
盤點GAN在目標(biāo)檢測中的應(yīng)用
重磅干貨,第一時間送達
1,2017-CVPR: A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
摘要
如何學(xué)習(xí)對遮擋和變形不敏感的物體檢測器?當(dāng)前解決方案主要使用的是基于數(shù)據(jù)驅(qū)動的策略:收集具有不同條件下的對象物體的大規(guī)模數(shù)據(jù)集去訓(xùn)練模型,并期望希望最終可學(xué)習(xí)到不變性。 但數(shù)據(jù)集真的有可能窮盡所有遮擋嗎?作者認為,像類別一樣,遮擋和變形也有長尾分布問題:一些遮擋和變形在訓(xùn)練集是罕見的,甚至不存在。 提出了一種解決方案:學(xué)習(xí)一個對抗網(wǎng)絡(luò)去生成具有遮擋和變形的樣本。對抗的目標(biāo)是生成難以被目標(biāo)檢測器分類的樣本檢測網(wǎng)絡(luò)和對抗網(wǎng)絡(luò)通過聯(lián)合訓(xùn)練得到。實驗結(jié)果表明,與Fast-RCNN方法相比,VOC07的mAP提升了2.3%,VOC2012的mAP提升了2.6%。

引言
一種可能的解決方法是通過采樣來生成逼真的圖像。然而,這實際上不太可行,因為圖像生成將需要訓(xùn)練這些罕見樣本。 另一個解決方案是生成所有可能的遮擋和變形,并從中訓(xùn)練物體檢測器。但由于變形和遮擋的搜索空間很大,因此這實際上也不可行和靈活。 事實上,使用所有樣本通常不是最佳解決方案,而選擇“困難”的正樣本更好。有沒有辦法可以生成具有不同遮擋和變形的困難正樣本且無需生成像素級別的圖像本身呢? 本文訓(xùn)練另一個網(wǎng)絡(luò):通過在空間上遮擋某些特征圖區(qū)域或通過操縱特征圖來創(chuàng)建空間變形以形成難樣本的對抗網(wǎng)絡(luò)。這里的關(guān)鍵思想是在卷積特征空間中創(chuàng)建對抗性樣本,而不是直接生成像素級別的數(shù)據(jù),因為后者是一個困難得多的問題。
方法
1,用于遮擋的Adversarial Spatial Dropout。作者提出使用一種Adversarial Spatial Dropout Network(ASDN)在前景目標(biāo)的深層特征級別上生成遮擋。在標(biāo)準(zhǔn)的Fast-RCNN中,RoI池層之后獲得每個前景對象的卷積特征;使用這些特征作為對抗網(wǎng)絡(luò)的輸入,ASDN以此生成一個掩碼,指示要刪除的特征部分(分配0),以使檢測網(wǎng)絡(luò)無法識別該對象。
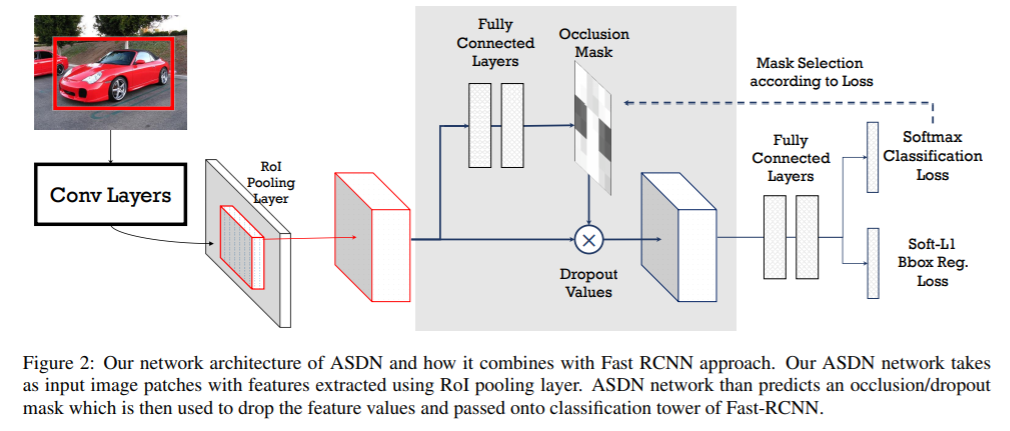
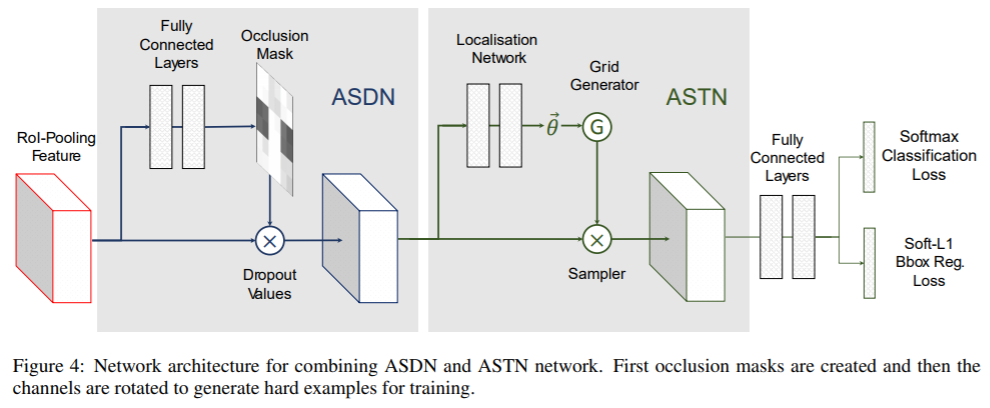
2,Adversarial Spatial Transformer Network(ASTN),關(guān)鍵思想是基于STN在特征上產(chǎn)生變形并使檢測網(wǎng)絡(luò)難以識別。通過與ASTN對抗,可以訓(xùn)練出更好的檢測網(wǎng)絡(luò)。 注:STN(Spatial Transformer Network )具有三個組成部分:localisation network, grid generator和sampler。給定特征圖作為輸入,localisation network將估計變形量(例如,旋轉(zhuǎn)度、平移距離和比例因子)。這些變量將用作grid generator和sampler生成目標(biāo)特征圖的輸入,輸出是變形后的特征圖。
2,2017-CVPR: Perceptual Generative Adversarial Networks for Small Object Detection
小物體分辨率低、易受噪聲影響,檢測任務(wù)非常困難。現(xiàn)有檢測方法通常學(xué)習(xí)多個尺度上所有目標(biāo)的表征來檢測小對象。但這種架構(gòu)的性能增益通常限于計算成本。 這項工作將小物體的表征提升為“超分辨”表征,實現(xiàn)了與大物體相似的特性,因此更具判別性。通過結(jié)合生成對抗網(wǎng)絡(luò)(Perceptual GAN)模型,縮小小對象與大對象之間的表征差異來改善小對象檢測性能。具體來說,生成器學(xué)習(xí)將小對象表征轉(zhuǎn)換為與真實大對象足夠相似以欺騙對抗判別器的超分辨表征。同時,判別器與生成器對抗以識別生成的表征,并對生成器施加條件要求——生成的小對象表征必須有利于檢測目標(biāo)。
3,2018 Adversarial Occlusion-aware Face Detection
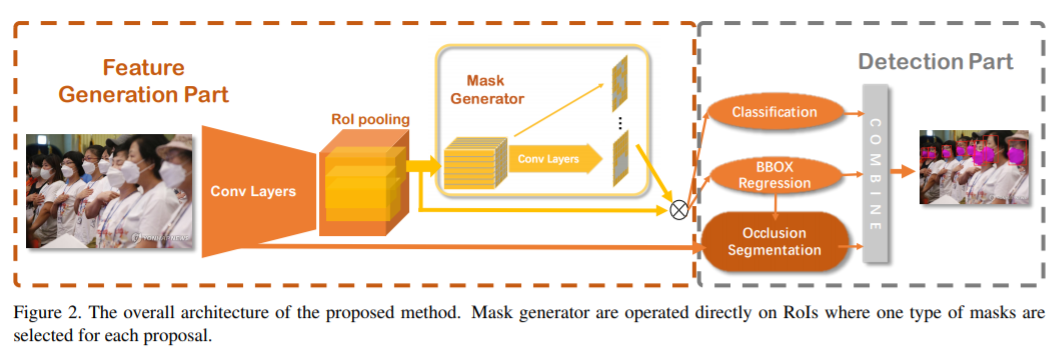
有遮擋人臉檢測是一項具有挑戰(zhàn)性的任務(wù)。通過同時檢測被遮擋的人臉和分割被遮擋區(qū)域,本文引進一種對抗性遮擋人臉檢測器Adversarial Occlusion-aware Face Detector (AOFD)。 為了檢測重度遮擋的臉部,設(shè)計AOFD的出發(fā)點是:(1)有效地利用未被遮擋的面部區(qū)域,以及(2)將遮擋的干擾轉(zhuǎn)化為有益的信息。 對于問題(1),未檢測到的臉通常被遮住了關(guān)鍵特征部分,例如眼睛和嘴巴。一種可行的方法是在訓(xùn)練集中遮蓋臉部的這些獨特部分,迫使檢測器了解即使暴露區(qū)域較少的人臉是什么樣。為此,以對抗的方式設(shè)計了掩模生成器,以為每個正樣本產(chǎn)生掩模。 對于問題(2),找到常見的遮擋有助于檢測其背后的不完整面孔。因此,引入了“遮擋分割”分支去分割遮擋部分包括頭發(fā)、眼鏡、圍巾、手和其他物體等。由于訓(xùn)練樣本很少,這并非易事。因此,作者標(biāo)記了從互聯(lián)網(wǎng)下載的374個訓(xùn)練樣本進行遮擋分割(該數(shù)據(jù)集記為SFS:small dataset for segmentation)。 如圖2所示,在RoI之后添加了一個遮擋區(qū)域生成器,然后是一個分類分支和一個邊界框回歸分支。最后,分割分支負責(zé)對每個邊界框內(nèi)的遮擋區(qū)域進行分割。最終將結(jié)合分類,邊界框回歸和遮擋分割的最終結(jié)果輸出。 實驗表明,AOFD不僅明顯優(yōu)于MAFA遮擋的人臉檢測數(shù)據(jù)集的最新技術(shù),而且在用于普通人臉檢測的基準(zhǔn)數(shù)據(jù)集(如FDDB)上也達到了競爭性的檢測精度。
4,2018-ECCV:SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
目標(biāo)檢測是計算機視覺中的一個基本而重要的問題。盡管在大規(guī)模檢測基準(zhǔn)(例如COCO數(shù)據(jù)集)上對大/中型對象已經(jīng)取得了令人印象深刻的結(jié)果,但對小對象的性能卻遠遠不能令人滿意。原因是小物體缺少足夠的外觀細節(jié)信息,這些信息可以將它們與背景或類似物體區(qū)分開。 為了解決小目標(biāo)檢測問題,提出了一種端到端的多任務(wù)生成對抗網(wǎng)絡(luò)(MTGAN)。其中生成器是一個超分辨率網(wǎng)絡(luò),可以將小的模糊圖像上采樣到精細圖像,并恢復(fù)詳細信息以進行更精確的檢測。判別器是一個多任務(wù)網(wǎng)絡(luò),該網(wǎng)絡(luò)用真實/虛假分數(shù),對象類別分數(shù)和邊界框回歸量來描述每個超分辨圖像塊。 此外,為了使生成器恢復(fù)更多細節(jié)以便于檢測,在訓(xùn)練過程中,將判別器中的分類和回歸損失反向傳播到生成器中。 在具有挑戰(zhàn)性的COCO數(shù)據(jù)集上進行的大量實驗證明了該方法從模糊的小圖像中恢復(fù)清晰的超分辨圖像的有效性,并表明檢測性能(特別是對于小型物體)比最新技術(shù)有所提高。
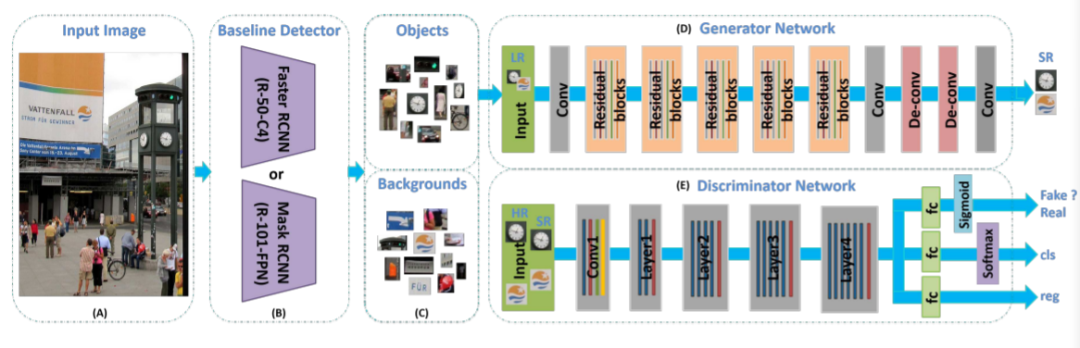
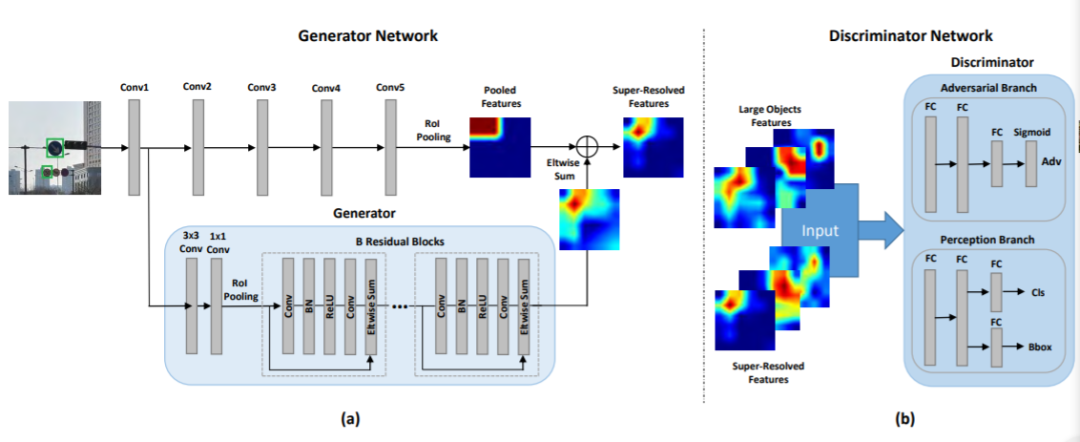
小物體檢測系統(tǒng)(SOD-MTGAN):
(A)將圖像輸入網(wǎng)絡(luò)。 (B)基線檢測器可以是任何類型的檢測器(例如Faster RCNN 、FPN或SSD),用于從輸入圖像中裁剪正(即目標(biāo)對象)和負(即背景)例,以訓(xùn)練生成器和判別器網(wǎng)絡(luò),或生成ROIs進行測試。 (C)正例和負例(或ROI)是由現(xiàn)成的檢測器生成的。 (D)生成器子網(wǎng)重建得到低分辨率輸入圖像的超分辨率版本(4倍放大);判別器網(wǎng)絡(luò)將GT與生成的高分辨率圖像區(qū)分開,同時預(yù)測對象類別并回歸對象位置(判別器網(wǎng)絡(luò)可以使用任何典型的體系結(jié)構(gòu),例如AlexNet、VGGNet、ResNet作為骨干網(wǎng),在實驗中使用ResNet-50或ResNet-101。
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:leetcode?開源書
在「AI算法與圖像處理」公眾號后臺回復(fù):leetcode,即可下載。每題都 runtime beats 100% 的開源好書,你值得擁有!
下載3 CVPR2020 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR2020,即可下載1467篇CVPR?2020論文 個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱

覺得不錯就點亮在看吧

評論
圖片
表情