
阿里云AI發(fā)女朋友啦!
點(diǎn)擊上方藍(lán)色“程序猿DD”,選擇“設(shè)為星標(biāo)”
回復(fù)“資源”獲取獨(dú)家整理的學(xué)習(xí)資料!

你,要不要擺脫技術(shù)人單身率高的魔咒?
這里有一份相親戰(zhàn)斗力評估指數(shù),阿里云幫你測一測以后還能不能找到對象。
據(jù)說是借助哥倫比亞大學(xué)多年研究相親找對象的心血,通過幾個(gè)簡單的特征來做評估。
具體模(yuan)型(fen)的測試頁面掃下方二維碼即可試玩~
在正式開始實(shí)驗(yàn)之前,我們需要尋找一個(gè)簡單好用方便上手的工具,這里我推薦一波阿里云的PAI-DSW探索者版,它對于個(gè)人開發(fā)者是免費(fèi)的,還有免費(fèi)GPU資源可以使用,實(shí)驗(yàn)的數(shù)據(jù)更會(huì)免費(fèi)保存30天。
點(diǎn)擊這里(鏈接:https://dsw-dev.data.aliyun.com/#/)只要登陸就可直接使用。今天,我們就會(huì)通過這個(gè)工具來探索人性的奧秘,走進(jìn)兩性關(guān)系的神秘空間,嘿嘿嘿。
整個(gè)實(shí)驗(yàn)的數(shù)據(jù)收集于一個(gè)線下快速相親的實(shí)驗(yàn)。(鏈接:https://faculty.chicagobooth.edu/emir.kamenica/documents/genderDifferences.pdf)這個(gè)實(shí)驗(yàn)中,參與者被要求參加多輪與異性進(jìn)行的快速相親,每輪相親持續(xù)4分鐘,在4分鐘結(jié)束后,參與者雙方會(huì)被詢問是否愿意與他們的對象再見面。只有當(dāng)雙方都回答了“是”的時(shí)候,這次相親才算是配對成功。
同時(shí),參與者也會(huì)被要求通過以量化的方式從外觀吸引力,真誠度,智商,風(fēng)趣程度,事業(yè)心,興趣愛好這六個(gè)方向來評估他們的相親對象。
這個(gè)數(shù)據(jù)集也包含了很多參加快速相親的參與者的其他相關(guān)信息,比如地理位置,喜好,對于理想對象的偏好,收入水平,職業(yè)以及教育背景等等。關(guān)于整個(gè)數(shù)據(jù)集的具體特征描述可以參考這個(gè)文件。(鏈接:https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc)
本次我們實(shí)驗(yàn)的目的主要是為了找出,當(dāng)一個(gè)人在參加快速相親時(shí),到底會(huì)有多高的幾率能夠遇到自己心動(dòng)的人并成功牽手。
在我們建模分析探索人性的秘密之前,讓我們先讀入數(shù)據(jù),來看看我們的數(shù)據(jù)集長什么樣。
import?pandas?as?pd
df?=?pd.read_csv('Speed?Dating?Data.csv',?encoding='gbk')
print(df.shape)
通過觀察,我們不難發(fā)現(xiàn),在這短短的兩年中,這個(gè)實(shí)驗(yàn)的小酒館經(jīng)歷了8000多場快速相親的實(shí)驗(yàn)。由此我們可以非常輕易的推斷出,小酒館的老板應(yīng)該賺的盆滿缽滿(大霧)
然后從數(shù)據(jù)的寬度來看,我們會(huì)發(fā)現(xiàn)一共有接近200個(gè)特征。
關(guān)于每個(gè)特征的具體描述大家可以參考這篇文檔鏈接:https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc。
然后我們再觀察數(shù)據(jù)的完整度,看看是否有缺失數(shù)據(jù)。
percent_missing?=?df.isnull().sum()?*?100?/?len(df)
missing_value_df?=?pd.DataFrame({
'column_name':?df.columns,
'percent_missing':?percent_missing
})
missing_value_df.sort_values(by='percent_missing')通過以上代碼,我們不難發(fā)現(xiàn),其實(shí)還有很多的特征是缺失的。這一點(diǎn)在我們后面做分析和建模的時(shí)候,都需要關(guān)注到。因?yàn)橐坏┮粋€(gè)特征缺失的數(shù)據(jù)較多,就會(huì)導(dǎo)致分析誤差變大或者模型過擬合/精度下降。看完數(shù)據(jù)的完整程度,我們就可以繼續(xù)往下探索了。
然后第一個(gè)問題就來了,在這8000多場的快速相親中,到底有多少場相親成功為參加的雙方找到了合適的伴侶的?帶著這個(gè)問題,我們就可以開始我們的第一個(gè)探索性數(shù)據(jù)分析。
#?多少人通過Speed?Dating找到了對象
plt.subplots(figsize=(3,3),?dpi=110,)
#?構(gòu)造數(shù)據(jù)
size_of_groups=df.match.value_counts().values
single_percentage?=?round(size_of_groups[0]/sum(size_of_groups)?*?100,2)
matched_percentage?=?round(size_of_groups[1]/sum(size_of_groups)*?100,2)
names?=?[
'Single:'?+?str(single_percentage)?+?'%',
'Matched'?+?str(matched_percentage)?+?'%']
#?創(chuàng)建餅圖
plt.pie(
size_of_groups,
labels=names,
labeldistance=1.2,
colors=Pastel1_3.hex_colors
)
plt.show()
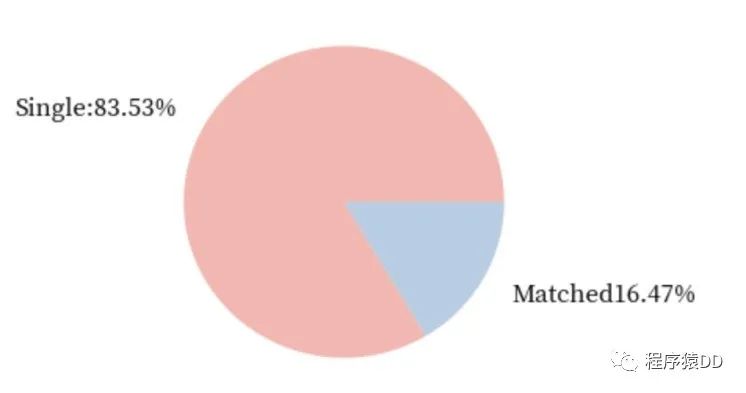
從上邊的餅圖我們可以發(fā)現(xiàn),真正通過快速相親找到對象的比率僅有16.47%。
然后我們就迎來了我們的第二個(gè)問題,這個(gè)比率和參加的人的性別是否有關(guān)呢?這里我們也通過Pandas自帶的filter的方式
df[df.gender?==?0]
來篩選數(shù)據(jù)集中的性別。通過閱讀數(shù)據(jù)集的文檔,我們知道0代表的是女生,1代表的是男生。然后同理,我們執(zhí)行類似的代碼
#?多少女生通過Speed?Dating找到了對象
plt.subplots(figsize=(3,3),?dpi=110,)
#?構(gòu)造數(shù)據(jù)
size_of_groups=df[df.gender?==?0].match.value_counts().values?#?男生只需要吧0替換成1即可
single_percentage?=?round(size_of_groups[0]/sum(size_of_groups)?*?100,2)
matched_percentage?=?round(size_of_groups[1]/sum(size_of_groups)*?100,2)
names?=?[
'Single:'?+?str(single_percentage)?+?'%',
'Matched'?+?str(matched_percentage)?+?'%']
#?創(chuàng)建餅圖
plt.pie(
size_of_groups,
labels=names,
labeldistance=1.2,
colors=Pastel1_3.hex_colors
)
plt.show()
來找出女生和男生分別在快速相親中找到對象的幾率的。
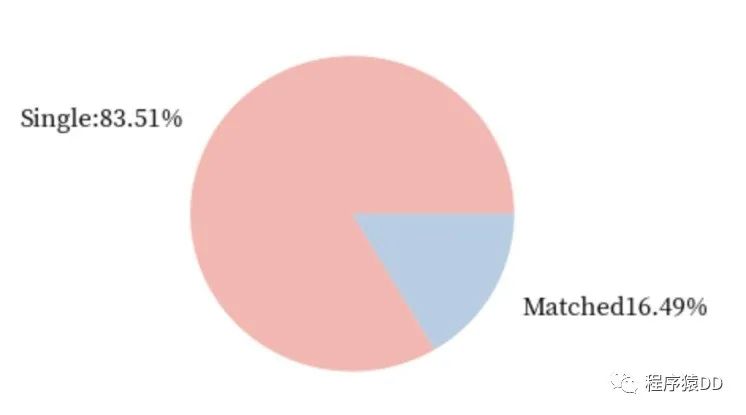
女生的幾率:
男生的幾率:
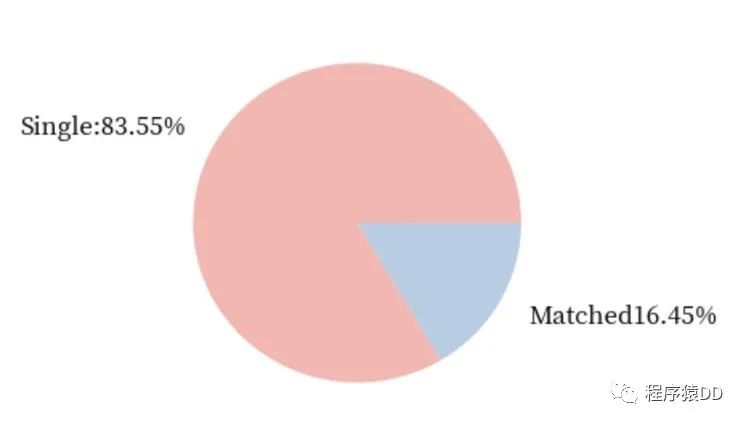
不難發(fā)現(xiàn),在快速相親中,女生相比于男生還是稍微占據(jù)一些優(yōu)勢的。女生成功匹配的幾率比男生成功匹配的幾率超出了0.04。
然后第二個(gè)問題來了:是什么樣的人在參加快速相親這樣的活動(dòng)呢?真的都是大齡青年(年齡大于30)嘛?這個(gè)時(shí)候我們就可以通過對參加人群的年齡分布來做一個(gè)統(tǒng)計(jì)分析。
#?年齡分布
age?=?df[np.isfinite(df['age'])]['age']
plt.hist(age,bins=35)
plt.xlabel('Age')
plt.ylabel('Frequency')
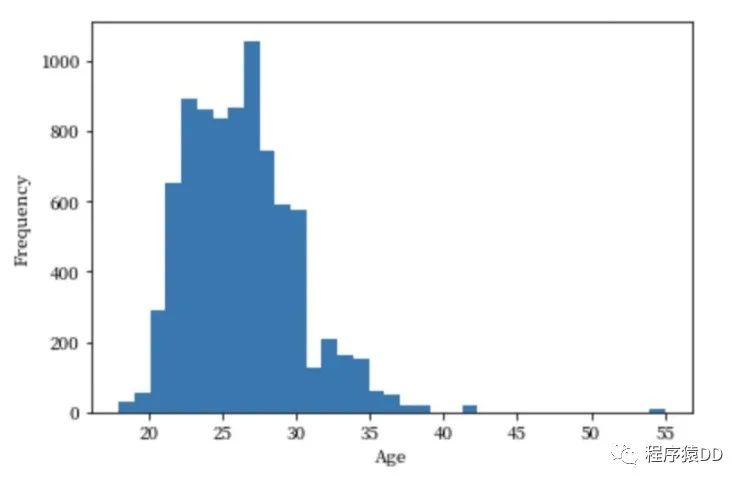
不難發(fā)現(xiàn),參加快速相親的人群主要是22~28歲的群體。這點(diǎn)與我們的預(yù)期有些不太符合,因?yàn)橹髁魅巳翰⒉皇谴簖g青年。接下來的問題就是,年齡是否會(huì)影響相親的成功率呢?和性別相比,哪個(gè)對于成功率的影響更大?這兩個(gè)問題在本文就先埋下一個(gè)伏筆,不一一探索了,希望閱讀文章的你能夠自己探索。
但是這里可以給出一個(gè)非常好用的探索相關(guān)性的方式叫做數(shù)據(jù)相關(guān)性分析。通過閱讀數(shù)據(jù)集的描述,我已經(jīng)為大家選擇好了一些合適的特征去進(jìn)行相關(guān)性分析。這里合適的定義是指:1. 數(shù)據(jù)為數(shù)字類型,而不是字符串等無法量化的值。2.數(shù)據(jù)的缺失比率較低
date_df?=?df[[
'iid',?'gender',?'pid',?'match',?'int_corr',?'samerace',?'age_o',
'race_o',?'pf_o_att',?'pf_o_sin',?'pf_o_int',?'pf_o_fun',?'pf_o_amb',
'pf_o_sha',?'dec_o',?'attr_o',?'sinc_o',?'intel_o',?'fun_o',?'like_o',
'prob_o',?'met_o',?'age',?'race',?'imprace',?'imprelig',?'goal',?'date',
'go_out',?'career_c',?'sports',?'tvsports',?'exercise',?'dining',
'museums',?'art',?'hiking',?'gaming',?'clubbing',?'reading',?'tv',
'theater',?'movies',?'concerts',?'music',?'shopping',?'yoga',?'attr1_1',
'sinc1_1',?'intel1_1',?'fun1_1',?'amb1_1',?'attr3_1',?'sinc3_1',
'fun3_1',?'intel3_1',?'dec',?'attr',?'sinc',?'intel',?'fun',?'like',
'prob',?'met'
]]
#?heatmap
plt.subplots(figsize=(20,15))
ax?=?plt.axes()
ax.set_title("Correlation?Heatmap")
corr?=?date_df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
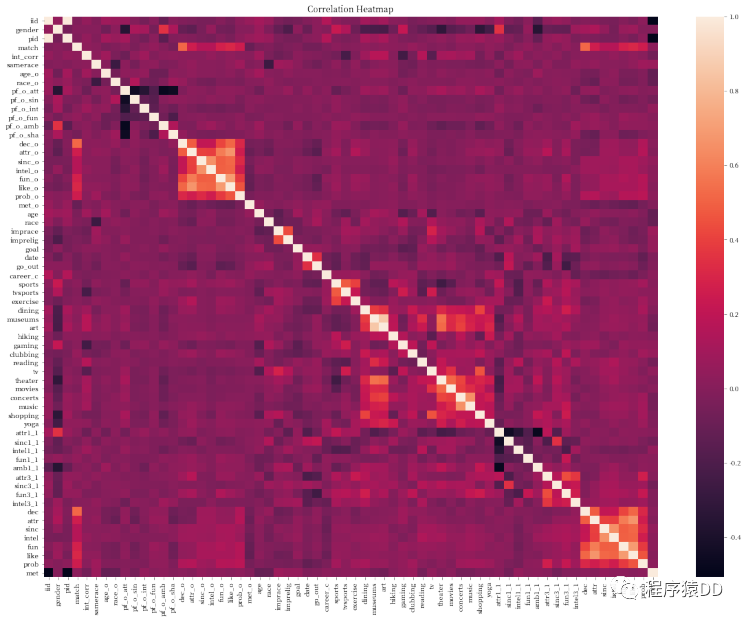
通過上面這張圖這張相關(guān)性分析的熱力圖,我們可以先關(guān)注一些特別亮的和特別暗的點(diǎn)。比如我們可以發(fā)現(xiàn),在 pf_o_att這個(gè)表示相親對象給出的外觀吸引力這個(gè)特征上,和其他相親對象給出的評分基本都是嚴(yán)重負(fù)相關(guān)的,除了pf_o_fun這一特征。由此我們可以推斷出兩個(gè)點(diǎn):
大家會(huì)認(rèn)為外觀更加吸引人的人在智商,事業(yè)心,真誠度上表現(xiàn)會(huì)相對較差。換句話說,可能就是顏值越高越浪
幽默風(fēng)趣的人更容易讓人覺得外觀上有吸引力,比如下面這位幽默風(fēng)趣的男士(大霧):

然后我們再看看我們最關(guān)注的特征 match,和這一個(gè)特征相關(guān)性比較高的特征是哪幾個(gè)呢?不難發(fā)現(xiàn),其實(shí)就是'attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o'這幾個(gè)特征,分別是相親對方給出的關(guān)于外觀,真誠度,智商,風(fēng)趣程度,事業(yè)線以及興趣愛好的打分。接下來我們就可以根據(jù)這個(gè)來進(jìn)行建模了。首先我們將我們的特征和結(jié)果列都放到一個(gè)Dataframe中,然后再去除含有空值的紀(jì)錄。最后我們再分為X和Y用來做訓(xùn)練。當(dāng)然分為X,y之后,由于我們在最開始就發(fā)現(xiàn)只有16.47%的參與場次中成功匹配了,所以我們的數(shù)據(jù)有嚴(yán)重的不均衡,這里我們可以用SVMSMOTE(鏈接:https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SVMSMOTE.html)來增加一下我們的數(shù)據(jù)量避免模型出現(xiàn)過度擬合。
#?preparing?the?data
clean_df?=?df[['attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o','match']]
clean_df.dropna(inplace=True)
X=clean_df[['attr_o','sinc_o','intel_o','fun_o','amb_o','shar_o',]]
y=clean_df['match']
oversample?=?imblearn.over_sampling.SVMSMOTE()
X,?y?=?oversample.fit_resample(X,?y)
#?做訓(xùn)練集和測試集分割
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.2,?random_state=0,?stratify=y)
數(shù)據(jù)準(zhǔn)備好之后,我們就可以進(jìn)行模型的構(gòu)建和訓(xùn)練了。通過以下代碼,我們可以構(gòu)建一個(gè)簡單的邏輯回歸的模型,并在測試集上來測試。
#?logistic?regression?classification?model
model?=?LogisticRegression(C=1,?random_state=0)
lrc?=?model.fit(X_train,?y_train)
predict_train_lrc?=?lrc.predict(X_train)
predict_test_lrc?=?lrc.predict(X_test)
print('Training?Accuracy:',?metrics.accuracy_score(y_train,?predict_train_lrc))
print('Validation?Accuracy:',?metrics.accuracy_score(y_test,?predict_test_lrc))
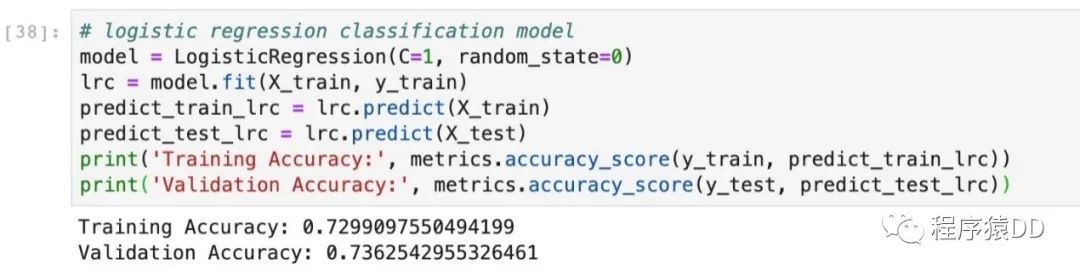
我們可以看到結(jié)果為0.83左右,這樣我們就完成了一個(gè)預(yù)測在快速相親中是否能夠成功配對的機(jī)器學(xué)習(xí)模型。
針對這個(gè)模型,數(shù)據(jù)科學(xué)老司機(jī)我還專門制作了一個(gè)小游戲頁面),來測試你的相親戰(zhàn)斗力指數(shù)。快來體驗(yàn)吧:
https://tianchi.aliyun.com/specials/promotion/dsw-hol?referFrom=mvp?