
知識蒸餾綜述:蒸餾機制
【GiantPandaCV導(dǎo)語】
Knowledge Distillation A Suvery的第二部分,上一篇介紹了知識蒸餾中知識的種類,這一篇介紹各個算法的蒸餾機制,根據(jù)教師網(wǎng)絡(luò)是否和學(xué)生網(wǎng)絡(luò)一起更新,可以分為離線蒸餾,在線蒸餾和自蒸餾。
感性上理解三種蒸餾方式:
離線蒸餾可以理解為知識淵博的老師給學(xué)生傳授知識。 在線蒸餾可以理解為教師和學(xué)生一起學(xué)習(xí)。 自蒸餾意味著學(xué)生自己學(xué)習(xí)知識。
1. 離線蒸餾 Offline Distillation

上圖中,紅色表示pre-trained, 黃色代表To be trained。
早期的KD方法都屬于離線蒸餾,將一個預(yù)訓(xùn)練好的教師模型的知識遷移到學(xué)生網(wǎng)絡(luò),所以通常包括兩個階段:
在蒸餾前,教師網(wǎng)絡(luò)在訓(xùn)練集上進行訓(xùn)練。 教師網(wǎng)絡(luò)通過logits層信息或者中間層信息提取知識,引導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練。
第一個階段通常不被認(rèn)為屬于知識蒸餾的一部分,因為默認(rèn)教師網(wǎng)絡(luò)本身就是已經(jīng)預(yù)訓(xùn)練好的。一般離線蒸餾算法關(guān)注與提升知識遷移的不同部分,包括:知識的形式,損失函數(shù)的設(shè)計,分布的匹配。
Offline Distillation優(yōu)點是實現(xiàn)起來比較簡單,形式上通常是單向的知識遷移(即從教師網(wǎng)絡(luò)到學(xué)生網(wǎng)絡(luò)),同時需要兩個階段的訓(xùn)練(訓(xùn)練教師網(wǎng)絡(luò)和知識蒸餾)。
Offline Distillation缺點是教師網(wǎng)絡(luò)通常容量大,模型復(fù)雜,需要大量訓(xùn)練時間,還需要注意教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)之間的容量差異,當(dāng)容量差異過大的時候,學(xué)生網(wǎng)絡(luò)可能很難學(xué)習(xí)好這些知識。
2. 在線蒸餾 Online Distillation

上圖中,教師模型和學(xué)生模型都是to be trained的狀態(tài),即教師模型并沒有預(yù)訓(xùn)練。
在大容量教師網(wǎng)絡(luò)沒有現(xiàn)成模型的時候,可以考慮使用online distillation。使用在線蒸餾的時候,教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)的參數(shù)會同時更新,整個知識蒸餾框架是端到端訓(xùn)練的。
Deep Mutual Learning(dml)提出讓多個網(wǎng)絡(luò)以合作的方式進行學(xué)習(xí),任何一個網(wǎng)絡(luò)可以作為學(xué)生網(wǎng)絡(luò),其他的網(wǎng)絡(luò)可以作為教師網(wǎng)絡(luò)。 Online Knowledge Distillation via Collaborative Learning提出使用soft logits繼承的方式來提升dml的泛化性能。 Oneline Knowledge distillation with diverse peers進一步引入了輔助peers和一個group leader來引導(dǎo)互學(xué)習(xí)過程。 為了降低計算代價,Knowledge Distillation by on-the-fly native ensemble通過提出一個多分支的架構(gòu),每個分支可以作為一個學(xué)生網(wǎng)絡(luò),不同的分支共享相同的的backbone。 Feature fusion for online mutual knowledge distillation提出了一種特征融合模塊來構(gòu)建教師分類器。 Training convolutional neural networks with cheap convolutions and online distillation提出使用cheap convolutioin來取代原先的conv層構(gòu)建學(xué)生網(wǎng)絡(luò)。 Large scale distributed neural network training throgh online distillation采用在線蒸餾訓(xùn)練大規(guī)模分布式網(wǎng)絡(luò)模型,提出了一種在線蒸餾的變體-co-distillation。co-distillation同時訓(xùn)練多個相同架構(gòu)的模型,每一個模型都是經(jīng)由其他模型訓(xùn)練得到的。 Feature-map-level online adversarial knowledge distillation提出了一種在線對抗知識蒸餾方法,利用類別概率和特征圖的知識,由判別器同時訓(xùn)練多個網(wǎng)絡(luò)
在線蒸餾法是一種具有高效并行計算的單階段端到端訓(xùn)練方案。然而,現(xiàn)有的在線方法(如相互學(xué)習(xí))通常不能解決在線設(shè)置中的大容量教師,因此,進一步探索在線設(shè)置中教師和學(xué)生模型之間的關(guān)系是一個有趣的話題。
3. 自蒸餾 Self-Distillation
在自蒸餾中,教師和學(xué)生模型使用相同的網(wǎng)絡(luò)。自蒸餾可以看作是在線蒸餾的一種特殊情況,因為教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)使用的是相同的模型。
Be your own teacher: Improve the performance of convolutional neural networks via self distillation 提出了一種新的自蒸餾方法,將網(wǎng)絡(luò)較深部分的知識蒸餾到網(wǎng)絡(luò)較淺部分。 Snapshot distillation:Teacher-student optimization in one generation 是自蒸餾的一種特殊變體,它將網(wǎng)絡(luò)早期階段(教師)的知識轉(zhuǎn)移到后期階段(學(xué)生),以支持同一網(wǎng)絡(luò)內(nèi)有監(jiān)督的培訓(xùn)過程。 為了進一步減少推斷的時間,Distillation based training for multi-exit architectures提出了基于蒸餾的訓(xùn)練方案,即淺層exit layer在訓(xùn)練過程中試圖模擬深層 exit layer的輸出。 最近,自蒸餾已經(jīng)在Self-distillation amplifies regularization in hilbert space進行了理論分析,并在Self-Distillation as Instance-Specific Label Smoothing中通過實驗證明了其改進的性能。 Revisit knowledge distillation: a teacher-free framework 提出了一種基于標(biāo)簽平滑化的無教師知識蒸餾方法。 Regularizing Class-wise Predictions via Self-knowledge Distillation提出了一種基于類間(class-wise)的自我知識蒸餾,以與相同的模型在同一源中,在同一源內(nèi)的訓(xùn)練模型的輸出分布相匹配。 Rethinking data augmentation: Self-supervision and self-distillation提出的自蒸餾是為數(shù)據(jù)增強所采用的,并對知識進行增強,以此提升模型本身的性能。
4. 教師學(xué)生架構(gòu)
在知識提煉中,師生架構(gòu)是形成知識傳遞的通用載體。換句話說,從教師到學(xué)生的知識獲取和提煉的質(zhì)量是由設(shè)計教師和學(xué)生網(wǎng)絡(luò)的方式 決定的。
就人類的學(xué)習(xí)習(xí)慣而言,我們希望學(xué)生能找到一個合適的老師。因此,要很好地完成知識提煉中的知識捕捉和提煉,如何選擇或設(shè)計合適的教師和學(xué)生的結(jié)構(gòu) 是非常重要而困難的問題。
最近,在蒸餾過程中,教師和學(xué)生的模型設(shè)置幾乎是預(yù)先固定的,其尺寸和結(jié)構(gòu)都不盡相同,這樣就容易造成模型容量差距。然而,如何對教師和學(xué)生的體系結(jié)構(gòu)進行特殊的設(shè)計,以及為什么他們的體系結(jié)構(gòu)是由這些模型設(shè)置決定的,這些問題幾乎沒有得到解答。
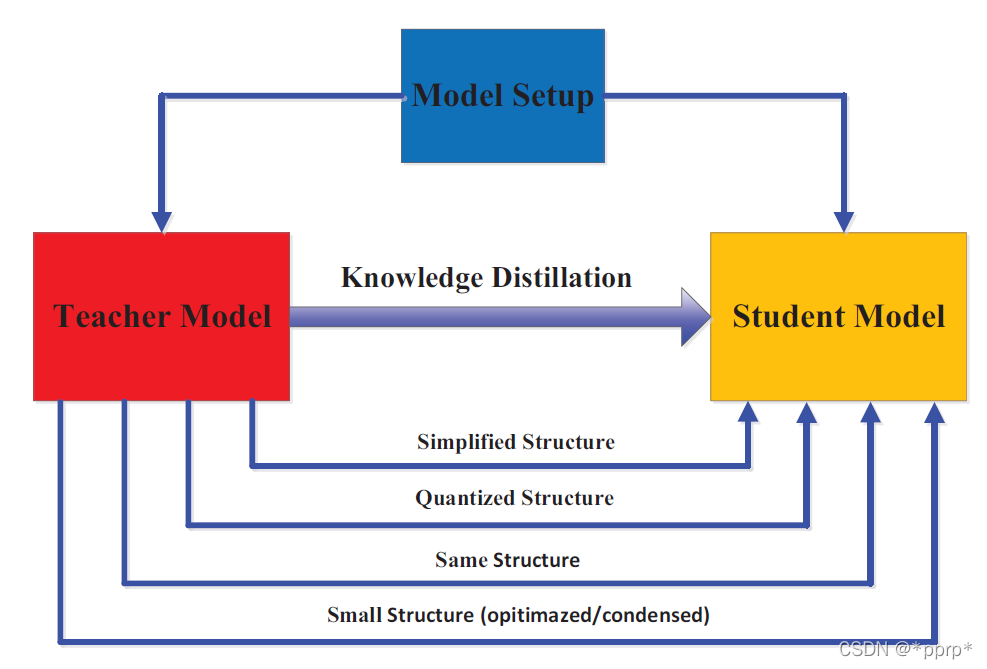
這部分將探討的教師模型和學(xué)生模型的結(jié)構(gòu)之間的關(guān)系,如上圖所示。
在Hinton提出的KD中,知識蒸餾先前被設(shè)計用來壓縮深度神經(jīng)網(wǎng)絡(luò),深度神經(jīng)網(wǎng)絡(luò)的復(fù)雜度主要來自于網(wǎng)絡(luò)的深度和寬度。通常需要將知識從更深更寬的神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)移到更淺更窄的神經(jīng)網(wǎng)絡(luò)。學(xué)生網(wǎng)絡(luò)被選擇為:
教師網(wǎng)絡(luò)的簡化版:通道數(shù)和層數(shù)減少。
教師網(wǎng)絡(luò)的量化版:網(wǎng)絡(luò)結(jié)構(gòu)被保留下來。
具有高效基本操作的小型網(wǎng)絡(luò)。
具有優(yōu)化全局網(wǎng)絡(luò)結(jié)構(gòu)的小型網(wǎng)絡(luò)。
與教師相同的網(wǎng)絡(luò)。
大型深度神經(jīng)網(wǎng)絡(luò)和小型學(xué)生網(wǎng)絡(luò)之間的模型容量差距會降低知識轉(zhuǎn)移的性能 。為了有效地將知識轉(zhuǎn)移到學(xué)生網(wǎng)絡(luò)中,已經(jīng)提出了多種方法來控制降低模型的復(fù)雜性。比如:
Improved knowledge distillation via ?teacher assistant引入教師助理,緩解教師模式和學(xué)生模式之間的訓(xùn)練gap。 Residual Error Based Knowledge Distillation提出使用殘差學(xué)習(xí)來降低訓(xùn)練gap,輔助的結(jié)構(gòu)主要用于學(xué)習(xí)殘差錯誤。
還有一些工作將關(guān)注點放在:最小化學(xué)生模型和教師模型結(jié)構(gòu)上差異 。
Model compression via distillation and quantization將網(wǎng)絡(luò)量化與知識蒸餾相結(jié)合,即學(xué)生模型是教師模型的量化版本。 Deep net triage: ?Analyzing the importance of network layers via structural compression.提出了一種結(jié)構(gòu)壓縮方法,將多個層學(xué)到的知識轉(zhuǎn)移到單個層。 Progressive blockwise knowledge distillation for ?neural network acceleration在保留感受野的同時,從教師網(wǎng)絡(luò)向?qū)W生網(wǎng)絡(luò)逐步進行block-wise的知識轉(zhuǎn)移。
以往的研究大多集中在設(shè)計教師與學(xué)生模型的結(jié)構(gòu) 或教師與學(xué)生之間的知識遷移機制 。為了使一個小的學(xué)生模型與一個大的教師模型相匹配,以提高知識提煉的績效,需要具有適應(yīng)性的師生學(xué)習(xí)架構(gòu)。近年來,知識提煉中的神經(jīng)結(jié)構(gòu)搜索,即在教師模型的指導(dǎo)下,對學(xué)生結(jié)構(gòu)和知識轉(zhuǎn)移進行聯(lián)合搜索,將是未來研究的一個有趣課題。
Search to distill: Pearls are everywhere but not the eyes Self-training with Noisy Student improves ImageNet classification Search for Better Students ?to Learn Distilled Knowledge
以上的幾個工作都是在給定教師網(wǎng)絡(luò)的情況下,搜索合適的學(xué)生網(wǎng)絡(luò)結(jié)構(gòu)。