
【知識蒸餾】Deep Mutual Learning
【GiantPandaCV導(dǎo)語】
Deep Mutual Learning(DML)是Knowledge Distillation的外延,經(jīng)過測試(代碼來自Knowledge-Distillation-Zoo), Deep Mutual Learning性能確實(shí)超出了原始KD很多,所以本文分析這篇CVPR2018年被接受的論文。同時PPOCRv2中也提到了DML,并提出了CML,取得效果顯著。
引言
首先感謝:https://github.com/AberHu/Knowledge-Distillation-Zoo
筆者在這個基礎(chǔ)上進(jìn)行測試,測試了在CIFAR10數(shù)據(jù)集上的結(jié)果。
學(xué)生網(wǎng)絡(luò)resnet20:92.29%?
教師網(wǎng)絡(luò)resnet110:94.31%
這里只展示幾個感興趣的算法結(jié)果帶來的收益:
logits(mimic learning via regressing logits): + 0.78
ST(soft target): + 0.16
OFD(overhaul of feature distillation): +0.45
AT(attention transfer): +0.71
NST(neural selective transfer): +0.38
RKD(relational knowledge distillation): +0.65
AFD(attention feature distillation): +0.18
DML(deep mutual learning): + 2.24 ?(ps: 這里教師網(wǎng)絡(luò)已經(jīng)訓(xùn)練好了,與DML不同)
DML也是傳統(tǒng)知識蒸餾的擴(kuò)展,其目標(biāo)也是將大型模型壓縮為小的模型。但是不同于傳統(tǒng)知識蒸餾的單向蒸餾(教師→學(xué)生),DML認(rèn)為可以讓學(xué)生互相學(xué)習(xí)(雙向蒸餾),在整個訓(xùn)練的過程中互相學(xué)習(xí),通過這種方式可以提升模型的性能。
DML通過實(shí)驗(yàn)證明在沒有先驗(yàn)強(qiáng)大的教師網(wǎng)絡(luò)的情況下,僅通過學(xué)生網(wǎng)絡(luò)之間的互相學(xué)習(xí)也可以超過傳統(tǒng)的KD。
如果傳統(tǒng)的知識蒸餾是由教師網(wǎng)絡(luò)指導(dǎo)學(xué)生網(wǎng)絡(luò),那么DML就是讓兩個學(xué)生互幫互助,互相學(xué)習(xí)。
DML
小型的網(wǎng)絡(luò)通常有與大網(wǎng)絡(luò)相同的表示能力,但是訓(xùn)練起來比大網(wǎng)絡(luò)更加困難。那么先訓(xùn)練一個大型的網(wǎng)絡(luò),然后通過使用模型剪枝、知識蒸餾等方法就可以讓小型模型的性能提升,甚至超過大型模型。
以知識蒸餾為例,通常需要先訓(xùn)練一個大而寬的教師網(wǎng)絡(luò),然后讓小的學(xué)生網(wǎng)絡(luò)來模仿教師網(wǎng)絡(luò)。通過這種方式相比直接從hard label學(xué)習(xí),可以降低學(xué)習(xí)的難度,這樣學(xué)生網(wǎng)絡(luò)甚至可以比教師網(wǎng)絡(luò)更強(qiáng)。
Deep Mutual Learning則是讓兩個小的學(xué)生網(wǎng)絡(luò)同時學(xué)習(xí),對于每個單獨(dú)的網(wǎng)絡(luò)來說,會有針對hard label的分類損失函數(shù),還有模仿另外的學(xué)生網(wǎng)絡(luò)的損失函數(shù),用于對齊學(xué)生網(wǎng)絡(luò)的類別后驗(yàn)。
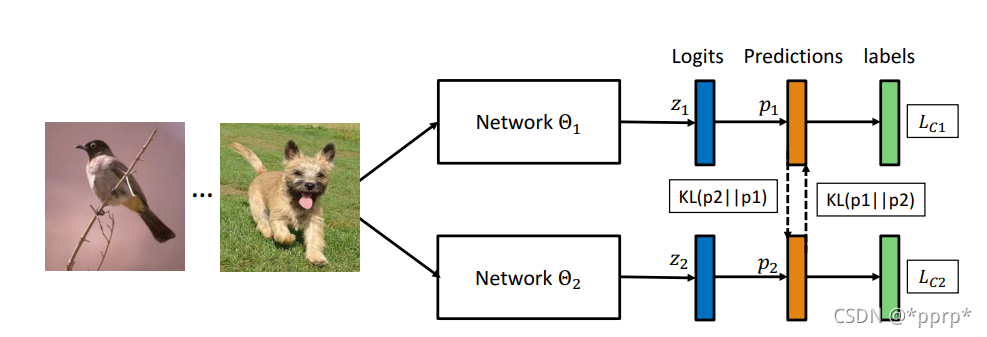
這種方式一般會產(chǎn)生這樣的疑問,兩個隨機(jī)初始化的學(xué)生網(wǎng)絡(luò)最初階段性能都很差的情況,這樣相互模仿可能會導(dǎo)致性能更差,或者性能停滯不前(the blind lead the blind)。
文章中這樣進(jìn)行解釋:
每個學(xué)生主要是倍傳統(tǒng)的有監(jiān)督學(xué)習(xí)損失函數(shù)影響,這意味著學(xué)生網(wǎng)絡(luò)的性能大體會是增長趨勢,這意味著他們的表現(xiàn)通常會提高,他們不能作為一個群體任意地漂移到群體思維。(原文:they cannot drift arbitrarily into groupthink as a cohort.)
在監(jiān)督信號下,所有的網(wǎng)絡(luò)都會朝著預(yù)測正確label的方向發(fā)展,但是不同的網(wǎng)絡(luò)在初始化值不同,他們會學(xué)到不同的表征,因此他們對下一類最有可能的概率的估計(jì)是不同的。
在Mutual Learning中,學(xué)生群體可以有效匯集下一個最后可能的類別估計(jì),為每個訓(xùn)練實(shí)例找到最有可能的類別,同時根據(jù)他們互學(xué)習(xí)對象增加每個學(xué)生的后驗(yàn)熵,有助于網(wǎng)絡(luò)收斂到更平坦的極小值,從而帶來更好的泛華能力和魯棒性。
Why Deep Nets Generalise 有關(guān)網(wǎng)絡(luò)泛化性能的討論認(rèn)為:在深度神經(jīng)網(wǎng)絡(luò)中,有很多解法(參數(shù)組合)可以使得訓(xùn)練錯誤為0,其中一些在比較loss landscape平坦處參數(shù)可以比其他narrow位置的泛華性能更好,所以小的干擾不會徹底改變預(yù)測的效果;
DML通過實(shí)驗(yàn)發(fā)現(xiàn):(1)訓(xùn)練過程損失可以接近于0 。(2)在擾動下對loss的變動接受能力更強(qiáng)。(3)給出的class置信度不會過于高。總體來說就是:DML并沒有幫助我們找到更好的訓(xùn)練損失最小值,而是幫助我們找到更廣泛/更穩(wěn)健的最小值,更好地對測試數(shù)據(jù)進(jìn)行泛華。
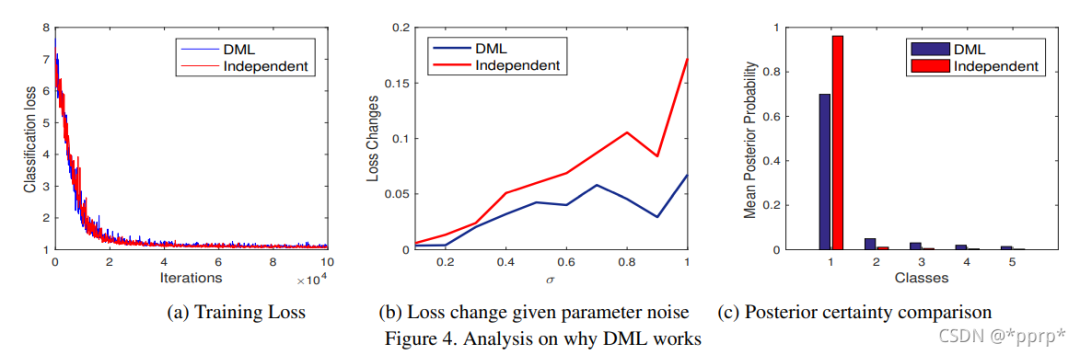
DML具有的特點(diǎn)是:
適合于各種網(wǎng)絡(luò)架構(gòu),由大小網(wǎng)絡(luò)混合組成的異構(gòu)的網(wǎng)絡(luò)也可以進(jìn)行相互學(xué)習(xí)(因?yàn)橹粚W(xué)習(xí)logits)
效能會隨著隊(duì)列中網(wǎng)絡(luò)數(shù)量的增加而增加,即互學(xué)習(xí)對象增多的時候,性能會有一定的提升。
有利于半監(jiān)督學(xué)習(xí),因?yàn)槠湓跇?biāo)記和未標(biāo)記數(shù)據(jù)上都激活了模仿?lián)p失。
雖然DML的重點(diǎn)是得到某一個有效的網(wǎng)絡(luò),整個隊(duì)列中的網(wǎng)絡(luò)可以作為模型集成的對象進(jìn)行集成。
DML中使用到了KL Divergence衡量兩者之間的差距:
P1和P2代表兩者的邏輯層輸出,那么對于每個網(wǎng)絡(luò)來說,他們需要學(xué)習(xí)的損失函數(shù)為:
其中代表傳統(tǒng)的分類損失函數(shù),比如交叉熵?fù)p失函數(shù)。
可以發(fā)現(xiàn)KL divergence是非對稱的,那么對兩個網(wǎng)絡(luò)來說,學(xué)習(xí)到的會有所不同,所以可以使用堆成的Jensen-Shannon Divergence Loss作為替代:
更新過程的偽代碼:

更多的互學(xué)習(xí)對象
給定K個互學(xué)習(xí)網(wǎng)絡(luò),, 那么目標(biāo)函數(shù)變?yōu)椋?/p>
將模仿信息變?yōu)槠渌W(xué)習(xí)網(wǎng)絡(luò)的KL divergence的均值。
擴(kuò)展到半監(jiān)督學(xué)習(xí)
在訓(xùn)練半監(jiān)督的時候,我們對于有標(biāo)簽數(shù)據(jù)只使用交叉熵?fù)p失函數(shù),對于所有訓(xùn)練數(shù)據(jù)(包括有標(biāo)簽和無標(biāo)簽)的計(jì)算KL Divergence 損失。
這是因?yàn)镵L Divergence loss的計(jì)算天然的不需要真實(shí)標(biāo)簽,因此有助于半監(jiān)督的學(xué)習(xí)。
實(shí)驗(yàn)結(jié)果
幾個網(wǎng)絡(luò)的參數(shù)情況:

在CIFAR10和CIFAR100上訓(xùn)練效果
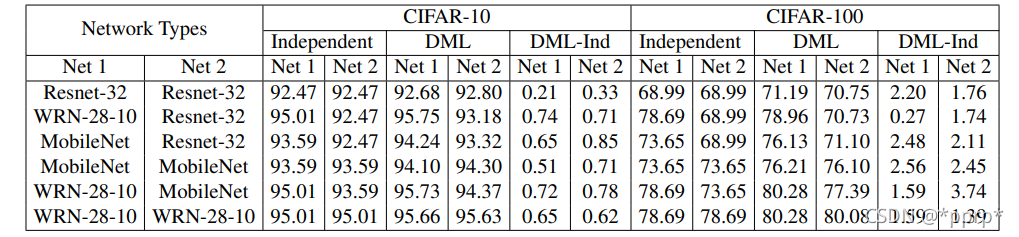
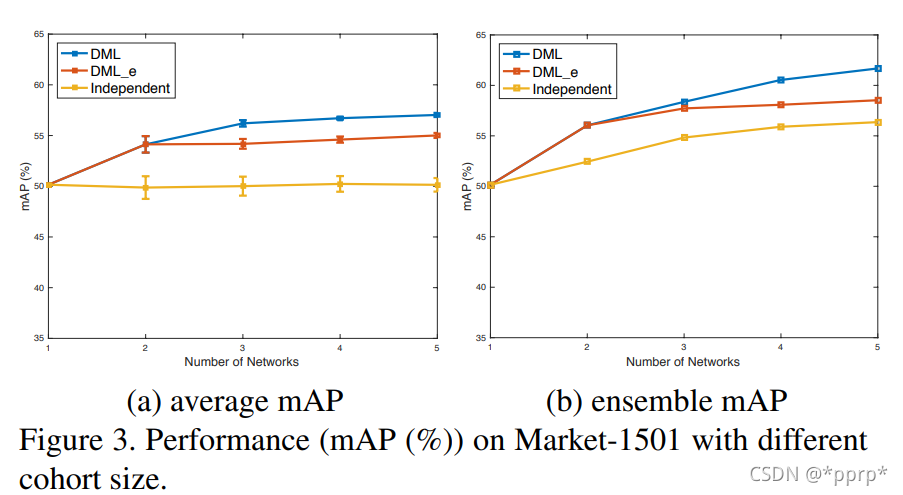
在Reid數(shù)據(jù)集Market-1501上也進(jìn)行了測試:
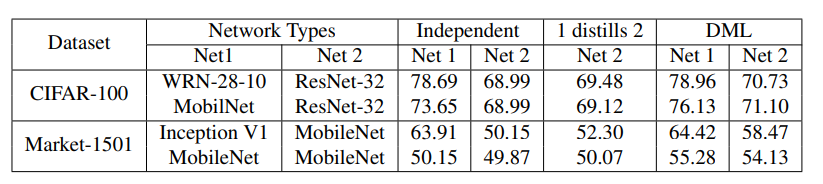
發(fā)現(xiàn)互學(xué)習(xí)目標(biāo)越多,性能呈上升趨勢:
結(jié)論
本文提出了一種簡單而普遍適用的方法來提高深度神經(jīng)網(wǎng)絡(luò)的性能,方法是在一個隊(duì)列中通過對等和相互蒸餾進(jìn)行訓(xùn)練。
通過這種方法,可以獲得緊湊的網(wǎng)絡(luò),其性能優(yōu)于那些從強(qiáng)大但靜態(tài)的教師中提煉出來的網(wǎng)絡(luò)。DML的一個應(yīng)用是獲得緊湊、快速和有效的網(wǎng)絡(luò)。文章還表明,這種方法也有希望提高大型強(qiáng)大網(wǎng)絡(luò)的性能,并且以這種方式訓(xùn)練的網(wǎng)絡(luò)隊(duì)列可以作為一個集成來進(jìn)一步提高性能。
參考
https://github.com/AberHu/Knowledge-Distillation-Zoo
https://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Deep_Mutual_Learning_CVPR_2018_paper.pdf
為了感謝讀者的長期支持,今天我們將送出三本由?人民郵電出版社?提供的:《openCV圖像處理入門與實(shí)踐》 。點(diǎn)擊下方抽獎助手參與抽獎。沒抽到并且對本書有興趣的也可以使用下方鏈接進(jìn)行購買。
