
你真的了解 ConcurrentHashMap 嗎?
作者:Amaranth007
blog.csdn.net/qq_32828253/article/details/110450249
HashMap是線程不安,而hashTable雖然是線程安全,但是性能很差。java提供了ConcurrentHashMap來替代hashTable。
我們先來看一下JDK1.7的currentMap的結構:
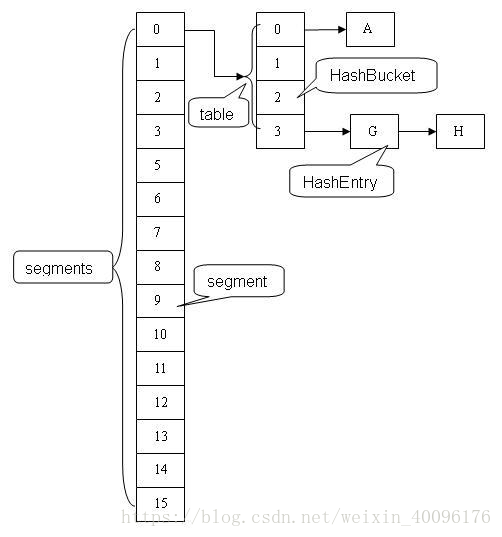
在ConcurrentHashMap中有個重要的概念就是Segment。我們知道HashMap的結構是數(shù)組+鏈表形式,從圖中我們可以看出其實每個segment就類似于一個HashMap。Segment包含一個HashEntry數(shù)組,數(shù)組中的每一個HashEntry既是一個鍵值對,也是一個鏈表的頭節(jié)點。
在ConcurrentHashMap中有2的N次方個Segment,共同保存在一個名為segments的數(shù)組當中。可以說,ConcurrentHashMap是一個二級哈希表。在一個總的哈希表下面,有若干個子哈希表。
為什么說ConcurrentHashMap的性能要比HashTable好,HashTables是用全局同步鎖,而CconurrentHashMap采用的是鎖分段,每一個Segment就好比一個自治區(qū),讀寫操作高度自治,Segment之間互不干擾。
先來看看幾個并發(fā)的場景:
Case1:不同Segment的并發(fā)寫入
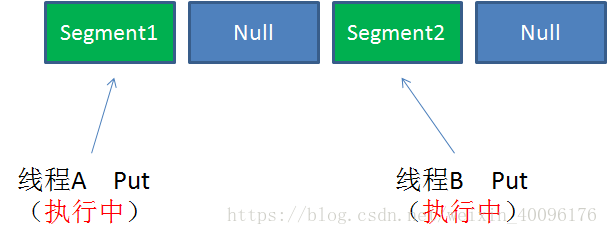
不同Segment的寫入是可以并發(fā)執(zhí)行的。
Case2:同一Segment的一寫一讀
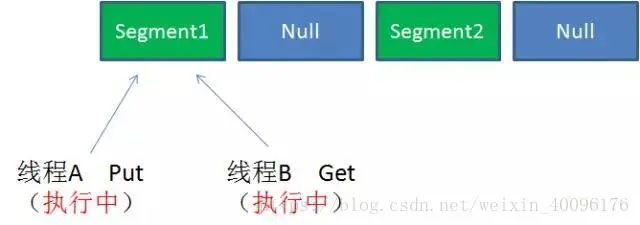
同一Segment的寫和讀是可以并發(fā)執(zhí)行的。
Case3:同一Segment的并發(fā)寫入
Segment的寫入是需要上鎖的,因此對同一Segment的并發(fā)寫入會被阻塞。
由此可見,ConcurrentHashMap當中每個Segment各自持有一把鎖。在保證線程安全的同時降低了鎖的粒度,讓并發(fā)操作效率更高。
上面我們說過,每個Segment就好比一個HashMap,其實里面的操作原理都差不多,只是Segment里面加了鎖。
Get方法:
為輸入的Key做Hash運算,得到hash值。 通過hash值,定位到對應的Segment對象 再次通過hash值,定位到Segment當中數(shù)組的具體位置。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
Put方法:
為輸入的Key做Hash運算,得到hash值。 通過hash值,定位到對應的Segment對象 獲取可重入鎖 再次通過hash值,定位到Segment當中數(shù)組的具體位置。 插入或覆蓋HashEntry對象。 釋放鎖。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
可以看出get方法并沒有加鎖,那怎么保證讀取的正確性呢,這是應為value變量用了volatile來修飾,后面再詳細講解volatile。(搜索公眾號:武哥聊編程,回復“面試題”,送你一份Java面試題寶典)
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
.....
size方法
既然每一個Segment都各自加鎖,那么我們在統(tǒng)計size()的時候怎么保證解決一直性的問題,比如我們在計算size時,有其他線程在添加或刪除元素。
/**
* Returns the number of key-value mappings in this map. If the
* map contains more than <tt>Integer.MAX_VALUE</tt> elements, returns
* <tt>Integer.MAX_VALUE</tt>.
*
* @return the number of key-value mappings in this map
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
ConcurrentHashMap的Size方法是一個嵌套循環(huán),大體邏輯如下:
遍歷所有的Segment。 把Segment的元素數(shù)量累加起來。 把Segment的修改次數(shù)累加起來。 判斷所有Segment的總修改次數(shù)是否大于上一次的總修改次數(shù)。如果大于,說明統(tǒng)計過程中有修改,重新統(tǒng)計,嘗試次數(shù)+1;如果不是。說明沒有修改,統(tǒng)計結束。 如果嘗試次數(shù)超過閾值,則對每一個Segment加鎖,再重新統(tǒng)計。 再次判斷所有Segment的總修改次數(shù)是否大于上一次的總修改次數(shù)。由于已經(jīng)加鎖,次數(shù)一定和上次相等。 釋放鎖,統(tǒng)計結束。
可以看出JDK1.7的size計算方式有點像樂觀鎖和悲觀鎖的方式,為了盡量不鎖住所有Segment,首先樂觀地假設Size過程中不會有修改。當嘗試一定次數(shù),才無奈轉為悲觀鎖,鎖住所有Segment保證強一致性。
JDK1.7和JDK1.8中ConcurrentHashMap的區(qū)別
1、在JDK1.8中ConcurrentHashMap的實現(xiàn)方式有了很大的改變,在JDK1.7中采用的是Segment + HashEntry,而Sement繼承了ReentrantLock,所以自帶鎖功能,而在JDK1.8中則取消了Segment,作者認為Segment太過臃腫,采用Node + CAS + Synchronized
ps:Synchronized一直以來被各種吐槽性能差,但java一直沒有放棄Synchronized,也一直在改進,既然作者在這里采用了Synchronized,可見Synchronized的性能應該是有所提升的,當然只是猜想哈哈哈。。。
2、在上篇HashMap中我們知道,在JDK1.8中當HashMap的鏈表個數(shù)超過8時,會轉換為紅黑樹,在ConcurrentHashMap中也不例外。這也是新能的一個小小提升。
3、在JDK1.8版本中,對于size的計算,在擴容和addCount()時已經(jīng)在處理了。JDK1.7是在調用時才去計算。
為了幫助統(tǒng)計size,ConcurrentHashMap提供了baseCount和counterCells兩個輔助變量和CounterCell輔助類,1.8中使用一個volatile類型的變量baseCount記錄元素的個數(shù),當插入新數(shù)據(jù)或則刪除數(shù)據(jù)時,會通過addCount()方法更新baseCount。
//ConcurrentHashMap中元素個數(shù),但返回的不一定是當前Map的真實元素個數(shù)。基于CAS無鎖更新
private transient volatile long baseCount;
private transient volatile CounterCell[] counterCells; // 部分元素變化的個數(shù)保存在此數(shù)組中
/**
* {@inheritDoc}
*/
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
END
我已經(jīng)更新了我的《10萬字Springboot經(jīng)典學習筆記》中,點擊下面小卡片,進入【武哥聊編程】,回復:筆記,即可免費獲取。
點贊是最大的支持
