
flink超越Spark的Checkpoint機(jī)制

Apache Flink提供容錯(cuò)機(jī)制,以持續(xù)恢復(fù)數(shù)據(jù)流應(yīng)用程序的狀態(tài)。該機(jī)制確保即使存在故障,程序的每條消息只會(huì)作用于狀態(tài)一次(exactly-once),當(dāng)然也可以降級(jí)為至少一次(at-least-once)。
容錯(cuò)機(jī)制持續(xù)地制作分布式流數(shù)據(jù)流的快照。對(duì)于狀態(tài)較小的流應(yīng)用程序,這些快照非常輕量級(jí),可以頻繁產(chǎn)生快照,而不會(huì)對(duì)性能產(chǎn)生太大影響。流應(yīng)用程序的狀態(tài)存儲(chǔ)的位置是可以配置的(例如存儲(chǔ)在master節(jié)點(diǎn)或HDFS)。
如果程序失敗(由于機(jī)器,網(wǎng)絡(luò)或軟件故障),F(xiàn)link任務(wù)掛掉,然后利用最近一次成功的checkpoint恢復(fù)算子的狀態(tài)。輸入流將重置為狀態(tài)快照消息的位置。
注意:默認(rèn)情況下,禁用checkpoint。
注意:要使容錯(cuò)機(jī)制完整,數(shù)據(jù)源(如消息隊(duì)列或者broker)要支持?jǐn)?shù)據(jù)回滾到歷史消息的位置。Apache Kafka具有這種能力,F(xiàn)link與Kafka的連接器利用了該功能。
注意:由于Flink的checkpoint是通過(guò)分布式快照實(shí)現(xiàn)的,因此快照和checkpoint的概念可以互換使用。
Flink分布式快照的核心概念之一是barriers。這些barriers被注入數(shù)據(jù)流并與消息一起作為數(shù)據(jù)流的一部分向下流動(dòng)。barriers永遠(yuǎn)不會(huì)超過(guò)前面的消息,數(shù)據(jù)流嚴(yán)格有序。barriers將數(shù)據(jù)流中的消息分為進(jìn)入當(dāng)前快照的消息和進(jìn)入下一個(gè)快照的消息。每個(gè)barriers都帶有快照的ID,并且barriers之前的消息都進(jìn)入了該快照。barriers不會(huì)中斷消息流的流動(dòng),非常輕量級(jí)。來(lái)自不同快照的多個(gè)barriers可以同時(shí)在流中出現(xiàn),這意味著可以同時(shí)發(fā)生各種快照。
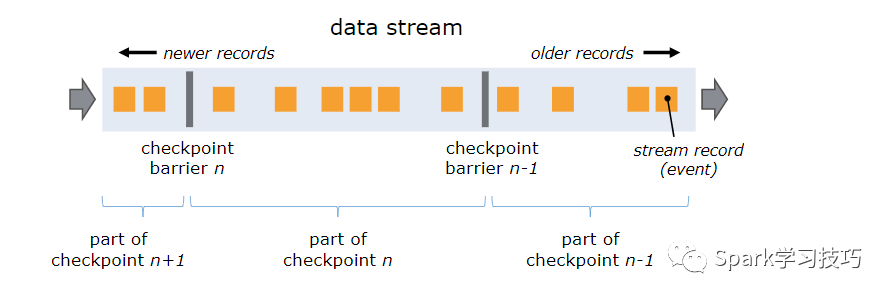
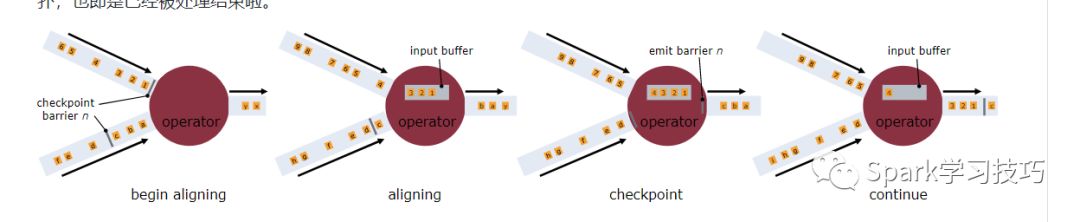
一旦操作算子從一個(gè)輸入流接收到快照barriers n,它就不能處理來(lái)自該流的任何消息,直到它接收到其他輸入算子barriers n為止。否則,它會(huì)搞混屬于快照n的消息和屬于快照n + 1的消息。 barriers n所屬的流暫時(shí)會(huì)被擱置。從這些流接收的消息不會(huì)被處理,而是放入輸入緩沖區(qū)。 一旦從最后一個(gè)流接收到barriers n,操作算子就會(huì)發(fā)出所有掛起的向后傳送的消息,然后自己發(fā)出快照n的barriers。 之后,它恢復(fù)處理來(lái)自所有輸入流的消息,在處理來(lái)自流的消息之前優(yōu)先處理來(lái)自輸入緩沖區(qū)的消息。
當(dāng)運(yùn)算符包含任何形式的狀態(tài)時(shí),此狀態(tài)也必須是快照的一部分。操作算子狀態(tài)有不同的形式:
用戶定義的狀態(tài):這是由轉(zhuǎn)換函數(shù)(如map()或filter())直接創(chuàng)建和修改的狀態(tài)。
系統(tǒng)狀態(tài):此狀態(tài)是指作為運(yùn)算符計(jì)算一部分的數(shù)據(jù)緩沖區(qū)。此狀態(tài)的典型示例是窗口緩沖區(qū),系統(tǒng)在其中收集(和聚合)窗口里的消息,直到窗口被計(jì)算和拋棄。
操作算子在他們從輸入流接收到所有快照barriers時(shí),以及在向其輸出流發(fā)出barriers之前,會(huì)對(duì)其狀態(tài)進(jìn)行寫(xiě)快照。此時(shí),在 barrier 之前的數(shù)據(jù)對(duì)狀態(tài)的更新已經(jīng)完成,barrier 之后的數(shù)據(jù)不會(huì)更新?tīng)顟B(tài)。由于快照的狀態(tài)可能很大,因此它存儲(chǔ)在可配置的狀態(tài)后端中。默認(rèn)情況下,是存儲(chǔ)到JobManager的內(nèi)存,但對(duì)于生產(chǎn)使用,應(yīng)配置分布式可靠存儲(chǔ)(例如HDFS)。在存儲(chǔ)狀態(tài)之后,操作算子確認(rèn)checkpoint完成,將快照barriers發(fā)送到輸出流中,然后繼續(xù)。
生成的快照現(xiàn)在包含:
對(duì)于每個(gè)并行流數(shù)據(jù)源,創(chuàng)建快照時(shí)流中的偏移/位置
對(duì)于每個(gè)運(yùn)算符,存儲(chǔ)在快照中的狀態(tài)指針

對(duì)齊步驟可能增加流式程序的等待時(shí)間。通常,這種額外的延遲大約為幾毫秒,但也會(huì)見(jiàn)到一些延遲顯著增加的情況。對(duì)于要求所有消息始終具有超低延遲(幾毫秒)的應(yīng)用程序,F(xiàn)link可以在checkpoint期間跳過(guò)流對(duì)齊。一旦操作算子看到每個(gè)輸入流的checkpoint barriers,就會(huì)寫(xiě) checkpoint 快照。
當(dāng)跳過(guò)對(duì)齊時(shí),即使在 checkpoint n 的某些 checkpoint barriers 到達(dá)之后,操作算子仍繼續(xù)處理所有輸入。這樣,操作算子還可以在創(chuàng)建 checkpoint n 的狀態(tài)快照之前,繼續(xù)處理屬于checkpoint n + 1的數(shù)據(jù)。在還原時(shí),這些消息將作為重復(fù)消息出現(xiàn),因?yàn)樗鼈兌及?checkpoint n 的狀態(tài)快照中,并將作為 checkpoint n 之后數(shù)據(jù)的一部分進(jìn)行重復(fù)處理。
注意:對(duì)齊僅適用于具有多個(gè)輸入(join)的運(yùn)算符以及具有多個(gè)輸出的運(yùn)算符(在流重新分區(qū)/shuffle之后)。正因?yàn)槿绱耍瑢?duì)于只有map(),flatMap(),filter()等操作,實(shí)際上即使在至少一次模式下也能提供一次保證。
注意,上述機(jī)制意味著操作算子在將狀態(tài)的快照存儲(chǔ)在狀態(tài)后端時(shí),停止處理輸入消息。每次寫(xiě)快照時(shí),這種同步狀態(tài)快照操作都會(huì)引入延遲。
可以讓操作算子在存儲(chǔ)狀態(tài)快照時(shí)繼續(xù)處理,高效地讓狀態(tài)快照存儲(chǔ)在后臺(tái)異步發(fā)生。為此,操作算子必須能夠生成一個(gè)狀態(tài)對(duì)象,該狀態(tài)對(duì)象應(yīng)以某種方式存儲(chǔ),以便對(duì)操作算子狀態(tài)的進(jìn)一步修改不會(huì)影響該狀態(tài)對(duì)象。例如,RocksDB中使用的寫(xiě)時(shí)復(fù)制(copy-on-write)數(shù)據(jù)結(jié)構(gòu)具有這種能力。
在接收到輸入的checkpoint的barriers后,操作算子啟動(dòng)其狀態(tài)的異步快照復(fù)制。它立即釋放其barriers到輸出,并繼續(xù)進(jìn)行常規(guī)流處理。后臺(tái)復(fù)制過(guò)程完成后,它會(huì)向checkpoint協(xié)調(diào)器(JobManager)確認(rèn)checkpoint完成。checkpoint僅在所有sink都已收到barriers并且所有有狀態(tài)操作算子已確認(rèn)其完成備份(可能在barriers到達(dá)sink之后)之后才算完成。
在創(chuàng)建操作算子快照時(shí),有兩部分:同步部分和異步部分。
操作算子和狀態(tài)后端將其快照提供為Java FutureTask。該任務(wù)包含同步部分已完成且異步部分處于掛起狀態(tài)的狀態(tài)。然后,異步部分由該checkpoint的后臺(tái)線程執(zhí)行。
完全同步的checkpoint返回已經(jīng)完成的FutureTask的運(yùn)算符。如果需要執(zhí)行異步操作,則在FutureTask的run()方法中執(zhí)行。
任務(wù)是可取消的,可以釋放流和其他資源消耗的句柄。
推薦閱讀:
1.干貨:Flink+Kafka 0.11端到端精確一次處理語(yǔ)義實(shí)現(xiàn)