
我裂開(kāi)了...人類腦海中的畫面,被AI解碼了??

大數(shù)據(jù)文摘授權(quán)轉(zhuǎn)載自夕小瑤的賣萌屋
作者:白鹡鸰

Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
論文鏈接:
http://arxiv.org/abs/2211.06956
代碼鏈接:
https://github.com/zjc062/mind-vis
背景
方法
基于fMRI收集的腦電數(shù)據(jù)
作為1991年的Nature封面,fMRI得到了廣泛研究,目前采集數(shù)據(jù)的技術(shù)已經(jīng)相當(dāng)成熟。但這一塊的原理非常復(fù)雜,感興趣的話可以搜索血氧依賴機(jī)理,blood-oxygen-level-dependent, BOLD。
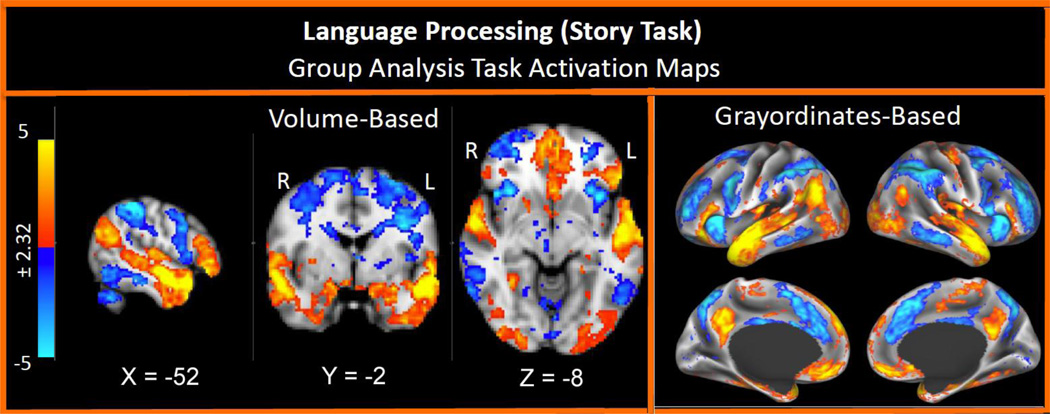
fMRI掃描所得到的數(shù)據(jù)是以三維形式的體素 (voxel)記錄的,每個(gè)數(shù)據(jù)點(diǎn)包括了三維坐標(biāo),電信號(hào)幅度等信息,維度很高。為了避免對(duì)體素直接進(jìn)行運(yùn)算,一般采用的方法是劃興趣區(qū)域 (Region of Interest, ROI),對(duì)電信號(hào)求時(shí)序上的均值,最終獲得一列體素,這樣的數(shù)據(jù)在緯度方面和通常處理的圖像數(shù)據(jù)存在相當(dāng)?shù)牟罹啵?/span> 鄰近的體素往往電信號(hào)幅度相近,fMRI收集的信息中存在一定冗余; 因?yàn)槿四X的復(fù)雜性,每個(gè)個(gè)體的數(shù)據(jù)都會(huì)存在一定的域偏移。

模型結(jié)構(gòu)
conditional synthesis是指限定某些特征后進(jìn)行數(shù)據(jù)生成。例如,生成微笑的不同人臉。
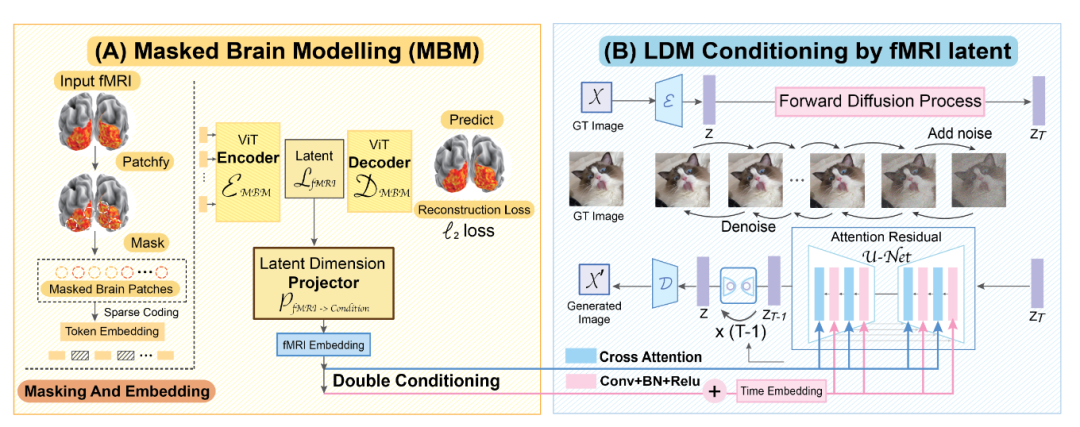
由于模型的結(jié)構(gòu)較為復(fù)雜,當(dāng)前版本的論文中沒(méi)有進(jìn)行更為詳細(xì)的描述,推薦極度好奇的讀者直接看開(kāi)源代碼。由于涉及了像Masked Brain Modeling,Diffusion Model這類前沿方法,在沒(méi)有一定基礎(chǔ)的情況下,想徹底吃透方法會(huì)需要相當(dāng)?shù)臅r(shí)間和精力,大家可以量力而行。
效果
由于fMRI的數(shù)據(jù)主要面向神經(jīng)科學(xué)方向的研究,滿足論文任務(wù)的數(shù)據(jù)量不大,模型的訓(xùn)練、驗(yàn)證、測(cè)試數(shù)據(jù)總共來(lái)自三個(gè)不同的數(shù)據(jù)集,不同集合的數(shù)據(jù)域都有所偏移。Human Connectome Project [1] 提供136,000個(gè)fMRI數(shù)據(jù)片段,沒(méi)有圖像,只有fMRI,主要是用來(lái)預(yù)訓(xùn)練模型的解碼部分。Generic Object Decoding Dataset (GOD) [3] 是主要面向fMRI-圖像任務(wù)的,包含1250張來(lái)自200個(gè)類別的圖像,其中50張被用于測(cè)試。Brain, Object, Landscape Dataset (BOLD5000) [4] 則選取了113組fMRI-圖像數(shù)據(jù)對(duì),作為測(cè)試。


尾聲
[1] David C Van Essen, Stephen M Smith, Deanna M Barch, Timothy EJ Behrens, Essa Yacoub, Kamil Ugurbil, Wu-Minn HCP Consortium, et al. The wu-minn human connectome project: an overview. Neuroimage, 80:62–79, 2013.
[2] He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Tomoyasu Horikawa and Yukiyasu Kamitani. Generic decoding of seen and imagined objects using hierarchical visual features. Nature communications, 8(1):1–15, 2017.
[4] Nadine Chang, John A Pyles, Austin Marcus, Abhinav Gupta, Michael J Tarr, and Elissa M Aminoff. Bold5000, a public fmri dataset while viewing 5000 visual images. Scientific data, 6(1):1–18, 2019.
評(píng)論
圖片
表情