
Mysql中join的那些事
作者丨黎杜
來源丨黎杜編程
但是,join的原理確實(shí)博大精深,對于一些傳統(tǒng)it企業(yè),幾乎是一句sql走天下,join了五六個(gè)表,當(dāng)數(shù)據(jù)量上來的時(shí)候,就會(huì)變得非常慢,索引對于掌握join的優(yōu)化還是非常有必要的。
阿里的開發(fā)手冊中規(guī)定join不能查過三個(gè),有些互聯(lián)網(wǎng)是明確規(guī)定不能使用join的的明文規(guī)定,那么在實(shí)際的場景中,我們真的不能使用join嗎?我們就來詳細(xì)的聊一聊。
Mysql的join主要涉及到三種算法,分別是Simple Nested-Loop Join、Block Nested-Loop Join、Index Nested-Loop Join,下面我們就來深入的了解這三種算法的原理、區(qū)別、效率。
首先,為了測試先準(zhǔn)備兩個(gè)表作為測試表,并且使用存儲(chǔ)過程初始化一些測試數(shù)據(jù),初始化的表結(jié)構(gòu)sql如下所示:
CREATE TABLE `testa` (
`id` int(20) NOT NULL AUTO_INCREMENT COMMENT '活動(dòng)主鍵',
`col1` int(20) NOT NULL DEFAULT '0' COMMENT '測試字段1',
`col2` int(20) NOT NULL DEFAULT '0' COMMENT '測試字段2',
PRIMARY KEY (`id`),
KEY `col1` (`idx_col1`)
)ENGINE=InnoDB AUTO_INCREMENT=782 DEFAULT CHARSET=utf8mb4 COMMENT='測試表1';
CREATE TABLE `testb` (
`id` int(20) NOT NULL AUTO_INCREMENT COMMENT '活動(dòng)主鍵',
`col1` int(20) NOT NULL DEFAULT '0' COMMENT '測試字段1',
`col2` int(20) NOT NULL DEFAULT '0' COMMENT '測試字段2',
PRIMARY KEY (`id`),
KEY `col1` (`idx_col1`)
) ENGINE=InnoDB AUTO_INCREMENT=782 DEFAULT CHARSET=utf8mb4 COMMENT='測試表2';
初始化數(shù)據(jù):
CREATE DEFINER = `root` @`localhost` PROCEDURE `init_data` ()
BEGIN
DECLARE i INT;
SET i = 1;
WHILE ( i <= 100 ) DO
INSERT INTO testa VALUES ( i, i, i );
SET i = i + 1;
END WHILE;
SET i = 1;
WHILE ( i <= 2000) DO
INSERT INTO test2 VALUES ( i, i, i );
SET i = i + 1;
END WHILE;
END
分別初始化testa表為100條數(shù)據(jù),testb為2000條數(shù)據(jù)
Simple Nested-Loop Join
首先,我們執(zhí)行如下sql:
select * from testa ta left join testb tb on (ta.col1=tb.col2);
Simple Nested-Loop Join是最簡單也是最粗暴的join方法,上面的sql在testb 的col2字段是沒有加索引的,所以當(dāng)testa為驅(qū)動(dòng)表,testb為被驅(qū)動(dòng)表時(shí),就會(huì)拿著testa的每一行,然后去testb的全表掃描,執(zhí)行流程如下:
-
從表testa中取出一行數(shù)據(jù),記為ta。 -
從ta中取出col1字段去testb中全表掃描查詢。 -
找到testb中滿足情況的數(shù)據(jù)與ta組成結(jié)果集返回。 -
重復(fù)執(zhí)行1-3步驟,直到把testa表的所有數(shù)據(jù)都取完。
因此掃描的時(shí)間復(fù)雜度就是100*2000=20W的行數(shù),所以在被驅(qū)動(dòng)表關(guān)聯(lián)字段沒有添加索引的時(shí)候效率就非常的低下。
假如testb是百萬數(shù)據(jù)以上,那么掃描的時(shí)間復(fù)雜度就更恐怖了,但是在Mysql中沒有使用這個(gè)算法,而是使用了另一種算法Block Nested-Loop Join,目的就是為了優(yōu)化驅(qū)動(dòng)表沒有索引時(shí)的查詢。
Block Nested-Loop Join
還是上面的sql,不過通過加explain關(guān)鍵字來查看這條sql的執(zhí)行計(jì)劃:
explain select * from testa ta left join testb tb on (ta.col1=tb.col2);

可以看到testb依舊是全表掃描,并且在Extra字段中可以看到testb的Using join buffer(hash join)的字樣,在rows中可以看到總掃描的行數(shù)是驅(qū)動(dòng)表行數(shù)+被驅(qū)動(dòng)表行數(shù),那么這個(gè)算法與Simple Nested-Loop Join有什么區(qū)別呢?
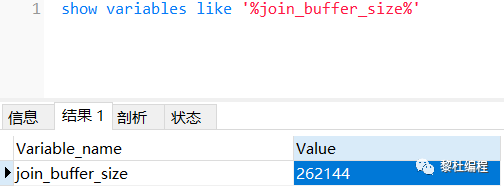
Block Nested-Loop Join算法中引入了join buffer區(qū)域,而join buffer是一塊內(nèi)存區(qū)域,它的大小由join_buffer_size參數(shù)大小控制,默認(rèn)大小是256k:
在執(zhí)行上面的sql的時(shí)候,它會(huì)把testa表的數(shù)據(jù)全部加載到j(luò)oin buffer區(qū)域,因?yàn)閖oin buffer是內(nèi)存操作,因此相對于比上面的simple算法要高效,具體的執(zhí)行流程如下:
-
首先把testa表的所有數(shù)據(jù)都加在到j(luò)oin buffer里面,這里的所有數(shù)據(jù)是select后面的testa的字段,因?yàn)檫@里是select *,所以就是加載所有的testa字段。 -
然后遍歷的取testb表中的每一行數(shù)據(jù),并且與join buffer里面的數(shù)據(jù)濟(jì)寧對比,符合條件的,就作為結(jié)果集返回。
具體的流程圖如下所示:
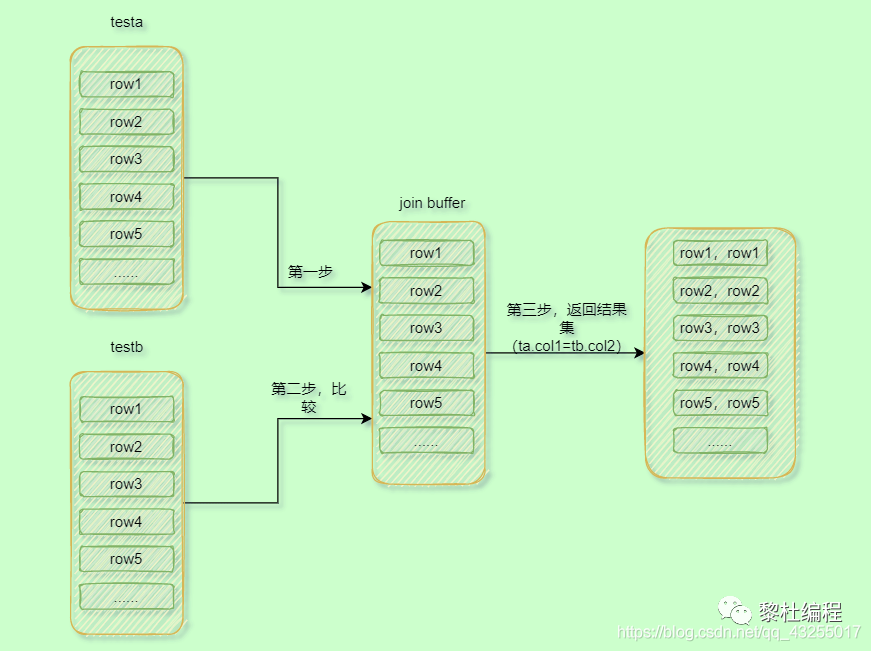
所以,從上面的執(zhí)行的步驟來看(假設(shè)驅(qū)動(dòng)表的行數(shù)為N,被驅(qū)動(dòng)表的行數(shù)據(jù)為M),Block Nested-Loop Join的掃描的行數(shù)還是驅(qū)動(dòng)表+被驅(qū)動(dòng)表行數(shù)(N+M),在內(nèi)存中總的比較次數(shù)還是驅(qū)動(dòng)表*被驅(qū)動(dòng)表行數(shù)(N*M)
上面我們提到j(luò)oin buffer是一塊內(nèi)存區(qū)域,并且有自己的大小,要是join buffer的大小不足夠容納驅(qū)動(dòng)表的數(shù)量級(jí)怎么辦呢?
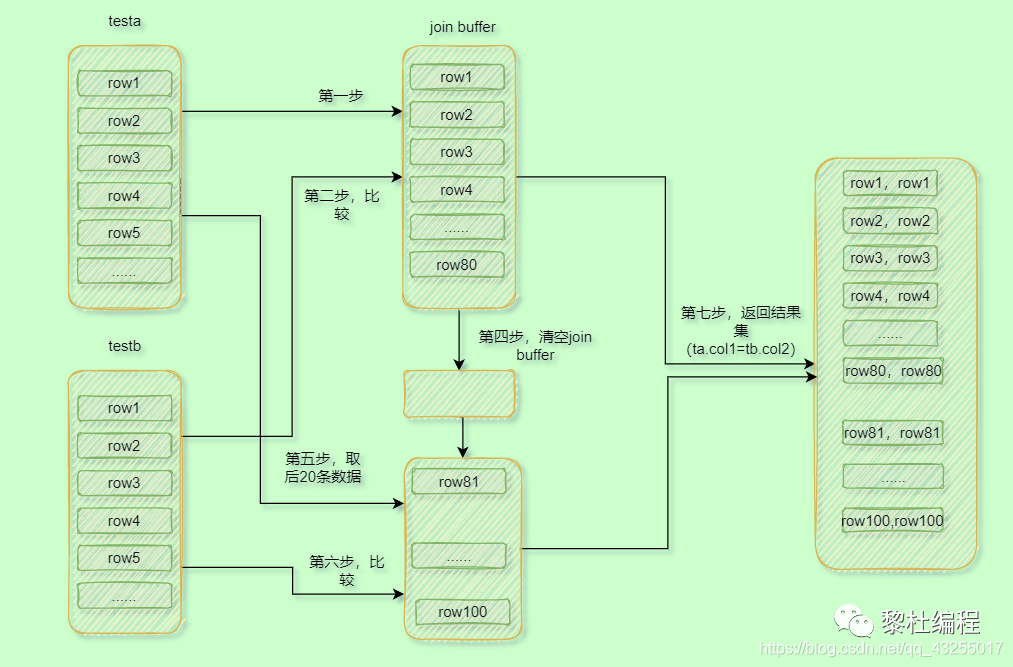
答案就是分段,你要是join buffer沒辦法容納驅(qū)動(dòng)表的所有數(shù)據(jù),那么就不把所有的數(shù)據(jù)加載到j(luò)oin buffer里面,先加載一部分,后面再加載另一部分,比如:先加載testa中的80條數(shù)據(jù),與testb比較完數(shù)據(jù)后,清空再加載testa后20條數(shù)據(jù),再與testb進(jìn)行比較。具體執(zhí)行流程如下:
-
先加載testa中的80條數(shù)據(jù)到j(luò)oin buffer -
然后一次遍歷testb的所有數(shù)據(jù),與join buffer里面的數(shù)據(jù)進(jìn)行比較,符合條件的組成結(jié)果集。 -
清空join buffer,再加載testa后面的20條數(shù)據(jù)。 -
然后一次遍歷testb的所有數(shù)據(jù),與join buffer里面的數(shù)據(jù)進(jìn)行比較,符合條件的組成結(jié)果集并返回。
執(zhí)行流程圖如下所示:
從上面的結(jié)果來看相對于比內(nèi)存足夠的join buffer來說,分段的join buffer多了一遍全表全表遍歷testb,并且分的段數(shù)越多,多掃描驅(qū)動(dòng)表的次數(shù)就越多。,性能就越差,所以在某一些場景下,適當(dāng)?shù)脑龃骿oin buffer的值,是能夠提高join的效率。
假如驅(qū)動(dòng)表的行數(shù)是N,分段參數(shù)為K,被驅(qū)動(dòng)表的行數(shù)是M,那么總的掃描行數(shù)還是N+K*M,而內(nèi)存比較的次數(shù)還是N*M,沒有變。
其中K段數(shù)與N的數(shù)據(jù)量有關(guān),若是N的數(shù)據(jù)量越大,那么可能K被分成段數(shù)就越多,這樣多次重復(fù)掃描的被驅(qū)動(dòng)表的次數(shù)就越多。
所以在join buffer不夠的情況小,驅(qū)動(dòng)表是越小越好,能夠減少K值,減少重復(fù)掃描被驅(qū)動(dòng)表的次數(shù)。這也就是為什么提倡小表要作為驅(qū)動(dòng)表的原因。
那么這里提到小表的概念,是不是就是數(shù)據(jù)量少的就是認(rèn)為是小表呢?其實(shí)不然,小表的真正的還是是實(shí)際參與join的數(shù)據(jù)量,比如以下的兩條sql:
select * from testa ta left join testb tb on (ta.col1=tb.col2) where tb.id<=20;
select * from testb tb left join testa ta on (ta.col1=tb.col2) where tb.id<=20;
在第二條sql中,雖然testb驅(qū)動(dòng)表數(shù)據(jù)量比較大,但是在where條件中實(shí)際參與join的行數(shù)也就是id小于等于20的數(shù)據(jù),完全小于testa的數(shù)據(jù)量,所以這里選擇以testb作為驅(qū)動(dòng)表是更加的合適。
在實(shí)際的開發(fā)中Block Nested-Loop Join也是嚴(yán)禁被禁止出現(xiàn)的,嚴(yán)格要求關(guān)聯(lián)條件建索引,所以性能最好的就是Index Nested-Loop Join算法。
Index Nested-Loop Join
當(dāng)我們執(zhí)行如下sql時(shí):
select * from testa ta left join testb tb on (ta.col1=tb.col1);

它的執(zhí)行流程如下:
-
首先取testa表的一行數(shù)據(jù)。 -
使用上面的行數(shù)據(jù)的col1字段去testb表進(jìn)行查詢。 -
在testb找到符合條件的數(shù)據(jù)行,并與testa的數(shù)據(jù)行組合作為結(jié)果集。 -
重復(fù)執(zhí)行1-3步驟,直到取完testa表的所有數(shù)據(jù)。
因?yàn)閠estb的col1字段是建立了索引,所以,當(dāng)使用testa表的字段col1去testb查找的時(shí)候,testb走的是col1索引的b+樹的搜索,時(shí)間復(fù)雜度近似log2M,并且因?yàn)槭莝elect*,也就是要查找testb的所有字段,所以這里也涉及到回表查詢,因此就變成了2*log2M,若是不懂回表的,可以參考這一篇文章:十萬個(gè)為什么,精通Mysql索引
在這個(gè)過程中,testa表的掃描行數(shù)是全部,所以需要掃描100行,然后testa的每一行都與testb也是一一對應(yīng)的,所以col1索引查詢掃描的行數(shù)也是100行,所以總的掃描行數(shù)就是200行。
我們假設(shè)驅(qū)動(dòng)表的數(shù)據(jù)行位N,被驅(qū)動(dòng)表的數(shù)據(jù)行為M,那么近似的復(fù)雜度為:N+N*2*log M,因?yàn)轵?qū)動(dòng)表的掃描行數(shù)就是N,然后被驅(qū)動(dòng)表因?yàn)槊恳淮味紝?yīng)驅(qū)動(dòng)表的一次,并且一次的時(shí)間復(fù)雜度就是近似2*log M,所以被驅(qū)動(dòng)表就是N*2*log M。
明顯N的值對于N+N*2*log M的結(jié)果值影響更大,所以N越小越好,所以選擇小表作為驅(qū)動(dòng)表是最優(yōu)選擇。
在一些情況下的優(yōu)化,假如join的驅(qū)動(dòng)表所需要的字段很少(兩個(gè)),可以建立聯(lián)合索引來優(yōu)化join查詢,并且如果業(yè)務(wù)允許的話,可以通過冗余字段,減少join的個(gè)數(shù)提高查詢的效率。
好了,這一期就分享join的原理,以及join一些優(yōu)化的手段和注意的事項(xiàng),我們下一期見。
參考
《Mysql 45講》
-End-
最近有一些小伙伴,讓我?guī)兔φ乙恍?nbsp;面試題 資料,于是我翻遍了收藏的 5T 資料后,匯總整理出來,可以說是程序員面試必備!所有資料都整理到網(wǎng)盤了,歡迎下載!
點(diǎn)擊??卡片,關(guān)注后回復(fù)【 面試題】即可獲取
