
【Python實戰(zhàn)案例】讀取Excel批量替換Word局部信息
一個word辦公自動化的私活
最近接到一個單子,需要我將word文檔中的關(guān)鍵信息(紅色字體內(nèi)容)替換為一個excel文檔中的一行數(shù)據(jù),并能夠批量化的將excel文檔中的每個數(shù)據(jù)依據(jù)這個word模板生成對應(yīng)數(shù)量的word文件。
做了一下午,總算拿到傭金,還是挺開心的
接下來看看,先看下數(shù)據(jù)源和要替換的word模板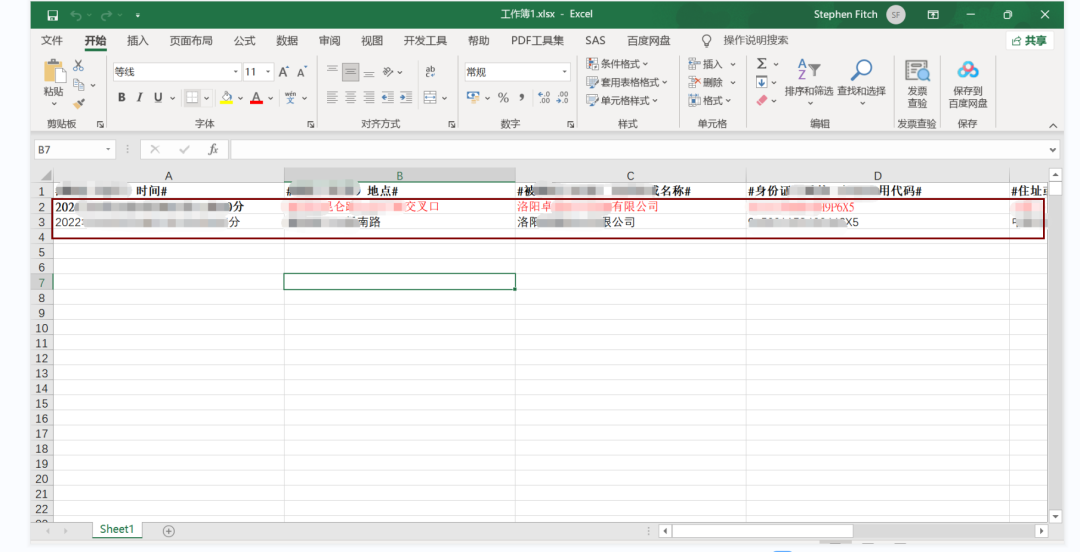 (數(shù)據(jù)源)
(數(shù)據(jù)源)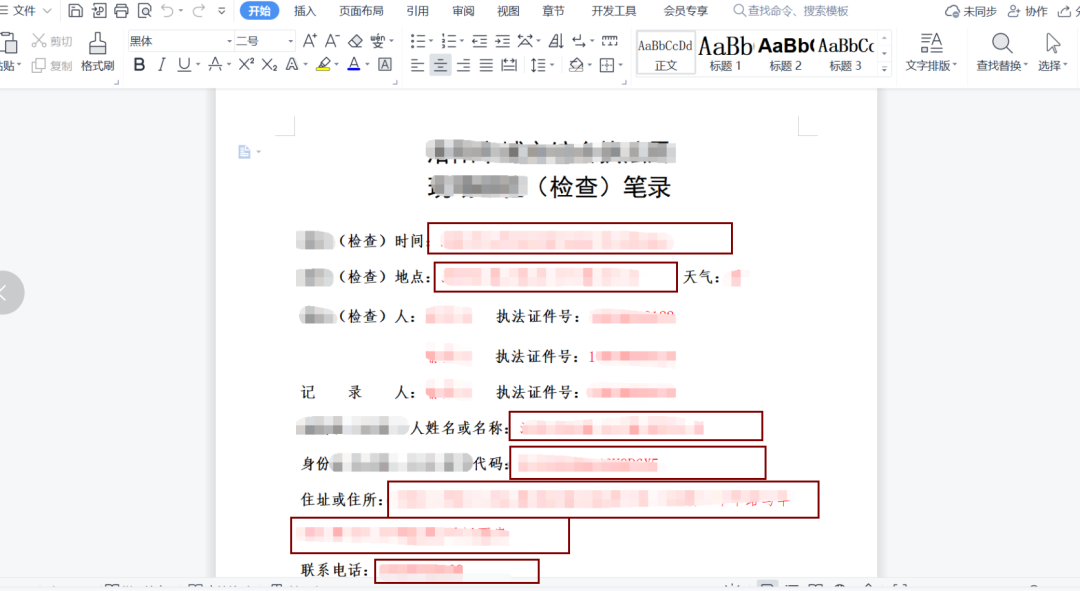 (word模板)
(word模板)
主要原理
這里主要的原理是我使用了專門處理word的python擴(kuò)展包python-docx,然后提取段落,對段落中執(zhí)行文檔的編號進(jìn)行遍歷,由于格式是固定的,那么只要對每個段落對象進(jìn)行計數(shù),然后按照對應(yīng)計數(shù)來進(jìn)行數(shù)組定位,并把從excel中讀取到的字段值進(jìn)行替換就可以達(dá)到批量生成模板數(shù)據(jù)的要求了。
看下代碼:
from?docx?import?Document
import?docx
import?pandas?as?pd
df?=?pd.read_excel(r'工作簿1.xlsx')
#讀取excel數(shù)據(jù)
for?i?in?df.index:
????#?實例化一個文件對象
????doc?=?Document(r'1XXXXXXXXXXX模版.docx')
????tm?=?df.loc[i,"#XXXXXX??時間#"]
????plc?=?df.loc[i,"#XXXXX?地點#"]
????chp?=?df.loc[i,'#被XXXXX?姓名或名稱#']
????ids?=?df.loc[i,'#XXXX?社會XXXX碼#']
????adr?=?df.loc[i,'#住XXXXX所#']
????ph?=?df.loc[i,'#聯(lián)XXXX話#']
????cp?=?df.loc[i,'#現(xiàn)XXXXX人#']
????idp?=?df.loc[i,'#身XXXX號#']
????#?定位信息節(jié)點:
????doc_paras?=?doc.paragraphs
????count?=?0
????for?para?in?doc_paras[3:14]:
????????print("段落"+str(count))
????????if?count?==?9:
????????????col1?=?para.text.split(":")
????????????col1[2]?=?idp
????????????col1[1]?=?col1[1].split("??")
????????????col1[1][0]?=?cp
????????????col2?=?col1[0]+":"+col1[1][0]+"??"+col1[1][1]+":"+str(col1[2])
????????????para.text?=?col2
????????elif?count==0:
????????????col?=?para.text.split(":")
????????????col[1]?=?tm
????????????res?=?":".join(col)
????????????para.text?=?res
????????????print(para.text)
????????elif?count==1:
????????????col1?=?para.text.split("???")
????????????col2?=?col1[0].split(":")
????????????col2[1]?=?plc
????????????col3?=?col2[0]+":"+col2[1]+"???"+col1[1]
????????????para.text?=?col3
????????????print(para.text)
????????elif?count==5:
????????????col1?=?para.text.split(":")
????????????col1[1]?=?chp
????????????col2?=?col1[0]+":"+col1[1]
????????????para.text?=?col2
????????????print(para.text)
????????elif?count==6:
????????????col1?=?para.text.split(":")
????????????col1[1]?=?ids
????????????col2?=?col1[0]+":"+col1[1]
????????????para.text?=?col2
????????????print(para.text)
????????elif?count==7:
????????????col1?=?para.text.split(":")
????????????col1[1]?=?adr
????????????col2?=?col1[0]+":"+col1[1]
????????????para.text?=?col2
????????????print(para.text)
????????elif?count==8:
????????????col1?=?para.text.split(":")
????????????col1[1]?=?ph
????????????col2?=?col1[0]+":"+str(col1[1])
????????????para.text?=?col2
????????????print(para.text)
????????count+=1
????doc.save(rf'new{i}.doc')
????????
最終實現(xiàn)了所有對應(yīng)數(shù)據(jù)的替換,python在處理word方面的辦公自動化比起excel來,一點也不差,而且可以和excel進(jìn)行結(jié)合,產(chǎn)生更多不可思議的高效功能。

圖中紅色框就是被替換的程序,這段代碼將來會用在他們的很多部門,預(yù)計能夠批量產(chǎn)生幾百上千個類似表格,懸賞人對我感謝之情溢于言表。
?
? ?最后,推薦螞蟻老師的《零基礎(chǔ)入門Python到辦公自動化》課程
? ?
評論
圖片
表情