
認(rèn)真的聊一聊決策樹和隨機(jī)森林
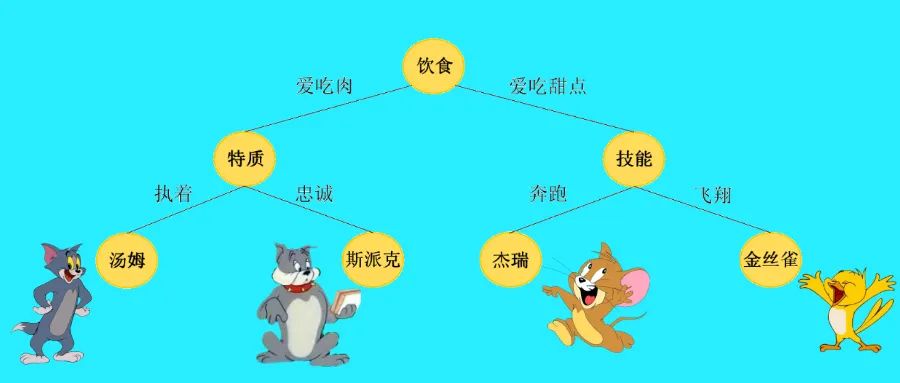
隨機(jī)森林是一種簡單又實(shí)用的機(jī)器學(xué)習(xí)集成算法。
“隨機(jī)“表示2種隨機(jī)性,即每棵樹的訓(xùn)練樣本、訓(xùn)練特征隨機(jī)選取。
多棵決策樹組成了一片“森林”,計(jì)算時(shí)由每棵樹投票或取均值的方式來決定最終結(jié)果,體現(xiàn)了三個(gè)臭皮匠頂個(gè)諸葛亮的中國傳統(tǒng)民間智慧。
那我們該如何理解決策樹和這種集成思想呢?
01 決策樹
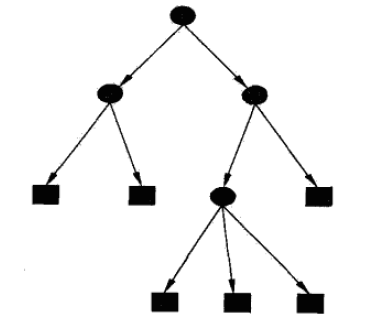
以分類任務(wù)為代表的決策樹模型,是一種對(duì)樣本特征構(gòu)建不同分支的樹形結(jié)構(gòu)。
決策樹由節(jié)點(diǎn)和有向邊組成,其中節(jié)點(diǎn)包括內(nèi)部節(jié)點(diǎn)(圓)和葉節(jié)點(diǎn)(方框)。內(nèi)部節(jié)點(diǎn)表示一個(gè)特征或?qū)傩裕~節(jié)點(diǎn)表示一個(gè)具體類別。
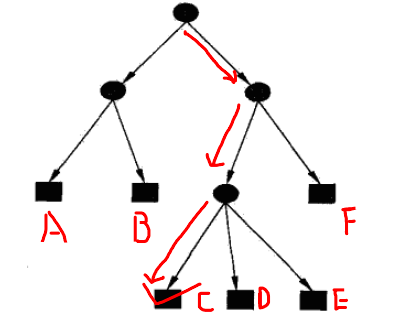
預(yù)測時(shí),從最頂端的根節(jié)點(diǎn)開始向下搜索,直到某一個(gè)葉子節(jié)點(diǎn)結(jié)束。下圖的紅線代表了一條搜索路線,決策樹最終輸出類別C。
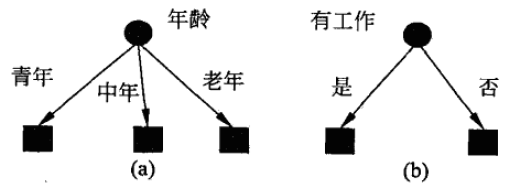
決策樹的特征選擇
假如有為青年張三想創(chuàng)業(yè),但是摸摸口袋空空如也,只好去銀行貸款。
銀行會(huì)綜合考量多個(gè)因素來決定張三是不是一個(gè)騙子,是否給他放貸。例如,可以考慮的因素有性別、年齡、工作、是否有房、信用情況、婚姻狀況等等。
這么多因素,哪些是重要的呢?
這就是特征選擇的工作。特征選擇可以判別出哪些特征最具有區(qū)分力度(例如“信用情況”),哪些特征可以忽略(例如“性別”)。特征選擇是構(gòu)造決策樹的理論依據(jù)。
不同的特征選擇,生成了不同的決策樹。
決策樹的特征選擇一般有3種量化方法:信息增益、信息增益率、基尼指數(shù)。
信息增益
在信息論中,熵表示隨機(jī)變量不確定性的度量。假設(shè)隨機(jī)變量X有有限個(gè)取值,取值?
?
如果某件事一定發(fā)生(太陽東升西落)或一定不發(fā)生(釣魚島是日本的),則概率為1或0,對(duì)應(yīng)的熵均為0。
如果某件事可能發(fā)生可能不發(fā)生(天要下雨,娘要嫁人),概率介于0到1之間,熵大于0。
由此可見,熵越大,隨機(jī)性越大,結(jié)果越不確定。
我們再來看一看條件熵?
明確了這兩個(gè)概念,理解信息增益就比較方便了。現(xiàn)在我們有一份數(shù)據(jù)集D(例如貸款信息登記表)和特征A(例如年齡),則A的信息增益就是D本身的熵與特征A給定條件下D的條件熵之差,即:
?
數(shù)據(jù)集D的熵是一個(gè)常量。信息增益越大,表示條件熵?
所以要優(yōu)先選擇信息增益大的特征,它們具有更強(qiáng)的分類能力。由此生成決策樹,稱為ID3算法。
信息增益率
當(dāng)某個(gè)特征具有多種候選值時(shí),信息增益容易偏大,造成誤差。引入信息增益率可以校正這一問題。
信息增益率?
?
同樣,我們優(yōu)先選擇信息增益率最大的特征,由此生成決策樹,稱為C4.5算法。
基尼指數(shù)
基尼指數(shù)是另一種衡量不確定性的指標(biāo)。
假設(shè)數(shù)據(jù)集D有K個(gè)類,樣本屬于第K類的概率為?
?
其中?
如果數(shù)據(jù)集D根據(jù)特征A是否取某一可能值a被分割成?
?
容易證明基尼指數(shù)越大,樣本的不確定性也越大,特征A的區(qū)分度越差。
我們優(yōu)先選擇基尼指數(shù)最小的特征,由此生成決策樹,稱為CART算法。
決策樹剪枝
決策樹生成算法遞歸產(chǎn)生一棵決策樹,直到結(jié)束劃分。什么時(shí)候結(jié)束呢?
樣本屬于同一種類型 沒有特征可以分割
這樣得到的決策樹往往對(duì)訓(xùn)練數(shù)據(jù)分類非常精準(zhǔn),但是對(duì)于未知數(shù)據(jù)表現(xiàn)比較差。
原因在于基于訓(xùn)練集構(gòu)造的決策樹過于復(fù)雜,產(chǎn)生過擬合。所以需要對(duì)決策樹簡化,砍掉多余的分支,提高泛化能力。
決策樹剪枝一般有兩種方法:
預(yù)剪枝:在樹的生成過程中剪枝。基于貪心策略,可能造成局部最優(yōu) 后剪枝:等樹全部生成后剪枝。運(yùn)算量較大,但是比較精準(zhǔn)
決策樹剪枝往往通過極小化決策樹整體的損失函數(shù)實(shí)現(xiàn)。
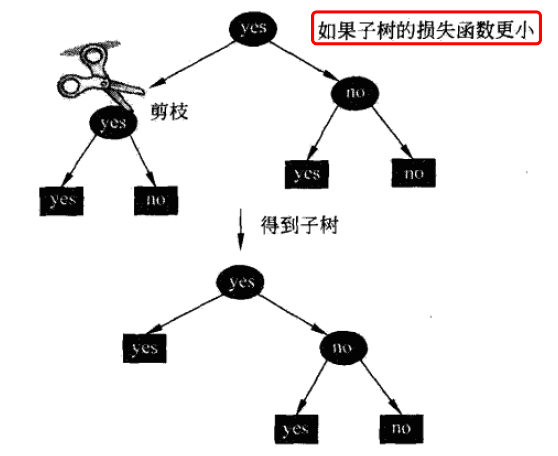
假設(shè)樹T有|T|個(gè)葉子節(jié)點(diǎn),某一個(gè)葉子節(jié)點(diǎn)t上有?
?
?
其中熵為:
?
損失函數(shù)第一項(xiàng)為訓(xùn)練誤差,第二項(xiàng)為模型復(fù)雜度,用參數(shù)?
CART算法
CART表示分類回歸決策樹,同樣由特征選擇、樹的生成及剪枝組成,可以處理分類和回歸任務(wù)。
相比之下,ID3和C4.5算法只能處理分類任務(wù)。
CART假設(shè)決策樹是二叉樹,內(nèi)部結(jié)點(diǎn)特征的取值為“是”和“否”,依次遞歸地二分每個(gè)特征。
CART 對(duì)回歸樹采用平方誤差最小化準(zhǔn)則,對(duì)分類樹用基尼指數(shù)最小化準(zhǔn)則。
02 bagging集成
機(jī)器學(xué)習(xí)算法中有兩類典型的集成思想:bagging和bossting。
bagging是一種在原始數(shù)據(jù)集上,通過有放回抽樣分別選出k個(gè)新數(shù)據(jù)集,來訓(xùn)練分類器的集成算法。分類器之間沒有依賴關(guān)系。
隨機(jī)森林屬于bagging算法。通過組合多個(gè)弱分類器,集思廣益,使得整體模型具有較高的精確度和泛化性能。
03?隨機(jī)森林
我們將使用CART決策樹作為弱學(xué)習(xí)器的bagging方法稱為隨機(jī)森林。
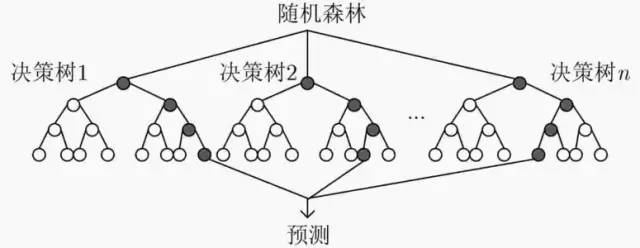
由于隨機(jī)性,隨機(jī)森林對(duì)于降低模型方差效果顯著。故隨機(jī)森林一般不需要額外剪枝,就能取得較好的泛化性能。
相對(duì)而言,模型對(duì)于訓(xùn)練集的擬合程度就會(huì)差一些,相比于基于boosting的GBDT模型,偏差會(huì)大一些。
另外,隨機(jī)森林中的樹一般會(huì)比較深,以盡可能地降低偏差;而GBDT樹的深度會(huì)比較淺,通過減少模型復(fù)雜度來降低方差。(面試考點(diǎn))
最后,我們總結(jié)一下隨機(jī)森林都有哪些優(yōu)點(diǎn):
采用了集成算法,精度優(yōu)于大多數(shù)單模型算法 在測試集上表現(xiàn)良好,兩個(gè)隨機(jī)性的引入降低了過擬合風(fēng)險(xiǎn) 樹的組合可以讓隨機(jī)森林處理非線性數(shù)據(jù) 訓(xùn)練過程中能檢測特征重要性,是常見的特征篩選方法 每棵樹可以同時(shí)生成,并行效率高,訓(xùn)練速度快 可以自動(dòng)處理缺省值
推? 薦? 閱? 讀
2021-01-18

2021-01-19

2021-01-26


參考資料
https://www.jianshu.com/p/a779f0686acc
原創(chuàng)不易,有收獲的話請(qǐng)幫忙點(diǎn)擊分享、點(diǎn)贊、在看吧??