
EfficientNetV2:更小,更快,更好的EfficientNet
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


作者:Mostafa Ibrahim
編譯:ronghuaiyang
相比于之前的SOTA,訓(xùn)練速度快了5~10x,而且性能更高。
論文:https://arxiv.org/pdf/2104.00298.pdf
代碼:https://github.com/google/automl/efficientnetv2
通過漸進學(xué)習(xí),我們的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers數(shù)據(jù)集上顯著優(yōu)于之前的模型。通過在相同的ImageNet21k上進行預(yù)訓(xùn)練,我們的EfficientNetV2在ImageNet ILSVRC2012上實現(xiàn)了87.3%的top1精度,在使用相同的計算資源進行5到11倍的訓(xùn)練時,比最近的ViT的準確率高出2.0%。代碼可以在https://github.com/google/automl/efficientnetv2上找到。
EfficientNets已經(jīng)成為高質(zhì)量和快速圖像分類的重要手段。它們是兩年前發(fā)布的,非常受歡迎,因為它們的規(guī)模讓它們的訓(xùn)練速度比其他網(wǎng)絡(luò)快得多。幾天前谷歌發(fā)布了EfficientNetV2,在訓(xùn)練速度和準確性方面都有了很大的提高。在本文中,我們將探索這個新的EfficientNet是如何對之前的一個進行改進的。
性能更好的網(wǎng)絡(luò)(如DenseNets和EfficientNets)的主要基礎(chǔ)是用更少的參數(shù)實現(xiàn)更好的性能。當你減少參數(shù)的數(shù)量時,你通常會得到很多好處,例如更小的模型尺寸使它們更容易放到內(nèi)存中。然而,這通常會降低性能。因此,主要的挑戰(zhàn)是在不降低性能的情況下減少參數(shù)的數(shù)量。
這一挑戰(zhàn)目前主要集中在神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu)搜索(NAS)這一日益成為熱點的領(lǐng)域。在最優(yōu)情況下,我們給某個神經(jīng)網(wǎng)絡(luò)一個問題描述,然后它就會給出這個問題的最優(yōu)網(wǎng)絡(luò)結(jié)構(gòu)。
我不想在這篇文章中討論EfficientNets 。但是,我想提醒你EfficientNets的概念,這樣我們就可以精確地指出在架構(gòu)上的主要差異,從而使性能更好。EfficientNets使用NAS來構(gòu)建一個基線網(wǎng)絡(luò)(B0),然后他們使用“復(fù)合擴展”來增加網(wǎng)絡(luò)的容量,而不需要大幅增加參數(shù)的數(shù)量。在這種情況下,最重要的度量指標是FLOPS(每秒浮點運算次數(shù)),當然還有參數(shù)的數(shù)量。
1. 漸進式訓(xùn)練

EfficientNetV2使用了漸進式學(xué)習(xí)的概念,這意味著盡管在訓(xùn)練開始時圖像大小最初很小,但它們逐漸增大。這個解決方案源于這樣一個事實,即EfficientNets的訓(xùn)練速度在大圖像尺寸時開始受到影響。
漸進式學(xué)習(xí)并不是一個新概念,它在以前已經(jīng)被使用過。問題是,以前使用的時候,相同的正則化效果被用于不同大小的圖像。EfficientNetV2的作者認為這降低了網(wǎng)絡(luò)容量和性能。這就是為什么他們會隨著圖像大小的增加而動態(tài)增加正規(guī)化來解決這個問題。
如果你仔細想想,這很有道理。在小圖像上過度正則化會導(dǎo)致擬合不足,而在大圖像上過度正則化會導(dǎo)致過擬合。
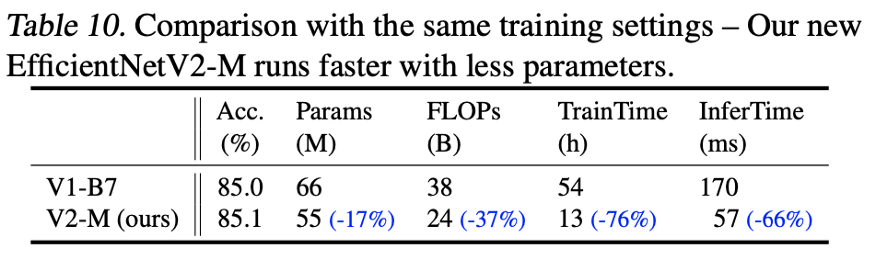
通過改進的漸進學(xué)習(xí),我們的EfficientNetV2在ImageNet、CIFAR-10、CIFAR- 100、Cars和Flowers數(shù)據(jù)集上取得了強大的結(jié)果。在ImageNet上,我們實現(xiàn)了85.7%的top-1精度,同時訓(xùn)練速度提高了3 - 9倍,比以前的模型小6.8倍
2. 在MB Conv層上構(gòu)建Fused-MB Conv層
EfficientNets使用了一個稱為“depth convolution layer”的卷積層,這些層有較少的參數(shù)和FLOPS,但它們不能充分利用GPU/CPU。為了解決這一問題,最近發(fā)表了一篇題為“MobileDets: Searching for Object Detection Architectures for Mobile accelerator”的論文,該論文通過一個名為“Fuse-MB Conv layer”的新層解決了這一問題。這個新層被使用在這里的EfficientNetV2上。然而,由于其參數(shù)較多,不能簡單地將所有舊的MB Conv層都替換成Fused-MB Conv層。
這就是為什么他們使用訓(xùn)練感知NAS來動態(tài)搜索fused和常規(guī)MB Conv層的最佳組合。NAS實驗結(jié)果表明,在較小的模型中,早期將部分MB Conv層替換為fused層可以獲得更好的性能。研究還表明,MB Conv層(沿網(wǎng)絡(luò))的擴展比越小越好。最后,它表明更小的內(nèi)核大小和更多的層是更好的。

3. 一個更加動態(tài)的方法去擴展
我認為這里值得學(xué)習(xí)的一個主要有價值的想法是他們改進網(wǎng)絡(luò)的方法。我認為總結(jié)這一方法的最好方法是首先用EfficientNet來查看問題,這是顯而易見的,但接下來的步驟是開始制定一些更動態(tài)的規(guī)則和概念,以便更好地適應(yīng)目標和目的。我們首先在漸進式學(xué)習(xí)中看到了這一點,當他們使正則化更加動態(tài),以便更好地適應(yīng)圖像大小,提高了表現(xiàn)。
我們現(xiàn)在看到這種方法再次被用于擴展網(wǎng)絡(luò)。EfficientNet使用一個簡單的復(fù)合縮放規(guī)則,均勻地擴大所有stages。EfficientNetV2的作者指出這是不必要的,因為并不是所有的階段都需要通過擴展來提高性能。這就是為什么他們使用非統(tǒng)一的擴展策略在后期逐步添加更多層的原因。他們還添加了一個縮放規(guī)則來限制最大的圖像大小,因為EfficientNets傾向于積極地將圖像大小放大。
我認為這背后的主要原因是,早期的層并不需要擴展,因為在這個早期階段,網(wǎng)絡(luò)只關(guān)注高級特征。然而,當我們深入到網(wǎng)絡(luò)的更深層,并開始研究低級特征時,我們將需要更大的層來完全消化這些細節(jié)。
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運營維護的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進步!