返回,所以這里會阻塞
with?futures.ProcessPoolExecutor(workers)?as?executor:
????results?=?executor.map(to_do,?sorted(param_list))
????
#?打印所有
for?result?in?results:
????print(result)
print(time.time()-start_time)
#?耗時0.3704512119293213s,?而線程版本需要14.935384511947632s
4. python中的協(xié)程
4.1 簡單協(xié)程
我們先來看下python是怎么實(shí)現(xiàn)協(xié)程的。答案是yield。以下例子的功能是實(shí)現(xiàn)計算移動平均數(shù)
from?collections?import?namedtuple
Result?=?namedtuple('Result',?'count?average')
#?協(xié)程函數(shù)
def?averager():
????total?=?0.0
????count?=?0
????average?=?None
????while?True:
????????term?=?yield?None??#?暫停,等待主程序傳入數(shù)據(jù)喚醒
????????if?term?is?None:
????????????break??#?決定是否退出
????????total?+=?term
????????count?+=?1
????????average?=?total/count?#?累計狀態(tài),包括上一次的狀態(tài)
????return?Result(count,?average)
#?協(xié)程的觸發(fā)
coro_avg?=?averager()
#?預(yù)激活協(xié)程
next(coro_avg)
#?調(diào)用者給協(xié)程提供數(shù)據(jù)
coro_avg.send(10)
coro_avg.send(30)
coro_avg.send(6.5)
try:
????coro_avg.send(None)
except?StopIteration?as?exc:?#?執(zhí)行完成,會拋出StopIteration異常,返回值包含在異常的屬性value里
????result?=?exc.value
print(result)
yield關(guān)鍵字有兩個含義:產(chǎn)出和讓步; ?把yield的右邊的值產(chǎn)出給調(diào)用方,同時做出讓步,暫停執(zhí)行,讓程序繼續(xù)執(zhí)行。
上面的例子可知
協(xié)程用yield來控制流程,接收和產(chǎn)出數(shù)據(jù) next():預(yù)激活協(xié)程 send:協(xié)程從調(diào)用方接收數(shù)據(jù) StopIteration:控制協(xié)程結(jié)束, 同時獲取返回值
我們來回顧下1.3中協(xié)程的概念:本質(zhì)是為了能讓多組過程能不獨(dú)自占用完所有資源,在一個線程內(nèi)交叉執(zhí)行,達(dá)到高并發(fā)的目的。。上面的例子怎么解釋呢?
可以把一個協(xié)程單次一個任務(wù),即移動平均 每個任務(wù)可以拆分成小步驟(也可以說是子程序), 即每次算一個數(shù)的平均 如果多個任務(wù)需要執(zhí)行呢?怎么調(diào)用控制器在調(diào)用方 如果有10個,可以想象,調(diào)用在控制的時候隨機(jī)的給每個任務(wù)send的一個數(shù)據(jù)化,就會是多個任務(wù)在交叉執(zhí)行,達(dá)到并發(fā)的目的。
4.2 asyncio協(xié)程應(yīng)用包
asyncio即異步I/O, 如在高并發(fā)(如百萬并發(fā))網(wǎng)絡(luò)請求。異步I/O即你發(fā)起一個I/O操作不必等待執(zhí)行結(jié)束,可以做其他事情。asyncio底層是協(xié)程的方式來實(shí)現(xiàn)的。我們先來看一個例子,了解下asyncio的五臟六腑。
import?time
import?asyncio
now?=?lambda?:?time.time()
#?async定義協(xié)程
async?def?do_some_work(x):
????print("waiting:",x)
????#?await掛起阻塞,?相當(dāng)于yield,?通常是耗時操作
????await?asyncio.sleep(x)
????return?"Done?after?{}s".format(x)
#?回調(diào)函數(shù),和yield產(chǎn)出類似功能
def?callback(future):
????print("callback:",future.result())
start?=?now()
tasks?=?[]
for?i?in?range(1,?4):
????#?定義多個協(xié)程,同時預(yù)激活
????coroutine?=?do_some_work(i)
????task?=?asyncio.ensure_future(coroutine)
????task.add_done_callback(callback)
????tasks.append(task)
#?定一個循環(huán)事件列表,把任務(wù)協(xié)程放在里面,
loop?=?asyncio.get_event_loop()
try:
????#?異步執(zhí)行協(xié)程,直到所有操作都完成,?也可以通過asyncio.gather來收集多個任務(wù)
????loop.run_until_complete(asyncio.wait(tasks))
????for?task?in?tasks:
????????print("Task?ret:",task.result())
except?KeyboardInterrupt?as?e:?#?協(xié)程任務(wù)的狀態(tài)控制
????print(asyncio.Task.all_tasks())
????for?task?in?asyncio.Task.all_tasks():
????????print(task.cancel())
????loop.stop()
????loop.run_forever()
finally:
????loop.close()
print("Time:",?now()-start)
上面涉及到的幾個概念:
event_loop 事件循環(huán):程序開啟一個無限循環(huán),把一些函數(shù)注冊到事件循環(huán)上,當(dāng)滿足事件發(fā)生的時候,調(diào)用相應(yīng)的協(xié)程函數(shù) coroutine 協(xié)程:協(xié)程對象,指一個使用async關(guān)鍵字定義的函數(shù),它的調(diào)用不會立即執(zhí)行函數(shù),而是會返回一個協(xié)程對象。協(xié)程對象需要注冊到事件循環(huán),由事件循環(huán)調(diào)用。 task任務(wù):一個協(xié)程對象就是一個原生可以掛起的函數(shù),任務(wù)則是對協(xié)程進(jìn)一步封裝,其中包含了任務(wù)的各種狀態(tài) future: 代表將來執(zhí)行或沒有執(zhí)行的任務(wù)的結(jié)果。它和task上沒有本質(zhì)上的區(qū)別 async/await 關(guān)鍵字:python3.5用于定義協(xié)程的關(guān)鍵字,async定義一個協(xié)程,await用于掛起阻塞的異步調(diào)用接口。從上面可知, asyncio通過事件的方式幫我們實(shí)現(xiàn)了協(xié)程調(diào)用方的控制權(quán)處理,包括send給協(xié)程數(shù)據(jù)等。我們只要通過async定義協(xié)程,await定義阻塞,然后封裝成future的task,放入循環(huán)的事件列表中,就等著返回數(shù)據(jù)。
再來看一個http下載的例子,比如你想下載5個不同的url(同樣的,你想接收外部的百萬的請求)
import?time
import?asyncio
from?aiohttp?import?ClientSession
tasks?=?[]
url?=?"https://www.baidu.com/{}"
async?def?hello(url):
????async?with?ClientSession()?as?session:
????????async?with?session.get(url)?as?response:
????????????response?=?await?response.read()
#????????????print(response)
????????????print('Hello?World:%s'?%?time.time())
if?__name__?==?'__main__':
????loop?=?asyncio.get_event_loop()
????for?i?in?range(5):
????????task?=?asyncio.ensure_future(hello(url.format(i)))
????????tasks.append(task)
????loop.run_until_complete(asyncio.wait(tasks))
4.3 協(xié)程的應(yīng)用場景
支撐高并發(fā)I/O情況,如寫支撐高并發(fā)的服務(wù)端 代替線程,提供并發(fā)性能 tornado和gevent都實(shí)現(xiàn)了類似功能, 之前文章提到Twisted也是
5. 總結(jié)
本文分享關(guān)于python協(xié)程的概念和asyncio包的初步使用情況,同時也介紹了基本的相關(guān)概念,如進(jìn)程、線程、并發(fā)、并行等。希望對你有幫助,歡迎交流(@mintel)。簡要總結(jié)如下:
并發(fā)和并行不一樣,并行是同時執(zhí)行多個任務(wù), 并發(fā)是在極短時間內(nèi)處理多個任務(wù) 多核cpu,進(jìn)程是并行,python線程受制于GIL,不能并行,反而因?yàn)樯舷挛那袚Q更耗時,協(xié)程正好可以彌補(bǔ) 協(xié)程也不是并行,只是任務(wù)交替執(zhí)行任務(wù),在存在阻塞I/O情況,能夠異步執(zhí)行,提高效率 asyncio 異步I/O庫,可用于開發(fā)高并發(fā)應(yīng)用
作者簡介:wedo實(shí)驗(yàn)君, 數(shù)據(jù)分析師;熱愛生活,熱愛寫作
贊 賞 作 者

更多閱讀
特別推薦

點(diǎn)擊下方閱讀原文加入社區(qū)會員