
2021 ICCV Best Paper | Swin Transformer
及時獲取最優(yōu)質的CV內容

昨天Swin Transformer拿到2021 ICCV Best Paper了!恭喜恭喜!MSRA再一次拿到Best Paper,上一次可以追溯到ResNet,巧合的是,這一次也是通用骨干網絡模型。

放一張圖感受一下SwinT的威力
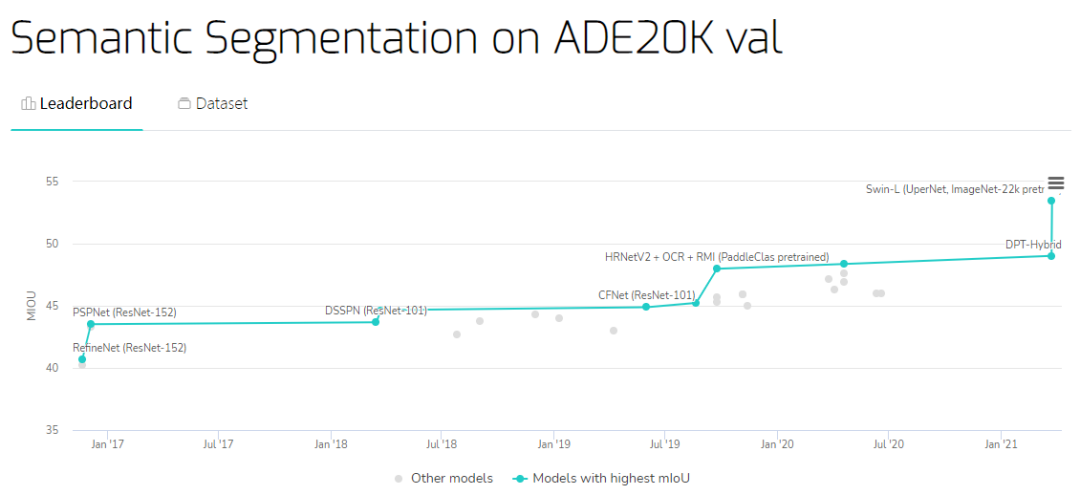
語義分割在ADE20K上刷到53.5 mIoU,超過之前SOTA大概4.5 mIoU!
來源:https://paperswithcode.com/sota/semantic-segmentation-on-ade20k-val
最近Transformer的文章眼花繚亂,但是精度和速度相較于CNN而言還是差點意思,直到Swin Transformer的出現,讓人感覺到了一絲絲激動,Swin Transformer可能是CNN的完美替代方案。
作者分析表明,Transformer從NLP遷移到CV上沒有大放異彩主要有兩點原因:1. 兩個領域涉及的scale不同,NLP的scale是標準固定的,而CV的scale變化范圍非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的計算復雜度是圖像尺度的平方,這會導致計算量過于龐大。為了解決這兩個問題,Swin Transformer相比之前的ViT做了兩個改進:1.引入CNN中常用的層次化構建方式構建層次化Transformer 2.引入locality思想,對無重合的window區(qū)域內進行self-attention計算。

相比于ViT,Swin Transfomer計算復雜度大幅度降低,具有輸入圖像大小線性計算復雜度。Swin Transformer隨著深度加深,逐漸合并圖像塊來構建層次化Transformer,可以作為通用的視覺骨干網絡,應用于圖像分類、目標檢測和語義分割等任務。
01
Swin Transformer?
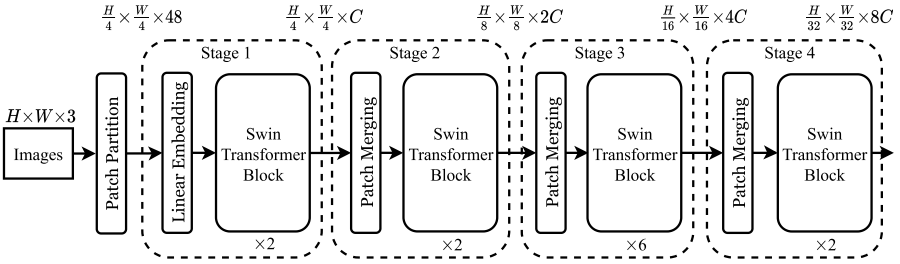
整個Swin Transformer架構,和CNN架構非常相似,構建了4個stage,每個stage中都是類似的重復單元。和ViT類似,通過patch partition將輸入圖片HxWx3劃分為不重合的patch集合,其中每個patch尺寸為4x4,那么每個patch的特征維度為4x4x3=48,patch塊的數量為H/4 x W/4;stage1部分,先通過一個linear embedding將輸劃分后的patch特征維度變成C,然后送入Swin Transformer Block;stage2-stage4操作相同,先通過一個patch merging,將輸入按照2x2的相鄰patches合并,這樣子patch塊的數量就變成了H/8 x W/8,特征維度就變成了4C,這個地方文章寫的不清楚,猜測是跟stage1一樣使用linear embedding將4C壓縮成2C,然后送入Swin Transformer Block。
另外有一個細節(jié),Swin Transformer和ViT劃分patch的方式類似,Swin Transformer也是先確定每個patch的大小,然后計算確定patch數量。不同的是,隨著網絡深度加深ViT的patch數量不會變化,而Swin Transformer隨著網絡深度的加深數量會逐漸減少并且每個patch的感知范圍會擴大,這個設計是為了方便Swin Transformer的層級構建,并且能夠適應視覺任務的多尺度。
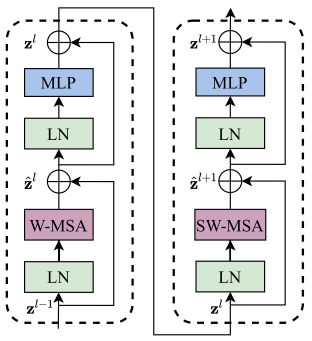
上圖是兩個連續(xù)的Swin Transformer Block。一個Swin Transformer Block由一個帶兩層MLP的shifted window based MSA組成。在每個MSA模塊和每個MLP之前使用LayerNorm(LN)層,并在每個MSA和MLP之后使用殘差連接。
02
Shifted Window based MSA?
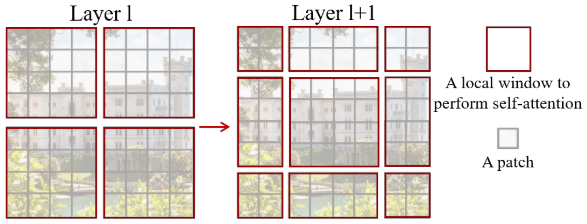
上圖中紅色區(qū)域是window,灰色區(qū)域是patch。W-MSA將輸入圖片劃分成不重合的windows,然后在不同的window內進行self-attention計算。假設一個圖片有hxw的patches,每個window包含MxM個patches,那么MSA和W-MSA的計算復雜度分別為:
?
(復雜度計算,計算?
由于window的patch數量遠小于圖片patch數量,W-MSA的計算復雜度和圖像尺寸呈線性關系。
另外W-MSA雖然降低了計算復雜度,但是不重合的window之間缺乏信息交流,于是作者進一步引入shifted window partition來解決不同window的信息交流問題,在兩個連續(xù)的Swin Transformer Block中交替使用W-MSA和SW-MSA。以上圖為例,將前一層Swin Transformer Block的8x8尺寸feature map劃分成2x2個patch,每個patch尺寸為4x4,然后將下一層Swin Transformer Block的window位置進行移動,得到3x3個不重合的patch。移動window的劃分方式使上一層相鄰的不重合window之間引入連接,大大的增加了感受野。
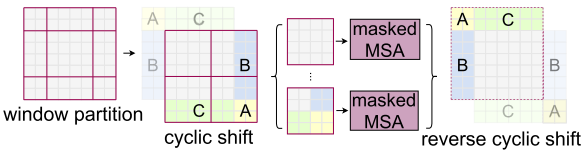
但是shifted window劃分方式還引入了另外一個問題,就是會產生更多的windows,并且其中一部分window小于普通的window,比如2x2個patch -> 3x3個patch,windows數量增加了一倍多。于是作者提出了通過沿著左上方向cyclic shift的方式來解決這個問題,移動后,一個batched window由幾個特征不相鄰的sub-windows組成,因此使用masking mechanism來限制self-attention在sub-window內進行計算。cyclic shift之后,batched window和regular window數量保持一致,極大提高了Swin Transformer的計算效率。這一部分比較抽象復雜,不好理解,等代碼開源了再補上。
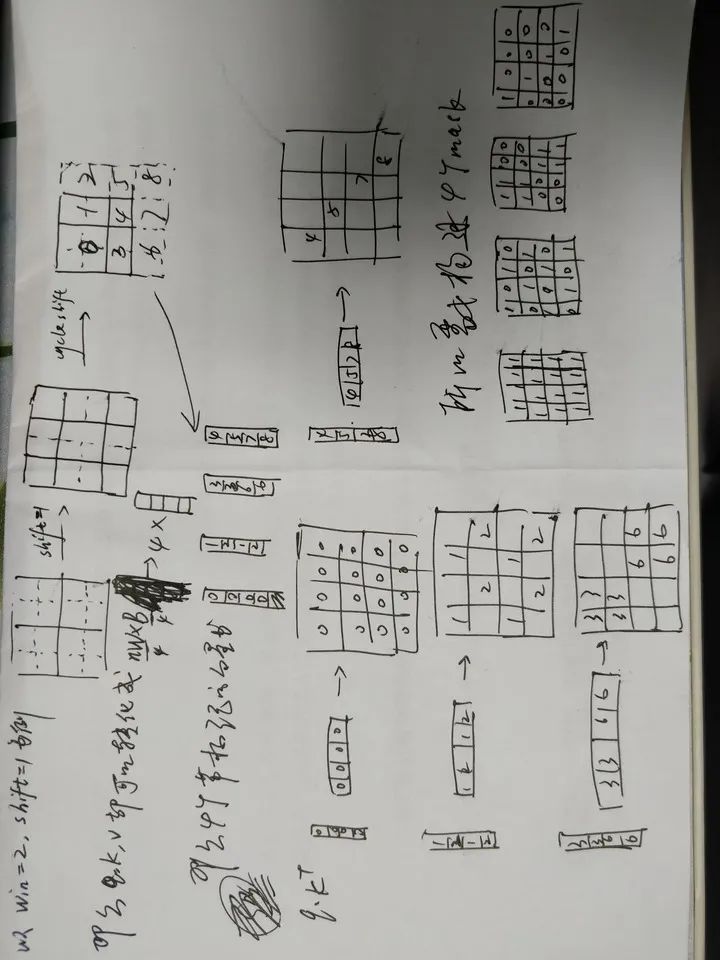
感謝Smarter交流群小伙伴的補充說明(加微信進交流群: cjy094617)

03
實驗結果
放一些實驗結果,感受一下Swin Transformer對之前SOTA的降維打擊。
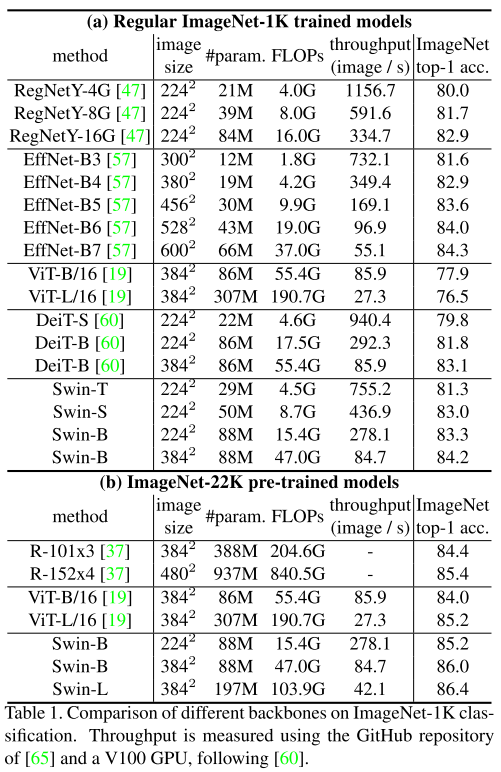
圖像分類上比ViT、DeiT等Transformer類型的網絡效果更好,但是比不過CNN類型的EfficientNet,猜測Swin Transformer還是更加適用于更加復雜、尺度變化更多的任務。
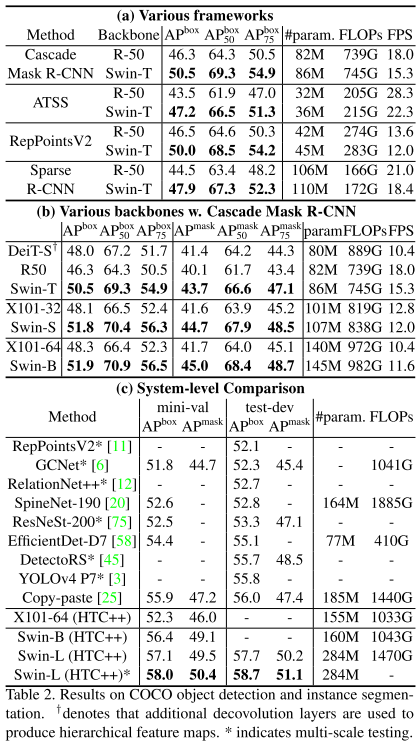
目標檢測碾壓
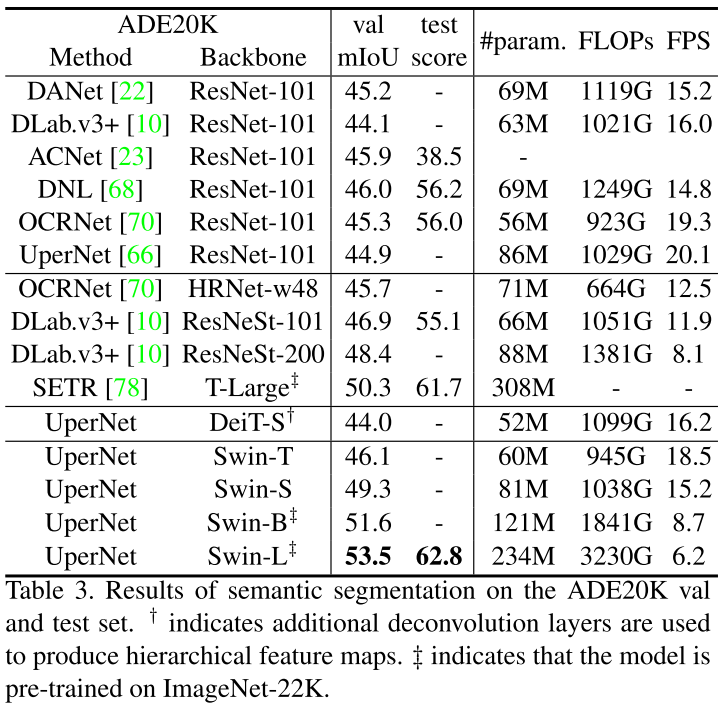
語義分割碾壓
目標檢測在COCO上刷到58.7 AP(發(fā)表時第一)
實例分割在COCO上刷到51.1 Mask AP(發(fā)表時第一)
語義分割在ADE20K上刷到53.5 mIoU(發(fā)表時第一)
paper: https://arxiv.org/abs/2103.14030
code: https://github.com/microsoft/Swin-Transformer
一作解讀: https://www.zhihu.com/question/437495132/answer/1800881612
04
總結
網絡架構設計:CNN based和Transformer based
上一篇文章討論了一下網絡架構設計是以CNN為主好還是Transformer為主好的問題,Swin Transformer給出了答案。Swin Transformer 吸收了CNN的locality、translation invariance和hierarchical等優(yōu)點,形成了對CNN的降維打擊。
Swin Transformer改進思路還是源于CNN,Transformer站在巨人的肩膀上又迎來了一次巨大的飛躍,未來Transformer會接過CNN手中的接力棒,把locality、translation invariance和hierarchical等思想繼續(xù)發(fā)揚光大。
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉載請說明出處
掃描下方二維碼關注【集智書童】公眾號,獲取更多實踐項目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
