
我女朋友們竟然不會Flink的CheckPoint機制
這里已經(jīng)是Flink的第三篇原創(chuàng)啦。第一篇《Flink入門教程》講解了Flink的基礎(chǔ)和相關(guān)概念,第二篇《背壓原理》講解了什么是背壓,在Flink背壓大概的流程是怎么樣的。
這篇來講Flink另一個比較重要的知識,就是它的容錯機制checkpoint原理。
所謂的CheckPoint其實就是Flink會在指定的時間段上保存狀態(tài)的信息,如果Flink掛了可以將上一次狀態(tài)信息再撈出來,重放還沒保存的數(shù)據(jù)來執(zhí)行計算,最終可以實現(xiàn)exactly once。
狀態(tài)只持久化一次到最終的存儲介質(zhì)中(本地數(shù)據(jù)庫/HDFS),在Flink下就叫做exactly once(計算的數(shù)據(jù)可能會重復(無法避免),但狀態(tài)在存儲介質(zhì)上只會存儲一次)。
前排提醒,本文基于Flink 1.7
《淺入淺出學習Flink的checkpoint知識》
開胃菜(復習)
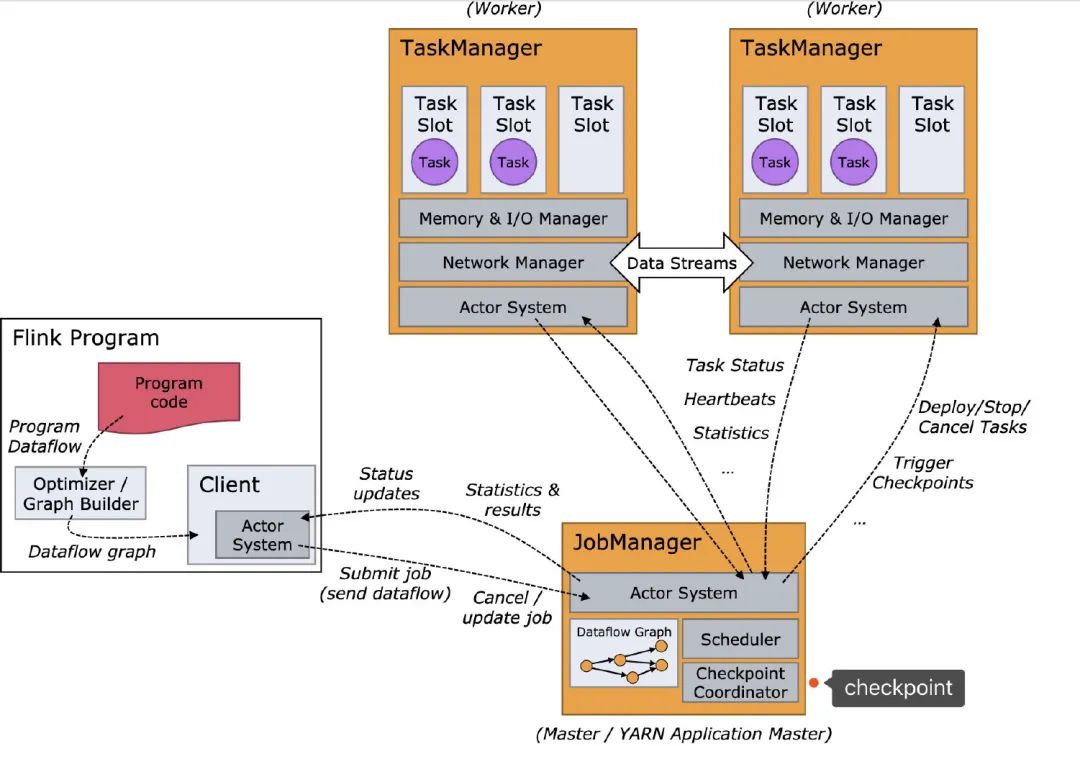
作為用戶,我們寫好Flink的程序,上管理平臺提交,Flink就跑起來了(只要程序代碼沒有問題),細節(jié)對用戶都是屏蔽的。
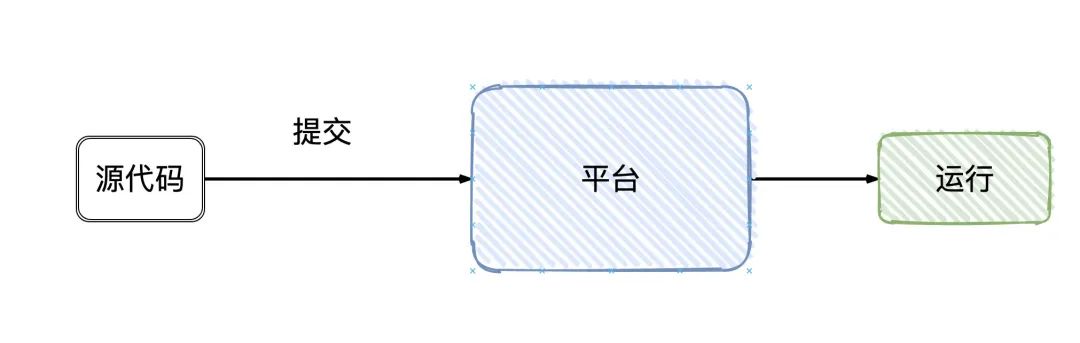
實際上大致的流程是這樣的:
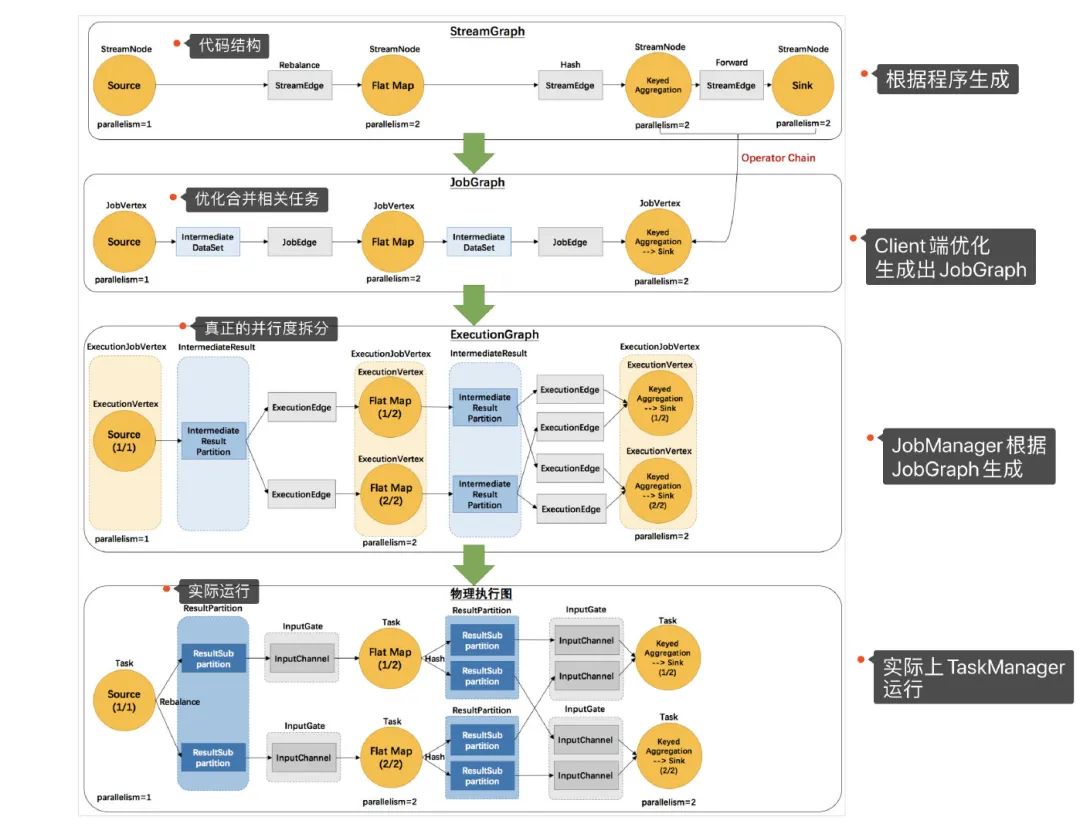
Flink會根據(jù)我們所寫代碼,會生成一個StreamGraph的圖出來,來代表我們所寫程序的拓撲結(jié)構(gòu)。然后在提交的之前會將 StreamGraph這個圖優(yōu)化一把(可以合并的任務(wù)進行合并),變成JobGraph將 JobGraph提交給JobManagerJobManager收到之后JobGraph之后會根據(jù)JobGraph生成ExecutionGraph(ExecutionGraph是JobGraph的并行化版本)TaskManager接收到任務(wù)之后會將ExecutionGraph生成為真正的物理執(zhí)行圖
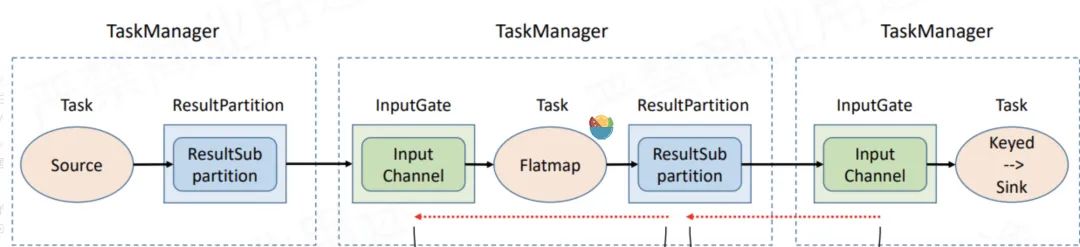
可以看到物理執(zhí)行圖真正運行在TaskManager上Transform和Sink之間都會有ResultPartition和InputGate這倆個組件,ResultPartition用來發(fā)送數(shù)據(jù),而InputGate用來接收數(shù)據(jù)。
屏蔽掉這些Graph,可以發(fā)現(xiàn)Flink的架構(gòu)是:Client->JobManager->TaskManager
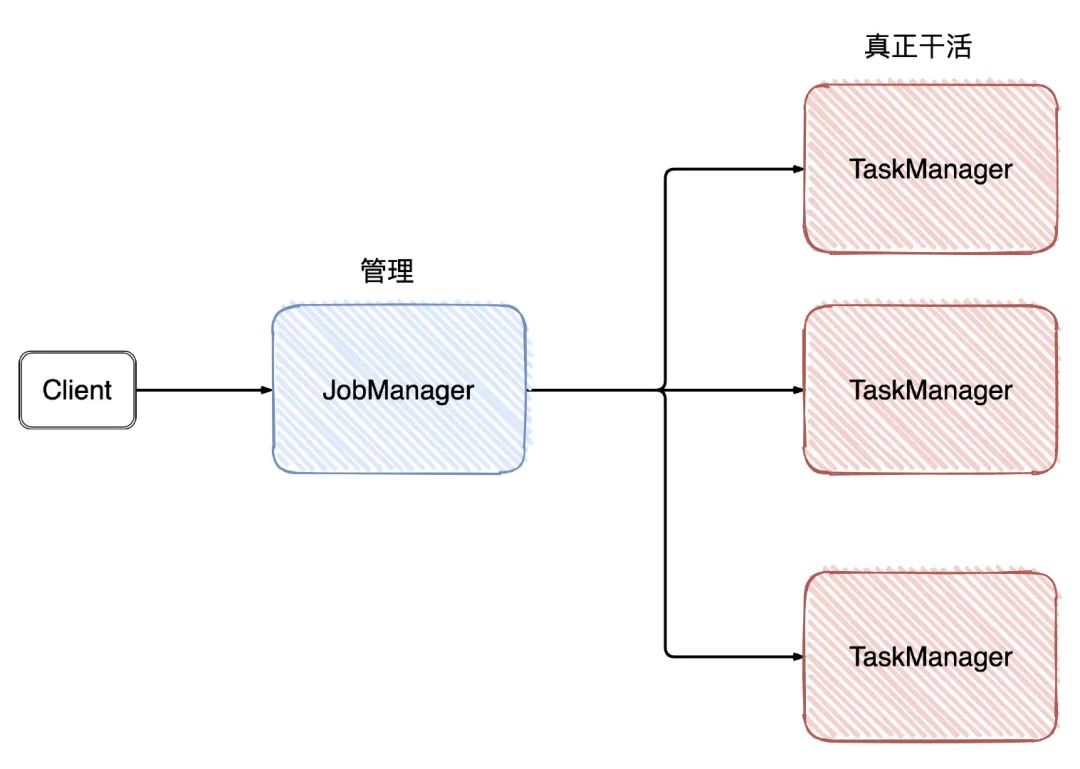
從名字就可以看出,JobManager是干「管理」,而TaskManager是真正干活的。回到我們今天的主題,checkpoint就是由JobManager發(fā)出。
Flink本身就是有狀態(tài)的,Flink可以讓你選擇執(zhí)行過程中的數(shù)據(jù)保存在哪里,目前有三個地方,在Flink的角度稱作State Backends:
MemoryStateBackend(內(nèi)存) FsStateBackend(文件系統(tǒng),一般是HSFS) RocksDBStateBackend(RocksDB數(shù)據(jù)庫)
同樣地,checkpoint信息就是保存在State Backends上
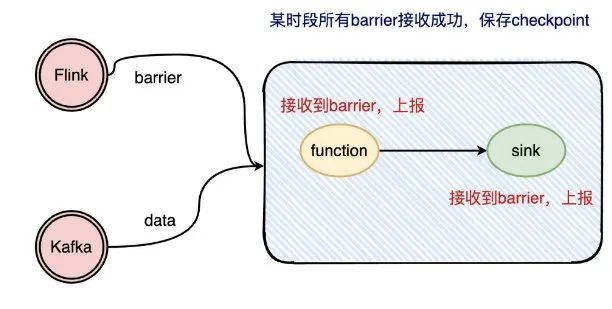
先來簡單描述一下checkpoint的實現(xiàn)流程:
checkpoint的實現(xiàn)大致就是插入barrier,每個operator收到barrier就上報給JobManager,等到所有的operator都上報了barrier,那JobManager 就去完成一次checkpointi
因為checkpoint機制是Flink實現(xiàn)容錯機制的關(guān)鍵,我們在實際使用中,往往都要配置checkpoint相關(guān)的配置,例如有以下的配置:
final?StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
簡單鋪墊過后,我們就來擼源碼了咯?
Checkpoint(原理)
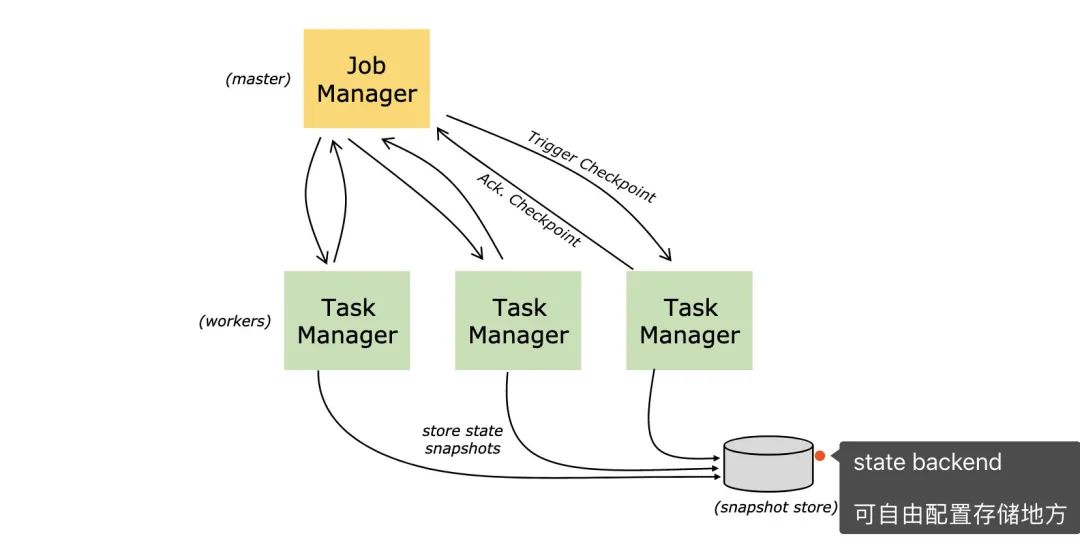
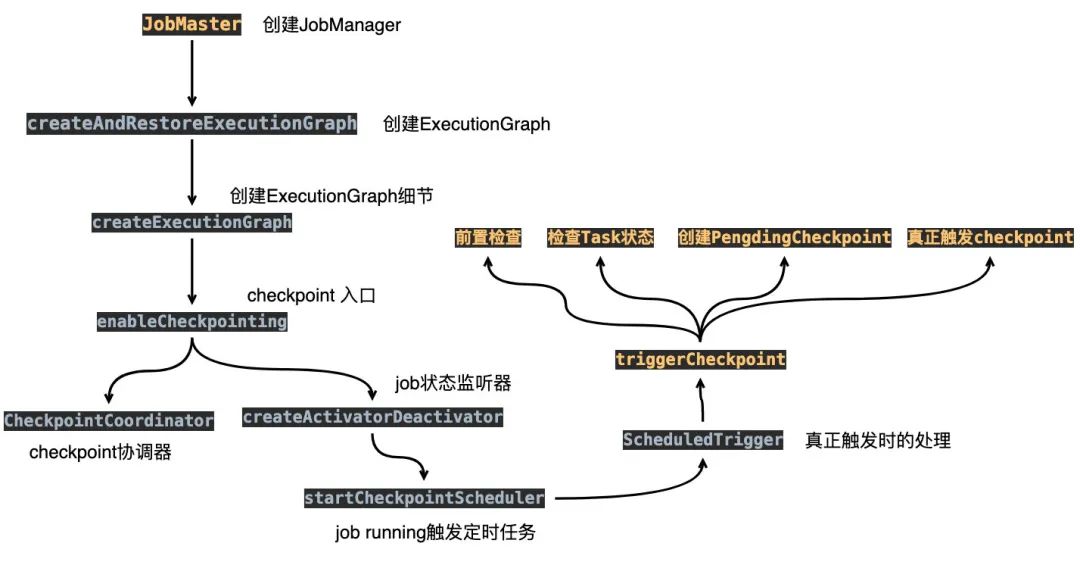
JobManager發(fā)送checkpoint
從上面的圖我們可以發(fā)現(xiàn) checkpoint是由JobManager發(fā)出的,并且JobManager收到的是JobGraph,會將JobGraph轉(zhuǎn)換成ExecutionGraph。
這塊在JobMaster的構(gòu)造器就能體現(xiàn)出來:
public?JobMaster(...)?throws?Exception?{
??//?創(chuàng)建ExecutionGraph
??this.executionGraph?=?createAndRestoreExecutionGraph(jobManagerJobMetricGroup);
?}
我們點擊進去createAndRestoreExecutionGraph看下:
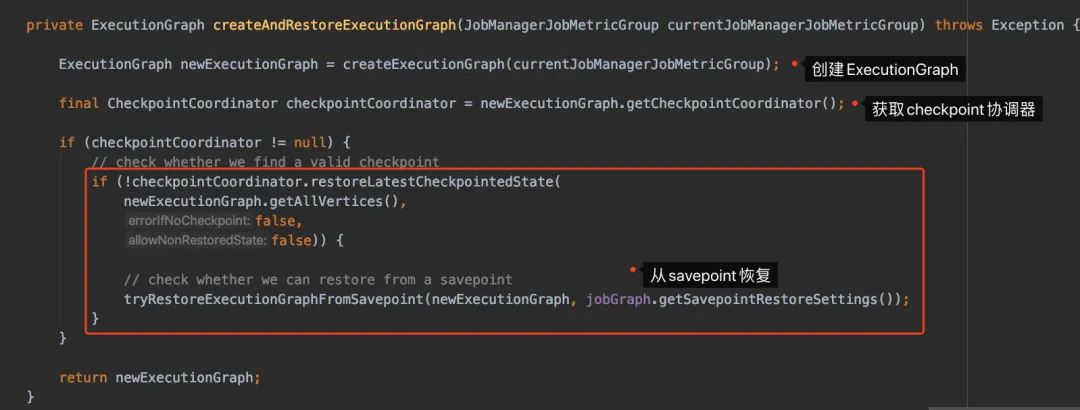
看CheckpointCoordinator這個名字,就覺得他很重要,有木有?它從ExecutionGraph來,我們就進去createExecutionGraph里邊看看唄。
點了兩層buildGraph()方法,可以看到在方法的末尾處有checkpoint相關(guān)的信息:
executionGraph.enableCheckpointing(
????chkConfig.getCheckpointInterval(),
????chkConfig.getCheckpointTimeout(),
????chkConfig.getMinPauseBetweenCheckpoints(),
????chkConfig.getMaxConcurrentCheckpoints(),
????chkConfig.getCheckpointRetentionPolicy(),
????triggerVertices,
????ackVertices,
????confirmVertices,
????hooks,
????checkpointIdCounter,
????completedCheckpoints,
????rootBackend,
????checkpointStatsTracker);
前面的幾個參數(shù)就是我們在配置checkpoint參數(shù)的時候指定的,而triggerVertices/confirmVertices/ackVertices我們溯源看了一下,在源碼中注釋也寫得清清楚楚的。
//?collect?the?vertices?that?receive?"trigger?checkpoint"?messages.
//?currently,?these?are?all?the?sources?
List?triggerVertices?=?new?ArrayList<>();
//?collect?the?vertices?that?need?to?acknowledge?the?checkpoint
//?currently,?these?are?all?vertices
List?ackVertices?=?new?ArrayList<>(jobVertices.size());
//?collect?the?vertices?that?receive?"commit?checkpoint"?messages
//?currently,?these?are?all?vertices
List?commitVertices?=?new?ArrayList<>(jobVertices.size());
下面還是進去enableCheckpointing()看看大致做了些什么吧:
//?將上面的入?yún)⒎謩e封裝成ExecutionVertex數(shù)組
ExecutionVertex[]?tasksToTrigger?=?collectExecutionVertices(verticesToTrigger);
ExecutionVertex[]?tasksToWaitFor?=?collectExecutionVertices(verticesToWaitFor);
ExecutionVertex[]?tasksToCommitTo?=?collectExecutionVertices(verticesToCommitTo);
//?創(chuàng)建觸發(fā)器
checkpointStatsTracker?=?checkNotNull(statsTracker,?"CheckpointStatsTracker");
//?創(chuàng)建checkpoint協(xié)調(diào)器
checkpointCoordinator?=?new?CheckpointCoordinator(
??jobInformation.getJobId(),
??interval,
??checkpointTimeout,
??minPauseBetweenCheckpoints,
??maxConcurrentCheckpoints,
??retentionPolicy,
??tasksToTrigger,
??tasksToWaitFor,
??tasksToCommitTo,
??checkpointIDCounter,
??checkpointStore,
??checkpointStateBackend,
??ioExecutor,
??SharedStateRegistry.DEFAULT_FACTORY);
//?設(shè)置觸發(fā)器
checkpointCoordinator.setCheckpointStatsTracker(checkpointStatsTracker);
//?狀態(tài)變更監(jiān)聽器
//?job?status?changes?(running?->?on,?all?other?states?->?off)
if?(interval?!=?Long.MAX_VALUE)?{
??registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
}
值得一提的是,點進去CheckpointCoordinator()構(gòu)造方法可以發(fā)現(xiàn)有狀態(tài)后端StateBackend的身影(因為checkpoint就是保存在所配置的狀態(tài)后端)
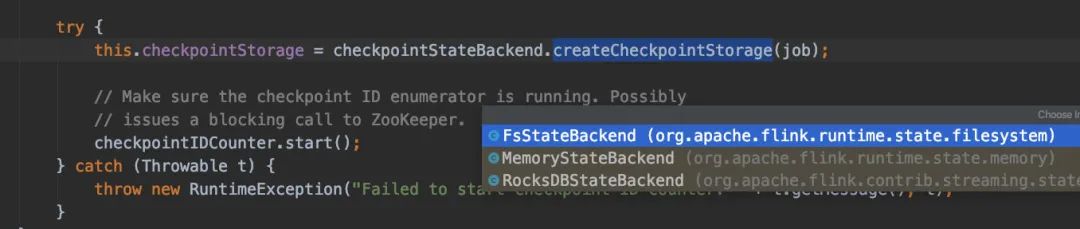
如果Job的狀態(tài)變更了,CheckpointCoordinatorDeActivator是能監(jiān)聽到的。
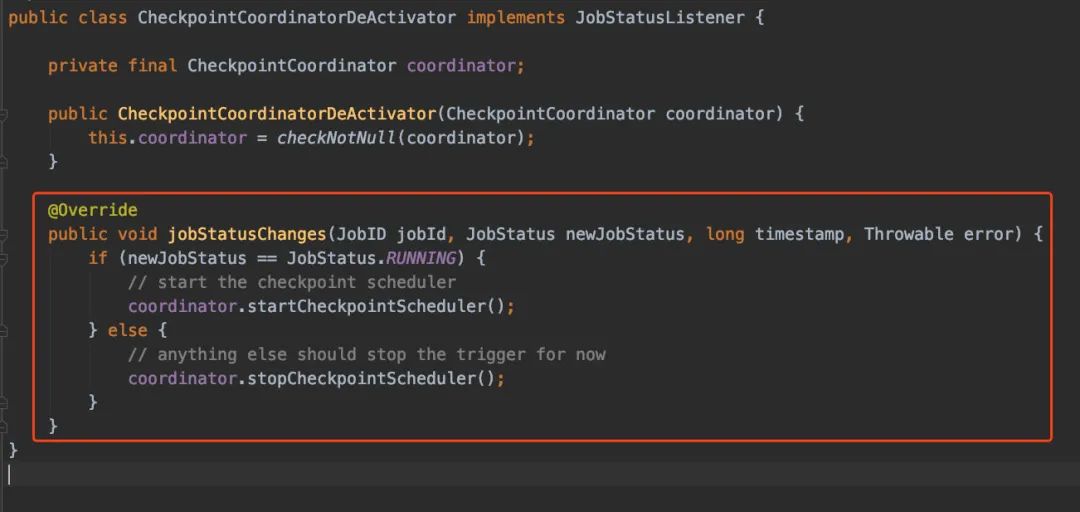
當我們的Job啟動的時候,又簡單看看startCheckpointScheduler()里邊究竟做了些什么操作:
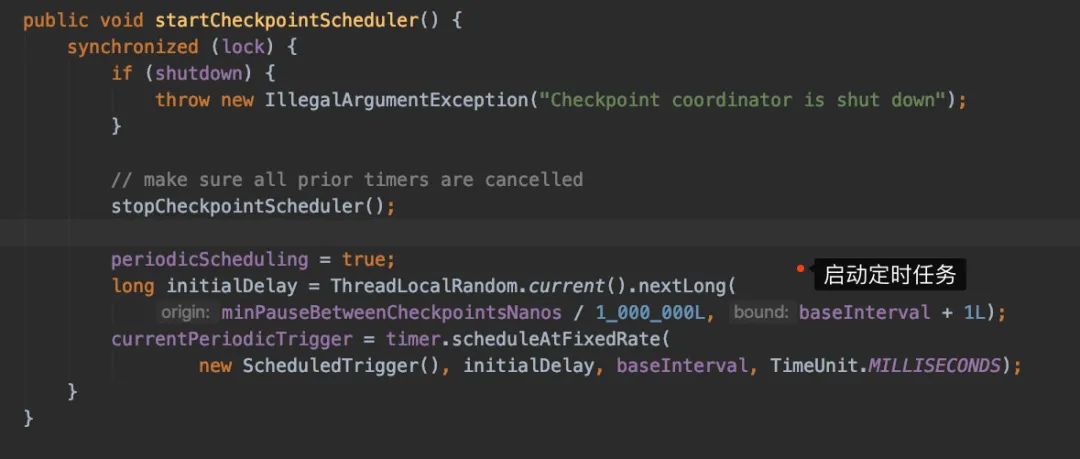
它會啟動一個定時任務(wù),我們具體看看定時任務(wù)具體做了些什么ScheduledTrigger,然后看到比較重要的方法:triggerCheckpoint()
這塊代碼的邏輯有點多,我們簡單來總結(jié)一下
前置檢查(是否可以觸發(fā) checkpoint,距離上一次checkpoint的間隔時間是否符合...)檢查是否所有的需要做 checkpoint的Task都處于running狀態(tài)生成 checkpointId,然后生成PendingCheckpoint對象來代表待處理的檢查點注冊一個定時任務(wù),如果 checkpoint超時后取消checkpoint
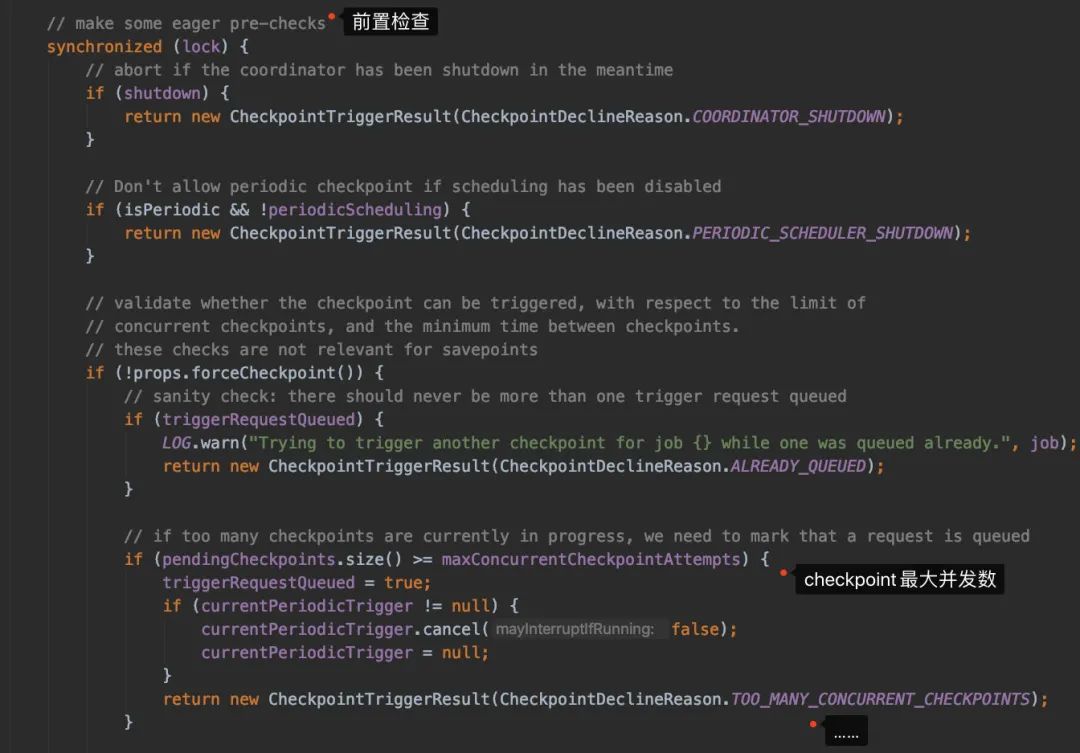
注:檢查task的任務(wù)狀態(tài)時,只會把source的task封裝給進Execution[]數(shù)組
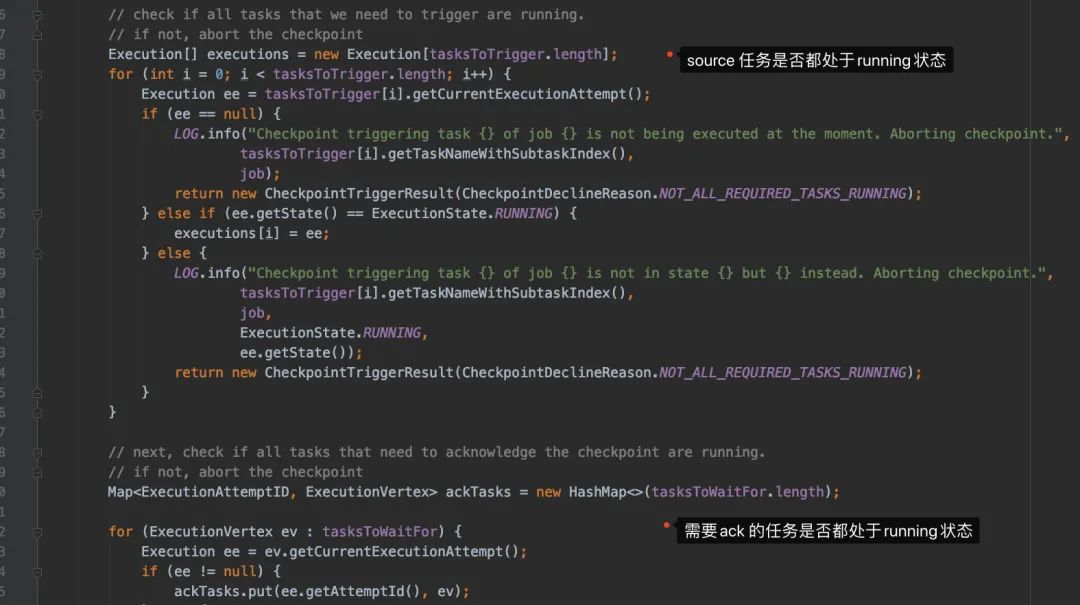
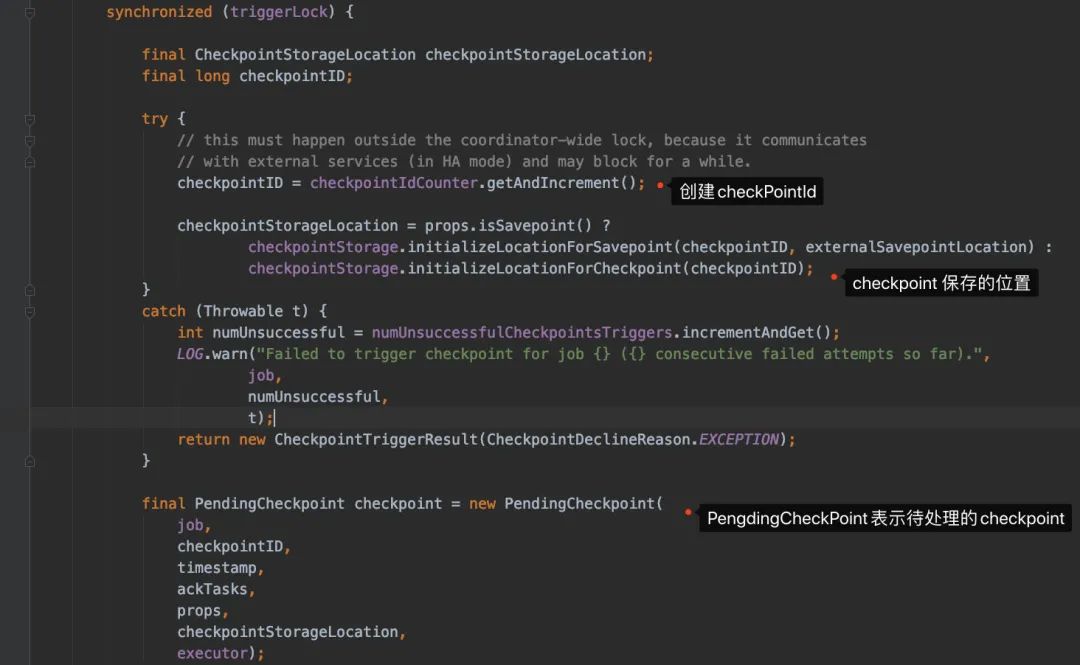
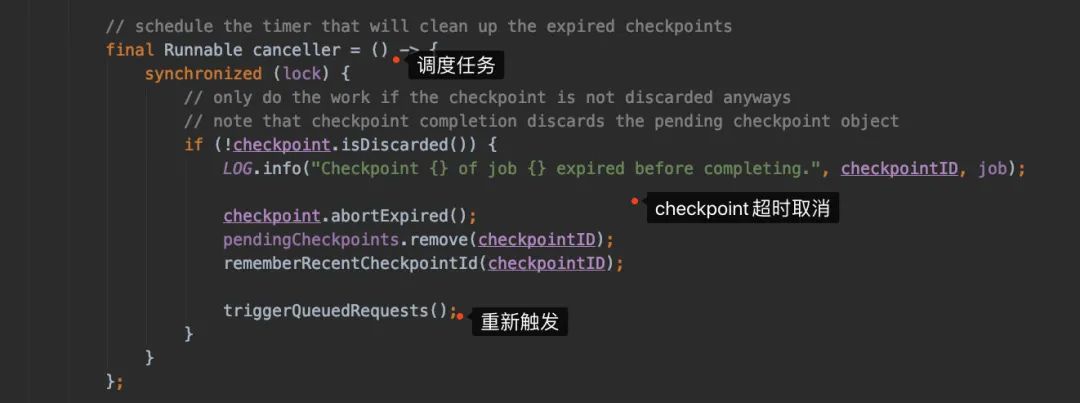

JobManager側(cè)只會發(fā)給source的task發(fā)送checkpoint
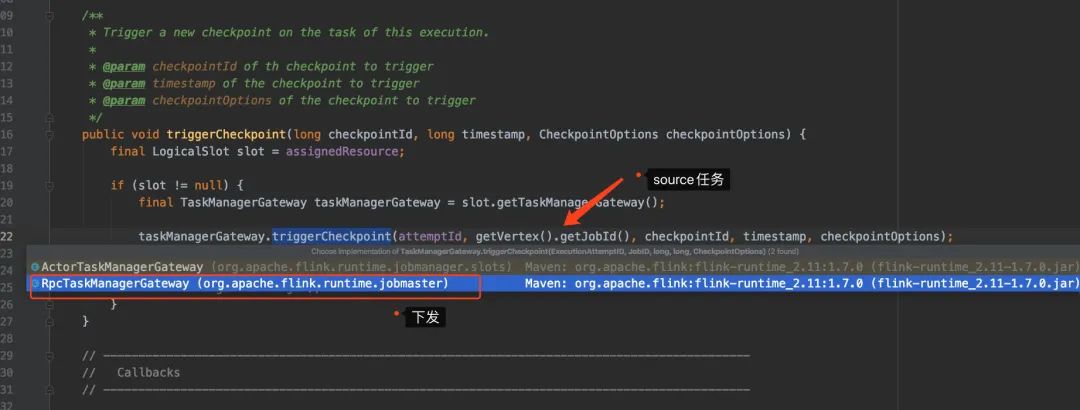
JobManager發(fā)送總結(jié)
貼的圖有點多,最后再來簡單總結(jié)一波,順便畫個流程圖,你就會發(fā)現(xiàn)還是比較清晰的。
JobManager收到client提交的JobGraphJobManger需要通過JobGraph生成ExecutionGraph在生成 ExcutionGraph的過程中實際上就會觸發(fā)checkpoint的邏輯定時任務(wù)會前置檢查(其實就是你實際上配置的各種參數(shù)是否符合) 判斷 checkpoint相關(guān)的task是否都是running狀態(tài),將source的任務(wù)封裝到Execution數(shù)組中創(chuàng)建 checkpointID/checkpointStorageLocation(checkpoint保存的地方)/PendingCheckpoint(待處理的checkpoint)創(chuàng)建定時任務(wù)(如果當 checkpoint超時,會將相關(guān)狀態(tài)清除,重新觸發(fā))真正觸發(fā) checkPoint給TaskManager(只會發(fā)給source的task)找出所有 source和需要ack的Task創(chuàng)建 checkpointCoordinator協(xié)調(diào)器創(chuàng)建 CheckpointCoordinatorDeActivator監(jiān)聽器,監(jiān)聽Job狀態(tài)的變更當 Job啟動時,會觸發(fā)ScheduledTrigger定時任務(wù)
TaskManager(source Task接收)
前面提到了,JobManager 在生成ExcutionGraph時,會給所有的source 任務(wù)發(fā)送checkpoint,那么source收到barrier又是怎么處理的呢?會到TaskExecutor這里進行處理。
TaskExecutor有個triggerCheckpoint()方法對接收到的checkpoint進行處理:
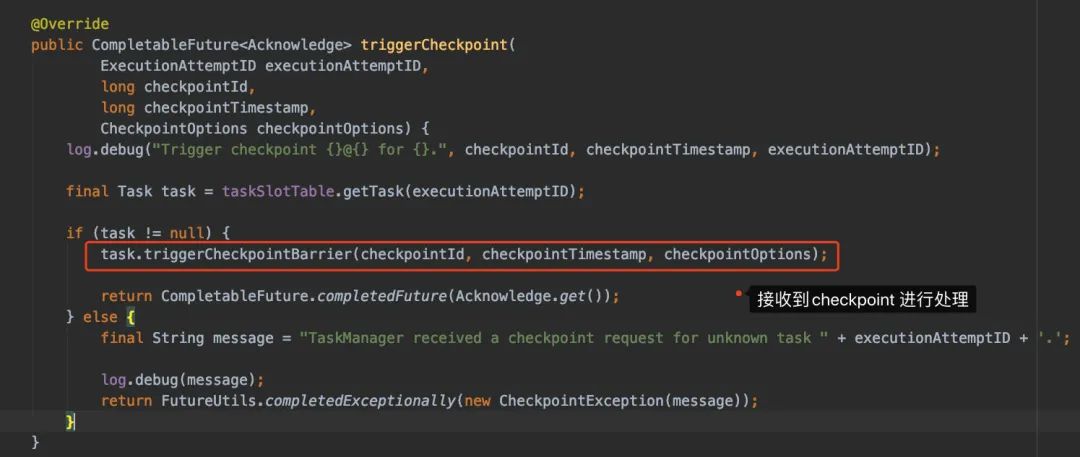
進入triggerCheckpointBarrier()看看:
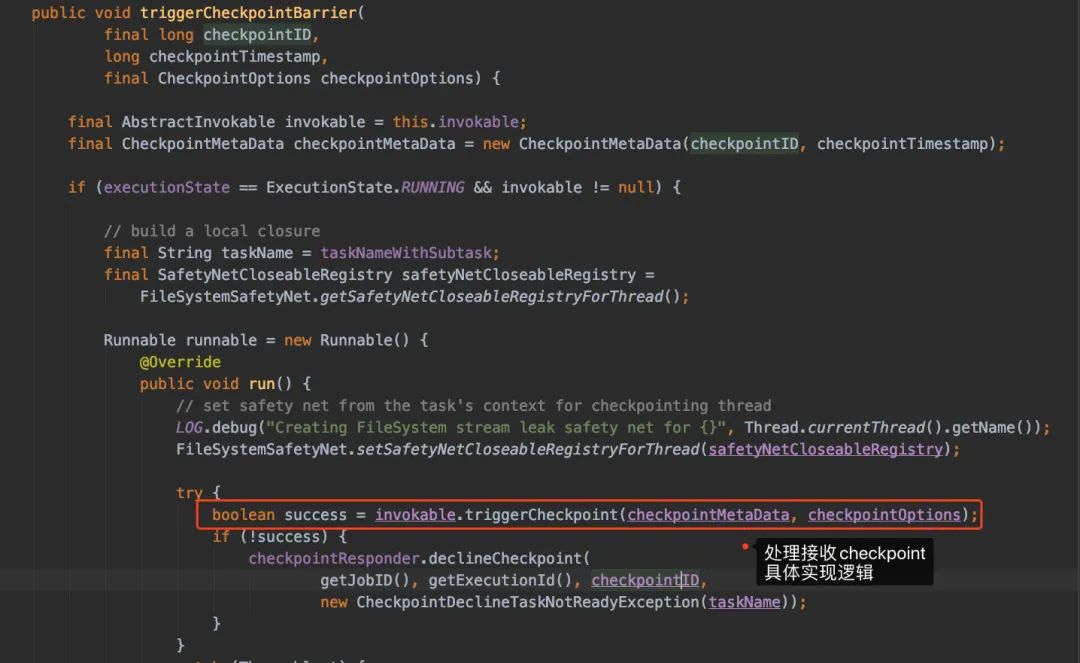
再想點進去triggerCheckpoint()看實現(xiàn)時,我們會發(fā)現(xiàn)走到performCheckpoint()這個方法上:

從實現(xiàn)的注釋我們可以很方便看出方法大概做了什么:
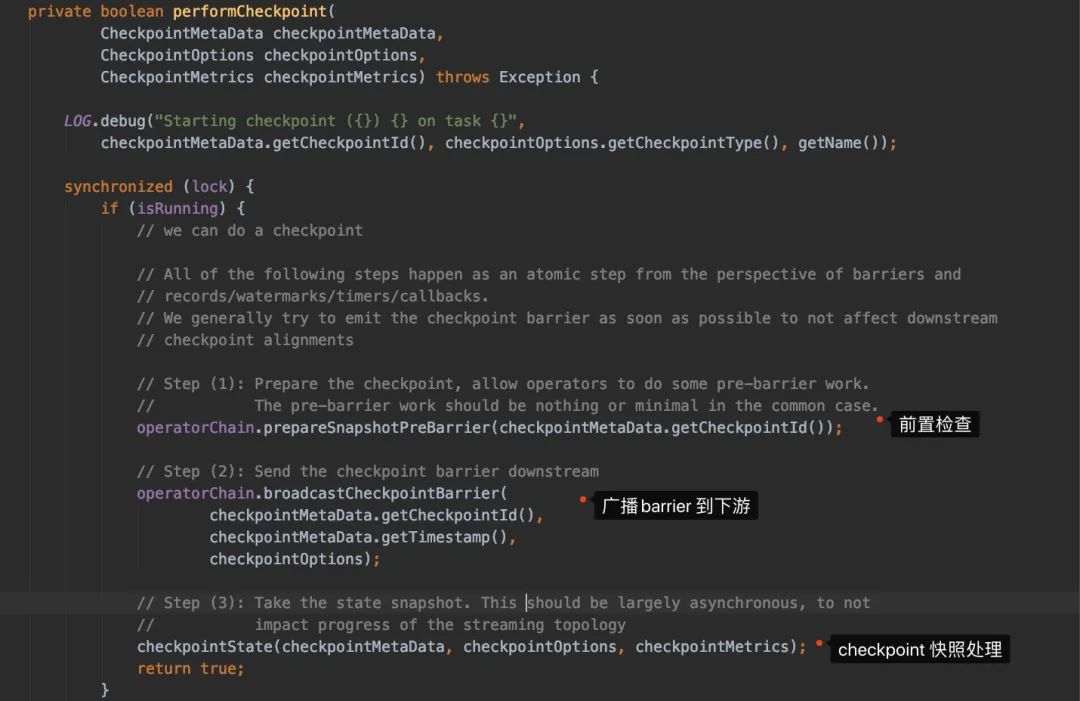
這塊我們先在這里放著,知道Source的任務(wù)接收到Checkpoint會廣播到下游,然后會做快照處理就好。
下面看看非Source 的任務(wù)接收到checkpoint是怎么處理的。
TaskManager(非source Task接收)
在上一篇《背壓原理》又或是這篇的基礎(chǔ)鋪墊上,其實我們可以看到在Flink接收數(shù)據(jù)用的是InputGate,所以我們還是回到org.apache.flink.streaming.runtime.io.StreamInputProcessor#processInput這個方法上
隨后定位到處理數(shù)據(jù)的邏輯:
final?BufferOrEvent?bufferOrEvent?=?barrierHandler.getNextNonBlocked();
想點擊進去,發(fā)現(xiàn)有兩個實現(xiàn)類:
BarrierBufferBarrierTracker

這兩個實現(xiàn)類其實就是對應著AT_LEAST_ONCE 和EXACTLY_ONCE這兩種模式。
/**
?*?The?BarrierTracker?keeps?track?of?what?checkpoint?barriers?have?been?received?from
?*?which?input?channels.?Once?it?has?observed?all?checkpoint?barriers?for?a?checkpoint?ID,
?*?it?notifies?its?listener?of?a?completed?checkpoint.
?*
?*?Unlike?the?{@link?BarrierBuffer},?the?BarrierTracker?does?not?block?the?input
?*?channels?that?have?sent?barriers,?so?it?cannot?be?used?to?gain?"exactly-once"?processing
?*?guarantees.?It?can,?however,?be?used?to?gain?"at?least?once"?processing?guarantees.
?*
?*?
NOTE:?This?implementation?strictly?assumes?that?newer?checkpoints?have?higher?checkpoint?IDs.
?*/
/**
?*?The?barrier?buffer?is?{@link?CheckpointBarrierHandler}?that?blocks?inputs?with?barriers?until
?*?all?inputs?have?received?the?barrier?for?a?given?checkpoint.
?*
?*?To?avoid?back-pressuring?the?input?streams?(which?may?cause?distributed?deadlocks),?the
?*?BarrierBuffer?continues?receiving?buffers?from?the?blocked?channels?and?stores?them?internally?until
?*?the?blocks?are?released.
?*/
簡單翻譯下就是:
BarrierTracker是at least once模式,只要inputChannel接收到barrier,就直接通知完成處理checkpointBarrierBuffer是exactly-once模式,當所有的inputChannel接收到barrier才通知完成處理checkpoint,如果有的inputChannel還沒接收到barrier,那已接收到barrier的inputChannel會讀數(shù)據(jù)到緩存中,直到所有的inputChannel都接收到barrier,這有可能會造成反壓。
說白了,就是BarrierBuffer會有對齊barrier的處理。
這里又提到exactly-once和at least once了。在文章開頭也說過Flink是可以實現(xiàn)exactly-once的,含義就是:狀態(tài)只持久化一次到最終的存儲介質(zhì)中(本地數(shù)據(jù)庫/HDFS)。
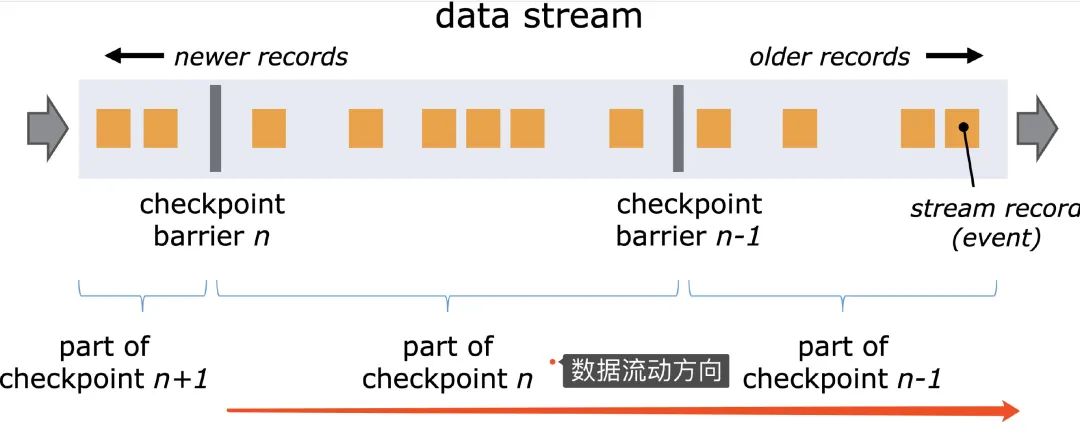
在這里我還是畫個圖和舉個例子配合BarrierBuffer/BarrierTracker來解釋一下。
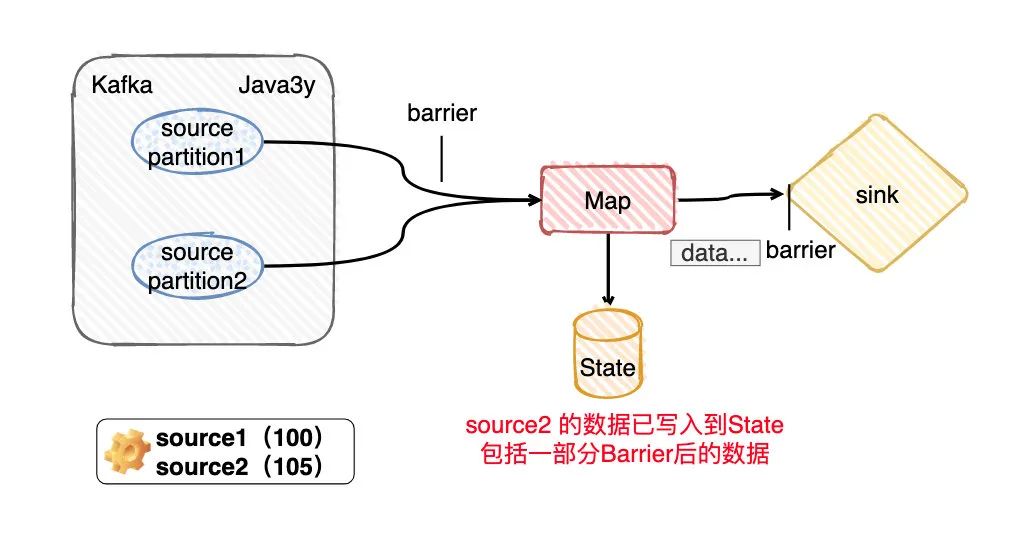
現(xiàn)在我有一個Topic,假定這個Topic有兩個分區(qū)partition(又或者你可以理解我設(shè)置消費的并行度是2)。現(xiàn)在要拉取Kafka這兩個分區(qū)的數(shù)據(jù),由算子Map進行消費轉(zhuǎn)換,期間在轉(zhuǎn)化的時候可能會存儲些信息到State(Flink給我們提供的存儲,你就當做是會存到HDFS上就好了),最終輸出到Sink。
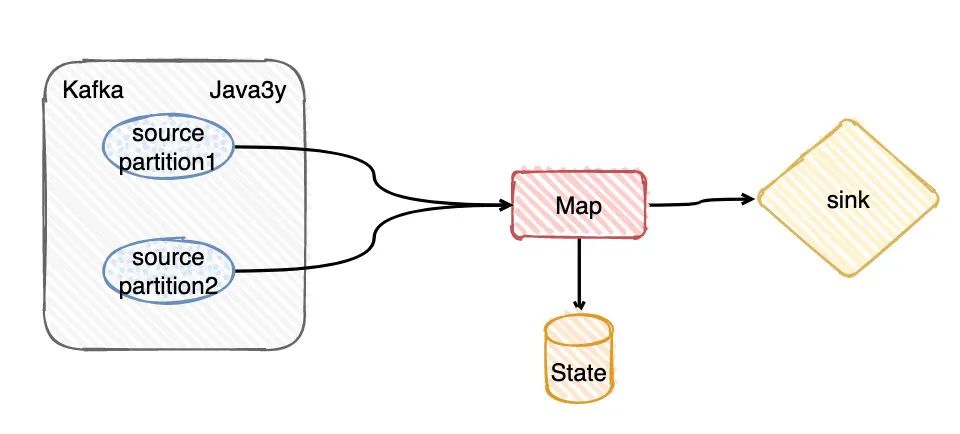
從上面的知識點我們應該可以知道, 在Flink做checkpoint的時候JobManager往每個Source任務(wù)(簡單對應圖上的兩個paritiion) 發(fā)送checkpointId,然后做快照存儲。
顯然,source任務(wù)存儲最主要的內(nèi)容就是消費分區(qū)的offset嘛。比如現(xiàn)在source 1的offerset是100,而source2的offset是105。
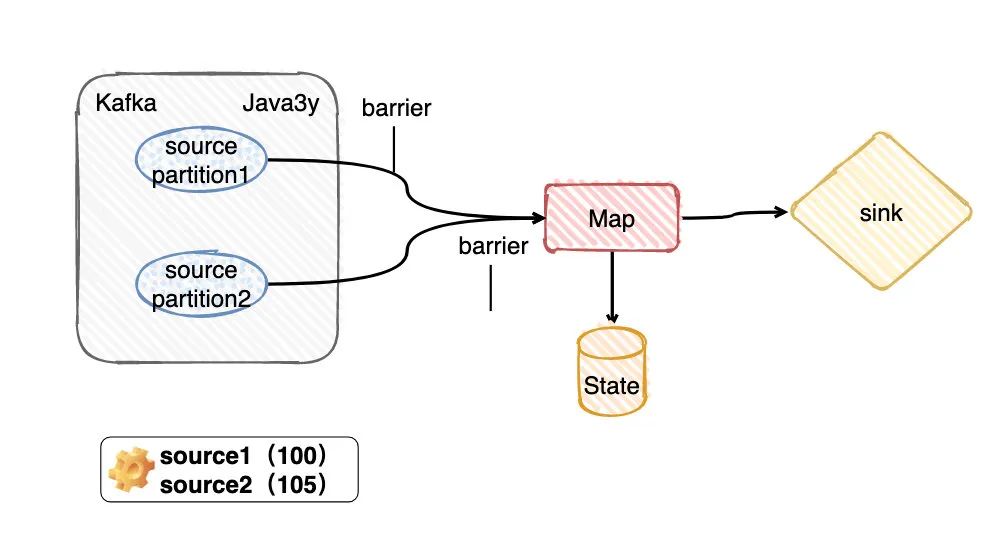
目前看來source2的數(shù)據(jù)會比source1的數(shù)據(jù)先到達Map
假定我們用的是BarrierBuffer exactly-once模式,那么source2的barrier到達Map算子的后,source2之后的數(shù)據(jù)只能停下來,放到buffer上,不做處理。等source1 的barrier來了以后,再真正處理source2放在buffer的數(shù)據(jù)。
這就是所謂的barrier對齊
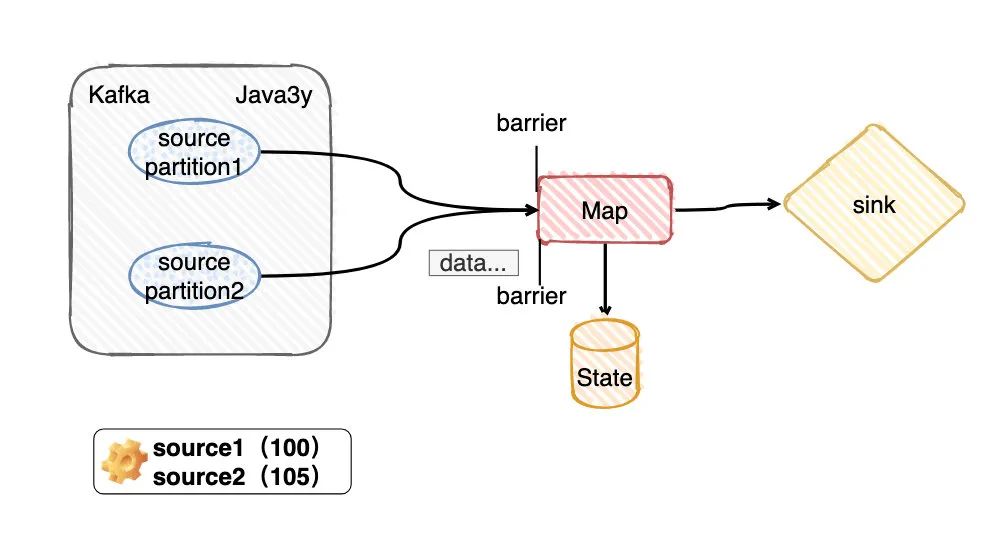
假定我們用的是BarrierTracker at least once模式,那么source2的barrier到達Map算子的后,source2之后的數(shù)據(jù)不會停下來等待source1,后面的數(shù)據(jù)會繼續(xù)處理。
現(xiàn)在問題就來了,那對不對齊的區(qū)別是什么呢?
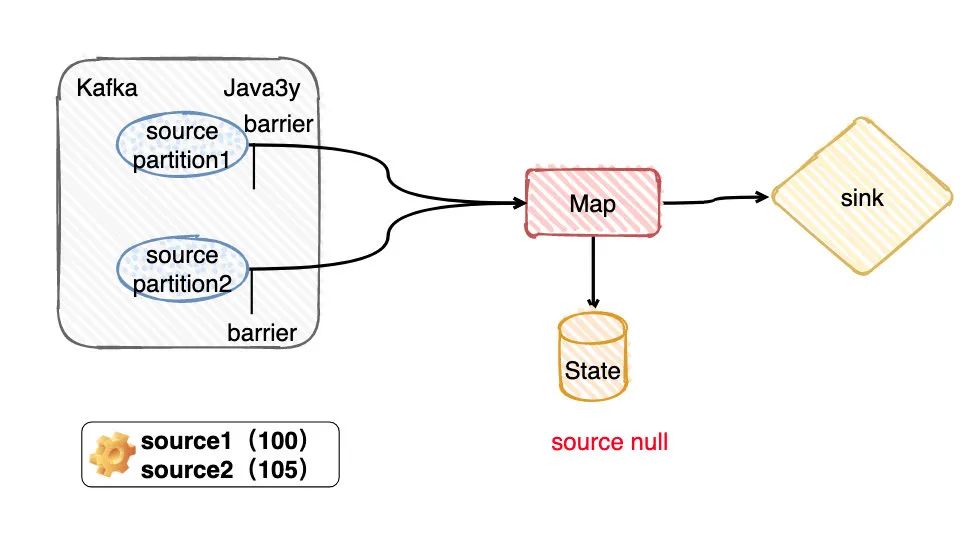
依照上面圖的的運行狀態(tài)(無論是BarrierTracker at least once模式還是BarrierBuffer exactly-once模式),現(xiàn)在我們的checkpoint都沒做,因為source1的barrier還沒到sink端呢。現(xiàn)在Flink掛了,那顯然會重新拉取source 1的offerset是小于100,而source2的offset是小于105的數(shù)據(jù),State的最終信息也不會保存。
checkpoint從沒做過的時候,對數(shù)據(jù)不會產(chǎn)生任何的影響(所以這里在Flink的內(nèi)部是沒啥區(qū)別的)
而假設(shè)我們現(xiàn)在是BarrierTracker at least once模式,沒有任何問題,程序繼續(xù)執(zhí)行。現(xiàn)在source1的barrier也走到了slink,最后完成了一次checkpoint。
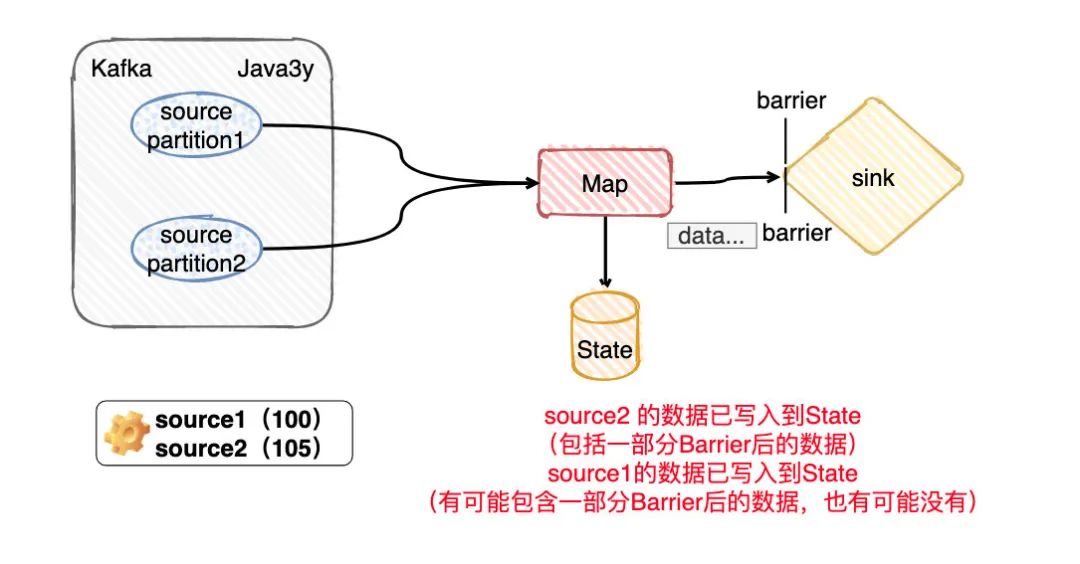
由于source2的barrier比source1的barrier要快,那么source1所處理的State的數(shù)據(jù)實際是包括offset>105的數(shù)據(jù)的,自然Flink保存的時候也會把這部分保存進去。
程序繼續(xù)運行,剛好保存完checkpoint后,此時系統(tǒng)出了問題,掛了。因為checkpoint已經(jīng)做完了,所以Flink會從source 1的offerset是100,而source2的offset是105重新消費。
但是,由于我們是BarrierTracker at least once模式,所以State里邊的保存狀態(tài)實際上有過source2的offset 大于105 的記錄了。那source2重新從offset是105開始消費,那就是會重復消費!

理解了上面所講的話,那再看BarrierBuffer exactly-once模式應該就不難理解了(各位大哥大嫂你也要經(jīng)過這個operator處理保存嗎?我們一起吧?有問題,我們一起重來,沒問題我們一起保存)
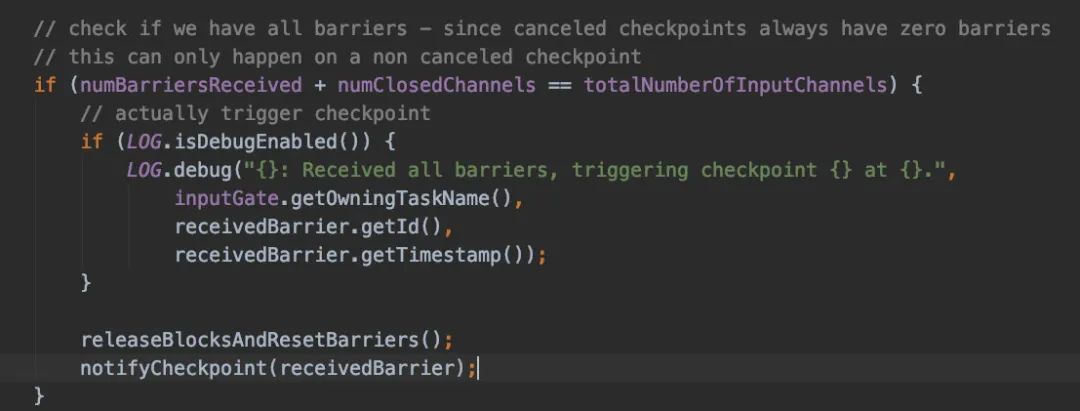
無論是BarrierTracker還是BarrierBuffer也好,在處理checkpoint的時候都需要調(diào)用notifyCheckpoint() 方法,而notifyCheckpoint()方法最終調(diào)用的是triggerCheckpointOnBarrier
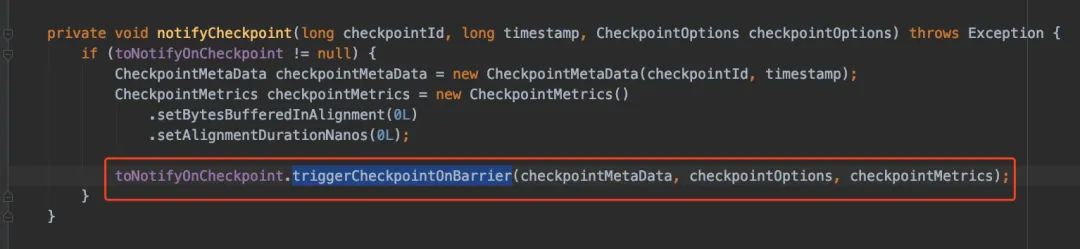
triggerCheckpointOnBarrier()最終還是會調(diào)用performCheckpoint()方法,所以無論是source接收到checkpoint還是operator接收到checkpoint,最終還是會調(diào)用performCheckpoint()方法。
大家有興趣可以進去checkpointState()方法里邊詳細看看,里邊會對State狀態(tài)信息進行寫入,完成后上報給TaskManager
TaskManager總結(jié)
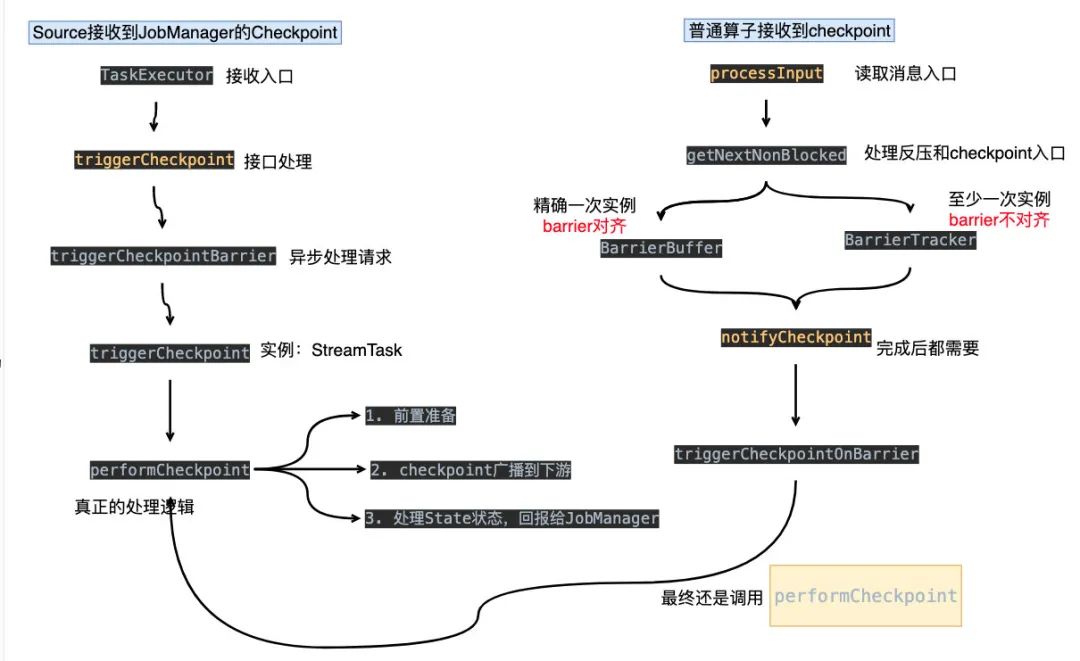
TaskExecutor接收到JobManager下發(fā)的checkpoint,由triggerCheckpoint方法進行處理triggerCheckpoint方法最終會調(diào)用org.apache.flink.streaming.runtime.tasks.StreamTask#triggerCheckpoint,而最主要的就是performCheckpoint方法performCheckpoint方法會對checkpoint做前置處理,barrier廣播到下游,處理State狀態(tài)做快照,最后回到成功消息給JobManager普通算子由 org.apache.flink.streaming.runtime.io.StreamInputProcessor#processInput這個方法讀取數(shù)據(jù),具體處理邏輯在getNextNonBlocked方法上。該方法有兩個實例,分別是 BarrierBuffer和BarrierTracker,這兩個實例對應著checkpoint不同的模式(至少一次和精確一次)。精確一次需要對barrier對齊,有可能導致反壓的情況最后處理完,會調(diào)用 notifyCheckpoint方法,實際上還是會調(diào)performCheckpoint方法
所以說,最終處理checkpoint的邏輯是一致的,只是會source會直接通過TaskExecutor處理,而普通算子會根據(jù)不同的配置在接收到后有不同的實例處理:BarrierTracker/BarrierBuffer。
JobManager接收回應
前面提到了,無論是source還是普通算子,都會調(diào)用performCheckpoint方法進行處理。
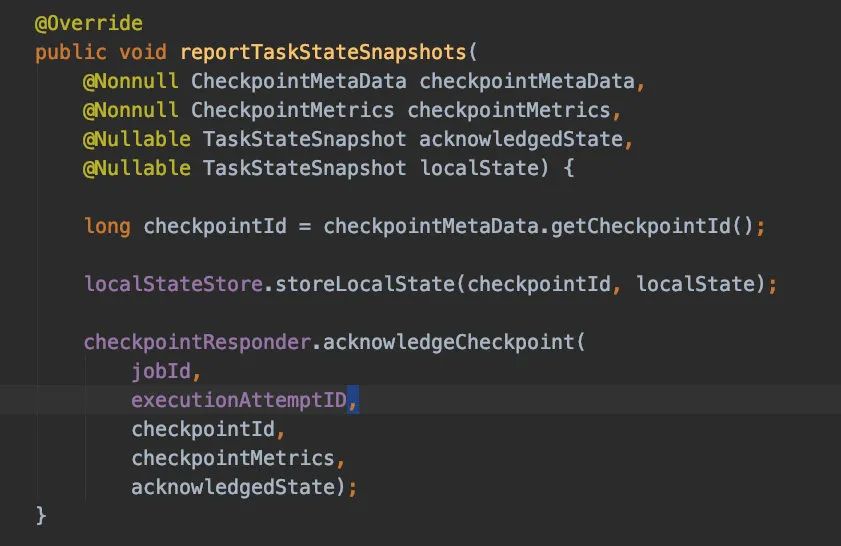
performCheckpoint方法里邊處理完State快照的邏輯,會調(diào)用reportCompletedSnapshotStates告訴JobManager快照已經(jīng)處理完了。
reportCompletedSnapshotStates方法里邊又會調(diào)用acknowledgeCheckpoint方法通過RPC去通知JobManager
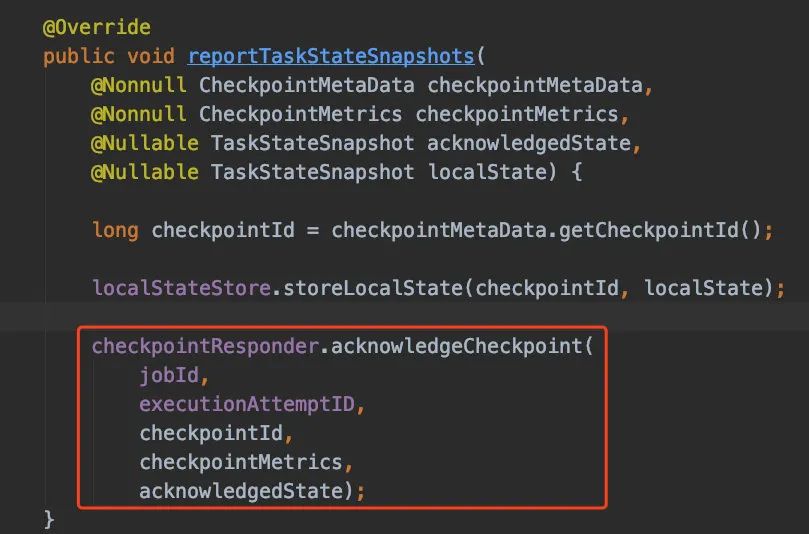
兜兜轉(zhuǎn)轉(zhuǎn),最后還是會回到checkpointCoordinator上,調(diào)用receiveAcknowledgeMessage進行處理
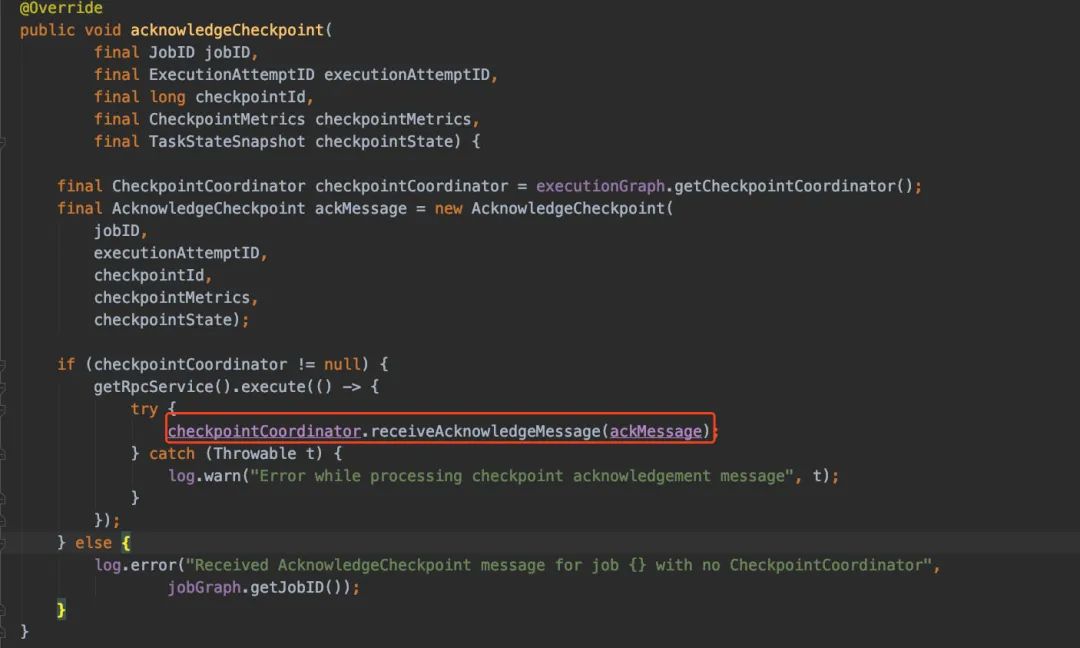
進入到receiveAcknowledgeMessage上,主要就是下面圖的邏輯:處理完返回不同的狀態(tài),根據(jù)不同的狀態(tài)進行處理
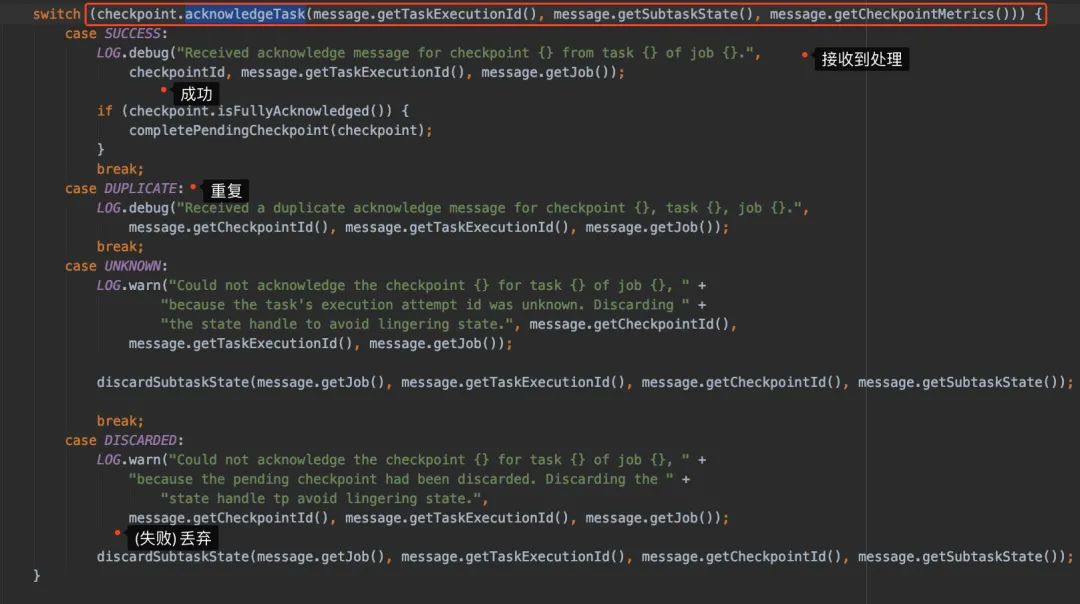
主要我們看的其實就是acknowledgeTask方法里邊做了些什么。
在 PendingCheckpoint維護了兩個Map:
//??已經(jīng)接收到?Ack?的算子的狀態(tài)句柄
private?final?Map?operatorStates;
//?需要?Ack?但還沒有接收到的?Task
private?final?Map?notYetAcknowledgedTasks;
然后我們進去acknowledgeTask簡單了解一下可以發(fā)現(xiàn)就是在處理operatorStates和notYetAcknowledgedTasks
synchronized?(lock)?{
???if?(discarded)?{
????return?TaskAcknowledgeResult.DISCARDED;
???}
???
????//?接收到Task了,從notYetAcknowledgedTasks移除
???final?ExecutionVertex?vertex?=?notYetAcknowledgedTasks.remove(executionAttemptId);
???if?(vertex?==?null)?{
????if?(acknowledgedTasks.contains(executionAttemptId))?{
?????return?TaskAcknowledgeResult.DUPLICATE;
????}?else?{
?????return?TaskAcknowledgeResult.UNKNOWN;
????}
???}?else?{
????acknowledgedTasks.add(executionAttemptId);
???}
????//?...
???if?(operatorSubtaskStates?!=?null)?{
????for?(OperatorID?operatorID?:?operatorIDs)?{
?????//?...
?????OperatorState?operatorState?=?operatorStates.get(operatorID);
?????//?新來的operatorID,添加到operatorStates
?????if?(operatorState?==?null)?{
??????operatorState?=?new?OperatorState(
???????operatorID,
???????vertex.getTotalNumberOfParallelSubtasks(),
???????vertex.getMaxParallelism());
??????operatorStates.put(operatorID,?operatorState);
?????}
??????????//....
????}
???}
等到所有的Task都到齊以后,就會調(diào)用isFullyAcknowledged進行處理。

最后調(diào)用completedCheckpoint = pendingCheckpoint.finalizeCheckpoint();來實現(xiàn)最終的存儲,所有完畢以后會通知所有的Task 現(xiàn)在checkpoint已經(jīng)完成了。
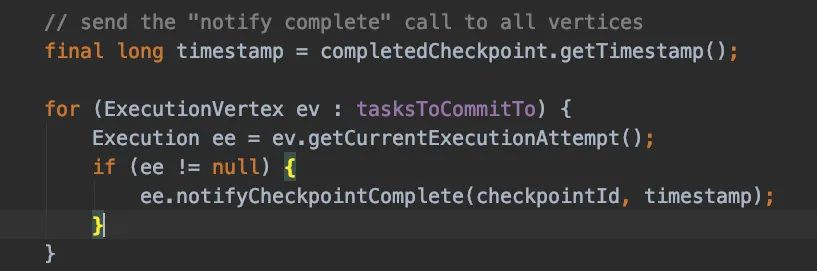
最后
總的來說,這篇文章帶著大家走馬觀花擼了下Checkpoint,很多細節(jié)我也沒去深入,但我認為這篇文章可以讓你大概了解到Checkpoint的實現(xiàn)過程。
最后再來看看官網(wǎng)的圖,看完應該大概就能看得懂啦:
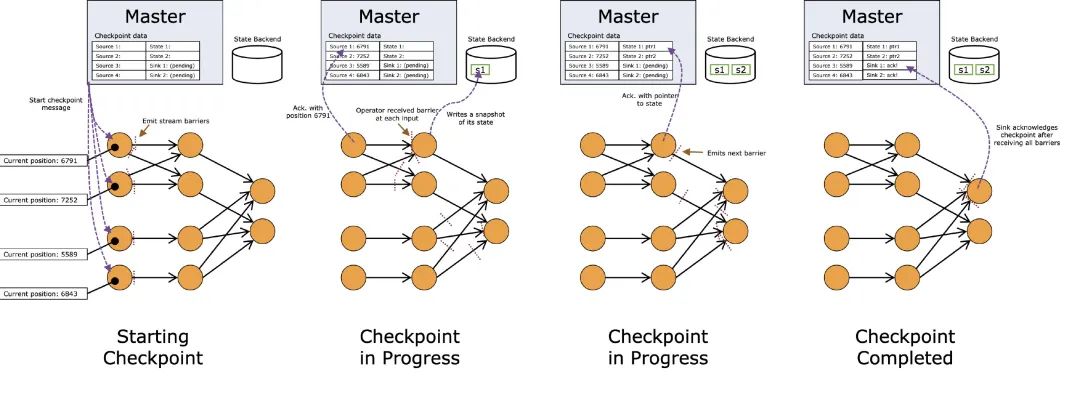
相信我,或許你現(xiàn)在還沒用到Flink,但等你真正去用Flink的時候,checkpoint是肯定得搞搞的(:現(xiàn)在可能有的同學還沒看懂,沒關(guān)系,先點個贊??,收藏起來,后面就用得上了。
參考資料:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/concepts/stateful-stream-processing.html https://blog.csdn.net/weixin_40809627/category_9631155.html https://www.jianshu.com/p/4d31d6cddc99 https://www.jianshu.com/p/d2fb32ba2c9b
三歪老婆會了嗎?