
如何掌握好圖像分類算法?
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
大家好,這是專欄《AI有識(shí)境》的第一篇文章,講述如何掌握好圖像分類算法。
進(jìn)入到有識(shí)境界,可以大膽地說自己是一個(gè)非常合格的深度學(xué)習(xí)算法工程師了,能夠敏銳地把握自己研究的領(lǐng)域,跟蹤前沿和能落地的技術(shù),對(duì)自己暫時(shí)不熟悉的領(lǐng)域也能快速地觸類旁通。
作為第一篇文章,我們講解圖像分類需要掌握的重要知識(shí)點(diǎn)。本文將帶你走進(jìn)圖像分類的大門,著重關(guān)注該領(lǐng)域的研究方向以及重點(diǎn)難點(diǎn),講述如何學(xué)好圖像分類算法。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?作者&編輯 | 郭冰洋&言有三
1 簡(jiǎn)介
圖像分類,即給定計(jì)算機(jī)一張圖像,旨在讓其判斷出該圖像的所屬類別。它是計(jì)算機(jī)視覺領(lǐng)域的基礎(chǔ),更是重中之重。
近年來,隨著深度學(xué)習(xí)技術(shù)的興起,圖像分類領(lǐng)域得到了飛速的發(fā)展,并延申出一系列全新的研究方向,主要包括:
(1) 多類別圖像分類;
(2) 細(xì)粒度圖像分類;
(3) 多標(biāo)簽圖像分類;
(4) 無/半監(jiān)督圖像分類;
(5) 零樣本圖像分類;
對(duì)人類而言,由于有大量的先驗(yàn)知識(shí)和相關(guān)的學(xué)習(xí)經(jīng)驗(yàn),可以迅速識(shí)別圖像的相關(guān)內(nèi)容。然而,對(duì)于計(jì)算機(jī)而言,提取并識(shí)別其中的特征是有挑戰(zhàn)的。
目前存在的主要問題有:
(1) 遮擋:目標(biāo)物體被遮擋某一部分
(2) 多視角:每個(gè)物體的呈現(xiàn)視角是多樣的
(3) 光照條件:像素層級(jí)上而言,不同光照對(duì)識(shí)別的影響較大
(4) 樣本量較少:某些圖像的樣本難以獲取,導(dǎo)致樣本過少
(5) 類內(nèi)差異:某種類別下的物體差異性較大,比如桌椅等,呈現(xiàn)形式多樣,不具備統(tǒng)一的特征
(6) 類別不平衡:數(shù)據(jù)集不同類別的樣本數(shù)量差異較大
本文剩余部分將首先介紹分類任務(wù)的流程化處理,隨后著重介紹每個(gè)研究方向的發(fā)展進(jìn)程,并對(duì)其中難點(diǎn)問題的解決方法加以解讀。
2 經(jīng)典分類模型的發(fā)展簡(jiǎn)史
自深度學(xué)習(xí)發(fā)展以來,經(jīng)過數(shù)十年的研究,衍生出了無數(shù)經(jīng)典的分類模型。
在上個(gè)世紀(jì)90年代末本世紀(jì)初,經(jīng)典的手寫字體識(shí)別MNIST數(shù)據(jù)集,被SVM和KNN為代表的傳統(tǒng)算法統(tǒng)治,其錯(cuò)誤率約為0.56%。彼時(shí)仍然超過以神經(jīng)網(wǎng)絡(luò)為代表的方法,即LeNet系列網(wǎng)絡(luò)。LeNet[1]網(wǎng)絡(luò)誕生于1994年,后經(jīng)過多次的迭代才有了1998年的LeNet5,是為我們所廣泛知曉的版本。
作為早期的分類網(wǎng)絡(luò),LeNet包含了現(xiàn)有CNN的核心模塊。其中卷積層由卷積,池化,非線性激活函數(shù)構(gòu)成。從1998年至今,經(jīng)過20年的發(fā)展后,卷積神經(jīng)網(wǎng)絡(luò)依然遵循著這樣的設(shè)計(jì)思想。其中,卷積發(fā)展出了很多的變種,池化則逐漸被帶步長(zhǎng)的卷積完全替代,非線性激活函數(shù)更是演變出了很多的變種。
在本世紀(jì)的早期,神經(jīng)網(wǎng)絡(luò)開始有復(fù)蘇的跡象,但是受限于數(shù)據(jù)集的規(guī)模和硬件的發(fā)展,神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和優(yōu)化仍然是非常困難的。
后來在李飛飛等人數(shù)年時(shí)間的整理下,2009年,ImageNet數(shù)據(jù)集發(fā)布了,并且從2010年開始每年舉辦一次ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)賽,即ILSVRC。競(jìng)賽初期,仍以SVM和Boost等傳統(tǒng)算法為主,直到2012年AlexNet的橫空出世。
AlexNet[2]是第一個(gè)真正意義上的深度網(wǎng)絡(luò),與LeNet5的5層相比,它的層數(shù)增加了3層,網(wǎng)絡(luò)的參數(shù)量也大大增加,輸入也從28變成了224,同時(shí)GPU的面世,也使得深度學(xué)習(xí)從此進(jìn)行GPU為王的訓(xùn)練時(shí)代。
AlexNet在LeNet5的基礎(chǔ)上進(jìn)行改進(jìn),包括5個(gè)卷積層和3個(gè)全連接層。使用Relu激活函數(shù),收斂很快,解決了Sigmoid在網(wǎng)絡(luò)較深時(shí)出現(xiàn)的梯度彌散問題。同時(shí)加入了Dropout層,防止過擬合。此外,還使用了LRN歸一化層,對(duì)局部神經(jīng)元的活動(dòng)創(chuàng)建競(jìng)爭(zhēng)機(jī)制,抑制反饋較小的神經(jīng)元放大反應(yīng)大的神經(jīng)元,增強(qiáng)了模型的泛化能力。由于算力限制,AlexNet創(chuàng)新性的采用兩塊GPU分塊運(yùn)算,并通過全連接的層將兩個(gè)分支的結(jié)果進(jìn)行融合。
2014年的冠亞軍網(wǎng)絡(luò)分別是GoogLeNet[3]和VGGNet[4]。
其中VGGNet包括16層和19層兩個(gè)版本,共包含參數(shù)約為550M。全部使用3×3的卷積核和2×2的最大池化核,簡(jiǎn)化了卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)。VGGNet很好的展示了如何在先前網(wǎng)絡(luò)架構(gòu)的基礎(chǔ)上通過簡(jiǎn)單地增加網(wǎng)絡(luò)層數(shù)和深度就可以提高網(wǎng)絡(luò)的性能。雖然簡(jiǎn)單,但是卻異常的有效,在今天,VGGNet仍然被很多的任務(wù)選為基準(zhǔn)模型。
GoogLeNet是來自于Google的Christian Szegedy等人提出的22層的網(wǎng)絡(luò),其top-5分類錯(cuò)誤率只有6.7%。
GoogleNet的核心是Inception Module,它采用并行的方式。一個(gè)經(jīng)典的inception結(jié)構(gòu),包括有四個(gè)成分。1×1卷積,3×3卷積,5×5卷積,3×3最大池化,最后對(duì)四個(gè)成分運(yùn)算結(jié)果進(jìn)行通道上組合。這就是Inception Module的核心思想。通過多個(gè)卷積核提取圖像不同尺度的信息然后進(jìn)行融合,可以得到圖像更好的表征。自此,深度學(xué)習(xí)模型的分類準(zhǔn)確率已經(jīng)達(dá)到了人類的水平(5%~10%)。與VGGNet相比,GoogleNet模型架構(gòu)在精心設(shè)計(jì)的Inception結(jié)構(gòu)下,模型更深又更小,計(jì)算效率更高。
2015年,ResNet[5]獲得了分類任務(wù)冠軍。它以3.57%的錯(cuò)誤率表現(xiàn)超過了人類的識(shí)別水平,并以152層的網(wǎng)絡(luò)架構(gòu)創(chuàng)造了新的模型記錄。由于ResNet采用了跨層連接的方式,它成功的緩解了深層神經(jīng)網(wǎng)絡(luò)中的梯度消散問題,為上千層的網(wǎng)絡(luò)訓(xùn)練提供了可能。
在ResNet基礎(chǔ)上,密集連接的DenseNet[6]在前饋過程中將每一層與其他的層都連接起來。對(duì)于每一層網(wǎng)絡(luò)來說,前面所有網(wǎng)絡(luò)的特征圖都被作為輸入,同時(shí)其特征圖也都被后面的網(wǎng)絡(luò)層作為輸入所利用。
DenseNet中的密集連接還可以緩解梯度消失的問題,同時(shí)相比ResNet,可以更強(qiáng)化特征傳播和特征的復(fù)用,并減少了參數(shù)的數(shù)目。DenseNet相較于ResNet所需的內(nèi)存和計(jì)算資源更少,并達(dá)到更好的性能。
2017年,也是ILSVRC圖像分類比賽的最后一年,SeNet[7]獲得了冠軍。這個(gè)結(jié)構(gòu),僅僅使用了注意力機(jī)制對(duì)特征進(jìn)行處理,通過學(xué)習(xí)獲取每個(gè)特征通道的重要程度,根據(jù)重要性去降低或者提升相應(yīng)的特征通道的權(quán)重。
至此,圖像分類的比賽基本落幕,也接近算法的極限。但是,在實(shí)際的應(yīng)用中,卻面臨著比比賽中更加復(fù)雜和現(xiàn)實(shí)的問題,需要大家不斷積累經(jīng)驗(yàn)。
3 如何完成一個(gè)圖像分類任務(wù)
3.1? 構(gòu)建流程化處理模式
初學(xué)者在入門階段,需要構(gòu)建流程化處理的思維模式,將一個(gè)完整的任務(wù)進(jìn)行拆解,并對(duì)其中的各個(gè)流程加以掌握。一個(gè)完整的圖像分類任務(wù),包括以下幾個(gè)流程:
(1) 選擇開源學(xué)習(xí)框架
本流程需要掌握主流的深度學(xué)習(xí)框架,常見的包括Tensorflow、Pytorch、Mxnet等。此外,還需要掌握Linux開發(fā)指令以及相應(yīng)的編程技巧。
(2) 構(gòu)建數(shù)據(jù)集并讀取數(shù)據(jù)
圖像分類作為數(shù)據(jù)驅(qū)動(dòng)的任務(wù),高質(zhì)量的數(shù)據(jù)集是準(zhǔn)確率的保證。因此,在明確任務(wù)需求的初期,就需要著手構(gòu)建內(nèi)容清晰、符合實(shí)際的數(shù)據(jù)集,并將其劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。此外,還要根據(jù)數(shù)據(jù)集的格式,結(jié)合不同的學(xué)習(xí)框架,完成對(duì)數(shù)據(jù)集的讀取,保證每張圖片以張量的形式,送入訓(xùn)練網(wǎng)絡(luò)。
(3) 網(wǎng)絡(luò)模型選擇
在選擇訓(xùn)練網(wǎng)絡(luò)時(shí),需要根據(jù)現(xiàn)有的研究?jī)?nèi)容和成果進(jìn)行篩選。在選定的基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)上進(jìn)行實(shí)驗(yàn)和改進(jìn),進(jìn)一步提升網(wǎng)絡(luò)的性能。
(4) 訓(xùn)練及參數(shù)調(diào)試
選擇合適的學(xué)習(xí)率、優(yōu)化方式、損失函數(shù)進(jìn)行訓(xùn)練,并可以借助不同的數(shù)據(jù)增強(qiáng)方式,進(jìn)一步提升模型對(duì)數(shù)據(jù)的敏感力。參數(shù)的選擇是否合適,可以通過訓(xùn)練集和驗(yàn)證集的結(jié)果對(duì)比進(jìn)行調(diào)試。
(5) 測(cè)試
在測(cè)試集上達(dá)到精度要求后,對(duì)模型完成進(jìn)一步的部署。
3.2? 進(jìn)一步提高分類任務(wù)的質(zhì)量
分類精度的提高主要可以從數(shù)據(jù)集、網(wǎng)絡(luò)結(jié)構(gòu)和調(diào)參三個(gè)方面入手。
(1) 數(shù)據(jù)集:質(zhì)量高、目標(biāo)清晰
(2) 網(wǎng)絡(luò)結(jié)構(gòu):根據(jù)不同任務(wù)進(jìn)行針對(duì)性的選擇,務(wù)必根據(jù)現(xiàn)有的研究選取合適的結(jié)構(gòu),不可以盲目猜想
(3) 調(diào)參:針對(duì)任務(wù)需求選擇合適的損失函數(shù),并選擇合適的學(xué)習(xí)率和優(yōu)化方式
4 分類損失函數(shù)
作為網(wǎng)絡(luò)模型的優(yōu)化目標(biāo),合理的損失函數(shù)可以提高最終的準(zhǔn)確率。常見的分類損失函數(shù)主要包括0-1損失函數(shù)、交叉熵?fù)p失函數(shù)等等。
0-1損失函數(shù):計(jì)算n個(gè)樣本上的0-1分類損失的和或者平均值。
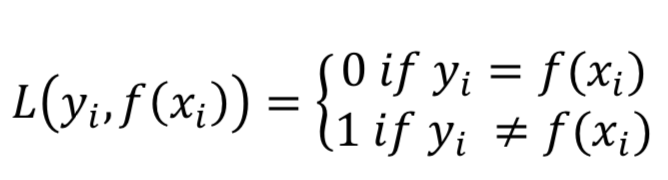
交叉熵?fù)p失函數(shù):圖像分類任務(wù)中最常用的損失函數(shù),定義在概率分布基礎(chǔ)上的,通常用來度量分類器的預(yù)測(cè)輸出的概率分布與真實(shí)分布的差異,令n對(duì)應(yīng)于樣本數(shù)量,m是類別數(shù)量,yij 表示第i個(gè)樣本屬于分類j的標(biāo)簽,它是0或者1,f(xij)是預(yù)測(cè)第i個(gè)樣本屬于分類j的概率。
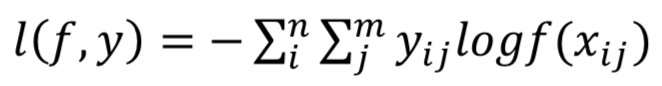
Hinge損失函數(shù):計(jì)算模型與數(shù)據(jù)之間的平均距離,是一個(gè)僅僅考慮了預(yù)測(cè)誤差的單邊度量。通常被用于最大間隔分類器。
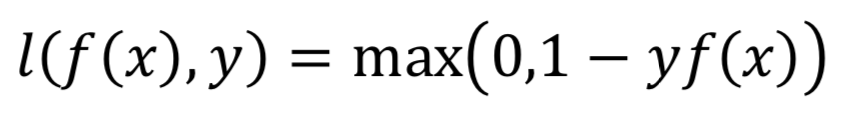
多標(biāo)簽分類任務(wù)函數(shù):多標(biāo)簽分類任務(wù)與單分類任務(wù)不同,每一張圖像可能屬于多個(gè)類別,因此需要預(yù)測(cè)樣本屬于每一類的概率值,sigmoid cross_entropy_loss通常被用于多標(biāo)簽分類任務(wù),單個(gè)樣本的損失定義如下:
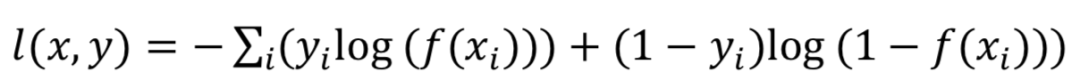
漢明距離損失函數(shù):將預(yù)測(cè)的標(biāo)簽集合與實(shí)際的標(biāo)簽集合進(jìn)行對(duì)比,按照漢明距離的相似度來衡量。漢明距離的相似度越高,即漢明損失函數(shù)越小,則模型的準(zhǔn)確率越高,也常用于多標(biāo)簽分類任務(wù),?Y表示距離。
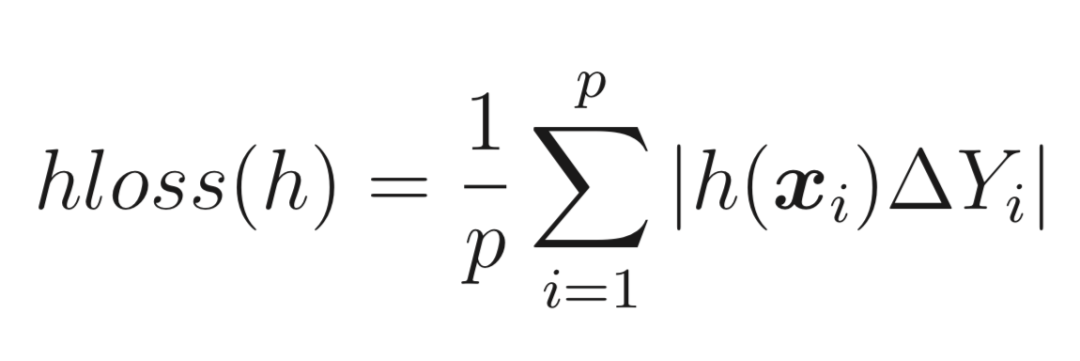
5 圖像分類的不同研究方向
5.1? 多類別圖像分類

多類別圖像分類作為圖像分類的最基礎(chǔ)研究,其目的是將若干不相關(guān)類別的圖像進(jìn)行分類。隨著深度學(xué)習(xí)的發(fā)展,已經(jīng)由原有的特征提取方式,轉(zhuǎn)化為數(shù)據(jù)驅(qū)動(dòng)的深度學(xué)習(xí)方式,并得到了極大的發(fā)展。現(xiàn)有的經(jīng)典網(wǎng)絡(luò),如VGG、ResNet、SENet等均是在此基礎(chǔ)上研究而來。對(duì)于該方向的研究,筆者建議對(duì)經(jīng)典文章進(jìn)行精讀,并掌握其中經(jīng)典結(jié)構(gòu)的設(shè)計(jì)思想。
5.2? 細(xì)粒度圖像分類

細(xì)粒度分類即在區(qū)分出基本類別的基礎(chǔ)上,進(jìn)行更精細(xì)的子類劃分,如貓的品種、車的品牌等等。相較于多類別圖像分類,細(xì)粒度圖像具有更加相似的外觀和特征,導(dǎo)致數(shù)據(jù)間的類內(nèi)差異較大,分類難度也更高。
現(xiàn)有的解決方案主要包括線性網(wǎng)絡(luò)結(jié)構(gòu)、額外標(biāo)注信息和注意力機(jī)制。
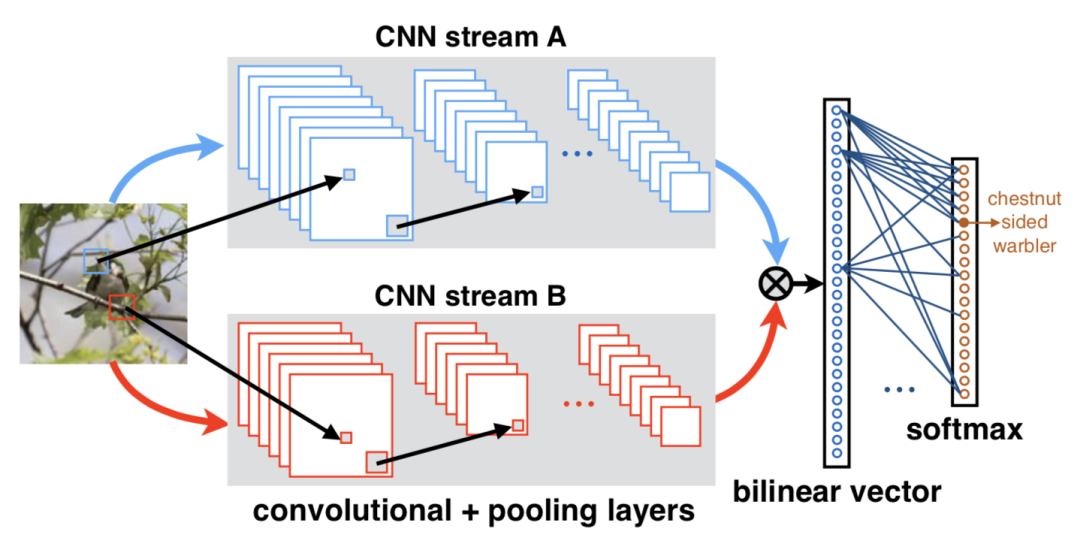
Lin等[8]提出了雙線性卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)(Bilinear CNN),通過不同的分支提取到兩個(gè)特征向量,如KxN和KxM,通過池化函數(shù)將兩個(gè)特征匯聚成MxN的特征向量,即包含了圖像的特征信息和位置信息,達(dá)到互補(bǔ)的目的。
還有的方法通過引入bounding box和key point等額外的人工標(biāo)注信息,通過R-CNN提取相關(guān)的區(qū)域信息,對(duì)其進(jìn)行特征修正,送入相應(yīng)的分類器進(jìn)行訓(xùn)練。
還有的方法通過引入視覺注意力機(jī)制(Vision Attention Mechanism),在CNN內(nèi)部嵌入注意力模塊,定位圖像中有區(qū)分性的區(qū)域,無需引入額外的標(biāo)注信息。
詳細(xì)了解細(xì)粒度分類,請(qǐng)閱讀:【圖像分類】細(xì)粒度圖像分類是什么,有什么方法,發(fā)展的怎么樣
5.3? 無監(jiān)督/半監(jiān)督圖像分類
顧名思義,不借助類別標(biāo)簽或只借助部分類別標(biāo)簽對(duì)圖像完成分類,屬于圖像分類中較難的任務(wù)類型,現(xiàn)階段的解決方案大都是傳統(tǒng)聚類算法與深度學(xué)習(xí)的融合。
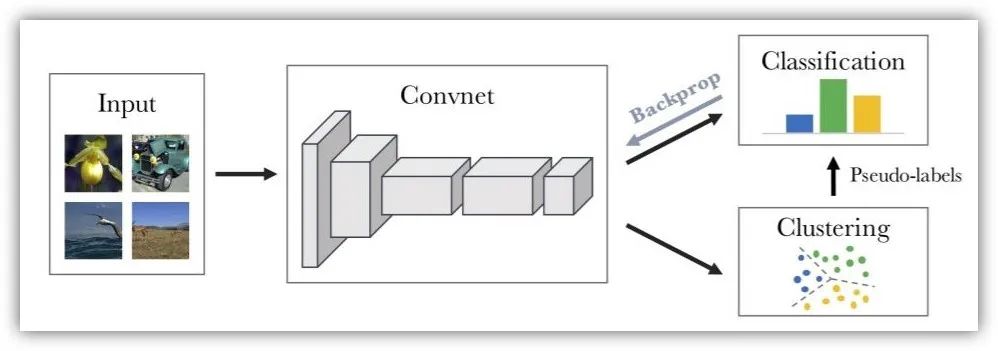
Deep Clustering[9]通過CNN提取圖像的特征信息,然后通過K-means算法對(duì)特征進(jìn)行聚類,并賦予相應(yīng)的偽標(biāo)簽,再用偽標(biāo)簽進(jìn)行相應(yīng)的分類訓(xùn)練。

牛津大學(xué)構(gòu)建了信息不變性聚類網(wǎng)絡(luò)(Invariant Information Clustering CNN)[10],將原有的圖像進(jìn)行平移、旋轉(zhuǎn)得到新的圖像,原有圖像和新圖像輸入同一CNN,獲得的特征信息相匹配的,則聚合為一類。
詳細(xì)了解無監(jiān)督分類,請(qǐng)閱讀:【圖像分類】簡(jiǎn)述無監(jiān)督圖像分類發(fā)展現(xiàn)狀
5.4? 多標(biāo)簽圖像分類
現(xiàn)實(shí)生活中的圖像往往包含多個(gè)目標(biāo),并非只包含單一種類的物體。針對(duì)此問題,多標(biāo)簽分類應(yīng)運(yùn)而生。其需要對(duì)含有多個(gè)目標(biāo)的圖像進(jìn)行分類,準(zhǔn)確識(shí)別出多個(gè)類別。常見的解決方案主要包括以下幾點(diǎn):
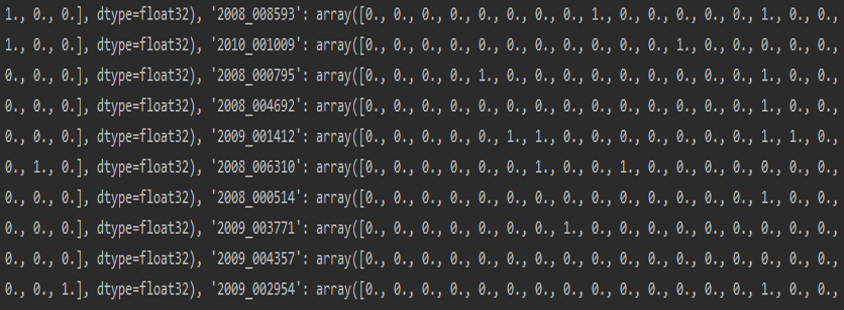
標(biāo)簽轉(zhuǎn)化:假定多標(biāo)簽分類任務(wù)中共有N個(gè)標(biāo)簽,則針對(duì)每張圖片,將其標(biāo)簽轉(zhuǎn)化為Nx1的向量,如[1,1,0,…,1,0],同時(shí)使用漢明距離作為損失函數(shù),這一方法簡(jiǎn)單便捷,只需要在標(biāo)簽格式上進(jìn)行處理。
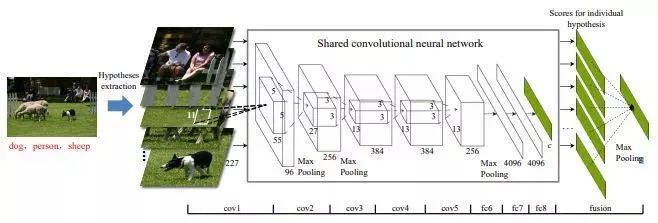
原圖拆分:根據(jù)BING理論將圖像生成若干含有標(biāo)簽的區(qū)域圖像,將區(qū)域圖像送入單標(biāo)簽分類網(wǎng)絡(luò)得到分類結(jié)果,隨后將每個(gè)區(qū)域圖像的結(jié)果進(jìn)行融合得到最終結(jié)果。
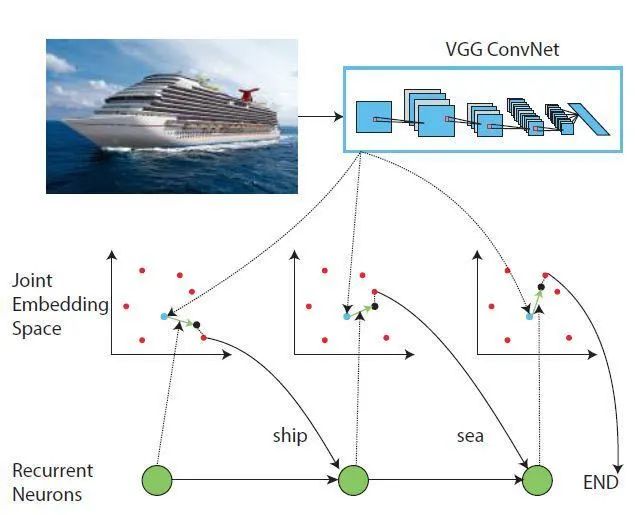
添加詞向量:通過添加一定的詞向量對(duì)不同的類別進(jìn)行描述,首先利用CNN對(duì)圖像進(jìn)行特征提取,隨后利用RNN構(gòu)建圖像特征與詞向量之間的關(guān)系,可以充分考慮類別之間的相關(guān)性。
詳細(xì)了解多標(biāo)簽分類,請(qǐng)閱讀:【技術(shù)綜述】多標(biāo)簽圖像分類綜述
5.5? 零樣本圖像分類

在傳統(tǒng)的分類模型中,為了解決多分類問題(例如三個(gè)類別:貓、狗和豬),就需要提供大量的貓、狗和豬的圖片用以模型訓(xùn)練,然后給定一張新的圖片,就能判定屬于貓、狗或豬的其中哪一類。但是對(duì)于之前訓(xùn)練圖片未出現(xiàn)的類別(例如牛),這個(gè)模型便無法將牛識(shí)別出來,而零樣本分類就是為了解決這種問題。在零樣本分類中,某一類別在訓(xùn)練樣本中未出現(xiàn),但是我們知道這個(gè)類別的特征,然后通過語料知識(shí)庫,便可以將這個(gè)類別識(shí)別出來。
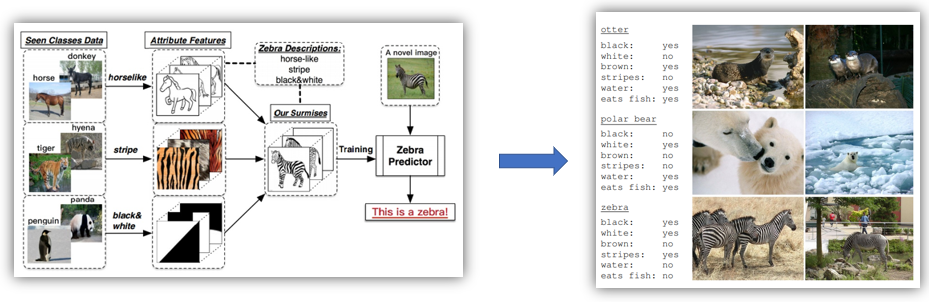
利用若干學(xué)習(xí)器去學(xué)習(xí)斑馬的相關(guān)特征,隨后輸入斑馬的圖片。如果此時(shí)我有一張表,這張表里記錄著每一種動(dòng)物這三種屬性的取值,我們就可以通過查表的方式,將這張圖片對(duì)應(yīng)到斑馬這一類別這里的屬性表。相關(guān)屬性表是事先總結(jié)好的,因?yàn)槭占罅康奈粗悇e的圖片是困難的,但是僅僅總結(jié)每一類別相應(yīng)的屬性卻是可行的。
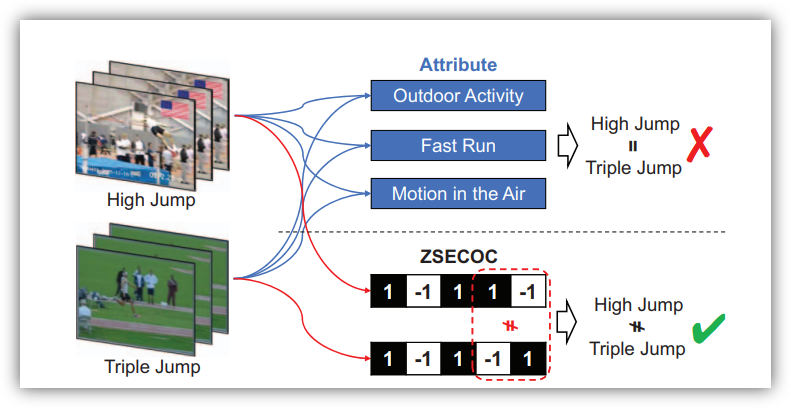
通過構(gòu)建詞向量(word2vec)的方式,將自然語言中的字詞轉(zhuǎn)化為計(jì)算機(jī)可以理解的數(shù)字向量,結(jié)合圖像和相應(yīng)的詞向量訓(xùn)練學(xué)習(xí)器。在測(cè)試階段,輸入測(cè)試的圖像,輸入預(yù)測(cè)的詞向量,從而得到預(yù)測(cè)結(jié)果與相應(yīng)類別的距離,距離最近的則為所屬類別。
6?如何解決類別不平衡
構(gòu)建數(shù)據(jù)集時(shí),不同類別下的樣本數(shù)目相差過大,從而導(dǎo)致分類模型的性能變差。現(xiàn)有的解決方案包括以下幾類:
優(yōu)化目標(biāo)設(shè)計(jì)法:優(yōu)化目標(biāo)設(shè)計(jì)主要是通過修改損失和函數(shù)對(duì)不同類別進(jìn)行不同的加權(quán)或者歸一化處理,比如在交叉熵中添加類別權(quán)重。
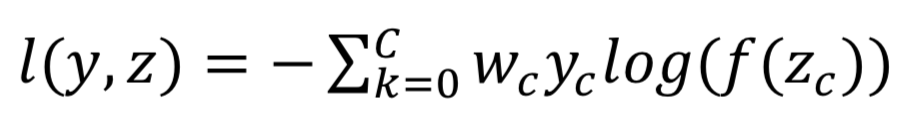
提升樣本(over sampling)法:即對(duì)于類別數(shù)目較少的類別,從中隨機(jī)選擇一些圖片進(jìn)行復(fù)制并添加至該類別包含的圖像內(nèi),直到這個(gè)類別的圖片數(shù)目和最大數(shù)目類的個(gè)數(shù)相等為止。通過實(shí)驗(yàn)發(fā)現(xiàn),這一方法對(duì)最終的分類結(jié)果有了非常大的提升。
在這個(gè)基礎(chǔ)上進(jìn)行改進(jìn)的方法是動(dòng)態(tài)采樣(dynamic sampling)法:該方法根據(jù)訓(xùn)練結(jié)果對(duì)數(shù)據(jù)集進(jìn)行動(dòng)態(tài)調(diào)整,對(duì)結(jié)果較好的類別進(jìn)行隨機(jī)刪除樣本操作,對(duì)結(jié)果較差的類別進(jìn)行隨機(jī)復(fù)制操作,以保證分類模型每次學(xué)習(xí)都能學(xué)到相關(guān)的信息。
兩階段(two-phase)訓(xùn)練法:首先根據(jù)數(shù)據(jù)集分布情況設(shè)置一個(gè)閾值N,通常為最少類別所包含樣例個(gè)數(shù)。隨后對(duì)樣例個(gè)數(shù)大于閾值的類別進(jìn)行隨機(jī)抽取,直到達(dá)到閾值。此時(shí)根據(jù)閾值抽取的數(shù)據(jù)集作為第一階段的訓(xùn)練樣本進(jìn)行訓(xùn)練,并保存模型參數(shù)。最后采用第一階段的模型作為預(yù)訓(xùn)練數(shù)據(jù),再在整個(gè)數(shù)據(jù)集上進(jìn)行訓(xùn)練,對(duì)最終的分類結(jié)果有了一定的提升。
詳細(xì)了解類別不平衡問題,請(qǐng)閱讀:【圖像分類】 關(guān)于圖像分類中類別不平衡那些事
7?如何解決樣本量過少的問題
在構(gòu)建數(shù)據(jù)集時(shí),由于某些圖片的采集難度交大或存在狀況較少,往往會(huì)導(dǎo)致樣本量過少,這一現(xiàn)象同樣會(huì)導(dǎo)致分類模型的性能降低。現(xiàn)有的解決方案主要包括以下幾類:
采用預(yù)訓(xùn)練模型:使用在大量樣本下足夠訓(xùn)練的模型,如果模型的訓(xùn)練數(shù)據(jù)足夠大,且跟你所需求的任務(wù)相匹配,那么可以理解為該預(yù)訓(xùn)練模型所學(xué)到的特征具備一定的通用性。?
降低模型復(fù)雜度:在樣本量過少的情況下,現(xiàn)有的數(shù)據(jù)無法滿足網(wǎng)絡(luò)模型的龐大參數(shù),因此可以對(duì)所用模型進(jìn)行簡(jiǎn)化。
數(shù)據(jù)增強(qiáng):包括平移、翻轉(zhuǎn)、亮度、對(duì)比度、裁剪、縮放等。?
詳細(xì)了解數(shù)據(jù)增強(qiáng)技術(shù),請(qǐng)閱讀:【技術(shù)綜述】深度學(xué)習(xí)中的數(shù)據(jù)增強(qiáng)方法都有哪些?
8 圖像分類的相關(guān)競(jìng)賽與數(shù)據(jù)集
自圖像分類興起以來,各行各業(yè)均提出了自身的需求,并舉辦很多圖像分類的競(jìng)賽,提出了各種數(shù)據(jù)集。
8.1 競(jìng)賽
其中,最著名的即ImageNet分類競(jìng)賽,自2009年李飛飛團(tuán)隊(duì)發(fā)布了ImageNet數(shù)據(jù)集以來,從2010年開始每年舉辦一次ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)賽,即ILSVRC。該競(jìng)賽于2017年正式結(jié)束。八年間,該競(jìng)賽大大促進(jìn)了圖像分類領(lǐng)域的發(fā)展,并有無數(shù)經(jīng)典的網(wǎng)絡(luò)得以提出。
2011 年,谷歌開始贊助舉辦第一屆FGVC Workshop,之后每?jī)赡昱e辦一次,到 2017 年已經(jīng)舉辦了四屆。由于近年來計(jì)算機(jī)視覺的快速發(fā)展,F(xiàn)GVC 活動(dòng)影響力也越來越大,自2018年開始由兩年一次改為了一年一次。FGVC競(jìng)賽側(cè)重于子類別的詳細(xì)劃分,每屆賽事都包含了多個(gè)主題,涵蓋了動(dòng)物種類、零售產(chǎn)品、藝術(shù)品屬性、木薯葉病、臘葉標(biāo)本的野牡丹科物種、來自生命科學(xué)圖片的動(dòng)物物種、蝴蝶和蛾物種、菜肴烹飪以及博物館藝術(shù)品等多個(gè)事物的細(xì)粒度屬性。
除此了上述兩個(gè)大型競(jìng)賽以外,Kaggle和阿里天池也同樣舉辦了若干圖像分類競(jìng)賽,不僅解決了實(shí)際的應(yīng)用問題,也進(jìn)一步促進(jìn)了分類模型的研究發(fā)展。
8.2 數(shù)據(jù)集
俗話說:巧婦難為無米之炊。數(shù)據(jù)作為驅(qū)動(dòng)深度學(xué)習(xí)的源動(dòng)力之一,更是圖像分類任務(wù)的根基,直白來說,任何領(lǐng)域的分類研究都離不開數(shù)據(jù)。
不論學(xué)界還是工業(yè)界,確定特定的研究方向后,必須搭建相關(guān)的高質(zhì)量數(shù)據(jù)集才可以進(jìn)行進(jìn)一步的研究,同時(shí)也能以更統(tǒng)一的標(biāo)準(zhǔn)對(duì)模型性能進(jìn)行評(píng)判。
下面根據(jù)應(yīng)用場(chǎng)景的不同,匯總了9個(gè)相關(guān)領(lǐng)域的數(shù)據(jù)集,并根據(jù)數(shù)據(jù)集自身特點(diǎn),注明其容量、類別和適用的分類任務(wù),以供大家參考使用。
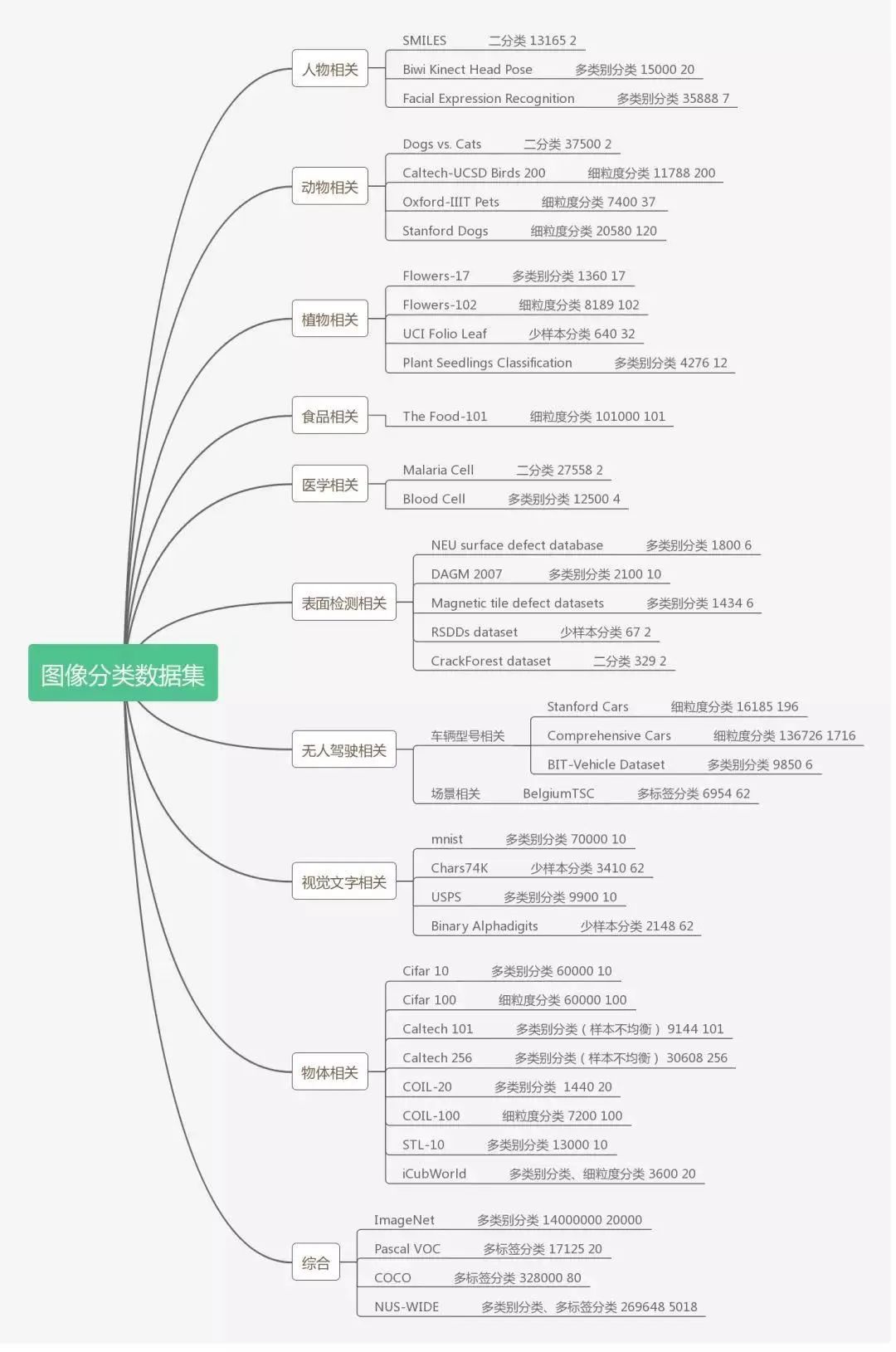
初入圖像處理領(lǐng)域的同學(xué),主要以MNIST、CIFAR 10數(shù)據(jù)集進(jìn)行練手,可以幫助新手迅速了解神經(jīng)網(wǎng)絡(luò)的構(gòu)成,同時(shí)掌握深度學(xué)習(xí)和圖像處理的相關(guān)基礎(chǔ)知識(shí)。
對(duì)于已經(jīng)有一定基礎(chǔ)的同學(xué),需要通過更多的實(shí)操來強(qiáng)化對(duì)不同結(jié)構(gòu)和知識(shí)的理解以及應(yīng)用,并實(shí)現(xiàn)調(diào)參、數(shù)據(jù)處理、網(wǎng)絡(luò)結(jié)構(gòu)替換等更高一層的任務(wù),CIFAR 100、表情分類相關(guān)的數(shù)據(jù)集則是其中代表。
對(duì)于經(jīng)過多個(gè)任務(wù)歷練,需要根據(jù)實(shí)際需求和科研方向來選擇數(shù)據(jù)集的同學(xué),這就涉及到多標(biāo)簽分類、細(xì)粒度分類和少樣本分類等更復(fù)雜的任務(wù),也就需要選擇Pascal VOC、ImageNet等更高層級(jí)的數(shù)據(jù)集,同時(shí)還有可能同時(shí)利用這些數(shù)據(jù)集,從中選取合適的圖像以搭建滿足自己需求的數(shù)據(jù)。
9 參考資料
最后,我們來匯總一下有三AI生態(tài)中掌握好圖像分類任務(wù)可以使用的相關(guān)資源。
(1) 圖像分類專欄,本專欄詳解了圖像分類的各領(lǐng)域關(guān)鍵技術(shù)。

(2) 書籍《深度學(xué)習(xí)之圖像識(shí)別:核心技術(shù)和與案例實(shí)戰(zhàn)》和《深度學(xué)習(xí)之模型設(shè)計(jì):核心算法與案例實(shí)踐》,前者詳解了圖像分類中的核心算法,后者詳解了各種各樣的模型設(shè)計(jì)思想。

[1] Lecun Y , Bottou L . Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[2]?Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[3]?Szegedy C , Liu W , Jia Y , et al. Going Deeper with Convolutions[J]. 2014.
[4]?Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[5] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2015.
[6]?Huang G , Liu Z , Laurens V D M , et al. Densely Connected Convolutional Networks[J]. 2016.
[7]?Hu J , Shen L , Albanie S , et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[8]?Lin T Y , Roychowdhury A , Maji S . Bilinear CNN Models for Fine-grained Visual Recognition[J]. 2015.
[9]?Bhatnagar B L , Singh S , Arora C , et al. Unsupervised Learning of Deep Feature Representation for Clustering Egocentric Actions[C]// IJCAI. 2017.
[10]?Ji X , Vedaldi A , Henriques J . Invariant Information Clustering for Unsupervised Image Classification and Segmentation[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019.
[11]言有三.深度學(xué)習(xí)之圖像識(shí)別:核心技術(shù)和與案例實(shí)戰(zhàn)[M].機(jī)械工業(yè)出版社:北京,2019:5.
[12]?言有三.深度學(xué)習(xí)之模型設(shè)計(jì):核心算法與案例實(shí)踐[M].電子工業(yè)出版社:北京,2020:6.
圖像分類作為計(jì)算機(jī)視覺領(lǐng)域的基礎(chǔ)任務(wù)之一,是其他計(jì)算機(jī)視覺任務(wù)的研究基礎(chǔ),更是進(jìn)入該領(lǐng)域的敲門磚。因此,掌握?qǐng)D像分類的基礎(chǔ)知識(shí),會(huì)幫助你更快地開展學(xué)習(xí)任務(wù)。本文所涵蓋的內(nèi)容并非全面,但仍希望能在你初學(xué)的道路上給予一定的幫助!