NAS在檢測中的應(yīng)用

極市導(dǎo)讀
?本文主要介紹將NAS用于detection上,作者以NAS-FPN作為開場,陸續(xù)介紹了EfficientDet、SpineNet、CRNAS。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
一. NAS-FPN????????????
這篇文章里使用RNN Controller來做NAS,以前看[1]、[2]時留了一些疑問,所以就在這先說說RNN控制器。
RNN-Controller:最早的NAS文章[1]中,強化學(xué)習(xí)模型的主體是RNN結(jié)構(gòu),用來做序列處理。那么如何采樣到狀態(tài)轉(zhuǎn)換序列呢?很簡單,先初始化一個RNN,begin token做輸入送入RNN輸出第一層結(jié)構(gòu),第一層結(jié)構(gòu)做輸入送入RNN輸出第二層結(jié)構(gòu)......就這樣先在一個eposide期間得到整個網(wǎng)絡(luò)結(jié)構(gòu),重復(fù)采樣多個eposide,就可以采樣到多個? ?序列,這個r是怎么得到了呢?就是一個eposide采樣得到的整個網(wǎng)絡(luò)的精度,有了精度作為回報就可以更新RNN了。
?序列,這個r是怎么得到了呢?就是一個eposide采樣得到的整個網(wǎng)絡(luò)的精度,有了精度作為回報就可以更新RNN了。
在之后的NAS文章[2]中,不對整個模型做搜索,而是去搜索網(wǎng)絡(luò)的基本Cell,然后將搜索得到的Cell堆疊起來構(gòu)成網(wǎng)絡(luò)的整體結(jié)構(gòu),更具體的,每個Cell有更細致的微結(jié)構(gòu)。從大的層面來看,Normal Cell和Reduction Cell都接受兩個輸入? ?和?
?和? ?。在生成Cell結(jié)構(gòu)的過程中,論文巧妙的將其遞歸的分成幾步,每一步的操作都是一樣的。具體的,生成Normal Cell和Reduction Cell的過程,就是將下面的過程重復(fù)B次,先驗條件下,B=5。步驟如下:
?。在生成Cell結(jié)構(gòu)的過程中,論文巧妙的將其遞歸的分成幾步,每一步的操作都是一樣的。具體的,生成Normal Cell和Reduction Cell的過程,就是將下面的過程重復(fù)B次,先驗條件下,B=5。步驟如下:
從?
?和??或上一步中得到的隱含狀態(tài)中選擇一個作為輸入一。從?
?和??或上一步中得到的隱含狀態(tài)中選擇一個作為輸入二。(可以與第一個一樣)從操作集合中選擇一個操作應(yīng)用在輸入一上。
從操作集合中選擇一個操作應(yīng)用在輸入二上。
選擇一個方法將第三步和第四步的結(jié)果合并。
這時的NAS如何采樣到狀態(tài)轉(zhuǎn)換序列?
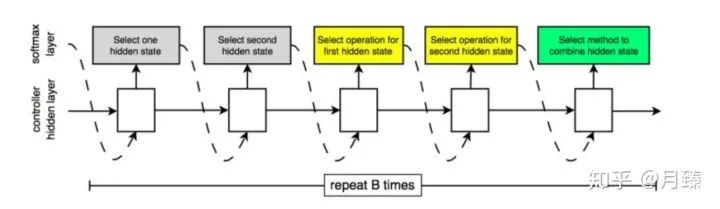
RNN的每步輸出可以是不同種類的信息,什么意思呢?從上圖可以看出來,采樣仍然是分步采樣的,即softmax layer作為RNN的輸入輸出第一個選擇的隱含狀態(tài),第一個選擇的隱含狀態(tài)作為輸入輸出第二個選擇的隱含狀態(tài)......這里可能就存在一個問題輸入和輸出的集合不是同一個集合,但是即使操作集合和狀態(tài)集合不一樣大,也不影響將狀態(tài)或者操作通過詞嵌入映射到同一維度;反之,輸出時也不影響將同一緯度的東西映射成不同維度的probability vector來回到操作集合或者狀態(tài)集合。
二. EfficientDet
之前已經(jīng)有很多的工作設(shè)計更加高效的檢測器結(jié)構(gòu)(比如one-stage或者anchor-free的檢測器、對現(xiàn)有結(jié)構(gòu)進行壓縮),但這些方法大都以獲得更高的效率為目標(biāo)而對精度有損,同時只針對特定的硬件約束無法充分利用實時變化的資源限制。因此就有了一個很自然的問題:有沒有可能構(gòu)建一個效率和精度更高的可擴展的檢測器結(jié)構(gòu),同時可以縮放模型來應(yīng)對不同的資源限制?基于one-stage的檢測器結(jié)構(gòu)組成,作者重新審視了backbone、neck(論文中的FPN部分)、head(論文中的class/box網(wǎng)絡(luò)),確定了兩個主要挑戰(zhàn):
Challenge 1:高效的多尺度特征融合——之前從FPN、PANet、NAS-FPN中已經(jīng)介紹了各種進行跨尺度特征融合的網(wǎng)絡(luò)結(jié)構(gòu),它們都有一個共同點:當(dāng)融合不同分辨率的輸入特征時,都是簡單地將它們進行相加。然而由于分辨率不同它們對于融合后的特征的貢獻應(yīng)該是不等價的,為了解決這個問題,作者提出了一種簡單而高效的加權(quán)雙向特征金字塔網(wǎng)絡(luò)(BiFPN),它對不同分辨率的輸入特征引入不同的加權(quán)值,同時應(yīng)用了top-down和bottom-up的特征融合;
Challenge 2:模型縮放——之前的方法中通常會采用更大的backbone或者更大的輸入圖片來提高檢測精度,我們觀察到當(dāng)將高效性和精度同時考慮在內(nèi)的話,縮放特征網(wǎng)絡(luò)和box/class網(wǎng)絡(luò)同樣很重要。受到EfficientNet的啟發(fā),因此作者提出了一種復(fù)合縮放方法,它可以對所有的backbone、feature network、box/class prediction network同時做resolution/width/depth上的聯(lián)合縮放;
以EfficientNet為backbone,結(jié)合BiFPN和復(fù)合縮放方法,作者提出了EfficientDet[4]——一種可擴展式的檢測器。
1. BiFPN
在本節(jié),作者先公式化了多尺度的特征融合問題,然后為BiFPN引入了兩個核心觀點:高效的雙向跨尺度連接和加權(quán)特征融合。
1.1 Problem Formulation
多尺度特征融合旨在融合不同分辨率的特征。給定一組輸入特征? ?,這里的?
?,這里的? ?指的是在?
?指的是在? ?等級的特征,其特征分辨率為 input resolution/?
?等級的特征,其特征分辨率為 input resolution/? ?,我們的目標(biāo)是找到一個轉(zhuǎn)換函數(shù)f來高效地融合不同的特征,輸出一組新特征:?
?,我們的目標(biāo)是找到一個轉(zhuǎn)換函數(shù)f來高效地融合不同的特征,輸出一組新特征:? ?。
?。
以Figure 2(a)中FPN的特征融合為例,它的輸出為:

1.2 Cross-Scale Connections
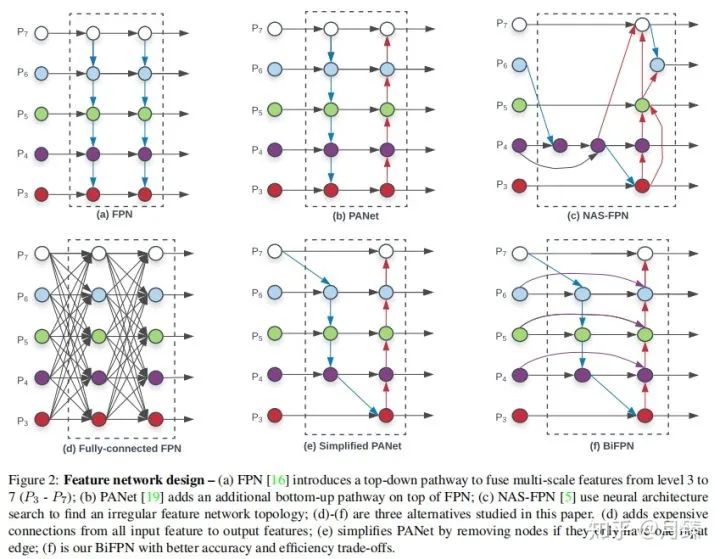
和RetinaNet設(shè)置一樣,也是采用了P3-P7作為neck的特征融合層。作者通過這幾個簡化圖清楚地展示了思考過程,(a)是原始FPN特征融合,通過top-down支路增加了大特征圖的高層語義信息,提高了小物體的檢測精度,但同時使得頂層的特征優(yōu)化的沒有以前好,大物體的檢測精度比較低;(b)在(a)的基礎(chǔ)上加上了bottom-up特征融合,使得頂層特征的細節(jié)信息變得更多了;(c)通過NAS搜索的特征融合方式。
通過研究FPN、PANet和NAS-FPN的性能,作者發(fā)現(xiàn)PANet比其他兩個的表現(xiàn)要好,但是它的計算成本也更加昂貴,所以為了提高模型的效率,作者從NAS-FPN中的設(shè)計中獲取靈感來對PANet進行改進,做了以下優(yōu)化:
首先,移除只有一條輸入邊的節(jié)點,因為從直覺上這樣的節(jié)點對網(wǎng)絡(luò)特征融合貢獻的小,即(b)變成了(e);
第二點,如果輸出節(jié)點和輸入節(jié)點在同一個等級,在它們之間條件一條邊,(e)變成了(f)
最后,不像PANet只有一條top-down和botton-up路徑,在這里可以重復(fù)堆疊這樣的路徑來獲取更高級的特征;
1.3 Weighted Feature Fusion
不同層對最終融合的特征影響實際上是不同的,但是RetinaNet采用的是直接相加進行融合,當(dāng)然更理想的情況是可以自適應(yīng)地進行加權(quán)求和。最直接的就是引入可學(xué)習(xí)的權(quán)重就好了。基于這個想法,考慮下面三種加權(quán)方式:
Unbounded fusion:?
 ?,這里的?
?,這里的? ?可以是一個標(biāo)量(per feature)、一個向量(per channel)、一個多維度的tensor(per-pixel)。然而由于加權(quán)值是無界的,這經(jīng)常會導(dǎo)致訓(xùn)練不穩(wěn)定。所以考慮對加權(quán)值應(yīng)用正則化技術(shù);
?可以是一個標(biāo)量(per feature)、一個向量(per channel)、一個多維度的tensor(per-pixel)。然而由于加權(quán)值是無界的,這經(jīng)常會導(dǎo)致訓(xùn)練不穩(wěn)定。所以考慮對加權(quán)值應(yīng)用正則化技術(shù);Softmax-based fusion:?
 ?,這樣就將加權(quán)值約束到0-1之間,但是由于softmax這會導(dǎo)致增加額外的計算成本,運行速度變慢;
?,這樣就將加權(quán)值約束到0-1之間,但是由于softmax這會導(dǎo)致增加額外的計算成本,運行速度變慢;Fast normalized fusion:?
 ?,權(quán)重經(jīng)過relu保證是大于0的,然后簡單地做求和歸一化,可以同時保證精度和實際運行速度;
?,權(quán)重經(jīng)過relu保證是大于0的,然后簡單地做求和歸一化,可以同時保證精度和實際運行速度;
最后我們的BiFPN整合了雙向跨尺度連接和fast normalized fusion,這里我們描述了Figure 2(f)中l(wèi)evel 6處的兩個融合特征:

2. EfficientDet
基于BiFPN,作者衍生出了一族檢測模型,命名為EfficientDet。在本節(jié),我們討論整個模型的結(jié)構(gòu)和復(fù)合縮放方法。
2.1 EfficientDet Architecture
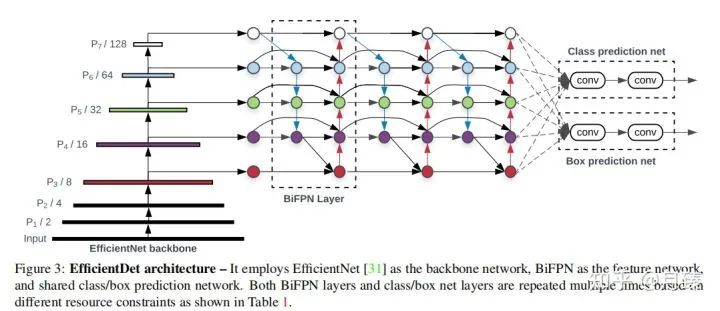
上圖是EfficientDet模型的整體結(jié)構(gòu),backbone是在ImageNet上預(yù)訓(xùn)練好的EfficientNet,BiFPN作為neck產(chǎn)生高級的融合特征,這些融合特征最后被送進class/box網(wǎng)絡(luò)來產(chǎn)生最終的預(yù)測結(jié)果。
2.2 Compound Scaling
和EfficientNet一樣引入了復(fù)合系數(shù)進行聯(lián)合優(yōu)化,在gird search基礎(chǔ)上加了一些先驗,如下:
Backbone network:直接利用EfficientNet的B0-B6作為預(yù)訓(xùn)練的backbone。
BiFPN network:指數(shù)調(diào)整BiFPN的channel數(shù),線性調(diào)整BiFPN的depth,即:
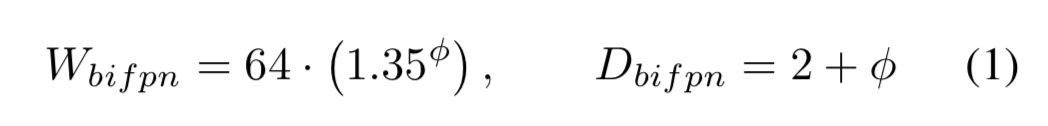
Box/class prediction network:channel數(shù)和BiFPN保持一致,線性調(diào)整depth,即:
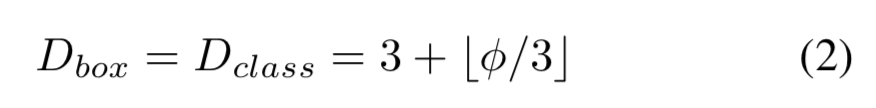
Input image resolution:因為使用了P3-P7層進行特征融合,輸入分辨率調(diào)整后必須是128的倍數(shù),即:
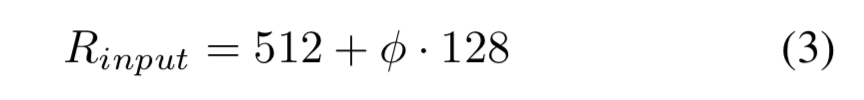
以上就是EfficientDet根據(jù)復(fù)合系數(shù)? ?進行調(diào)整的策略了,總結(jié)如下:
?進行調(diào)整的策略了,總結(jié)如下:

3. 實驗結(jié)果
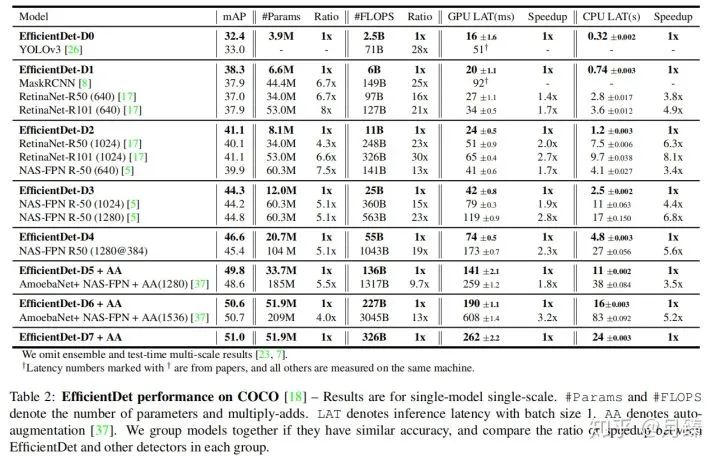
下面這張圖展示了EfficientDet這個系列在相同參數(shù)量和計算量下相對之前的模型的優(yōu)越之處:
3.1 Ablation Study
3.1.1 Disentangling Backbone and BiFPN

首先來研究過Backbone和特征融合對檢測精度的影響。從ResNet50+FPN出發(fā),先使用EfficientNet-B3替換ResNet50,map漲了3個點,參數(shù)量和FLOPS反而下降了;再進一步使用BiFPN替換FPN,直接漲了4個點,同時參數(shù)量和計算量也下降了,這可能是因為使用的是深度分離卷積。
3.1.2 BiFPN Cross-Scale Connections
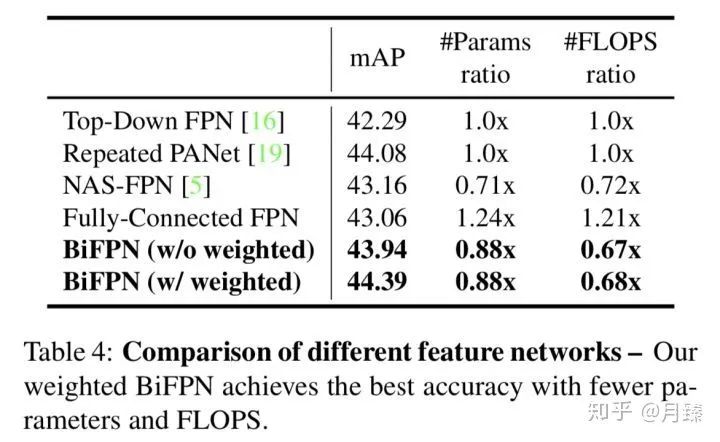
原始的PANet和FPN都只有一次top-down和botton-up路徑,為了進行公平的比較,這里將其分別堆疊了5次。BiFPN的精度和Repeated PANet[6]基本持平,但是計算量和參數(shù)量都有降低,此外利用加權(quán)特征融合后,BiFPN的精度又能進一步提升。
3.1.3 Softmax vs Fast Normalized Fusion
接著是對加權(quán)融合方式的研究,結(jié)果如下:
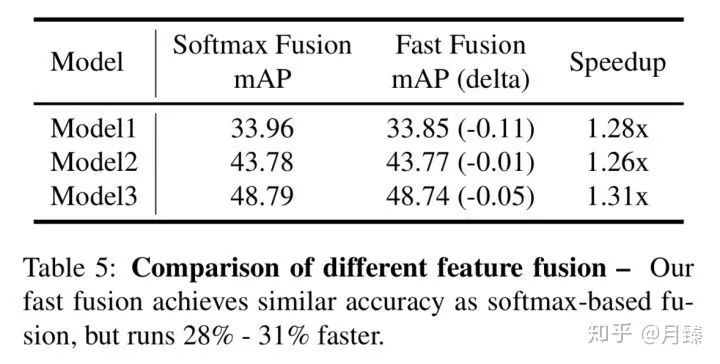
可以看出來,F(xiàn)ast Fusion取得了和Softmax Fusion相近的結(jié)果,但加速效果很明顯。
3.1.4 Compound Scaling
最后研究了單一維度上的scale和這種聯(lián)合scale的影響:
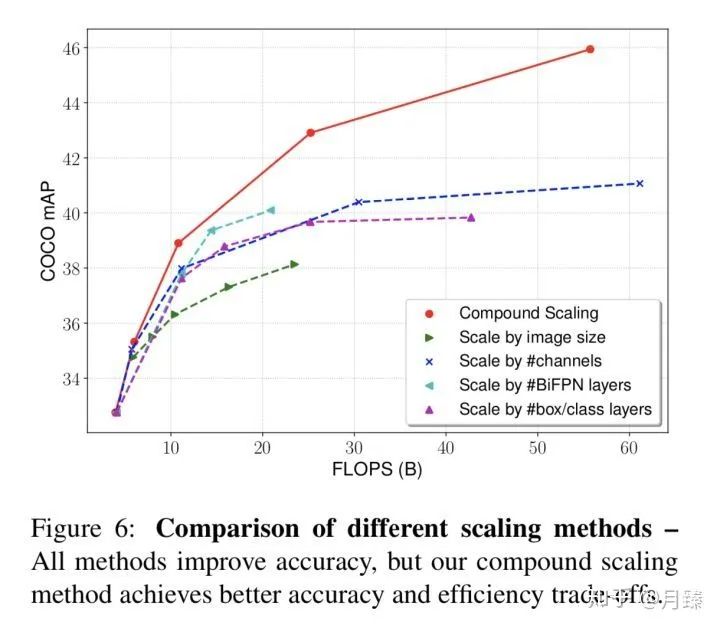
三. SpineNet
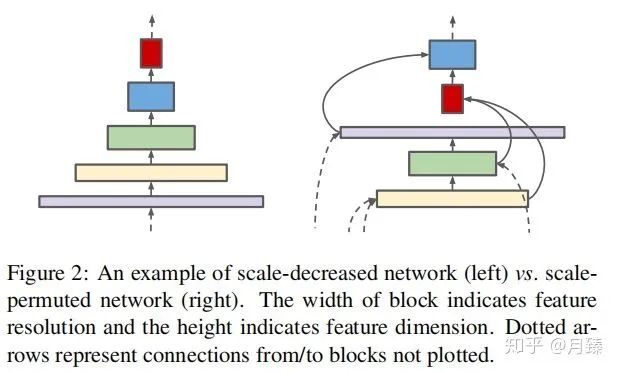
在分類任務(wù)中,傳統(tǒng)的CNN的分辨率通常會隨著網(wǎng)絡(luò)的深度逐漸變小,這樣在top層特征圖就會有一個很大的感受野和豐富的語義信息,從而可以更好的encode輸入圖像,完成分類。但是對于像檢測這樣同時需要分類和定位的任務(wù)來說,這樣的網(wǎng)絡(luò)結(jié)構(gòu)是不是還是最佳的呢?答案是否定的,直接使用頂層的特征圖做檢測發(fā)現(xiàn)小物體檢測的精度很低,這是因為在不斷下采樣的過程中丟失了大量的細節(jié)信息,即使通過top-down path(decode)也無法完全恢復(fù),導(dǎo)致檢測的性能下降很嚴(yán)重。于是這篇論文提出了SpineNet,,將編碼器和解碼器合二為一構(gòu)建了尺度可變的backbone,這個backbone同時具備之前提到的編碼器和解碼器功能,因此也是直接連在分類和回歸網(wǎng)絡(luò)上的。而這個尺度可變的backbone具備兩個特點:首先,中間特征圖的分辨率能夠隨時增加或減少,這樣模型可以隨著深度的增加而保留空間信息;其次,特征圖之間能夠跨越特征尺度連接,以促進多尺度特征融合。下圖顯示了SpineNet和傳統(tǒng)CNN之間的結(jié)構(gòu)區(qū)別:
1. Method
作者提出的backbone是一個固定的steam network后面跟著learned scale-permuted network。其中steam network是分辨率之間降低的網(wǎng)絡(luò)(傳統(tǒng)意義上的CNN),并且在steam network這部分的blocks可以用作后續(xù)的scale-permuted network的輸入。實際上這篇文章要搜的就是后面的scale-permuted network。
一個scale-permuted網(wǎng)絡(luò)是由一系列構(gòu)建塊? ?組成,每個block?
?組成,每個block? ?多對應(yīng)一個用來描述分辨率大小的特征等級?
?多對應(yīng)一個用來描述分辨率大小的特征等級? ?,??等級對應(yīng)的塊中特征圖大小為網(wǎng)絡(luò)輸入分辨率的?
?,??等級對應(yīng)的塊中特征圖大小為網(wǎng)絡(luò)輸入分辨率的? ?,同個塊中所有層的特征圖大小一樣。受到NAS-FPN的啟發(fā),作者定義了5個“輸出塊”(等級從?
?,同個塊中所有層的特征圖大小一樣。受到NAS-FPN的啟發(fā),作者定義了5個“輸出塊”(等級從? ?),scale-permuted中的剩余塊稱為“中間塊”。網(wǎng)絡(luò)結(jié)構(gòu)搜索時先搜索這N個塊的排列順序,再搜索它們之間的連接方式,最后進一步通過調(diào)整模塊的屬性來提高性能。
?),scale-permuted中的剩余塊稱為“中間塊”。網(wǎng)絡(luò)結(jié)構(gòu)搜索時先搜索這N個塊的排列順序,再搜索它們之間的連接方式,最后進一步通過調(diào)整模塊的屬性來提高性能。
1.1 Search Space
Scale permutations:這N個塊的相對順序是很重要的,因為一個塊只能接受兩個輸入,而且它的輸入都來自它之前的塊。所以總共有? ?中可能的排序。塊的排列順序是首先要確定好的。
?中可能的排序。塊的排列順序是首先要確定好的。
Cross-scale connections:每個塊可以從之前塊(包括steam network中的塊)中接受兩個輸入。當(dāng)融合不同分辨率的兩個輸入時需要做resamping spatial and feature dimensions操作(后面會細說),這個搜索空間大小為? ?,這里的m是steam network中候選塊的數(shù)量。
?,這里的m是steam network中候選塊的數(shù)量。
Block adjustments:作者允許進一步增大了搜索空間,每一個塊的種類可以從{bottleneck block,residual block}中任意選擇,同時中間塊也可以調(diào)整自己的等級(在自己的等級上加{-1, 0, 1, 2}中的任意一個)。
1.2 Resampling in Cross-scale Connections
融合特征的一個重大挑戰(zhàn)就是parent(有兩個,代表模塊的輸入)和target模塊之間的分辨率和通道數(shù)可能不同,所以需要做一些調(diào)整,操作示意圖如Figure 4。這篇論文引入了比例因子α(默認為0.5)將通道數(shù)C調(diào)整為α×C(降低計算量)。然后再使用最近鄰插值進行上采樣或進行stride為2的卷積用于下采樣特征圖以匹配目標(biāo)特征圖分辨率。最后,再應(yīng)用1×1卷積將輸入特征圖的通道數(shù)α×C與目標(biāo)特征圖的通道數(shù)相匹配,如下圖所示:
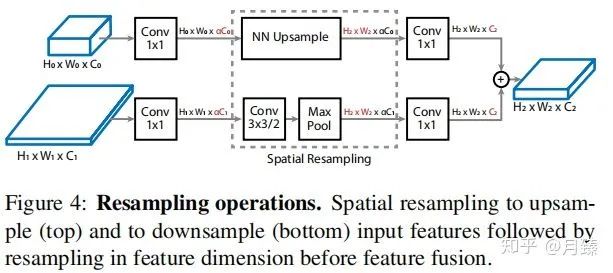
1.3 Scale-Permuted Model by Permuting ResNet
現(xiàn)在考慮一個問題如何排列ResNet網(wǎng)絡(luò)的塊結(jié)構(gòu)來構(gòu)造一個scale-permuted模型。由于連接塊的操作Resampling in Cross-scale Connections的計算量可以忽略,所以比較是公平的。原始的ResNet-50僅含有4種尺度? ?,第6和第7種尺度是如何產(chǎn)生的呢?w 我認為這里是將一個?
?,第6和第7種尺度是如何產(chǎn)生的呢?w 我認為這里是將一個? ?模塊替換為一個?
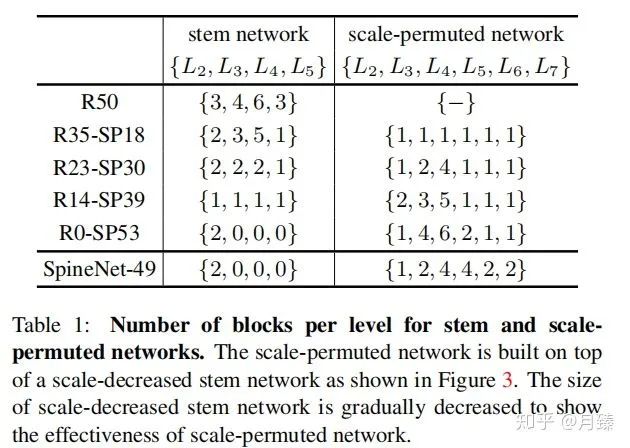
?模塊替換為一個? ?, 同時這三個等級的模塊特征通道數(shù)都是256。table 1展示了搜索出來的一族模型的構(gòu)建塊的對比數(shù)量,R[N]-SP[M]代表在手工構(gòu)造網(wǎng)絡(luò)中有N個特征層,scale-permuted網(wǎng)絡(luò)中有M個特征層。
?, 同時這三個等級的模塊特征通道數(shù)都是256。table 1展示了搜索出來的一族模型的構(gòu)建塊的對比數(shù)量,R[N]-SP[M]代表在手工構(gòu)造網(wǎng)絡(luò)中有N個特征層,scale-permuted網(wǎng)絡(luò)中有M個特征層。
1.4 SpineNet Architectures
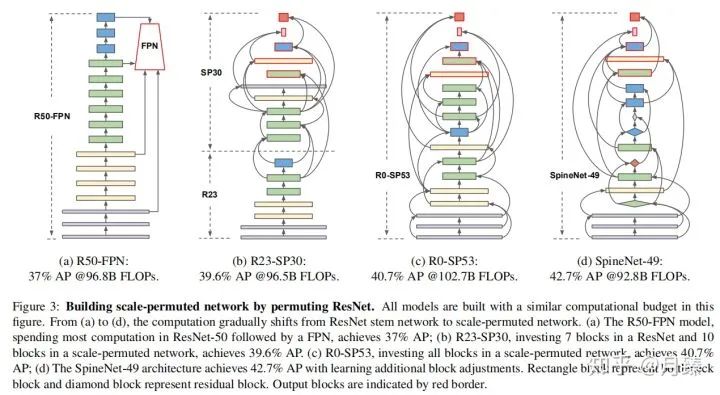
如上圖所示,其中有紅色邊框的塊看作是輸出塊,按照論文描述每個特征圖都應(yīng)該只有兩個輸入,但是圖中可以看到一些輸出特征圖是有三個輸入的,這是因為采用了和NAS-FPN一樣的做法,即如果feature blocks不連接到更高順序的任何中間feature blocks,則將它們連接到相應(yīng)級別的輸出feature blocks。
考慮到ResNet-50可能并不是最佳的基礎(chǔ)網(wǎng)絡(luò),所以作者又添加了feature blocks自身的尺度以及block類型調(diào)整的搜索空間,最終得到上圖(d)的結(jié)果,這也能進一步帶來精度的提升。而在SpineNet-49的基礎(chǔ)上,作者又構(gòu)建了一些擴展的網(wǎng)絡(luò)結(jié)構(gòu) SpineNet-49s/49/96/143。其中SpineNet-49s是將整個網(wǎng)絡(luò)的特征通道數(shù)統(tǒng)一用0.75縮放,SpineNet-96是將每個塊??重復(fù)堆疊兩次,? ?連接原始??的兩個輸入,?
?連接原始??的兩個輸入,? ?連接輸出目標(biāo)塊,SpineNet-143是將每個塊重復(fù)堆疊三次,同時resampling操作時的?
?連接輸出目標(biāo)塊,SpineNet-143是將每個塊重復(fù)堆疊三次,同時resampling操作時的? ?。Figure 5展示了通過重復(fù)塊增加網(wǎng)絡(luò)深度的例子。
?。Figure 5展示了通過重復(fù)塊增加網(wǎng)絡(luò)深度的例子。

2. 實驗
NAS細節(jié):和[1]中一樣,訓(xùn)練一個RNN控制器來搜索網(wǎng)絡(luò)結(jié)構(gòu),為了加速搜索,設(shè)計了一個代理SpineNet(SpineNet-49的特征通道數(shù)縮放為原來的0.25,resampling時的? ?,box/class網(wǎng)絡(luò)中的特征通道數(shù)為64),每次采樣到的結(jié)構(gòu)訓(xùn)練5個epoch得到的精度作為reward。
?,box/class網(wǎng)絡(luò)中的特征通道數(shù)為64),每次采樣到的結(jié)構(gòu)訓(xùn)練5個epoch得到的精度作為reward。

Ablation Studies
Importance of Scale Permutation:選取了兩種固定塊排列順序的結(jié)構(gòu)(Hourglass和Fish)與R0-SP53對比,結(jié)果如下:
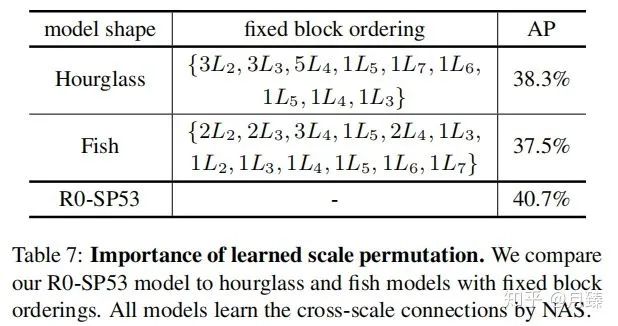
結(jié)果表明聯(lián)合優(yōu)化塊排列和連接關(guān)系得到的結(jié)果要比使用固定結(jié)構(gòu)只優(yōu)化連接關(guān)系得到性能好。
Importance of Cross-scale Connections:cross-scale的連接拓撲結(jié)構(gòu)在融合不同分辨率的特征中扮演著重要角色,接下來作者對拓撲結(jié)構(gòu)做一些破壞,以R0-Spine53為例,主要的破壞方式有三種:(1)一處最短范圍的連接(2)移除最長的連接(3)移除所有的連接,順序連接各個模塊。結(jié)果如table 8所示,任何一種破壞都會損失網(wǎng)絡(luò)性能。

四. CR-NAS
這篇文章來自商湯ICRL 2020[6],其motivation就是在檢測中,通常是將分類網(wǎng)絡(luò)直接拿來做backbone的,但其實這是不合適的。作者分析了這個Gap的可能的一大原因是兩個任務(wù)的data相差太大。對分類而言,ImageNet輸入大小是224*224,但是對于檢測而言,拿COCO為例,輸入可能到800*1333,而且還需要去handle各個尺度的物體。那么我們?nèi)绾尾拍茉O(shè)計(搜索)一個適合于檢測的backbone呢?
作者寫了一個對論文的介紹,詳情可見:ICLR2020|商湯提出新目標(biāo)檢測NAS方法:算力重分配(CRNAS) - 云+社區(qū) - 騰訊云
1. Two-level Architecture Search Space
作者提出了CR-NAS,先對不同分辨率的stage進行重新分配,然后在空間位置上對卷積的空洞因子進行重新分配。
1.1 Stage Reallocation Space
假設(shè)一個backbone在不斷下采樣的過程中產(chǎn)生四種尺度的特征——? ,可以視作四個stage,同個stage中的block分辨率相同,由于網(wǎng)絡(luò)設(shè)計中遵循分辨率減半的同時channel數(shù)加倍,所以不同stage中每個block的計算量也是相等的,于是就有了一個思路,能不能對每種stage的block數(shù)量中心分配,只要總數(shù)不變,網(wǎng)絡(luò)整體上的計算量就是相同的。
,可以視作四個stage,同個stage中的block分辨率相同,由于網(wǎng)絡(luò)設(shè)計中遵循分辨率減半的同時channel數(shù)加倍,所以不同stage中每個block的計算量也是相等的,于是就有了一個思路,能不能對每種stage的block數(shù)量中心分配,只要總數(shù)不變,網(wǎng)絡(luò)整體上的計算量就是相同的。
實際中往往需要針對不同的計算預(yù)算學(xué)習(xí)不同的stage reallocation,不同的應(yīng)用需要不同size的模型。所以作者設(shè)計了一個搜索空間可以覆蓋各種候選情況。以ResNet系列為例,設(shè)計第一個和第二個stage的block數(shù)量選擇范圍為? ?,第三個stage為?
?,第三個stage為? ?,第四個stage為?
?,第四個stage為? ?。
?。
1.2 Convolution Reallocation Space
空洞卷積是通過對卷積位置進行稀疏采樣來影響有效感受野的,它的另外一個好處就是沒有增加額外的參數(shù)和計算量(我覺得增加了)。由于第一步我們已經(jīng)對stage的重新分配進行了搜索,也就是各個stage的block數(shù)量已經(jīng)確定了,所以在這里只需要針對每個塊搜索出它的空洞率(1,2,3)。
1.3 Stage Reallocation Search
先訓(xùn)練一個包含所有block選擇的supernet,然后采樣子結(jié)構(gòu)? ?并直接在目標(biāo)檢測任務(wù)上進行評估,設(shè)定block總數(shù)的約束為N,可以發(fā)現(xiàn)最好的分配策略為:
?并直接在目標(biāo)檢測任務(wù)上進行評估,設(shè)定block總數(shù)的約束為N,可以發(fā)現(xiàn)最好的分配策略為:
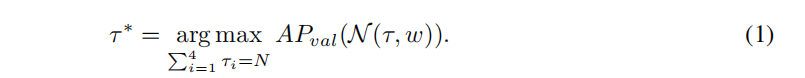
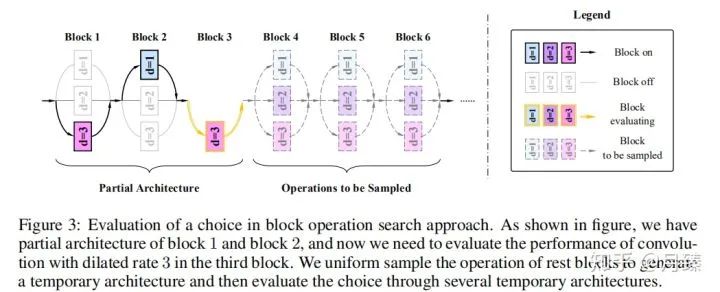
1.4 Block Operation Search
在1.3中為每個stage選擇了確定的block數(shù)量后,網(wǎng)絡(luò)的結(jié)構(gòu)也就確定了,接下來就是對每個塊中的卷積層的空洞率進行微調(diào)。假如有16個塊,每個塊的空洞率可以在 {1, 2, 3} 之間選擇,作者先訓(xùn)練一個包含所有選擇的supernet,然后通過搜索得到最佳的選擇,搜索空間大小為? ?,為了進一步減小搜索成本。作者選擇貪心搜索算法。
?,為了進一步減小搜索成本。作者選擇貪心搜索算法。
具體來講,就是先將網(wǎng)絡(luò)結(jié)構(gòu) o看作一系列選擇? ?。從第一塊開始遍歷,每次保留前K=3個最佳結(jié)構(gòu);對于第一個塊,由于空洞率可以有三種選擇,所以要訓(xùn)練評估三次,當(dāng)空洞率為1時,對后面的blocks的空洞率隨機采樣,采樣5000個結(jié)構(gòu),然后選擇5000張圖片評估一次,作為空洞率=1時的評估結(jié)構(gòu),這樣對于第一個塊前三個最佳結(jié)構(gòu)分別對應(yīng)空洞率等于1,2,3;對于第二個塊,由于第一塊有三個選擇,那么就有進行9次評估了,從中選擇最佳的三個結(jié)果......依次遍歷完所有的塊,然后從最佳的K個結(jié)構(gòu)中選擇最好的那個作為最終的選擇。偽代碼如下:
?。從第一塊開始遍歷,每次保留前K=3個最佳結(jié)構(gòu);對于第一個塊,由于空洞率可以有三種選擇,所以要訓(xùn)練評估三次,當(dāng)空洞率為1時,對后面的blocks的空洞率隨機采樣,采樣5000個結(jié)構(gòu),然后選擇5000張圖片評估一次,作為空洞率=1時的評估結(jié)構(gòu),這樣對于第一個塊前三個最佳結(jié)構(gòu)分別對應(yīng)空洞率等于1,2,3;對于第二個塊,由于第一塊有三個選擇,那么就有進行9次評估了,從中選擇最佳的三個結(jié)果......依次遍歷完所有的塊,然后從最佳的K個結(jié)構(gòu)中選擇最好的那個作為最終的選擇。偽代碼如下:

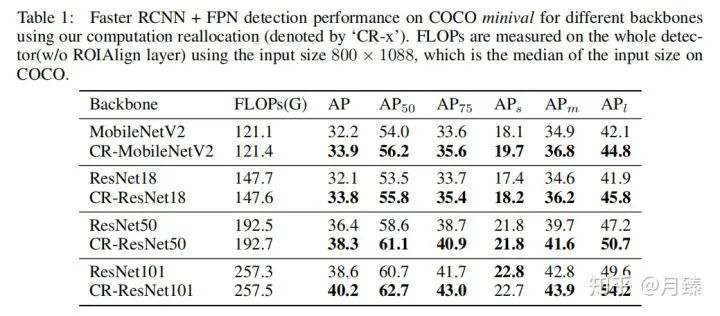
實驗結(jié)果:
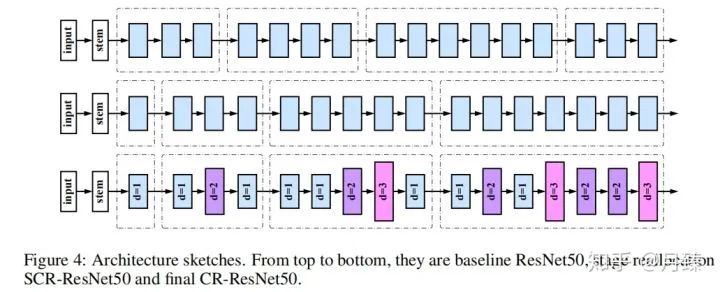
參考文獻
推薦閱讀