
Redis內(nèi)存管理
Redis是一個(gè)基于內(nèi)存的鍵值數(shù)據(jù)庫(kù),內(nèi)存大小有限,隨著要緩存的數(shù)據(jù)量越來(lái)越大,有限的內(nèi)存空間不可避免地會(huì)被寫滿,此時(shí)應(yīng)該怎么辦呢?放心,Redis內(nèi)部幫助我們實(shí)現(xiàn)了內(nèi)存管理。
Redis回收內(nèi)存大致有兩個(gè)機(jī)制:過(guò)期策略和內(nèi)存淘汰策略。一個(gè)是刪除到達(dá)過(guò)期時(shí)間的鍵值對(duì)象,一個(gè)是當(dāng)Redis已使用內(nèi)存達(dá)到設(shè)置的maxmemory大小時(shí),將觸發(fā)內(nèi)存淘汰策略,強(qiáng)制刪除選擇出來(lái)的鍵值對(duì)象。
一、過(guò)期策略
1、定期刪除
Redis會(huì)將每個(gè)設(shè)置了過(guò)期時(shí)間的key放入到一個(gè)獨(dú)立的字典中,以后會(huì)定時(shí)遍歷這個(gè)字典來(lái)刪除到期的key。
優(yōu)點(diǎn):節(jié)約內(nèi)存,每隔一段時(shí)間就清除過(guò)期的key,快速釋放掉不必要的內(nèi)存占用。
缺點(diǎn):清除key這個(gè)操作需要用到CPU資源,相當(dāng)于每隔一段時(shí)間就要占用CPU,CPU壓力過(guò)大,會(huì)影響Redis服務(wù)器的響應(yīng)時(shí)間和指令吞吐量。
總結(jié):用處理器性能換取存儲(chǔ)空間(拿時(shí)間換空間)
2、惰性刪除
只有當(dāng)訪問(wèn)一個(gè)key時(shí),才會(huì)判斷該key是否已過(guò)期,過(guò)期則清除。
優(yōu)點(diǎn):節(jié)約CPU性能,只有訪問(wèn)key時(shí),才會(huì)使用CPU。
缺點(diǎn):內(nèi)存壓力過(guò)大,極端情況可能出現(xiàn)大量的過(guò)期key沒(méi)有再次被訪問(wèn),從而不會(huì)被清除,占用大量?jī)?nèi)存。
總結(jié):用存儲(chǔ)空間換取處理器性能(拿空間換時(shí)間)
二、內(nèi)存淘汰策略
1、既然Redis已經(jīng)存在過(guò)期策略,為什么還需要淘汰策略呢?
因?yàn)椴还苁嵌ㄆ趧h除還是惰性刪除都不是一種完全精準(zhǔn)的刪除,還是會(huì)存在key沒(méi)有被刪除掉的場(chǎng)景,所以就需要內(nèi)存淘汰策略進(jìn)行補(bǔ)充。
2、簡(jiǎn)單介紹
當(dāng)Redis已使用內(nèi)存達(dá)到設(shè)置的maxmemory大小時(shí),將觸發(fā)內(nèi)存淘汰策略,來(lái)清理內(nèi)存。
3、maxmemory參數(shù)
(1).maxmemory如何設(shè)置?
maxmemory參數(shù)可以在redis.conf中配置,可以在運(yùn)行時(shí)使用命令CONFIG SET動(dòng)態(tài)設(shè)置。
maxmemory?1GB
CONFIG?SET?maxmemory?1GB
(2).maxmemory的大小應(yīng)該設(shè)置成多大?
Redis 緩存使用內(nèi)存來(lái)保存數(shù)據(jù),避免業(yè)務(wù)應(yīng)用從后端數(shù)據(jù)庫(kù)中讀取數(shù)據(jù),可以提升應(yīng)用的響應(yīng)速度。那么是否可以將所有數(shù)據(jù)都放在Redis內(nèi)存中呢?
這樣做是不可行的。原因有二:
1、內(nèi)存的價(jià)格相對(duì)于磁盤要貴的多,這樣做雖然可以提高程序性能,但性價(jià)比太低。假設(shè)有1TB數(shù)據(jù),1TB 內(nèi)存的價(jià)格大約是 3.5 萬(wàn)元,而 1TB 磁盤的價(jià)格大約是 1000 元,所以最好是將全部數(shù)據(jù)存儲(chǔ)到MySQL中做數(shù)據(jù)的留底,一部分經(jīng)常訪問(wèn)的數(shù)據(jù)放到Redis中。
2、數(shù)據(jù)訪問(wèn)都是有局部性的,也就是我們通常所說(shuō)的“八二原理”,80% 的請(qǐng)求實(shí)際只訪問(wèn)了 20% 的數(shù)據(jù)。所以將所有數(shù)據(jù)都存儲(chǔ)到內(nèi)存中,并沒(méi)有必要。
“八二原理”只能說(shuō)是一個(gè)經(jīng)驗(yàn),不一定在所有場(chǎng)景都生效,因?yàn)?20% 的數(shù)據(jù)不一定能貢獻(xiàn) 80% 的訪問(wèn)量,我們不能簡(jiǎn)單地按照“總數(shù)據(jù)量的 20%”來(lái)設(shè)置緩存最大空間容量。在實(shí)踐過(guò)程中,我看到過(guò)的緩存容量占總數(shù)據(jù)量的比例,從 5% 到 40% 的都有。這個(gè)容量規(guī)劃不能一概而論,是需要結(jié)合應(yīng)用數(shù)據(jù)實(shí)際訪問(wèn)特征和成本開銷來(lái)綜合考慮的。
總結(jié):大容量緩存是能帶來(lái)性能加速的收益,但是成本也會(huì)更高,而小容量緩存不一定就起不到加速訪問(wèn)的效果。一般來(lái)說(shuō),我會(huì)建議把緩存容量設(shè)置為總數(shù)據(jù)量的 15% 到 30%,兼顧訪問(wèn)性能和內(nèi)存空間開銷。
4、內(nèi)存淘汰過(guò)程
1、客戶端執(zhí)行一個(gè)新指令添加數(shù)據(jù)。
2、Redis檢查內(nèi)存使用量,如果大于maxmemory限制,就通過(guò)內(nèi)存淘汰策略清理內(nèi)存。
3、執(zhí)行新命令,重復(fù)上述過(guò)程。
5、八種內(nèi)存淘汰策略
Redis 4.0之前一共實(shí)現(xiàn)了6種內(nèi)存淘汰策略,在4.0之后,又增加了2種策略。我把這 8 種策略的分類,畫到了一張圖里:
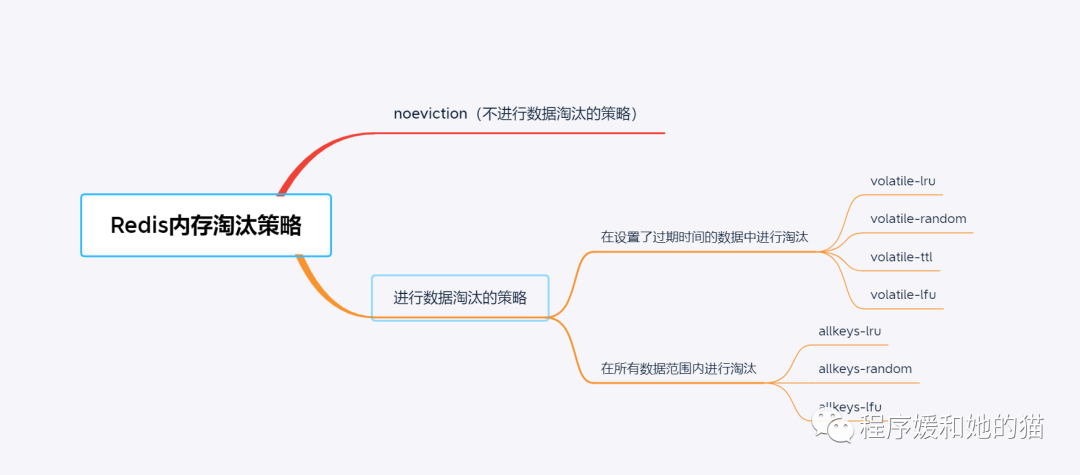 Redis內(nèi)存淘汰策略分類
Redis內(nèi)存淘汰策略分類1.noeviction:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,就返回error。這是默認(rèn)的淘汰策略。
2.volatile-lru:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,掃描那些設(shè)置了過(guò)期時(shí)間的key,淘汰一些最近未使用的key。
3.volatile-random:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,掃描那些設(shè)置了過(guò)期時(shí)間的key,隨機(jī)淘汰一些key。
4.volatile-ttl:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,掃描那些設(shè)置了過(guò)期時(shí)間的key,淘汰一些即將過(guò)期的key。
5.volatile-lfu:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,掃描那些設(shè)置了過(guò)期時(shí)間的key,淘汰一些使用頻率最低的key。
6.allkeys-lru:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,就會(huì)掃描所有的key,淘汰一些最近最少使用的key。
7.allkeys-random:添加數(shù)據(jù)時(shí),如果Redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,就會(huì)掃描所有的key,隨機(jī)淘汰一些key。
8.allkeys-lfu:添加數(shù)據(jù)時(shí),如果redis判斷該操作會(huì)導(dǎo)致占用內(nèi)存大小超過(guò)內(nèi)存限制,掃描那些設(shè)置了過(guò)期時(shí)間的key,淘汰一些最近最少使用的key。
6、內(nèi)存淘汰策略的選擇
(1).優(yōu)先使用 allkeys-lru 策略,這樣,可以充分利用 LRU 這一經(jīng)典緩存算法的優(yōu)勢(shì),把最近最常訪問(wèn)的數(shù)據(jù)留在緩存中,提高Redis的命中率,提升應(yīng)用的訪問(wèn)性能。
(2).當(dāng)Redis中的數(shù)據(jù)有一部分是我們經(jīng)常訪問(wèn)的,有一部分是幾乎訪問(wèn)不到的,即業(yè)務(wù)數(shù)據(jù)有明顯的冷熱數(shù)據(jù)區(qū)分,建議使用 allkeys-lru 策略,將最近最少使用的數(shù)據(jù)刪除(冷數(shù)據(jù)),保留經(jīng)常使用的數(shù)據(jù)(熱數(shù)據(jù))。
(3).當(dāng)Redis中的數(shù)據(jù)基本都會(huì)被訪問(wèn)到,沒(méi)有明顯的冷熱數(shù)據(jù)區(qū)分,建議使用 allkeys-random 策略,隨機(jī)選擇淘汰的數(shù)據(jù)就行。
(4).當(dāng)我們想精準(zhǔn)淘汰一些超時(shí)數(shù)據(jù)(時(shí)間>=key設(shè)置的超時(shí)時(shí)間)時(shí),建議使用volatile-ttl。
(5).如果你的業(yè)務(wù)有置頂?shù)男枨螅热缰庙斝侣劇⒅庙斠曨l,這些置頂?shù)臄?shù)據(jù)是永久保留的。此時(shí)的做法是,不給這些置頂數(shù)據(jù)設(shè)置過(guò)期時(shí)間,同時(shí)使用 volatile-lru 策略,這樣一來(lái),這些需要置頂?shù)臄?shù)據(jù)一直不會(huì)被刪除,而其他數(shù)據(jù)會(huì)在過(guò)期時(shí)根據(jù) LRU 規(guī)則進(jìn)行篩選。
三、淺談LRU算法
1、LRU算法簡(jiǎn)單介紹
LRU 算法的全稱是 Least Recently Used,從名字上就可以看出,LRU算法是按照最近最少使用的原則來(lái)篩選數(shù)據(jù),最不常用的數(shù)據(jù)會(huì)被篩選出來(lái),而最近頻繁使用的數(shù)據(jù)會(huì)留在緩存中。
那么Redis是怎么進(jìn)行數(shù)據(jù)篩選的呢?LRU 會(huì)把所有的數(shù)據(jù)組織成一個(gè)鏈表,鏈表的頭和尾分別表示 MRU 端和 LRU 端,分別代表最近最常使用的數(shù)據(jù)和最近最不常用的數(shù)據(jù)。
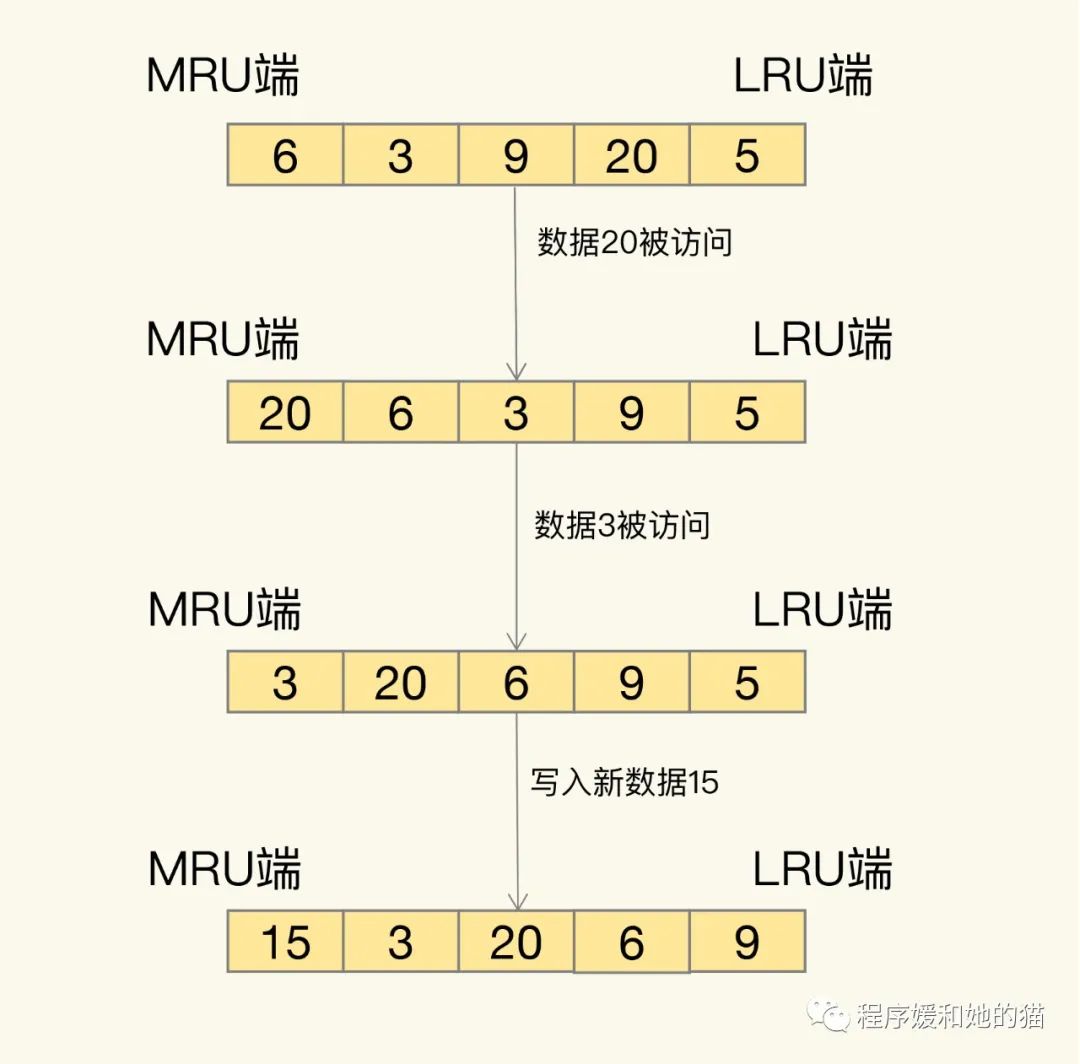 LRU算法演示圖
LRU算法演示圖
鏈表初始數(shù)據(jù)有6、3、9、20、5。如果數(shù)據(jù) 20 和 3 被先后訪問(wèn),它們都會(huì)從現(xiàn)有的鏈表位置移到 MRU 端,而鏈表中在它們之前的數(shù)據(jù)則相應(yīng)地往后移一位。因?yàn)椋琇RU 算法選擇刪除數(shù)據(jù)時(shí),都是從 LRU 端開始,所以把剛剛被訪問(wèn)的數(shù)據(jù)移到 MRU 端,就可以讓它們盡可能地留在緩存中。
現(xiàn)在有一個(gè)新數(shù)據(jù) 15 要被寫入緩存,但此時(shí)Redis中已經(jīng)沒(méi)有緩存空間了,也就是鏈表沒(méi)有空余位置了,那么,LRU 算法做兩件事:一是,數(shù)據(jù) 15 是剛被訪問(wèn)的,所以它會(huì)被放到 MRU 端。二是,算法把 LRU 端的數(shù)據(jù) 5 從緩存中刪除,相應(yīng)的鏈表中就沒(méi)有數(shù)據(jù) 5 的記錄了。
所以,LRU 算法的思想就是:它認(rèn)為剛剛被訪問(wèn)的數(shù)據(jù),肯定還會(huì)被再次訪問(wèn),所以就把它放在 MRU 端;長(zhǎng)久不訪問(wèn)的數(shù)據(jù),肯定就不會(huì)再被訪問(wèn)了,所以就讓它逐漸后移到 LRU 端,在緩存滿時(shí),就優(yōu)先刪除它。
2、LRU算法的缺陷
LRU 算法在實(shí)際實(shí)現(xiàn)時(shí),需要用鏈表管理所有的緩存數(shù)據(jù),這會(huì)帶來(lái)額外的空間開銷。
當(dāng)有數(shù)據(jù)被訪問(wèn)時(shí),需要在鏈表上把該數(shù)據(jù)移動(dòng)到 MRU 端,如果有大量數(shù)據(jù)被訪問(wèn),就會(huì)帶來(lái)很多鏈表移動(dòng)操作,會(huì)很耗時(shí),進(jìn)而會(huì)降低 Redis 緩存性能。
剛剛使用的數(shù)據(jù)移動(dòng)到表頭,后面的數(shù)據(jù)都要向后移動(dòng),如果鏈表很長(zhǎng)很長(zhǎng),那么就要移動(dòng)好久好久,是個(gè)很耗時(shí)的操作。
3、Redis對(duì)LRU算法的改進(jìn)
所以,在 Redis 中,LRU 算法被做了簡(jiǎn)化,以減輕數(shù)據(jù)淘汰對(duì)緩存性能的影響。具體來(lái)說(shuō),Redis 默認(rèn)會(huì)記錄每個(gè)數(shù)據(jù)的最近一次訪問(wèn)的時(shí)間戳(鍵值對(duì)數(shù)據(jù)結(jié)構(gòu) RedisObject 中的 lru 字段)。然后,Redis 在決定淘汰的數(shù)據(jù)時(shí),第一次會(huì)隨機(jī)選出 N 個(gè)數(shù)據(jù),把它們作為一個(gè)候選集合。接下來(lái),Redis 會(huì)比較這 N 個(gè)數(shù)據(jù)的 lru 字段,把 lru 字段值最小的數(shù)據(jù)從緩存中淘汰出去。這樣,就將一個(gè)超級(jí)大的鏈表分割成了無(wú)數(shù)個(gè)小鏈表,分治的思想,提高了淘汰的效率。
Redis 提供了一個(gè)配置參數(shù) maxmemory-samples,這個(gè)參數(shù)就是 Redis 選出的數(shù)據(jù)個(gè)數(shù) N。例如,我們執(zhí)行如下命令,可以讓 Redis 選出 100 個(gè)數(shù)據(jù)作為候選數(shù)據(jù)集:
CONFIG?SET?maxmemory-samples?100
當(dāng)需要再次淘汰數(shù)據(jù)時(shí),Redis 需要挑選數(shù)據(jù)進(jìn)入第一次淘汰時(shí)創(chuàng)建的候選集合。這兒的挑選標(biāo)準(zhǔn)是:能進(jìn)入候選集合的數(shù)據(jù)的 lru 字段值必須小于候選集合中最小的 lru 值。當(dāng)有新數(shù)據(jù)進(jìn)入候選數(shù)據(jù)集后,如果候選數(shù)據(jù)集中的數(shù)據(jù)個(gè)數(shù)達(dá)到了 maxmemory-samples,Redis 就把候選數(shù)據(jù)集中 lru 字段值最小的數(shù)據(jù)淘汰出去。
這樣一來(lái),Redis 緩存不用為所有的數(shù)據(jù)維護(hù)一個(gè)大鏈表,也不用在每次數(shù)據(jù)訪問(wèn)時(shí)要移動(dòng)好長(zhǎng)的鏈表項(xiàng),提升了緩存的性能。
四、淺談LFU算法
前面提到的LRU算法看似已經(jīng)是比較好的算法了,但實(shí)際上存在一些缺陷,因?yàn)?strong>存在某些key,在最近被訪問(wèn)過(guò)后就不再訪問(wèn)了,而有些key是很久以前訪問(wèn)過(guò),但是以后很可能也要訪問(wèn)的,如果根據(jù)LRU算法,就會(huì)導(dǎo)致前一類key保留下來(lái),反而后一類真正需要的key就被淘汰了,因此LFU算法就是該問(wèn)題的解決方式。
LFU算法在Redis中是通過(guò)一個(gè)計(jì)數(shù)器來(lái)實(shí)現(xiàn)的,每個(gè)key都有一個(gè)計(jì)數(shù)器,訪問(wèn)頻度越高,計(jì)數(shù)器的值就越大,Redis就根據(jù)計(jì)數(shù)器的值來(lái)淘汰key,當(dāng)然計(jì)數(shù)器的值也是會(huì)隨著時(shí)間減少的。
使用LFU算法時(shí),有兩個(gè)可配置參數(shù):lfu-log-factor和lfu-decay-time。
lfu-log-factor:默認(rèn)值是10。使用它可以調(diào)整計(jì)數(shù)器計(jì)數(shù)值的增長(zhǎng)速度,lfu-log-factor越大,計(jì)數(shù)值增長(zhǎng)的越慢,因此就要求key的訪問(wèn)頻度較高才能避免被淘汰。
lfu-decay-time:衰減時(shí)間默認(rèn)是1,它表示隔多久將計(jì)數(shù)值減1,使用它可以調(diào)整計(jì)數(shù)值的衰減速度。長(zhǎng)時(shí)間不讀取key的話,其計(jì)數(shù)值是需要進(jìn)行衰減的。
下面是不同的lfu-log-factor情況下的計(jì)數(shù)值的增長(zhǎng)情況,key的計(jì)數(shù)值不是每訪問(wèn)一次key都會(huì)增加1,它是和lfu-log-factor有關(guān)系的,計(jì)數(shù)值的最大值是255,lfu-log-factor越大,計(jì)數(shù)器的值增長(zhǎng)就越難,如下圖。
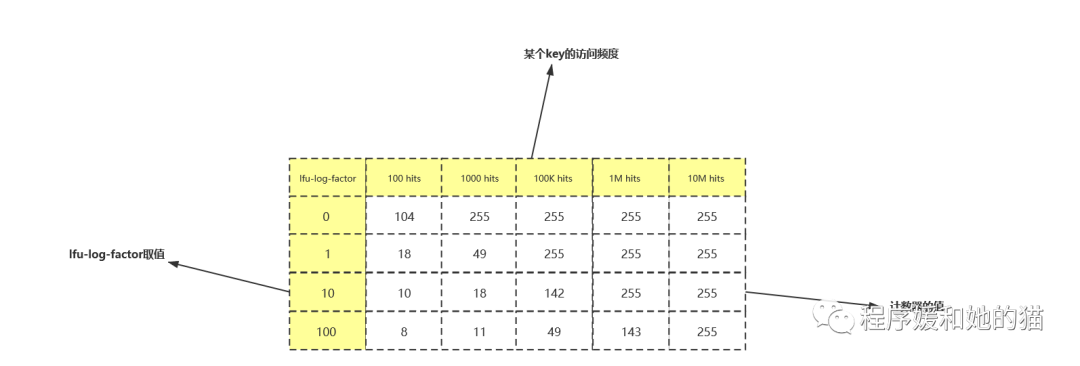 lfu-log-factor示意圖
lfu-log-factor示意圖文章借鑒內(nèi)容:極客時(shí)間《Redis核心技術(shù)與實(shí)戰(zhàn)》