
谷歌打怪升級之路:從EfficientNet到EfficientNetV2(上)
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
EfficientNet是繼ResNet之后又一個大眾所熟知的CNN網(wǎng)絡(luò),谷歌在19年提出的EfficientNet無論是效果,參數(shù)量還是速度均大幅度超越之前的網(wǎng)絡(luò),EfficientNet背后的主要設(shè)計(jì)是采用了復(fù)合縮放策略(Compound Model Scaling),其統(tǒng)一地縮放模型的三個維度(depth,width,resolution)。在21年4月,谷歌團(tuán)隊(duì)又提出了優(yōu)化版本EfficientNetV2,相比V1版本,其參數(shù)量更小,但訓(xùn)練速度更快。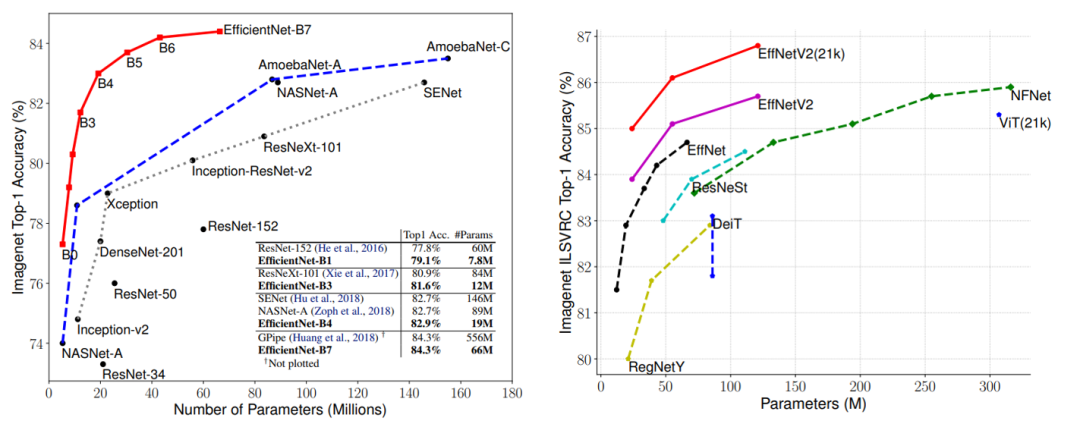
EfficientNet
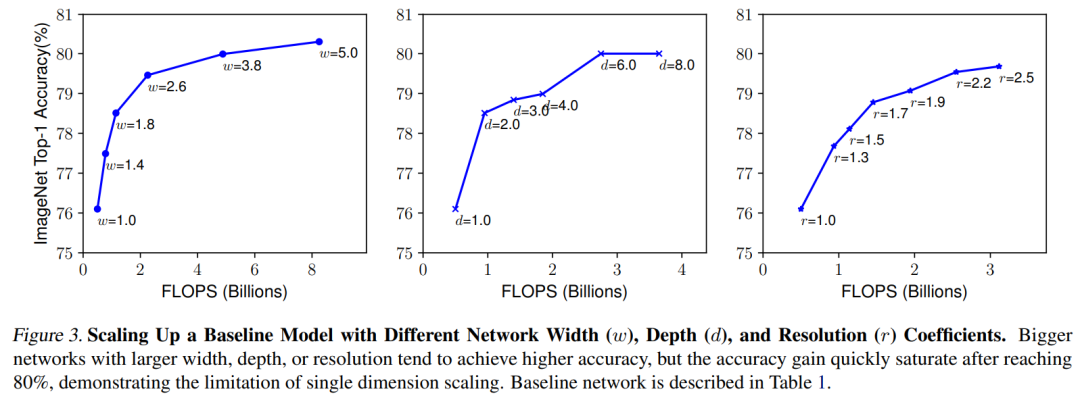
對于一個CNN網(wǎng)絡(luò)來說,影響模型參數(shù)大小和速度的主要有三個方面:depth,width,resolution (image size)。depth指的是模型的深度,即網(wǎng)絡(luò)的層數(shù),網(wǎng)絡(luò)越深,感受野越大,提取的特征語義越強(qiáng);width指的是網(wǎng)絡(luò)特征維度大小(channels),特征維度越大,模型的表征能力越強(qiáng);resolution指的是網(wǎng)絡(luò)的輸入圖像大小,即HxW,輸入圖像分辨率越大,越有利于提出更細(xì)粒度特征。depth和width影響模型參數(shù)大小和速度,但是resolution只影響模型速度(分辨率越大,計(jì)算量越大)。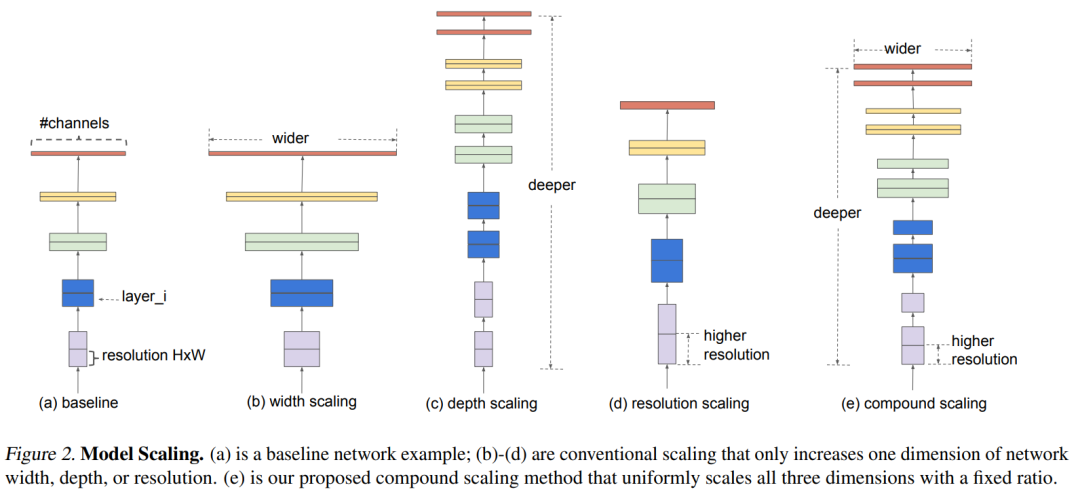 對于model scaling,也是通過scale這三個方面來實(shí)現(xiàn)的,上圖中b,c和d分別是對三個方面進(jìn)行scaling。但是之前的工作主要是調(diào)節(jié)這三個方面中的某一個方面來實(shí)現(xiàn)model scaling,如ResNet50到ResNet101只是增加了網(wǎng)絡(luò)的深度depth,而WidResNet是調(diào)整網(wǎng)絡(luò)的width。論文中發(fā)現(xiàn),如果單純地只對某一個方面scaling,隨著模型增大,性能會很快達(dá)到瓶頸,如下圖所示,對于baseline model,分別單獨(dú)縮放模型的depth,width,resolution,隨著模型變大,性能提升會很快飽和。
對于model scaling,也是通過scale這三個方面來實(shí)現(xiàn)的,上圖中b,c和d分別是對三個方面進(jìn)行scaling。但是之前的工作主要是調(diào)節(jié)這三個方面中的某一個方面來實(shí)現(xiàn)model scaling,如ResNet50到ResNet101只是增加了網(wǎng)絡(luò)的深度depth,而WidResNet是調(diào)整網(wǎng)絡(luò)的width。論文中發(fā)現(xiàn),如果單純地只對某一個方面scaling,隨著模型增大,性能會很快達(dá)到瓶頸,如下圖所示,對于baseline model,分別單獨(dú)縮放模型的depth,width,resolution,隨著模型變大,性能提升會很快飽和。
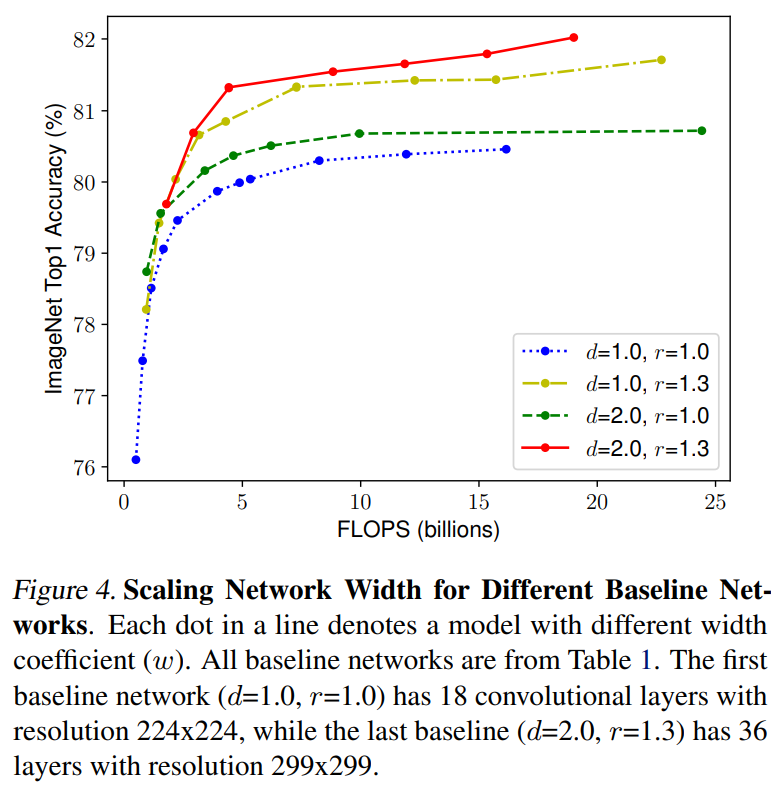
 直觀上看,如果模型的輸入圖片分辨率增加,那么應(yīng)該同時增加模型深度來增大感受野以提取同樣范圍大小的特征,相應(yīng)地,也應(yīng)該增加模型width來捕獲更細(xì)粒度的特征。所以說,理論上最好統(tǒng)一地對三個方面進(jìn)行scaling,而不是只針對某一個方面。論文中對比了不同depth和resolution下的對width進(jìn)行縮放的模型效果,如下圖所示,對于d=1.0和r=1.0就是只改變width,可以看到模型效果很快達(dá)到瓶頸,但是如果設(shè)置更大的depth和resolution(d=2.0和r=1.3),對width進(jìn)行縮放能取得更好的效果。
直觀上看,如果模型的輸入圖片分辨率增加,那么應(yīng)該同時增加模型深度來增大感受野以提取同樣范圍大小的特征,相應(yīng)地,也應(yīng)該增加模型width來捕獲更細(xì)粒度的特征。所以說,理論上最好統(tǒng)一地對三個方面進(jìn)行scaling,而不是只針對某一個方面。論文中對比了不同depth和resolution下的對width進(jìn)行縮放的模型效果,如下圖所示,對于d=1.0和r=1.0就是只改變width,可以看到模型效果很快達(dá)到瓶頸,但是如果設(shè)置更大的depth和resolution(d=2.0和r=1.3),對width進(jìn)行縮放能取得更好的效果。
 此外,為了實(shí)現(xiàn)更好的效果和模型效率,也應(yīng)該要平衡網(wǎng)絡(luò)的三個方面,讓模型各個方面均衡發(fā)展。據(jù)此,論文提出了一種復(fù)合縮放策略( compound scaling ),即通過一個統(tǒng)一的系數(shù)來均衡地縮放depth,width,resolution,這里限制如下:
此外,為了實(shí)現(xiàn)更好的效果和模型效率,也應(yīng)該要平衡網(wǎng)絡(luò)的三個方面,讓模型各個方面均衡發(fā)展。據(jù)此,論文提出了一種復(fù)合縮放策略( compound scaling ),即通過一個統(tǒng)一的系數(shù)來均衡地縮放depth,width,resolution,這里限制如下:
這里的是常量,分別表示depth,width和resolution三個方面的基礎(chǔ)系數(shù),這里只需要調(diào)整就可以實(shí)現(xiàn)模型的縮放。對于卷積操作,其FLOPS一般和成正比,如果depth變?yōu)?倍,那么計(jì)算量也變?yōu)?倍,但是width和resolution變?yōu)?倍的話,計(jì)算量變?yōu)?倍。對于baseline模型,其系數(shù),當(dāng)采用一個新的系數(shù)對模型進(jìn)行縮放時,模型的FLOPS將變?yōu)閎aseline模型的,這里限制了,所以FLOPS就近似增加了。
論文中通過一個多目標(biāo)的NAS來得到baseline模型(借鑒MnasNet),這里優(yōu)化的目標(biāo)是模型的ACC和FLOPS,其中target FLOPS是400M,最終得到了EfficientNet-B0模型,其模型架構(gòu)如下表所示: 可以看到EfficientNet-B0的輸入大小為224x224,首先是一個stride=2的3x3卷積層,最后是一個1x1卷積+global pooling+FC分類層,其余的stage主體是MBConv,這個指的是MobileNetV2中提出的mobile inverted bottleneck block(conv1x1-> depthwise conv3x3->conv1x1+shortcut),唯一的區(qū)別是增加了SE結(jié)構(gòu)來進(jìn)行優(yōu)化,表中的MBConv后面的數(shù)字表示的是expand_ratio(第一個1x1卷積要擴(kuò)大channels的系數(shù))。目前EfficientNet已經(jīng)在torchvision中實(shí)現(xiàn),這里給出MBConv的實(shí)現(xiàn)源碼:
可以看到EfficientNet-B0的輸入大小為224x224,首先是一個stride=2的3x3卷積層,最后是一個1x1卷積+global pooling+FC分類層,其余的stage主體是MBConv,這個指的是MobileNetV2中提出的mobile inverted bottleneck block(conv1x1-> depthwise conv3x3->conv1x1+shortcut),唯一的區(qū)別是增加了SE結(jié)構(gòu)來進(jìn)行優(yōu)化,表中的MBConv后面的數(shù)字表示的是expand_ratio(第一個1x1卷積要擴(kuò)大channels的系數(shù))。目前EfficientNet已經(jīng)在torchvision中實(shí)現(xiàn),這里給出MBConv的實(shí)現(xiàn)源碼:
class MBConv(nn.Module):
def __init__(self, cnf: MBConvConfig, stochastic_depth_prob: float, norm_layer: Callable[..., nn.Module],
se_layer: Callable[..., nn.Module] = SqueezeExcitation) -> None:
super().__init__()
if not (1 <= cnf.stride <= 2):
raise ValueError('illegal stride value')
# 只有stride=1且輸入和輸出channels相同時才有shortcut
self.use_res_connect = cnf.stride == 1 and cnf.input_channels == cnf.out_channels
layers: List[nn.Module] = []
activation_layer = nn.SiLU
# expand
expanded_channels = cnf.adjust_channels(cnf.input_channels, cnf.expand_ratio)
if expanded_channels != cnf.input_channels:
layers.append(ConvBNActivation(cnf.input_channels, expanded_channels, kernel_size=1,
norm_layer=norm_layer, activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(expanded_channels, expanded_channels, kernel_size=cnf.kernel,
stride=cnf.stride, groups=expanded_channels,
norm_layer=norm_layer, activation_layer=activation_layer))
# squeeze and excitation
squeeze_channels = max(1, cnf.input_channels // 4)
layers.append(se_layer(expanded_channels, squeeze_channels))
# project
layers.append(ConvBNActivation(expanded_channels, cnf.out_channels, kernel_size=1, norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.stochastic_depth = StochasticDepth(stochastic_depth_prob, "row")
self.out_channels = cnf.out_channels
def forward(self, input: Tensor) -> Tensor:
result = self.block(input)
if self.use_res_connect:
result = self.stochastic_depth(result)
result += input
return result
通過NAS搜索得到的EfficientNet-B0作為baseline模型,其系數(shù),根據(jù)前面的公式可以簡單地通過網(wǎng)格搜索來確定,搜索得到的最佳設(shè)置是:。有了baseline模型,就可以按照復(fù)合縮放策略來對模型進(jìn)行縮放以得到不同size的模型,論文中通過調(diào)整共得到了另外7個模型,即EfficientNet-B1~EfficientNet-B7,其中EfficientNet-B7的參數(shù)量為66M(輸入大小為600),而EfficientNet-B0的參數(shù)量僅為5.3M。不過,在谷歌開源的源碼中,不同的模型是通過給出width,depth增大的系數(shù)來確定的,如下所示::
def efficientnet_params(model_name):
"""Get efficientnet params based on model name."""
params_dict = {
# (width_coefficient, depth_coefficient, resolution, dropout_rate)
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
# 后面兩個是更大的模型
'efficientnet-b8': (2.2, 3.6, 672, 0.5),
'efficientnet-l2': (4.3, 5.3, 800, 0.5),
}
return params_dict[model_name]
根據(jù)增大的系數(shù),可以通過EfficientNet-B0來計(jì)算其他模型的depth和width,實(shí)際中是通過下面的函數(shù)來確定:
def _make_divisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# 簡單乘以增大系數(shù)外,要限制depth和width是8的整數(shù)倍
def adjust_channels(channels: int, width_mult: float, min_value: Optional[int] = None) -> int:
return _make_divisible(channels * width_mult, 8, min_value)
EfficientNet在ImageNet數(shù)據(jù)集上的訓(xùn)練采用RMSProp 優(yōu)化器,訓(xùn)練360epoch,而且策略上采用 SiLU (Swish-1) activation,AutoAugment和stochastic depth,這其實(shí)相比ResNet的訓(xùn)練已經(jīng)增強(qiáng)了不少(ResNet訓(xùn)練epoch為90,數(shù)據(jù)增強(qiáng)只有隨機(jī)裁剪(random-size cropping)和水平翻轉(zhuǎn)(flip horizontal))。在ImageNet上效果如下表所示,可以看到不同size的EfficientNet比其它CNN模型在acc,模型參數(shù)和FLOPS上均存在絕對性優(yōu)勢。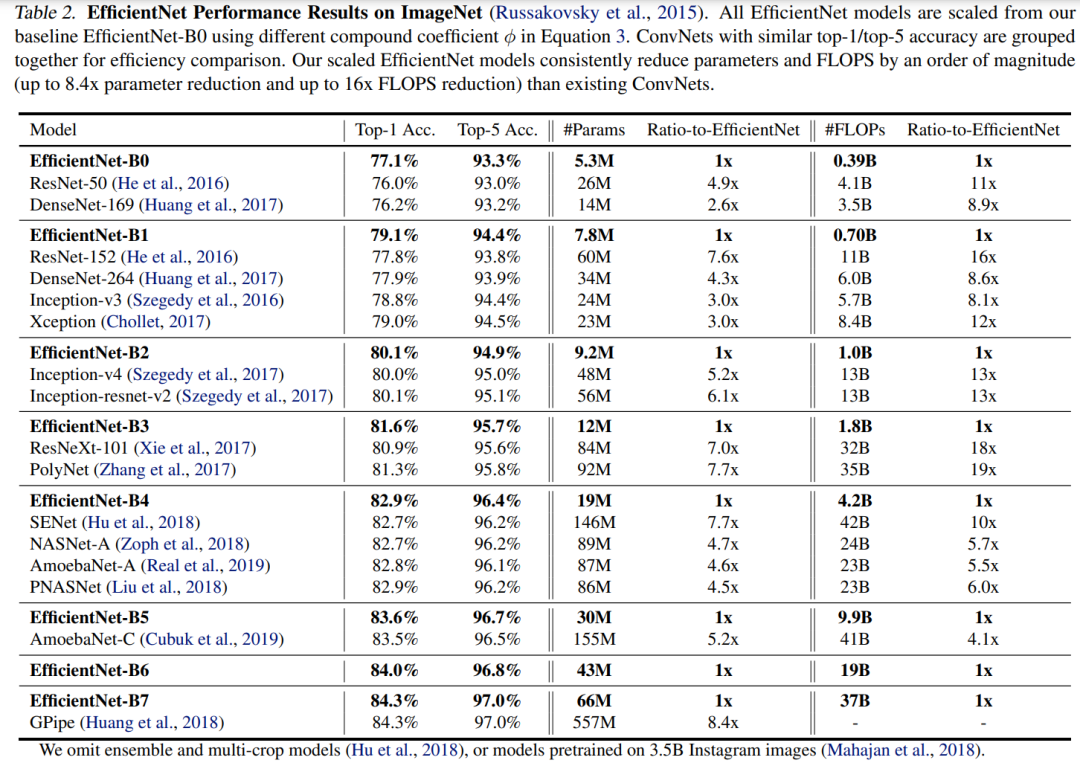 基于EfficientNet,谷歌在隨后也做了很多其它工作,如其在19年提出Noisy Student Training (EfficientNet-L2) ,其在ImageNet上的top1-acc達(dá)到了 88.4% ,還有谷歌后面基于EfficientNet提出的檢測模型EfficientDet。
基于EfficientNet,谷歌在隨后也做了很多其它工作,如其在19年提出Noisy Student Training (EfficientNet-L2) ,其在ImageNet上的top1-acc達(dá)到了 88.4% ,還有谷歌后面基于EfficientNet提出的檢測模型EfficientDet。
參考
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks EfficientNetV2: Smaller Models and Faster Training
推薦閱讀
谷歌AI用30億數(shù)據(jù)訓(xùn)練了一個20億參數(shù)Vision Transformer模型,在ImageNet上達(dá)到新的SOTA!
"未來"的經(jīng)典之作ViT:transformer is all you need!
PVT:可用于密集任務(wù)backbone的金字塔視覺transformer!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
不妨試試MoCo,來替換ImageNet上pretrain模型!
機(jī)器學(xué)習(xí)算法工程師
一個用心的公眾號
