
你真的了解 timeout 嗎?
本文來自董神,一個和曹大談笑風生的男人:
服務為什么需要 timeout 呢?提前釋放資源。
記得在上家公司時,一個 python 服務與公網(wǎng)交互,request 庫發(fā)出去的請求沒有設置 timeout... 而且還是個定時任務,占用了超多 fd。
同時微服務場景下某下游的服務阻塞卡頓,這樣會造成他的級聯(lián)上下游都雪崩了。
語言層面:對于使用線程池的語言,會消耗所有線程,worker 不夠用。其實對于 Go 來說,創(chuàng)建大量 goroutine 也會有 runtime 開銷的, 只是慢性死亡罷了。
內(nèi)核層面:還有一點超時配置的必要性,如果某服務掛了,那么內(nèi)核會幫忙收尾,根據(jù)情況或走 RST 或走 FIN,訪問者就知道連接關了。但如果主機掛了,或者中間網(wǎng)絡設備掛了,客戶端沒有超時配置,就只能通過 tcp keepalive 來判斷死鏈接,按照默認內(nèi)核配置語言兩個多小時,文末提到 redis 就是例子。
Latency
業(yè)界都用 P99 分位來衡量服務的 latency,即使這樣如果 QPS 非常高,另外 1% 的請求也會出現(xiàn) long tail。再來看幾個不同側(cè)重點的概念:
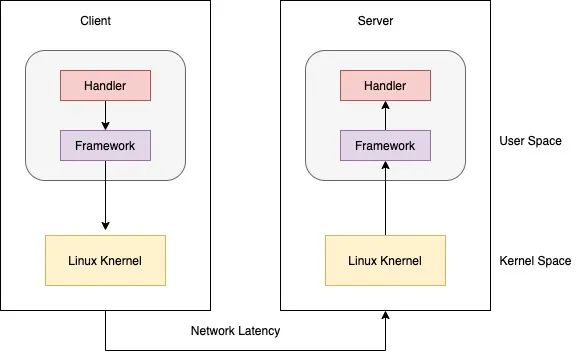
Server Side P99 統(tǒng)計的只是 server handler 處理時間。
Client P99 = client framework 時間 + client 內(nèi)核處理時間 + 網(wǎng)絡傳輸時間 + server 處理時間。
當你發(fā)現(xiàn) latency 比較高,想去 challenge 下游時,請對好口徑。通常 client p99 > server p99。
這還是普通的 server/client 模式,如果中間涉及了 lb, 或是 mesh 排查問題更要命。
可觀測性
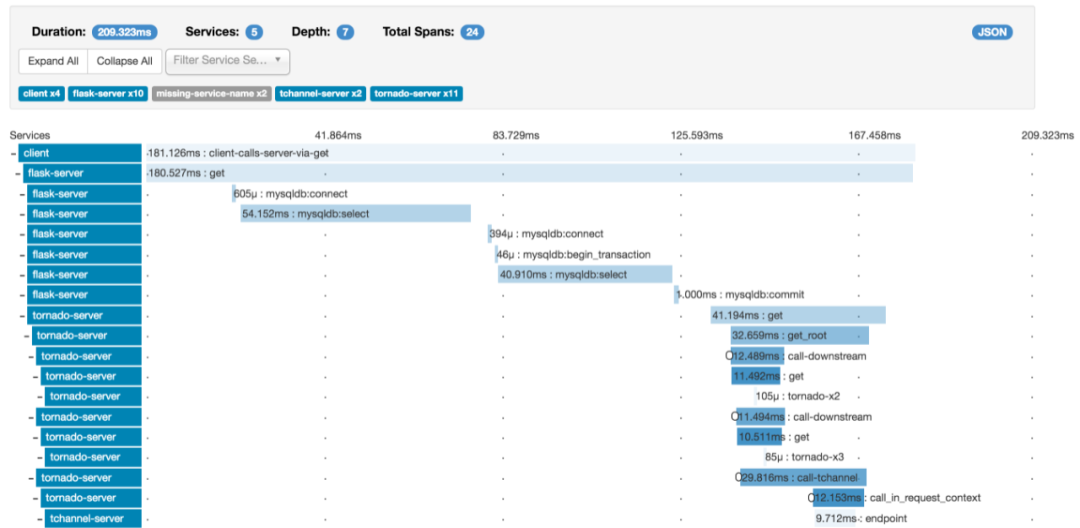
現(xiàn)在都是微服務場景,一個訂單全鏈路涉及幾十個服務,查起問題非常困難,所以分布式的 tracing 系統(tǒng)非常重要。
另外現(xiàn)在也都擁抱云原生環(huán)境,如果引入 service mesh 的話更難以排查問題。
一般 tracing 系統(tǒng)都是根據(jù) google 論文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure[1]發(fā)展而來的。
除了自己造輪子,主流的有zipkin[2], opentelemetry[3]
底層實現(xiàn)
定時器這塊業(yè)務早有標準實現(xiàn):小頂堆, 紅黑樹 和 時間輪。感興趣的同學可以搜索相關文章
原理不難,但是有公司面試都要求手寫紅黑樹,這就過份了吧。
Linux 內(nèi)核和 Nginx 的定時器采用了 紅黑樹 實現(xiàn),好多長連接系統(tǒng)多采用 時間輪。
Go 使用 小頂堆,四叉堆,比較矮胖,不是最樸素的二叉堆。
最早版本只有一個 timer 堆,所以性能非常差,精度也有問題。一般都用戶實現(xiàn)多堆,或是用時間輪實現(xiàn)。這方面的輪子比寫公眾號的碼農(nóng)都多 ^_^
后來經(jīng)過優(yōu)化 Go 內(nèi)置多堆實現(xiàn),每個 P 一個 timer 堆,性能好了很多。注意,Go 的 conn timeout 是通過用戶層 timer 實現(xiàn)的,而不是內(nèi)核的 setsockopt。
HTTP
這里要區(qū)分 http1 和 http2,以前寫過一篇 HOL blocking 的文章,感興趣可以翻下歷史
Http1 如果超時到了,那么底層庫是要關閉 tcp connection 的,強制丟棄未讀到的數(shù)據(jù),這時會產(chǎn)生大量的 timewait,要注意。
但是對于 Http2 來說,虛擬出來了 stream,做到了多路復用,只要關閉 stream 即可,底層 socket 還可以正常使用。
對于 Go Http 還有一個坑,可以參考 i/o timeout,希望你不要踩到這個net/http包的坑。
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //設置建立連接超時
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //設置發(fā)送接受數(shù)據(jù)超時
if err != nil {
return nil, err
}
return conn, nil
},
}
}
上面代碼是錯誤使用,這個導致每次 conn 連接后只設置一次超時時間:
client := &http.Client{
Transport: tr,
Timeout: 3*time.Second, // 超時加在這里,是每次調(diào)用的超時
}
正確的應該在 http.Client 結(jié)構(gòu)體里設置,感興趣的去參考全文吧。
另外服務端也要設置 timeout,以防把服務端壓跨,請參考So you want to expose Go on the Internet[4]
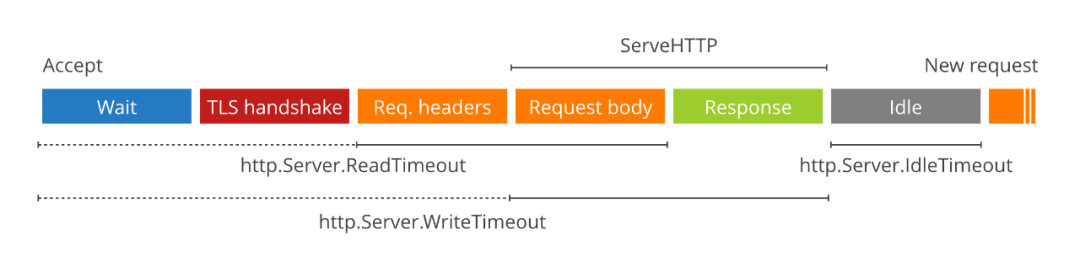
srv := &http.Server{
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 120 * time.Second,
TLSConfig: tlsConfig,
Handler: serveMux,
}
log.Println(srv.ListenAndServeTLS("", ""))
數(shù)據(jù)庫相關
做為 CRUD Boy,經(jīng)常和 DB 打交道,讓我們來看下常見的超時設置與坑。
Redis 服務端要注意兩個參數(shù):timeout 和 tcp-keepalive。
其中 timeout 用于關閉 idle client conn,默認是 0 不關閉,為了減少服務端 fd 占用,建議設置一個合理的值。
tcp-keepalive 在很早的 redis 版本是不開啟的,這樣經(jīng)常會遇到因為網(wǎng)格抖動等原因,socket conn 一直存在,但實際上 client 早已經(jīng)不存在的情況。
Redis Client 實現(xiàn)有一個重大問題,對于集群環(huán)境下,有些請求會做 Redirect 跳轉(zhuǎn),默認是 16 次,如果 tcp read timeout 設置了 100ms,那總時間很可能超過了 1s。
這就是一直強調(diào)的問題,tcp timeout 設置不代表實際的調(diào)用時間,因為業(yè)務層會多次調(diào)用 socket 讀寫。最好外面包一層 context 或是 circuit breaker。
MySQL 也同樣服務端可以設置 MAX_EXECUTION_TIME 來控制 sql 執(zhí)行時間。不同發(fā)行版本還不一樣,有的只支持 select,有的同時支持 dml ddl...
其它
分享轉(zhuǎn)發(fā)哦~參考資料
[1]
Dapper, a Large-Scale Distributed Systems Tracing Infrastructure: https://research.google/pubs/pub36356/
[2]zipkin: https://zipkin.io/
[3]opentelemetry: https://opentelemetry.io/docs/concepts/distributions/
[4]So you want to expose Go on the Internet: https://blog.cloudflare.com/exposing-go-on-the-internet/
最后,歡迎關注我的公眾號~