
利用Python分析數(shù)據(jù)分析師招聘現(xiàn)狀
作者介紹
越來越多的小伙伴想要入行或者轉(zhuǎn)行數(shù)據(jù)分析,作為圈內(nèi)老鳥,將使用 pandas 和 Matplotlib 分析一下數(shù)據(jù)分析師崗位目前現(xiàn)狀,希望可以幫到他們。
01
分析目標
1) 公司都要求掌握什么技能?
2) 學歷要求高嗎?
3) 薪資怎么分布?
4) 不同細分領(lǐng)域?qū)?shù)據(jù)分析的需求情況?
5) 各大城市對數(shù)據(jù)分析崗位的需求情況?
6) 工作經(jīng)驗與薪水有什么關(guān)系?
7) 不同規(guī)模的企業(yè)對經(jīng)驗的要求以及提供薪資的水平是什么?
02
數(shù)據(jù)加載
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontManagerfrom matplotlib import gridspecjobData = pd.read_csv('zhaopin.csv')jobData.drop_duplicates(inplace = True) # 刪除重復(fù)數(shù)據(jù)jobData
部分數(shù)據(jù)如下圖所示

03
數(shù)據(jù)預(yù)處理
1)過濾非數(shù)據(jù)分析的崗位
isTrue = jobData['positionName'].str.contains('數(shù)據(jù)分析') # 職位中是否包含‘數(shù)據(jù)分析’jobData = jobData[isTrue] # 篩選出想要的字段jobData.reset_index(inplace=True) # 重置行索引jobData
2)用均值作為相應(yīng)職位的薪水
薪水是一個區(qū)間,所以用薪水區(qū)間的均值作為相應(yīng)職位的薪水
jobData['salary'] = jobData['salary'].str.lower()\.str.extract(r'(\d+)[k]-(\d+)k')\.applymap(lambda x:int(x))\.mean(axis=1) # 用薪水區(qū)間的均值作為薪水jobData
3)提取技能要求
將技能分為:Python、SQL、Tableau、Excel、SPSS/SAS、R、數(shù)據(jù)挖掘。如果job_detail中含有這些技能,則賦值為1,否則為0
jobData['job_detail'] = jobData['job_detail'].str.lower().fillna('') # 將字母小寫,缺失值賦為空字符串jobData['python'] = jobData['job_detail'].map(lambda x:1 if('python' in x) else 0)jobData['SQL'] = jobData['job_detail'].map(lambda x:1 if('sql' in x) or ('hive' in x) else 0)jobData['Tableau'] = jobData['job_detail'].map(lambda x:1 if 'tableau' in x else 0)jobData['Excel'] = jobData['job_detail'].map(lambda x:1 if 'excel' in x else 0)jobData['SPSS/SAS'] = jobData['job_detail'].map(lambda x:1 if ('spss' in x) or ('sas' in x) else 0)jobData['R'] = jobData['job_detail'].map(lambda x:1 if('r' in x) else 0)jobData['數(shù)據(jù)挖掘'] = jobData['job_detail'].map(lambda x:1 if('挖掘') else 0)jobData
04
數(shù)據(jù)可視化分析
1)各城市對數(shù)據(jù)分析師的需求量
plt.rcParams['font.family'] = 'Heiti TC'plt.figure(figsize=(12, 9))cities = jobData['city'].value_counts()plt.barh(y = cities.index[::-1],width = cities.values[::-1],color = '#78a355')plt.box(False) # 不顯示邊框plt.title(label='各城市數(shù)據(jù)分析崗位的需求量',fontsize = 32, weight = 'bold', color = 'white',backgroundcolor = '#f47920', pad = 30)plt.tick_params(labelsize = 16)plt.grid(ls = '--', axis = 'x', linewidth = 0.5, color = '#78a355')
如下圖得知,一線城市數(shù)據(jù)分析師崗位較多,其中北京數(shù)據(jù)分析師崗位需求最多,其次是上海需求緊隨其后。
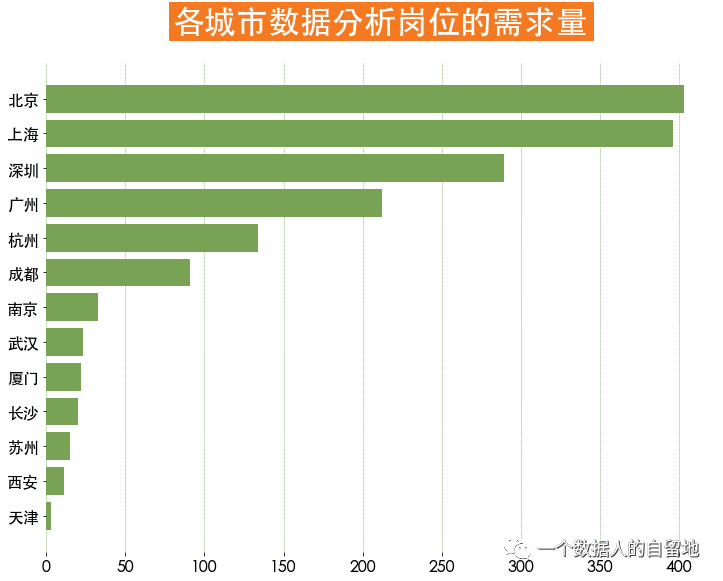
2)不同行業(yè)對數(shù)據(jù)分析師的需求量
industry_index = jobData['industryField'].value_counts()[:10].indexindustry = jobData.loc[jobData['industryField'].isin(industry_index), 'industryField']plt.figure(figsize=(12, 9))plt.barh(y = industry_index[::-1],width=pd.Series.value_counts(industry.values).values[::-1],color = '#78a355')plt.box(False) # 不顯示邊框plt.title('不同領(lǐng)域?qū)?shù)據(jù)分析崗位的需求量(前十)',fontsize = 32, weight = 'bold', color = 'white',backgroundcolor = '#f47920', pad = 30)plt.tick_params(labelsize = 16)plt.grid(ls = '--', axis = 'x', linewidth = 0.5, color = '#78a355')
如下圖得知,電商對于數(shù)據(jù)分析師的需求量最大,其次是金融。
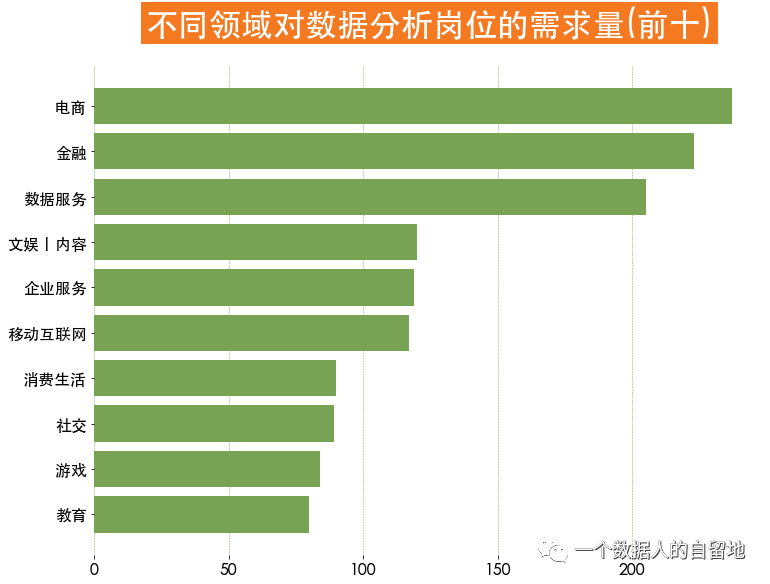
3)各城市薪資狀況
plt.figure(figsize=(12, 9))city_salary = jobData.groupby('city')['salary'].mean().sort_values(ascending=False)plt.bar(x = city_salary.index, height = city_salary.values,color = plt.cm.coolwarm_r(np.linspace(0,1,len(city_salary))))plt.title('各大城市的薪資對比',fontsize = 32, weight = 'bold', color = 'white',backgroundcolor = '#f47920', pad = 30)plt.tick_params(labelsize = 16)plt.grid(ls = '--', axis = 'y', linewidth = 0.5, color = '#a1a3a6')plt.yticks(ticks=np.arange(0, 25, step=5), labels=['', '5k', '10,', '15k', '20k'])plt.box(False)
如下圖得知,北京薪資最高,其次上海僅次于杭州。
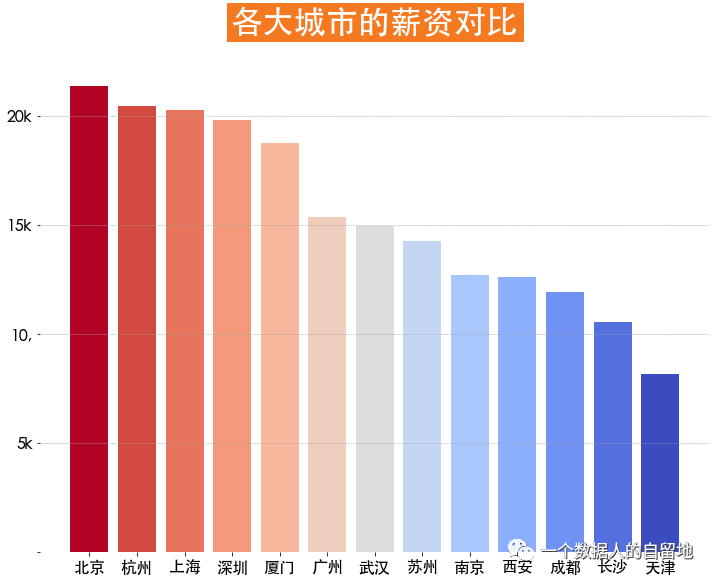
4)工作經(jīng)驗與薪水關(guān)系
work_salary = jobData.pivot_table(index='city', columns='workYear', values='salary')work_salary = work_salary[['應(yīng)屆畢業(yè)生', '1-3年', '3-5年', '5-10年', '10年以上']]\.sort_values(by='10年以上', ascending=False)data = work_salary.valuesdata = np.repeat(data, 4, axis=1)plt.figure(figsize=(12, 9))# plt.cm.OrRd_rplt.imshow(data, cmap='RdBu_r')plt.yticks(np.arange(13), work_salary.index)plt.xticks(np.array([1.5, 5.5, 9.5, 13.5, 17.5]), work_salary.columns)h, w = data.shapefor x in range(w):for y in range(h):if (x%4==0) and (~np.isnan(data[y, x])):text = plt.text(x+1.5, y, round(data[y, x], 1),ha='center', va='center', color='r', fontsize=16)plt.colorbar(shrink=0.72)plt.title('工作經(jīng)驗與薪水關(guān)系',fontsize = 32, weight = 'bold', color = 'white',backgroundcolor = '#f47920', pad = 30)plt.tick_params(labelsize = 16)
如下圖所示,數(shù)據(jù)分析師的工作經(jīng)驗與薪水成正比,北京工作10年以上的年薪是應(yīng)屆畢業(yè)生的5倍。
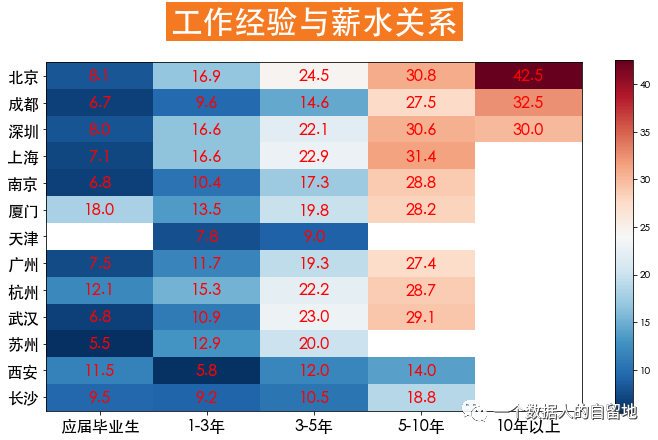
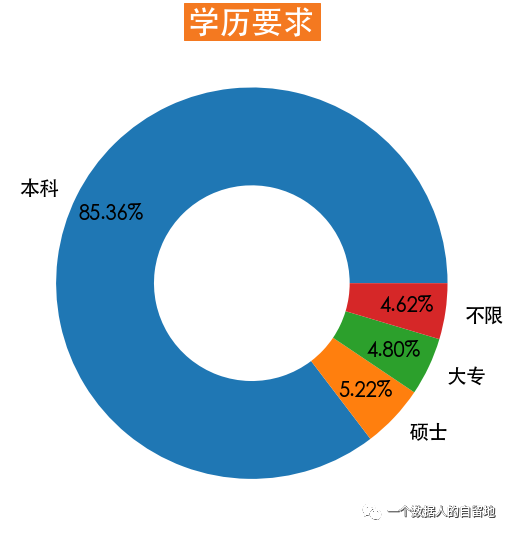
5)學歷要求
education = jobData['education'].value_counts(normalize=True)plt.figure(figsize=(9, 9))plt.pie(education, labels=education.index, autopct='%0.2f%%',wedgeprops=dict(linewidth=3, width=0.5), pctdistance=0.8,textprops=dict(fontsize=20))plt.title(label='學歷要求',fontsize=32, weight='bold',color='white', backgroundcolor='#f47920')
如下圖所示,85.36%的數(shù)據(jù)分析師崗位的學歷要求最低是本科,5.22%的崗位要求最低是碩士。
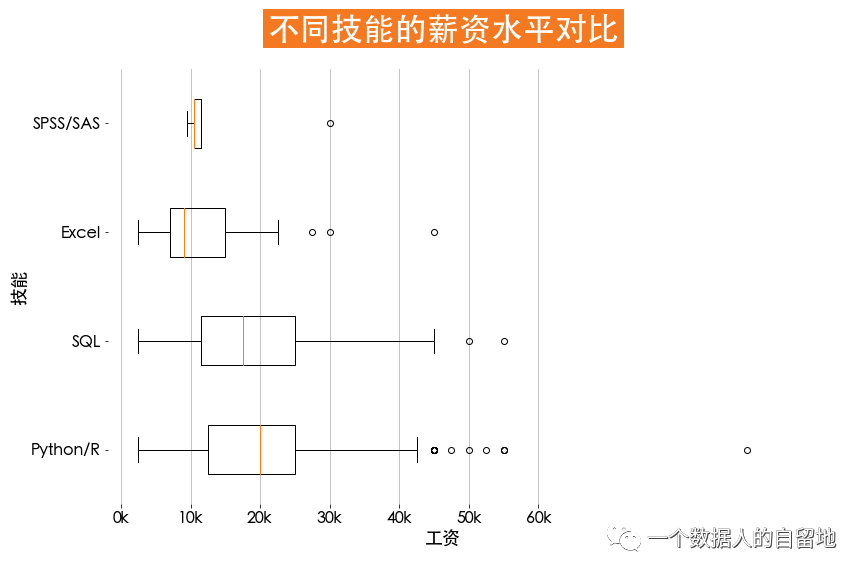
6)技能要求
def get_level(x):if x['python'] == 1:x['skill'] = 'Python/R'elif x['R'] == 1:x['skill'] = 'Python/R'elif x['SQL'] == 1:x['skill'] = 'SQL'elif x['Excel'] == 1:x['skill'] = 'Excel'elif x['SPSS/SAS'] == 1:x['skill'] = 'SPSS/SAS'else:x['skill'] = '其他'return xjobData = jobData.apply(get_level, axis=1) # 數(shù)據(jù)轉(zhuǎn)換# 獲取主要技能x = jobData.loc[jobData.skill!='其他'][['salary', 'skill']]condition1 = x['skill'] == 'Python/R'condition2 = x['skill'] == 'SQL'condition3 = x['skill'] == 'Excel'condition4 = x['skill'] == 'SPSS/SAS'plt.figure(figsize=(12, 8))plt.title(label='不同技能的薪資水平對比',fontsize=32, weight='bold', color='white',backgroundcolor='#f47920', pad=30)plt.boxplot(x=[jobData.loc[jobData.skill!='其他']['salary'][condition1],jobData.loc[jobData.skill!='其他']['salary'][condition2],jobData.loc[jobData.skill!='其他']['salary'][condition3],jobData.loc[jobData.skill!='其他']['salary'][condition4]],vert=False, labels=['Python/R', 'SQL', 'Excel', 'SPSS/SAS'])plt.tick_params(axis='both', labelsize=16)plt.grid(axis='x', linewidth=0.75)plt.xticks(np.arange(0, 61, 10), [str(i)+'k' for i in range(0, 61, 10)])plt.box(False)plt.xlabel('工資', fontsize=18)plt.ylabel('技能', fontsize=18)
如下圖所示,Python/R的異常值、中位數(shù)最高,SQL的上限較高,并且上限和下限差別最大。
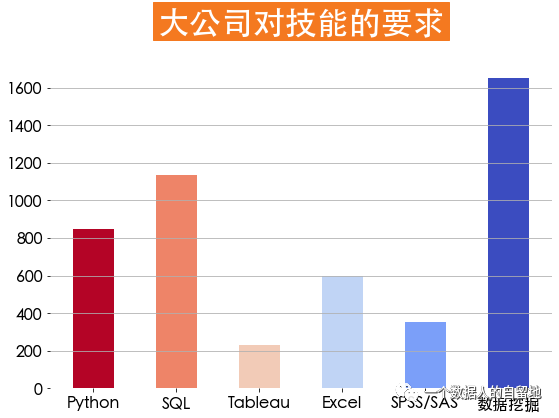
7)大公司對技能要求
job_skills = jobData[jobData['companySize'] == '2000人以上']labels = ['Python', 'SQL', 'Tableau', 'Excel', 'SPSS/SAS', '數(shù)據(jù)挖掘']counts =[]counts.append(jobData['python'].sum())counts.append(jobData['SQL'].sum())counts.append(jobData['Tableau'].sum())counts.append(jobData['Excel'].sum())counts.append(jobData['SPSS/SAS'].sum())counts.append(jobData['數(shù)據(jù)挖掘'].sum())plt.figure(figsize=(9, 6))plt.bar(x=labels, height=counts,width=0.5,color=plt.cm.coolwarm_r(np.linspace(0,1,len(counts))))np.linspace(0,1,len(counts))plt.title(label='大公司對技能的要求',fontsize=32, weight='bold', color='white',backgroundcolor='#f47920', pad=30)plt.tick_params(labelsize=16,)plt.grid(axis='y')plt.box(False)
由下圖得知,大公司要求最多的是數(shù)據(jù)挖掘,其次是SQL、Python。
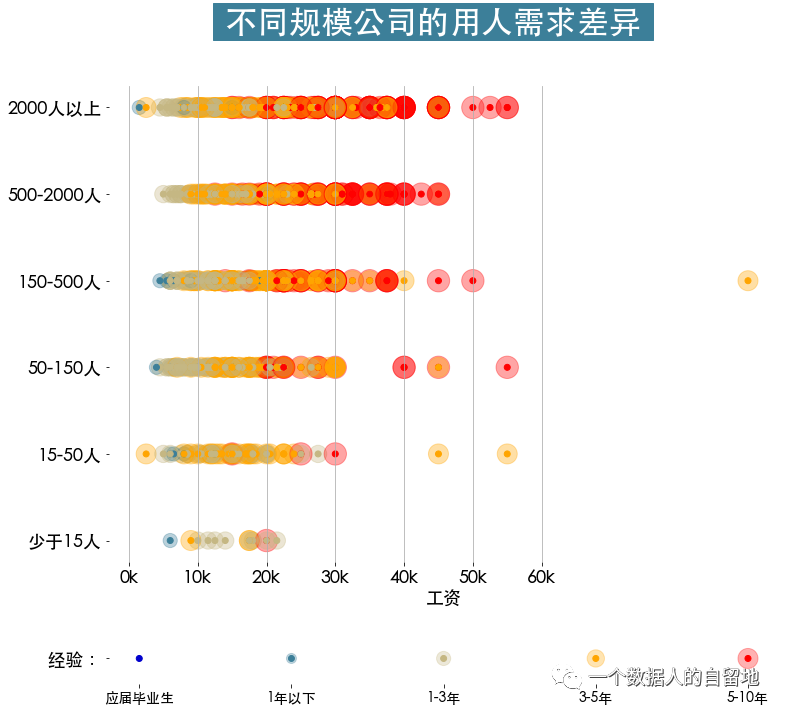
8)不同規(guī)模的公司在招人要求上的差異
color_map = {5:"#ff0000",4:"#ffa500",3:"#c5b783",2:"#3c7f99",1:"#0000cd"}cond = jobData.workYear.isin({'5-10年':5, '3-5年':4, '1-3年':3, '1年以下':2, '應(yīng)屆畢業(yè)?':1})jobData = jobData[cond]jobData['workYear'] = jobData.workYear.map(workYear_map)# 根據(jù)companySize進?排序,?數(shù)從多到少jobData['companySize'] = jobData['companySize'].astype('category')# list_custom = ['2000?以上', '500-2000?','150-500?','50-150?','15-50?','少于15?']list_custom = ['2000人以上', '500-2000人', '150-500人', '50-150人', '15-50人', '少于15人']# inplace = True,使 recorder_categories生效jobData['companySize'].cat.reorder_categories(list_custom, inplace=True)# inplace = True,使 df生效jobData.sort_values(by = 'companySize',inplace = True,ascending = False)plt.figure(figsize=(12,11))gs = gridspec.GridSpec(10,1)plt.subplot(gs[:8])plt.suptitle(t=' 不同規(guī)模公司的??需求差異 ',fontsize=32,weight='bold', color='white', backgroundcolor='#3c7f99')# 畫散點圖plt.scatter(jobData.salary,jobData.companySize,c = jobData.workYear.map(color_map),s = (jobData.workYear*100),alpha = 0.35)plt.scatter(jobData.salary,jobData.companySize,c = jobData.workYear.map(color_map))plt.grid(axis = 'x')plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])plt.xlabel('?資', fontsize=18)plt.box(False)plt.tick_params(labelsize = 18)# 繪制底部標記plt.subplot(gs[9:])x = np.arange(5)[::-1]y = np.zeros(len(x))s = x*100plt.scatter(x,y,s=s,c=color_map.values(),alpha=0.3)plt.scatter(x,y,c=color_map.values())plt.box(False)plt.xticks(ticks=x,labels=list(workYear_map.keys()),fontsize=14)plt.yticks(np.arange(1),labels=[' 經(jīng)驗:'],fontsize=18)
由下圖得知,大部分公司對工作經(jīng)驗為3年以上的求職者,需求量大。其中,需求量最大的是中大型公司。
05
結(jié)論
1)北京為數(shù)據(jù)分析師需求量最大的一線城市;
2)一線城市的數(shù)據(jù)分析師崗位的薪資很有競爭力;
3)數(shù)據(jù)分析工程師的核心技能:數(shù)據(jù)挖掘、SQL、Python等。




