
詳聊LLaMa技術(shù)細節(jié):LLaMA大模型是如何煉成的?
導(dǎo)讀
本文介紹來自 Meta AI 的 LLaMa 模型,類似于 OPT,也是一種完全開源的大語言模型。LLaMa 的參數(shù)量級從 7B 到 65B 大小不等,是在數(shù)萬億個 token 上面訓(xùn)練得到。值得一提的是,LLaMa 雖然只使用公共的數(shù)據(jù)集,依然取得了強悍的性能。
本文目錄
1 LLaMa:開源高效的大語言模型
(來自 Meta AI)
1.1 背景:模型參數(shù)量級的積累,或者訓(xùn)練數(shù)據(jù)的增加,哪個對性能提升幫助更大?
1.2 LLaMa 做到了什么
1.3 LLaMa 預(yù)訓(xùn)練數(shù)據(jù)
1.4 LLaMa 模型架構(gòu)
1.5 LLaMa 的優(yōu)化
1.6 LLaMa 的高效實現(xiàn)
1.7 LLaMa 實驗結(jié)果
1.8 訓(xùn)練期間的性能變化
太長不看版
本文介紹來自 Meta AI 的 LLaMa 模型,類似于 OPT,也是一種完全開源的大語言模型。LLaMa 的參數(shù)量級從 7B 到 65B 大小不等,是在數(shù)萬億個 token 上面訓(xùn)練得到。值得一提的是,LLaMa 雖然只使用公共的數(shù)據(jù)集,依然取得了強悍的性能。LLaMA-13B 在大多數(shù)基準測試中都優(yōu)于 GPT-3 (175B),LLaMA65B 與最佳模型 Chinchilla-70B 和 PaLM-540B 相比具有競爭力。
1 LLaMa:開源高效的大語言模型
論文名稱:LLaMA: Open and Efficient Foundation Language Models
論文地址:
https://arxiv.org/pdf/2302.13971.pdf
代碼鏈接:
https://github.com/facebookresearch/llama
1.1 背景:模型參數(shù)量級的積累,或者訓(xùn)練數(shù)據(jù)的增加,哪個對性能提升幫助更大?
以 GPT-3 為代表的大語言模型 (Large language models, LLMs) 在海量文本集合上訓(xùn)練,展示出了驚人的涌現(xiàn)能力以及零樣本遷移和少樣本學(xué)習(xí)能力。GPT-3 把模型的量級縮放到了 175B,也使得后面的研究工作繼續(xù)去放大語言模型的量級。大家好像有一個共識,就是:模型參數(shù)量級的增加就會帶來同樣的性能提升。
但是事實確實如此嗎?
最近的 "Training Compute-Optimal Large Language Models[1]" 這篇論文提出一種縮放定律 (Scaling Law):
訓(xùn)練大語言模型時,在計算成本達到最優(yōu)情況下,模型大小和訓(xùn)練數(shù)據(jù) (token) 的數(shù)量應(yīng)該比例相等地縮放,即:如果模型的大小加倍,那么訓(xùn)練數(shù)據(jù)的數(shù)量也應(yīng)該加倍。
翻譯過來就是:當我們給定特定的計算成本預(yù)算的前提下,語言模型的最佳性能不僅僅可以通過設(shè)計較大的模型搭配小一點的數(shù)據(jù)集得到,也可以通過設(shè)計較小的模型配合大量的數(shù)據(jù)集得到。
那么,相似成本訓(xùn)練 LLM,是大 LLM 配小數(shù)據(jù)訓(xùn)練,還是小 LLM 配大數(shù)據(jù)訓(xùn)練更好?
縮放定律 (Scaling Law) 告訴我們對于給定的特定的計算成本預(yù)算,如何去匹配最優(yōu)的模型和數(shù)據(jù)的大小。但是本文作者團隊認為,這個功能只考慮了總體的計算成本,忽略了推理時候的成本。因為大部分社區(qū)用戶其實沒有訓(xùn)練 LLM 的資源,他們更多的是拿著訓(xùn)好的 LLM 來推理。在這種情況下,我們首選的模型應(yīng)該不是訓(xùn)練最快的,而應(yīng)該是推理最快的 LLM。呼應(yīng)上題,本文認為答案就是:小 LLM 配大數(shù)據(jù)訓(xùn)練更好,因為小 LLM 推理更友好。
1.2 LLaMa 做到了什么
LLaMa 沿著小 LLM 配大數(shù)據(jù)訓(xùn)練的指導(dǎo)思想,訓(xùn)練了一系列性能強悍的語言模型,參數(shù)量從 7B 到 65B。例如,LLaMA-13B 比 GPT-3 小10倍,但是在大多數(shù)基準測試中都優(yōu)于 GPT-3。大一點的 65B 的 LLaMa 模型也和 Chinchilla 或者 PaLM-540B 的性能相當。
同時,LLaMa 模型只使用了公開數(shù)據(jù)集,開源之后可以復(fù)現(xiàn)。但是大多數(shù)現(xiàn)有的模型都依賴于不公開或未記錄的數(shù)據(jù)完成訓(xùn)練。
1.3 LLaMa 預(yù)訓(xùn)練數(shù)據(jù)
LLaMa 預(yù)訓(xùn)練數(shù)據(jù)大約包含 1.4T tokens,對于絕大部分的訓(xùn)練數(shù)據(jù),在訓(xùn)練期間模型只見到過1次,Wikipedia 和 Books 這兩個數(shù)據(jù)集見過2次。
如下圖1所示是 LLaMa 預(yù)訓(xùn)練數(shù)據(jù)的含量和分布,其中包含了 CommonCrawl 和 Books 等不同域的數(shù)據(jù)。
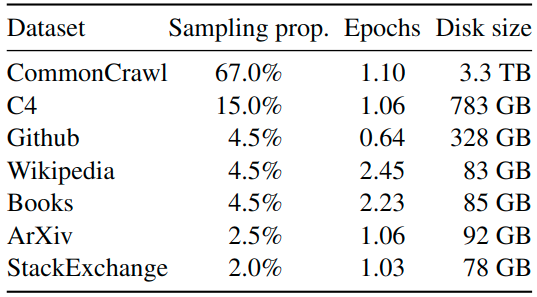
圖1:LLaMa 預(yù)訓(xùn)練數(shù)據(jù)的含量和分布
CommonCrawl (占 67%): 包含 2017 到 2020 的5個版本,預(yù)處理部分包含:刪除重復(fù)數(shù)據(jù),去除掉非英文的數(shù)據(jù),并通過一個 n-gram 語言模型過濾掉低質(zhì)量內(nèi)容。
C4 (占 15%): 在探索性實驗中,作者觀察到使用不同的預(yù)處理 CommonCrawl 數(shù)據(jù)集可以提高性能,因此在預(yù)訓(xùn)練數(shù)據(jù)集中加了 C4。預(yù)處理部分包含:刪除重復(fù)數(shù)據(jù),過濾的方法有一些不同,主要依賴于啟發(fā)式方法,例如標點符號的存在或網(wǎng)頁中的單詞和句子的數(shù)量。
Github (占 4.5%): 在 Github 中,作者只保留在 Apache、BSD 和 MIT 許可下的項目。此外,作者使用基于行長或字母數(shù)字字符比例的啟發(fā)式方法過濾低質(zhì)量文件,并使用正則表達式刪除標題。最后使用重復(fù)數(shù)據(jù)刪除。
Wikipedia (占 4.5%): 作者添加了 2022 年 6-8 月的 Wikipedia 數(shù)據(jù)集,包括 20 種語言,作者處理數(shù)據(jù)以刪除超鏈接、評論和其他格式樣板。
Gutenberg and Books3 (占 4.5%): 作者添加了兩個書的數(shù)據(jù)集,分別是 Gutenberg 以及 ThePile (訓(xùn)練 LLM 的常用公開數(shù)據(jù)集) 中的 Book3 部分。處理數(shù)據(jù)時作者執(zhí)行重復(fù)數(shù)據(jù)刪除,刪除內(nèi)容重疊超過 90% 的書籍。
ArXiv (占 2.5%): 為了添加一些科學(xué)數(shù)據(jù)集,作者處理了 arXiv Latex 文件。作者刪除了第一部分之前的所有內(nèi)容,以及參考文獻。還刪除了 .tex 文件的評論,以及用戶編寫的內(nèi)聯(lián)擴展定義和宏,以增加論文之間的一致性。
Stack Exchange (占 2%): 作者添加了 Stack Exchange,這是一個涵蓋各種領(lǐng)域的高質(zhì)量問題和答案網(wǎng)站,范圍從計算機科學(xué)到化學(xué)。作者從 28 個最大的網(wǎng)站保留數(shù)據(jù),從文本中刪除 HTML 標簽并按分數(shù)對答案進行排序。
Tokenizer 的做法基于 SentencePieceProcessor[2],使用 bytepair encoding (BPE) 算法。
LLaMa 的 PyTorch 代碼如下,用到了 sentencepiece 這個庫。
class Tokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
logger.info(f"Reloaded SentencePiece model from {model_path}")
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
logger.info(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}"
)
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
1.4 LLaMa 模型架構(gòu)
Pre-normalization [受 GPT3 的啟發(fā)]:
為了提高訓(xùn)練穩(wěn)定性,LLaMa 對每個 Transformer 的子層的輸入進行歸一化,而不是對輸出進行歸一化。使用 RMSNorm[3] 歸一化函數(shù)。
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
常規(guī)的 Layer Normalization:
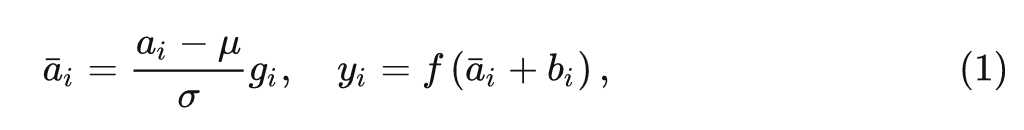
式中, 和 是 LN 的 scale 和 shift 參數(shù), 和 的計算如下式所示:
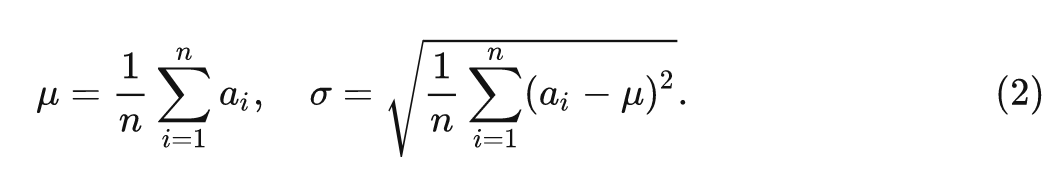
RMSNorm:
相當于是去掉了 這一項。
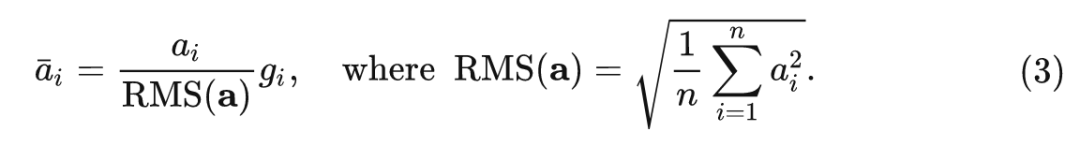
看上去就這一點小小的改動,有什么作用呢?RMSNorm 的原始論文進行了一些不變性的分析和梯度上的分析。
SwiGLU 激活函數(shù) [受 PaLM 的啟發(fā)]:
LLaMa 使用 SwiGLU 激活函數(shù)[4]替換 ReLU 非線性以提高性能,維度從 變?yōu)? 。
Rotary Embeddings [受 GPTNeo 的啟發(fā)]:
LLaMa 去掉了絕對位置編碼,使用旋轉(zhuǎn)位置編碼 (Rotary Positional Embeddings, RoPE)[5],這里的 RoPE 來自蘇劍林老師,其原理略微復(fù)雜,感興趣的讀者可以參考蘇神的原始論文和官方博客介紹:
https://spaces.ac.cn/archives/8265
Self-Attention 的 PyTorch 代碼:
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
這里有幾個地方值得注意一下:
首先是 model.py 文件里面從 fairscale 中 import 了3個類,分別是:ParallelEmbedding,RowParallelLinear,和 ColumnParallelLinear。
Fairscale 鏈接如下,是一個用于高性能大規(guī)模預(yù)訓(xùn)練的庫,LLaMa 使用了其 ParallelEmbedding 去替換 Embedding, 使用了其 RowParallelLinear 和 ColumnParallelLinear 去替換 nn.Linear,猜測可能是為了加速吧。
https://github.com/facebookresearch/fairscale
另一個需要注意的點是:cache 的緩存機制,可以看到在構(gòu)造函數(shù)里面定義了下面兩個東西:
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()關(guān)鍵其實就是這幾行代碼:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]在訓(xùn)練的時候,因為每次都是輸入完整的一句話,所以 cache 機制其實是不發(fā)揮作用的。
在推理的時候,比如要生成 "I have a cat",過程是:
1 輸入 <s>,生成 <s> I。
2 輸入 <s> I,生成 <s> I have。
3 輸入 <s> I have,生成 <s> I have a。
4 輸入 <s> I have a,生成 <s> I have a cat。在執(zhí)行3這一步時,計算 "a" 的信息時,還要計算 <s> I have 的 Attention 信息,比較復(fù)雜。因此,cache 的作用就是在執(zhí)行2這一步時,提前把 <s> I have 的 keys 和 values 算好,并保存在 self.cache_k 和 self.cache_v 中。在執(zhí)行3這一步時,計算 Attention 所需的 keys 和 values 是直接從這里面取出來的:
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
只需要額外地計算 "a" 的 keys 和 values 即可,這對模型的快速推理是至關(guān)重要的。還有一個值得注意的點:self.cache_k = self.cache_k.to(xq)
這里使用的是 to() 函數(shù)的一種不太常見的用法:torch.to(other, non_blocking=False, copy=False)→Tensor
Returns a Tensor with same torch.dtype and torch.device as the Tensor other.
FFN 的 PyTorch 代碼:
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
這里需要注意的點是:
激活函數(shù)用的是 F.silu(),也就是 Swish 激活函數(shù)。
self.w2(F.silu(self.w1(x)) * self.w3(x)) 的實現(xiàn)也就是 SwiGLU 激活函數(shù)。

Transformer Block 的 PyTorch 代碼:
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
Transformer 的 PyTorch 代碼:
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
self.tok_embeddings 用的是 ParallelEmbedding 這個函數(shù),把 ids 變?yōu)樵~向量。
mask 部分通過 torch.full() 函數(shù)和 torch.triu() 函數(shù)得到一個上三角矩陣,用于注意力的計算。
通過 torch.nn.ModuleList() 函數(shù)定義所有的 Transformer Block。
所有的 norm 函數(shù)都使用 RMSNorm 去定義。
生成過程的 PyTorch 代碼:
class LLaMA:
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate(
self,
prompts: List[str],
max_gen_len: int,
temperature: float = 0.8,
top_p: float = 0.95,
) -> List[str]:
bsz = len(prompts)
params = self.model.params
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
min_prompt_size = min([len(t) for t in prompt_tokens])
max_prompt_size = max([len(t) for t in prompt_tokens])
total_len = min(params.max_seq_len, max_gen_len + max_prompt_size)
tokens = torch.full((bsz, total_len), self.tokenizer.pad_id).cuda().long()
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t).long()
input_text_mask = tokens != self.tokenizer.pad_id
start_pos = min_prompt_size
prev_pos = 0
for cur_pos in range(start_pos, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits, dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
decoded = []
for i, t in enumerate(tokens.tolist()):
# cut to max gen len
t = t[: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
try:
t = t[: t.index(self.tokenizer.eos_id)]
except ValueError:
pass
decoded.append(self.tokenizer.decode(t))
return decoded
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token
這里需要注意的是:
torch.multinomial() 函數(shù)用于按照一定的概率 (probs_sort) 采樣一定數(shù)量 (num_samples) 的 Tensor。
torch.gather() 函數(shù)是一個抽數(shù)據(jù)的函數(shù),按照 probs_idx 的索引和 dim=-1 的維度。
1.5 LLaMa 的優(yōu)化
AdamW, , 使用 cosine 學(xué)習(xí)率衰減策略, 2000 步的 warm-up, 最終學(xué)習(xí)率等于最大學(xué)習(xí)率的 , 使用 0.1 的權(quán)重衰減和 1.0 的梯度裁剪。
1.6 LLaMa 的高效實現(xiàn)
快速的注意力機制: LLaMa 采用了高效的 causal multi-head attention (基于 xformers[6]),不存儲注意力權(quán)重,且不計算 mask 掉的 query 和 key 的值。
手動實現(xiàn)反向傳播過程,不使用 PyTorch autograd: 使用 checkpointing 技術(shù)減少反向傳播中的激活值的計算,更準確地說,LLaMa 保存計算代價較高的激活值,例如線性層的輸出。
通過使用模型和序列并行減少模型的內(nèi)存使用。此外,LLaMa 還盡可能多地重疊激活的計算和網(wǎng)絡(luò)上的 GPU 之間的通信。
LLaMa-65B 的模型使用 2048 塊 80G 的 A100 GPU,在 1.4T token 的數(shù)據(jù)集上訓(xùn)練 21 天。
1.7 LLaMa 實驗結(jié)果
LLaMa 在 20 個標準的 Zero-Shot 和 Few-Shot 任務(wù)上面做了評測。在評測時的任務(wù)包括自由形式的生成任務(wù)和多項選擇任務(wù)。多項選擇任務(wù)的目標是根據(jù)提供的上下文在一組給定選項中選擇最合適的答案。
Zero-Shot 在評測時,作者提供了任務(wù)和測試示例的文本描述。LLaMa 要么使用開放式生成提供答案,要么對給定的答案進行排名。Few-Shot 在評測時,作者提供了任務(wù)的幾個示例 (在 1 到 64 之間) 和一個測試示例。LLaMa 將此文本作為輸入并生成答案或者排名不同的選項。
1.7.1 常識推理實驗結(jié)果
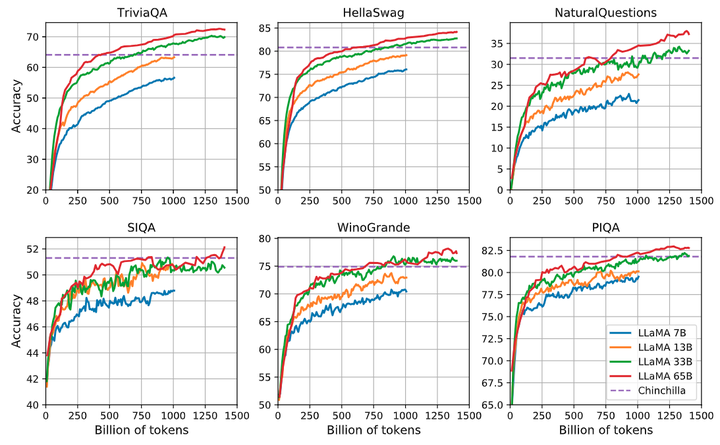
作者考慮了8個標準的常識推理基準:BoolQ, PIQA, SIQA, WinoGrande 等,采用標準的 Zero-Shot 的設(shè)定進行評估。結(jié)果如圖3所示,LLaMA-65B 在除了 BoolQ 的所有基準測試中都優(yōu)于 Chinchilla-70B,在除了 BoolQ 和 WinoGrande 的任何地方都超過了 PaLM540B。LLAMA-13B 模型在大多數(shù)基準測試中也優(yōu)于 GPT-3。
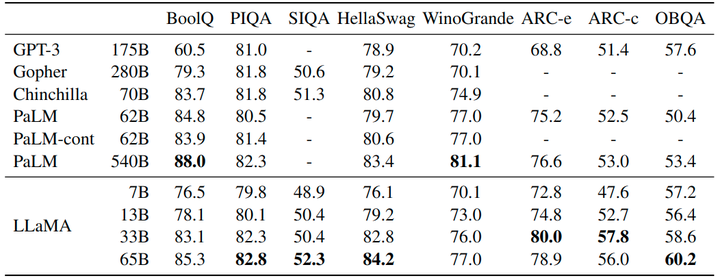
1.7.2 封閉式問答實驗結(jié)果
如下圖3和4所示是封閉式問答實驗結(jié)果,圖4是 Natural Questions 數(shù)據(jù)集,圖5是 TriviaQA 數(shù)據(jù)集,報告的是報告精確匹配性能,即:模型無法訪問包含回答問題證據(jù)的文檔。在這兩個基準測試中,LLaMA-65B 在零樣本和少樣本設(shè)置中實現(xiàn)了最先進的性能,而且 LLaMa-13B 的性能也同樣具備競爭力。
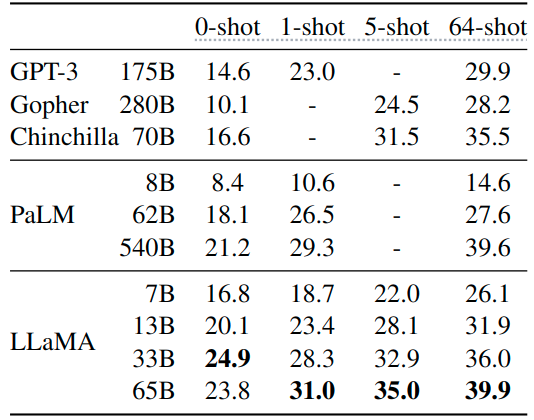
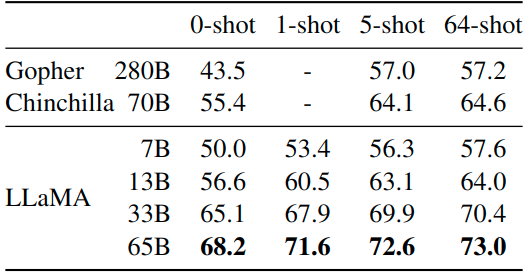
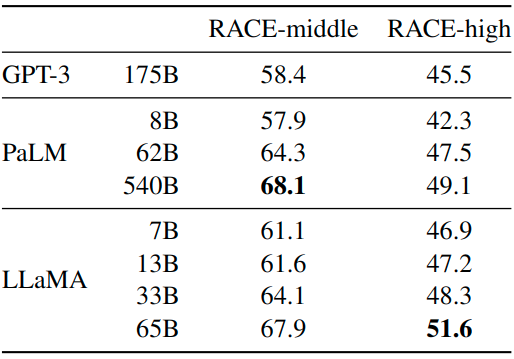
1.7.3 閱讀理解實驗結(jié)果
閱讀理解任務(wù)在 RACE 數(shù)據(jù)集上做評測,結(jié)果如圖6所示。LLaMA-65B 與 PaLM-540B 具有競爭力,LLaMA-13B 的性能比 GPT-3 好幾個百分點。
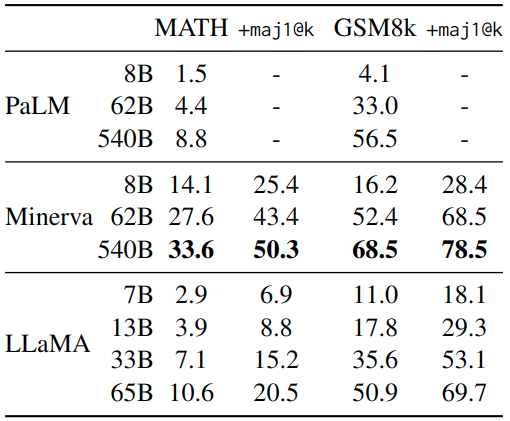
1.7.4 數(shù)學(xué)推理實驗結(jié)果
作者在 MATH 和 GSM8k 兩個任務(wù)上面做數(shù)學(xué)推理任務(wù),MATH 是一個 12K 中學(xué)和高中數(shù)學(xué)問題的數(shù)據(jù)集,用 LaTeX 編寫。GSM8k 是一組中學(xué)數(shù)學(xué)問題。在 GSM8k 上,盡管 LLaMA-65B 從沒在數(shù)學(xué)數(shù)據(jù)上進行微調(diào),但可以觀察到 LLaMA-65B 優(yōu)于 Minerva-62B。
1.7.5 代碼生成實驗結(jié)果
作者在 HumanEval 和 MBPP 兩個任務(wù)上面做代碼生成任務(wù),對于這兩個任務(wù),模型接收幾個句子中的程序描述,以及一些輸入輸出示例。模型需要生成一個符合描述并滿足測試用例的 Python 程序。圖7將 LLaMa 與尚未在代碼上微調(diào)的現(xiàn)有語言模型 (PaLM 和 LaMDA) 進行比較,PaLM 和 LLAMA 在包含相似數(shù)量代碼標記的數(shù)據(jù)集上進行訓(xùn)練。對于相似數(shù)量的參數(shù),LLaMa 優(yōu)于其他通用模型,例如 LaMDA 和 PaLM,這些模型沒有專門針對代碼進行訓(xùn)練或微調(diào)。具有 13B 參數(shù)的 LLAMA,在 HumanEval 和 MBPP 上都優(yōu)于 LaMDA 137B。LLaMA 65B 也超過了訓(xùn)練時間更長的 PaLM 62B。
1.7.6 大規(guī)模多任務(wù)語言理解實驗結(jié)果
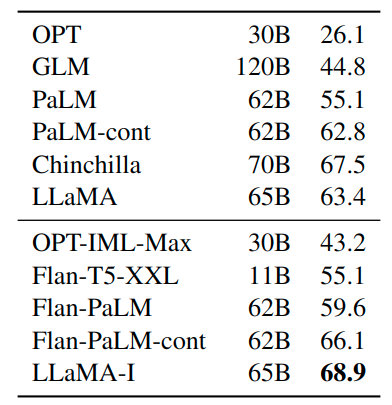
MMLU 大規(guī)模多任務(wù)語言理解基準由涵蓋各種知識領(lǐng)域的多項選擇題組成,包括人文、STEM 和社會科學(xué)。作者使用基準提供的示例在 5-shot 設(shè)置中評估我們的模型,結(jié)果如圖7所示。可以觀察到 LLaMa-65B 在大多數(shù)領(lǐng)域平均落后于 Chinchilla70B 和 PaLM-540B 幾個百分點。一個潛在的解釋是,LLaMa 在預(yù)訓(xùn)練數(shù)據(jù)中只使用了有限數(shù)量的書籍和學(xué)術(shù)論文,即 ArXiv、Gutenberg 和 Books3,總計只有 177GB,而其他的模型訓(xùn)練了多達 2TB 的書籍。
作者還發(fā)現(xiàn)加入一些微調(diào)指令也能夠提升 大規(guī)模多任務(wù)語言理解的性能。盡管 LLaMA-65B 的非微調(diào)版本已經(jīng)能夠遵循基本指令,但可以觀察到非常少量的微調(diào)提高了 MMLU 的性能,并進一步提高了模型遵循指令的能力。
如下圖8所示,盡管這里使用的指令微調(diào)方法很簡單,但在 MMLU 上達到了 68.9%。LLAMA-I (65B) 優(yōu)于 MMLU 現(xiàn)有中等大小的指令微調(diào)模型,但仍遠未達到最先進的水平。
1.8 訓(xùn)練期間的性能變化
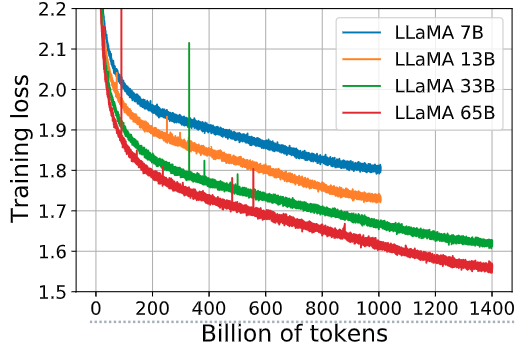
如下圖9所示是 7B、13B、33B 和 65B 這幾個模型在一些問答和常識基準的表現(xiàn)隨著 training token 的變化,圖10是 7B、13B、33B 和 65B 這幾個模型的 training loss 隨著 training token 的變化。在大多數(shù)基準測試中,性能穩(wěn)步提高,并且與模型的訓(xùn)練困惑度相關(guān)。
參考
https://blog.csdn.net/weixin_44826203/article/details/129255185
-
^https://arxiv.org/abs/2203.15556 -
^Neural machine translation of rare words with subword units -
^Root Mean Square Layer Normalization -
^Glu variants improve transformer -
^RoFormer: Enhanced Transformer with Rotary Position Embedding -
^https://github.com/facebookresearch/xformers