點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
報(bào)道|人工智能前沿講習(xí)
我的博士課題是自監(jiān)督學(xué)習(xí)(Self-supervised Learning)方法在計(jì)算機(jī)視覺表示學(xué)習(xí)領(lǐng)域的應(yīng)用。作為一個(gè)新名詞,自監(jiān)督學(xué)習(xí)實(shí)際上與監(jiān)督學(xué)習(xí)、非監(jiān)督學(xué)習(xí)、半監(jiān)督學(xué)習(xí)并沒有本質(zhì)上的鴻溝。Ps: 我個(gè)人是不太喜歡科學(xué)界命名新技術(shù)的風(fēng)格,給一些舊技術(shù)的新衍生冠以高大上的名字會(huì)讓初學(xué)者對于這個(gè)領(lǐng)域感到很混亂,而事實(shí)上很多名詞是交集或者子集的關(guān)系。我對于整個(gè)機(jī)器學(xué)習(xí)領(lǐng)域的技術(shù)分類迷茫了很久看了很多才慢慢理清楚,有機(jī)會(huì)給大家整理一個(gè)Node Map。當(dāng)然,取名字是Hinton、Bengio這些大佬的事。。。萬一哪天人家給RL改名叫Guess Learning/Try Learning >.<01
自監(jiān)督學(xué)習(xí)(Self-supervised Learning)是何方神圣?1.1 自監(jiān)督學(xué)習(xí)與監(jiān)督學(xué)習(xí)、非監(jiān)督學(xué)習(xí)的關(guān)系樣本特征在學(xué)習(xí)過程中至關(guān)重要。在簡單的數(shù)據(jù)挖掘任務(wù)中,重要的數(shù)據(jù)特征是人工設(shè)計(jì)的。這些功能通常稱為Hand-crafted features。在計(jì)算機(jī)視覺領(lǐng)域,這種類型的表示通常要求我們設(shè)計(jì)合適的函數(shù)以從圖像或視頻中提取所需的信息。但是,這些功能通常來自人類有關(guān)視覺任務(wù)中關(guān)鍵信息的經(jīng)驗(yàn),這導(dǎo)致手工制作的功能無法表示高級(jí)語義信息。例如,在早期工作中提出了各種視覺描述符,例如SIFT算子,HOG算子等等來表示有關(guān)對象邊緣,紋理等的視覺信息。此外,由于設(shè)計(jì)函數(shù)的復(fù)雜度限制,這種類型的表示能力通常相對較低,并且提出新的hand-crafted features并非易事。
總而言之,hand-crafted features在早期視覺任務(wù)中取得了一些成功,但是隨著問題的復(fù)雜性增加,它逐漸無法滿足我們的需求。隨著卷積神經(jīng)網(wǎng)絡(luò)的普及以及數(shù)據(jù)大小的指數(shù)增長,在完全監(jiān)督的任務(wù)中,自動(dòng)提取的表示形式逐漸取代了效率低下的hand-crafted features。在完全監(jiān)督模型中,通過反向傳播解決了以神經(jīng)網(wǎng)絡(luò)和監(jiān)督損失函數(shù)為代表的全局優(yōu)化問題。大量帶注釋的圖像和視頻數(shù)據(jù)集以及日益復(fù)雜的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)使諸如圖像分類和對象檢測之類的完全受監(jiān)督的任務(wù)成為可能。之后,經(jīng)過訓(xùn)練的模型的中間特征圖通常包含與特定任務(wù)相關(guān)的語義有意義的信息,這些信息可以傳遞給類似的問題。但是,手動(dòng)數(shù)據(jù)注釋是監(jiān)督學(xué)習(xí)中必不可少的步驟,這是耗時(shí),費(fèi)力且有噪聲的。與有監(jiān)督的方法不同,無監(jiān)督的方法不依賴于人類注釋,并且通常集中在數(shù)據(jù)良好表示(例如平滑度,稀疏性和分解)的預(yù)設(shè)先驗(yàn)上。無監(jiān)督方法的經(jīng)典類型是聚類方法,例如高斯混合模型,它將數(shù)據(jù)集分解為多個(gè)高斯分布式子數(shù)據(jù)集。然而,非監(jiān)督學(xué)習(xí)學(xué)習(xí)由于預(yù)設(shè)先驗(yàn)的一般性較差而不太值得信賴,在某些數(shù)據(jù)集(例如非高斯子數(shù)據(jù)集)上選擇將數(shù)據(jù)擬合為高斯分布可能是完全錯(cuò)誤的。自我監(jiān)督方法可以看作是一種具有監(jiān)督形式的特殊形式的非監(jiān)督學(xué)習(xí)方法,這里的監(jiān)督是由自我監(jiān)督任務(wù)而不是預(yù)設(shè)先驗(yàn)知識(shí)誘發(fā)的。與完全不受監(jiān)督的設(shè)置相比,自監(jiān)督學(xué)習(xí)使用數(shù)據(jù)集本身的信息來構(gòu)造偽標(biāo)簽。在表示學(xué)習(xí)方面,自我監(jiān)督學(xué)習(xí)具有取代完全監(jiān)督學(xué)習(xí)的巨大潛力。人類學(xué)習(xí)的本質(zhì)告訴我們,大型注釋數(shù)據(jù)集可能不是必需的,我們可以自發(fā)地從未標(biāo)記的數(shù)據(jù)集中學(xué)習(xí)。更為現(xiàn)實(shí)的設(shè)置是使用少量帶注釋的數(shù)據(jù)進(jìn)行自學(xué)習(xí)。這稱為Few-shot Learning。1.2?自監(jiān)督學(xué)習(xí)的主要流派在自監(jiān)督學(xué)習(xí)中,如何自動(dòng)獲取偽標(biāo)簽至關(guān)重要。根據(jù)偽標(biāo)簽的不同類型,我將自我監(jiān)督的表示學(xué)習(xí)方法分為4種類型:基于數(shù)據(jù)生成(恢復(fù))的任務(wù),基于數(shù)據(jù)變換的任務(wù),基于多模態(tài)的任務(wù),基于輔助信息的任務(wù)。這里簡單介紹第一類任務(wù)。事實(shí)上,所有的非監(jiān)督方法都可以視作第一類自監(jiān)督任務(wù),在我做文獻(xiàn)調(diào)研的過程中,我越發(fā)的感覺到事實(shí)上非監(jiān)督學(xué)習(xí)和自監(jiān)督學(xué)習(xí)根本不存在界限。
所有的非監(jiān)督學(xué)習(xí)方法,例如數(shù)據(jù)降維(PCA:在減少數(shù)據(jù)維度的同時(shí)最大化的保留原有數(shù)據(jù)的方差),數(shù)據(jù)擬合分類(GMM: 最大化高斯混合分布的似然), 本質(zhì)上都是為了得到一個(gè)良好的數(shù)據(jù)表示并希望其能夠生成(恢復(fù))原始輸入。這也正是目前很多的自監(jiān)督學(xué)習(xí)方法賴以使用的監(jiān)督信息。基本上所有的encoder-decoder模型都是以數(shù)據(jù)恢復(fù)為訓(xùn)練損失。02
2.1 什么是基于數(shù)據(jù)恢復(fù)的自監(jiān)督任務(wù)?
第一類任務(wù)也是使用最多的一類任務(wù):數(shù)據(jù)生成任務(wù)。
自監(jiān)督學(xué)習(xí)的出發(fā)點(diǎn)是考慮在缺少標(biāo)簽或者完全沒有標(biāo)簽的情況下,依然學(xué)習(xí)到能夠表示原始圖片的良好有意義的特征。那么什么樣的特征是良好有意義的呢?在第一類自監(jiān)督任務(wù)——數(shù)據(jù)恢復(fù)任務(wù)中,能夠通過學(xué)習(xí)到的特征還原生成原始數(shù)據(jù)的特征,我們認(rèn)為是良好有意義的。看到這里,實(shí)際上大家能夠聯(lián)想到自動(dòng)編碼器類的模型,甚至更簡單的PCA。實(shí)際上,幾乎所有的非監(jiān)督學(xué)習(xí)方法都是以這個(gè)原則作為基礎(chǔ)的。現(xiàn)在十分流行的深度生成模型VAE(后面我會(huì)寫一篇文章住專門介紹VAE,還在草稿箱里待著。。。)甚至更火的GAN也可以歸為這一類方法。
GAN的核心是通過Discriminator去縮小Generator distribution和real distribution之間的距離。GAN的學(xué)習(xí)過程不需要人為進(jìn)行數(shù)據(jù)標(biāo)注,其監(jiān)督信號(hào)也即是優(yōu)化目標(biāo)就是使得上述對抗過程趨向平穩(wěn)(Goodfellow 想出這個(gè)點(diǎn)子真的天才)。
這里我們以兩篇具體的paper為例子,介紹數(shù)據(jù)恢復(fù)類的自監(jiān)督任務(wù)如何操作實(shí)現(xiàn)。我們的重點(diǎn)依然是視覺問題,這里分別介紹一篇圖片上色的文章和一篇視頻預(yù)測的文章。其余的領(lǐng)域比如NLP,其本質(zhì)是類似的,在弄清楚了數(shù)據(jù)本身的特點(diǎn)之后,可以先做一些低級(jí)的照貓畫虎的工作。
2.2 圖片色彩恢復(fù)——瓢蟲是紅色的嗎?
設(shè)計(jì)自監(jiān)督任務(wù)時(shí)需要一些巧妙的思考。比如圖片色彩恢復(fù)任務(wù),我們已有的數(shù)據(jù)集是一張張的彩色圖片,假如去掉色彩,作為感性思考者的我們,是否能夠從黑白圖片中顯示的內(nèi)容推測原來圖片真實(shí)的色彩?對于一個(gè)嬰兒來說可能很難,但是對于我們來說,生活的經(jīng)歷告訴我們瓢蟲應(yīng)當(dāng)是紅色的(下圖第二行中)。我們是如何做出預(yù)測的?事實(shí)上,我們通過觀察大量的瓢蟲,在腦中建立了從“瓢蟲”到“紅色”的映射。

把這個(gè)學(xué)習(xí)過程推廣到我們的模型上,在給定黑白輸入的情況下,我們用正確的彩色的原始圖像作為學(xué)習(xí)的標(biāo)簽,從而模型會(huì)試著理解原始黑白圖像中“每個(gè)區(qū)域”是“什么”進(jìn)而去建立從是“什么”到“不同顏色”的映射。
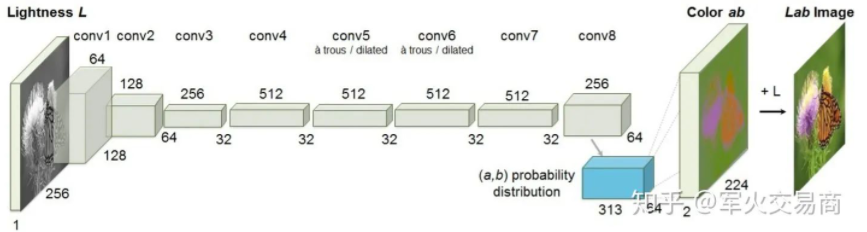
當(dāng)我們完成訓(xùn)練,模型的中間層feature map就得到了類似人腦對于“瓢蟲”以及其他物體的記憶,以向量的形式。
2.3 視頻預(yù)測——下一秒你會(huì)在哪里?
一般來說,視覺問題分成圖片和視頻兩大類,圖片數(shù)據(jù)可以認(rèn)為具有i.i.d特性,而視頻是由多個(gè)圖片幀構(gòu)成的,可以認(rèn)為具有一定的Markov dependency,時(shí)序關(guān)系是他們之間最大的不同。比如最簡單的思路,利用CNN提取單張圖片特征可以做圖片分類,再加入一個(gè)RNN或者LSTM去刻畫Markov Dependency,便可以應(yīng)用到視頻上。
視頻預(yù)測任務(wù)十分的耿直。怎么形容呢,他就是那種,你知道的,我們說視頻中幀與幀之間存在時(shí)空連續(xù)性。類似的,人類會(huì)利用這種幀與幀之間的連續(xù)性,當(dāng)我們看電影時(shí)突然按了暫停,下一秒下幾秒會(huì)發(fā)生什么實(shí)際上我們是可以預(yù)測的。
同樣,把這個(gè)學(xué)習(xí)過程推廣到我們的模型上,在給定前一幀或者前幾幀的情況下,我們用后續(xù)的視頻幀作為學(xué)習(xí)的標(biāo)簽,從而模型會(huì)試著理解給定視頻幀中的語義信息(發(fā)生了啥?)進(jìn)而去建立從當(dāng)前到未來的映射關(guān)系。

References
R. Zhang, P. Isola, and A. A. Efros, “Colorful image colorization,” in ECCV, pp. 649–666, Springer, 2016.https://arxiv.org/abs/1603.08511
N. Srivastava, E. Mansimov, and R. Salakhutdinov, “Unsuper- vised Learning of?Video Representations using LSTMs,” in ICML, 2015.
https://arxiv.org/abs/1502.0468103
第二類自監(jiān)督學(xué)習(xí)任務(wù)——基于數(shù)據(jù)變換的任務(wù)。事實(shí)上,人們現(xiàn)在常常提到的自監(jiān)督學(xué)習(xí)通常指的是這一類自監(jiān)督任務(wù),我個(gè)人認(rèn)為是比較狹義的概念。
用一句話說明這一類任務(wù),事實(shí)上原理很簡單。對于樣本????,我們對其做任意變換 ,則自監(jiān)督任務(wù)的目標(biāo)是能夠?qū)ι傻????估計(jì)出其變換????的參數(shù)
,則自監(jiān)督任務(wù)的目標(biāo)是能夠?qū)ι傻????估計(jì)出其變換????的參數(shù)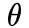 ?。
?。
下面介紹一種原理十分簡單但是目前看來非常有效的自監(jiān)督任務(wù)——Rotation Prediction。
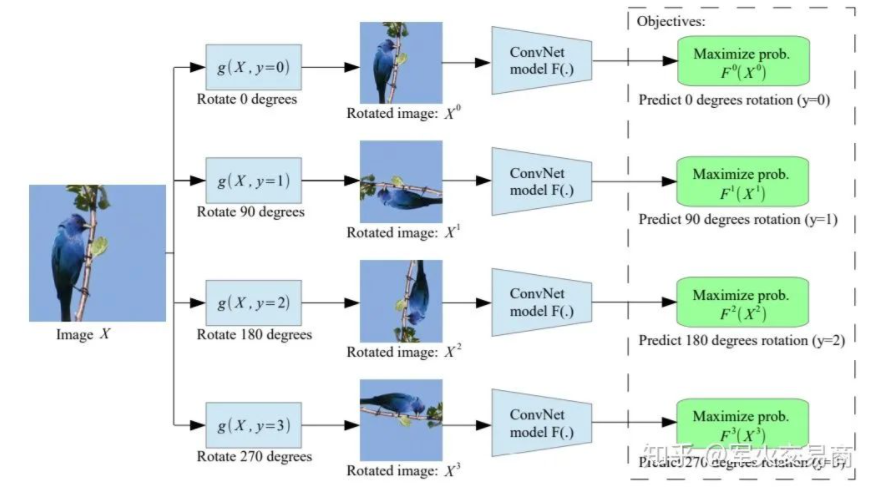
給定輸入圖片????,我們對其做4個(gè)角度的旋轉(zhuǎn),分別得到????,并且我們知道其對應(yīng)的變換角度分別為????。此時(shí),任務(wù)目標(biāo)即是對于以上4張圖片預(yù)測其對應(yīng)的旋轉(zhuǎn)角度,這里每張圖片都經(jīng)過同樣的卷積神經(jīng)網(wǎng)。
我始終堅(jiān)持的觀點(diǎn)是自監(jiān)督學(xué)習(xí)需要?jiǎng)訖C(jī)明確,這里我們能做的任意變換應(yīng)當(dāng)是對目標(biāo)有益的。比如在Rotation Prediction中,作為人類的我們只有在理解了圖片中是一只鳥站在枝頭之后才知道X_0的旋轉(zhuǎn)角度應(yīng)當(dāng)是????。那么我們有理由相信,當(dāng)模型能夠做出同樣正確的判斷時(shí),其中間的feature map必然攜帶了有意義的圖片語義信息。
https://arxiv.org/pdf/1803.07728.pdf
參考地址:
https://zhuanlan.zhihu.com/p/125721565
https://zhuanlan.zhihu.com/p/129067097
https://zhuanlan.zhihu.com/p/136108863
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。
