
綜述 | 語(yǔ)義分割經(jīng)典網(wǎng)絡(luò)及輕量化模型盤點(diǎn)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

基于圖像的語(yǔ)義分割又被理解為密集的像素預(yù)測(cè),即將每個(gè)像素進(jìn)行分類,這不僅僅對(duì)于算法是一個(gè)考驗(yàn),而且對(duì)于硬件的計(jì)算性能也有很高的要求。因此,本文從兩方面著手考慮,一方面是基于語(yǔ)義分割經(jīng)典網(wǎng)絡(luò)的介紹,向大家展示語(yǔ)義分割方向上的,經(jīng)典的網(wǎng)絡(luò)模型。另一方面,從計(jì)算的性能入手,向大家介紹一下語(yǔ)義分割方向的輕量化模型。在文章的最后,本文給出了一些語(yǔ)義分割方向上值得關(guān)注的博主還有網(wǎng)站。由于作者文筆有限,文章中難免會(huì)有錯(cuò)誤出現(xiàn),還望各位讀者及時(shí)指正,共同學(xué)習(xí)進(jìn)步。
經(jīng)典語(yǔ)義分割模型
全卷積神經(jīng)網(wǎng)絡(luò)(FCN)
FCN神經(jīng)網(wǎng)絡(luò)作為深度學(xué)習(xí)中,語(yǔ)義分割網(wǎng)絡(luò)的經(jīng)典之作,是必須要理解和掌握的一個(gè)網(wǎng)絡(luò)結(jié)構(gòu),它借鑒了傳統(tǒng)的分類網(wǎng)絡(luò)結(jié)構(gòu),而又區(qū)別于傳統(tǒng)的分類網(wǎng)絡(luò),將傳統(tǒng)分類網(wǎng)絡(luò)的全連接層轉(zhuǎn)化為卷積層。然后通過(guò)反卷積(deconvolution)進(jìn)行上采樣,逐步恢復(fù)圖像的細(xì)節(jié)信息并擴(kuò)大特征圖的尺寸。在恢復(fù)圖像的細(xì)節(jié)信息過(guò)程中,F(xiàn)CN一方面通過(guò)可以學(xué)習(xí)的反卷積來(lái)實(shí)現(xiàn),另一方面,采用了跳躍連接(skip-connection)的方式,將下采樣過(guò)程中得到的特征信息與上采樣過(guò)程中對(duì)應(yīng)的特征圖相融合。

雖然從目前的研究來(lái)看,F(xiàn)CN存在著諸如語(yǔ)義信息丟失,缺乏對(duì)于像素之間關(guān)聯(lián)性的研究,但是FCN引入了編碼-解碼的結(jié)構(gòu),為深度學(xué)習(xí)在語(yǔ)義分割方向上的應(yīng)用打開(kāi)了一扇大門,也為后續(xù)的研究做出了許多借鑒之處。
FCN-8s在VOC-2012上的準(zhǔn)確率如下圖所示:

論文地址:https://arxiv.org/abs/1411.4038
代碼實(shí)現(xiàn)地址:https://github.com/MarvinTeichmann/tensorflow-fcn[Tensorflow]
SegNet
SegNet采用了FCN的編碼-解碼的架構(gòu),但是與FCN不同的是,SegNet沒(méi)有使用跳躍連接結(jié)構(gòu),并且在上采樣的過(guò)程中,不是使用反卷積,而是使用了unpooling的操作。
SegNet相較于FCN有了兩點(diǎn)的改進(jìn)。第一,由于unpooling不需要進(jìn)行學(xué)習(xí),所以相比于FCN,SegNet的參數(shù)數(shù)量明顯下降,從而降低了計(jì)算量。第二,由于SegNet在解碼器中使用那些存儲(chǔ)的索引來(lái)對(duì)相應(yīng)特征圖進(jìn)行去池化操作。從而保證了高頻信息的完整性,但是對(duì)于較低分辨率的特征圖進(jìn)行unpooling時(shí),同樣會(huì)忽略像素近鄰之間的信息。

SegNet在CamVid數(shù)據(jù)集上的測(cè)試結(jié)果如下圖所示:

論文地址:https://arxiv.org/abs/1511.00561
代碼實(shí)現(xiàn)地址:https://github.com/tkuanlun350/Tensorflow-SegNet[Tensorflow]
Deeplab系列
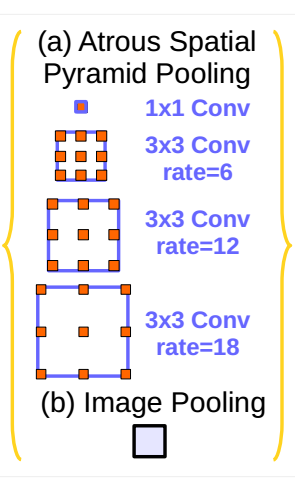
deeplab系列是由Google團(tuán)隊(duì)設(shè)計(jì)的一系列的語(yǔ)義分割網(wǎng)絡(luò)模型。是一個(gè)不斷進(jìn)化改進(jìn)的過(guò)程,通過(guò)閱讀deeplab系列的論文,理解作者一步步的改進(jìn)思路,無(wú)論對(duì)于文章的理解,還是設(shè)計(jì)我們自己的網(wǎng)絡(luò)結(jié)構(gòu),都有很大的幫助。deeplabv1的設(shè)計(jì)亮點(diǎn)在于,采用了空洞卷積和CRF的處理。利用空洞卷積在不增加參數(shù)的情況下擴(kuò)大了感受野的范圍。而CRF的后期處理可以更好的提升語(yǔ)義分割的準(zhǔn)確率。deeplabv2在v1的基礎(chǔ)之上增加了ASPP(空洞空間金字塔池化)模塊。如下圖所示:

通過(guò)不同尺度的空洞率來(lái)提取不同尺寸的特征,更好的融合不同的特征,達(dá)到更好的分割效果。deeplabv3的創(chuàng)新點(diǎn)有兩個(gè),一個(gè)是改進(jìn)了ASPP模塊,第二個(gè)是參考了HDC的設(shè)計(jì)思想,也就是橫縱兩種結(jié)構(gòu)。對(duì)于改進(jìn)的ASPP模塊,如下圖所示。
對(duì)比于v2的ASPP模塊,可以發(fā)現(xiàn)V3的ASPP模塊增加了一個(gè)1x1的卷積和全局池化層。對(duì)于ASPP模塊的構(gòu)建,作者采用了“縱向”的設(shè)計(jì)方式,如下圖所示:

與”縱向“向?qū)?yīng)的是”橫向“的設(shè)計(jì),如下圖所示:

作者將conv4的結(jié)構(gòu)連續(xù)復(fù)制了3次,后面的每一個(gè)block塊都有一個(gè)基礎(chǔ)的空洞率,而在每一個(gè)block塊里面,作者又參考了HDC的思想,將卷積層的空洞率設(shè)計(jì)為[1,2,1]的形式。這里的[1,2,1]設(shè)計(jì)模式是作者經(jīng)過(guò)試驗(yàn)得到的最好設(shè)計(jì)結(jié)構(gòu)。deeplabv3+的設(shè)計(jì)相較于v3有兩點(diǎn)改進(jìn),第一點(diǎn)是解碼的方式,第二點(diǎn)是采用改進(jìn)后的xception網(wǎng)絡(luò)作為backbone。下圖是deeplabv3+原文中對(duì)于v3和v3+以及編碼-解碼結(jié)構(gòu)的模型對(duì)比。
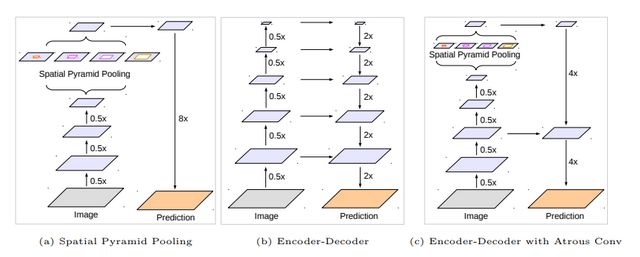
deeplabv3+文章中使用了兩種backbone,分別是Resnet101和改進(jìn)后的xception網(wǎng)絡(luò)。通過(guò)文章中的實(shí)驗(yàn)對(duì)比,以改進(jìn)后的xception作為backbone效果要優(yōu)于Resnet101。
deeplab的官方也發(fā)布過(guò)一個(gè)ppt,講述的是deeplab v1,v2和v3的主要區(qū)別,大家可以從ppt中獲取到更多的信息。下載鏈接:http://web.eng.tau.ac.il/deep_learn/wp-content/uploads/2017/12/Rethinking-Atrous-Convolution-for-Semantic-Image-Segmentation-1.pdf。
deeplabv1論文地址:https://arxiv.org/abs/1412.7062
deeplabv2論文地址:https://arxiv.org/abs/1606.00915
deeplabv3論文地址:https://arxiv.org/abs/1706.05587
deeplabv3+論文地址:https://arxiv.org/abs/1802.02611
deeplabv3 代碼實(shí)現(xiàn)地址:https://github.com/rishizek/tensorflow-deeplab-v3[Tensorflow]
deeplabv3+ 代碼實(shí)現(xiàn)地址:https://github.com/rishizek/tensorflow-deeplab-v3-plus[Tensorflow]
RefineNet
RefineNet提出了一種多路徑的提煉網(wǎng)絡(luò),通過(guò)使用遠(yuǎn)距離的殘差連接,盡可能多的利用下采樣過(guò)程中的信息。從而得到高分辨率的預(yù)測(cè)圖。文章通過(guò)細(xì)心的設(shè)計(jì)RefineNet模塊,通過(guò)鏈?zhǔn)綒埐畛鼗–RP)來(lái)融合上下文信息,將粗糙的深層特征和細(xì)節(jié)特征進(jìn)行融合。實(shí)現(xiàn)了端到端的訓(xùn)練。文章針對(duì)于目前語(yǔ)義分割存在的問(wèn)題進(jìn)行改進(jìn)。目前的分割算法采用降采樣使得很多的細(xì)節(jié)信息丟失,這樣得到的結(jié)果較為粗糙。而針對(duì)于這種情況,文章的Introduction部分介紹了目前的主要改進(jìn)方式。
利用反卷積來(lái)進(jìn)行上采樣,產(chǎn)生高分辨率的特征圖。但是反卷積不能恢復(fù)低層的特征,因?yàn)檫@部分信息在下采樣的過(guò)程中已經(jīng)丟失,已經(jīng)不可能找回(這里我想添加一點(diǎn)自己的理解,例如32倍的下采樣,那么理論上小于32x32像素的目標(biāo)將會(huì)丟失,而丟失的目標(biāo)無(wú)論怎樣反卷積都不會(huì)被找回,因?yàn)橄虏蓸拥奶卣鲌D中沒(méi)有包含該目標(biāo)的任何信息)。
利用空洞卷積。利用空洞卷積來(lái)產(chǎn)生較高分辨率的特征圖,這樣的操作不會(huì)帶來(lái)額外的參數(shù),但是由于特征圖的分辨率增加,會(huì)造成巨大的計(jì)算和存儲(chǔ)資源的消耗,因此deeplab輸出的尺寸只能是輸入尺寸的1/8甚至更小。而且,由于空洞卷積只是對(duì)于特征圖的粗略采樣,還是會(huì)存在潛在的重要細(xì)節(jié)信息的丟失。
利用中間層的信息。例如FCN網(wǎng)絡(luò)的跳躍連接。但是還是缺少較強(qiáng)的空間信息。文章作者認(rèn)為各層的信息對(duì)于分割都是有用的。高層特征有助于類別識(shí)別,低層特征有助于生成精細(xì)的邊界。如何有效的利用各個(gè)層的信息非常的重要。
作者圍繞如何有效的利用各個(gè)層的信息,設(shè)計(jì)了RefineNet網(wǎng)絡(luò)結(jié)構(gòu),如下圖所示:

該網(wǎng)絡(luò)將不同分辨率的特征圖進(jìn)行融合,通過(guò)上圖左側(cè)的ResNet101預(yù)訓(xùn)練模型,產(chǎn)生四個(gè)分辨率的特征圖,然后將四個(gè)特征圖分別通過(guò)對(duì)應(yīng)的RefineNet block模塊進(jìn)行進(jìn)行融合。由上圖也可以看出,除了RefineNet-4模塊外,其余的RefineNet block都是有兩個(gè)輸入,用于不同尺寸特征圖的提煉融合。RefineNet block的細(xì)節(jié)圖如下所示。

主要的組成部分包括Residual convolution unit(RCU,殘差卷積單元), Multi-resolution fusion(MRF,多分辨率融合),Chained residual pooling(CRP,鏈?zhǔn)綒埐畛鼗┖妥詈蟮腛utput convolutions(輸出卷積 )。其中各個(gè)部分的作用為:
RCU:該部分用來(lái)作為一個(gè)自適應(yīng)卷積集,主要是微調(diào)ResNet的權(quán)重。
MRF:從名字可以看出,該部分是將所有的輸入特征圖的分辨率調(diào)整為最大特征圖的分辨率尺寸。
CRP:通過(guò)鏈?zhǔn)綒埐畛鼗糠郑梢杂行У牟蹲缴舷挛男畔ⅰ?/p>
輸出卷積:在最終的輸出之前,再加一個(gè)RCU。
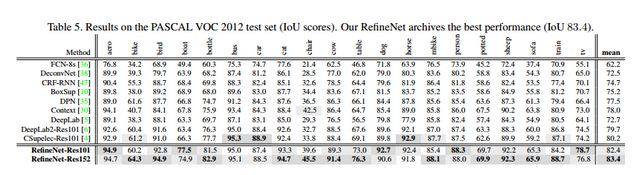
RefineNet再VOC2012數(shù)據(jù)集上的測(cè)試結(jié)果如下圖所示:
論文地址:https://arxiv.org/abs/1611.06612
代碼實(shí)現(xiàn)地址:https://github.com/eragonruan/refinenet-image-segmentation[Tensorflow]
PSPNet
PSPnet全稱為Pyramid Scene Parsing Network ,它采用的金字塔池化模塊,來(lái)融合圖像的上下文信息,注重像素之間的關(guān)聯(lián)性。如何理解像素之間的關(guān)聯(lián)性和圖像中的上下文信息呢?比如我們看到了一個(gè)物體,由于拍攝角度,光線等問(wèn)題,很難從物體本身來(lái)分別它究竟是條船還是一輛小汽車。但是我們知道船在水里,而車在路上,因此,結(jié)合物體所處的周圍環(huán)境信息,就能很好的分辨這個(gè)物體是什么了。PSPnet利用預(yù)訓(xùn)練模型提取特征后,將采用金字塔池化模塊提取圖像的上下文信息,并將上下文信息與提取的特征進(jìn)行堆疊后,經(jīng)過(guò)上采樣得到最終的輸出。而特征堆疊的過(guò)程其實(shí)就是講目標(biāo)的細(xì)節(jié)特征和全局特征融合的過(guò)程,這里的細(xì)節(jié)特征指的是淺層特征,也就是淺層網(wǎng)絡(luò)所提取到的特征,而全局特征指的是深層的特征,也就是常常說(shuō)的上下文特征。對(duì)應(yīng)的就是深層網(wǎng)絡(luò)提取的特征。

PSPNet在VOC2012上的測(cè)試結(jié)果如下圖所示:

論文地址:https://arxiv.org/abs/1612.01105
代碼實(shí)現(xiàn)地址:https://github.com/hellochick/PSPNet-tensorflow[Tensorflow]
輕量化模型
以上介紹的是近些年來(lái)的深度學(xué)習(xí)領(lǐng)域中語(yǔ)義分割方向比較經(jīng)典的文章,上述的文章注重的是分割準(zhǔn)確率的提升,但是在計(jì)算速度上并不是很出色。下面為大家介紹的是語(yǔ)義分割領(lǐng)域的輕量化模型。輕量化模型在注重計(jì)算的速度的同時(shí),也保證了分割的準(zhǔn)確率。
ENet
ENet是基于SegNet改進(jìn)的實(shí)時(shí)分割的輕量化模型,相比于SegNet,ENet的計(jì)算速度提升了18倍,計(jì)算量減少了75倍,參數(shù)量減少了79倍。并且在CityScapes和CamVid的數(shù)據(jù)集上,ENet的效果都要好于SegNet。ENet作為輕量化模型,設(shè)計(jì)的初衷就是如何最大限度的減少計(jì)算量,提升計(jì)算速度。ENet的網(wǎng)絡(luò)架構(gòu)如下圖所示。
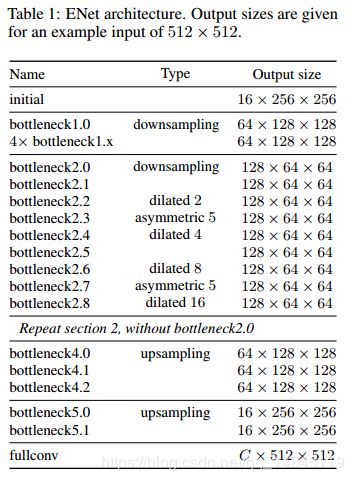
其中initial block 和bottleneck分別如下所示。
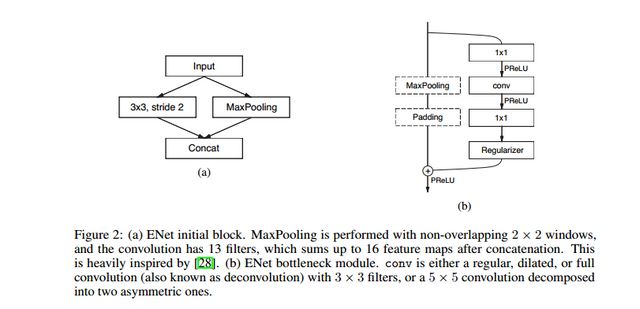
從提升網(wǎng)絡(luò)的計(jì)算速度來(lái)看,文章主要有以下幾點(diǎn)改進(jìn)。
在Initial Block中,文章將pooling操作和卷積操作并行,然后堆疊到一起,這將Initial Block的inference時(shí)間加速了10倍。
ENet的前兩個(gè)block大大的降低了輸入圖像的尺寸,而且只用了很少的特征圖。而作者這樣做的原因是考慮到視覺(jué)信息在空間上是高度冗余的,可以壓縮成更有效的表示方式。
ENet網(wǎng)絡(luò)將nxn的卷積核拆分為nx1和1xn的卷積核,從而有效的減少了參數(shù)量和計(jì)算量。
從提升網(wǎng)絡(luò)的準(zhǔn)確率來(lái)看,文章主要有以下的幾點(diǎn)改進(jìn)。
ENet去除了初始幾層的大部分的Relu激活函數(shù),實(shí)驗(yàn)發(fā)現(xiàn)可以提高網(wǎng)絡(luò)的準(zhǔn)確性。
在下采樣的過(guò)程中,ResNet的block會(huì)采用stride為2的1x1卷積,這會(huì)造成75%的輸入信息丟失,ENet采用處理方法是將卷積核改為2x2大小,使得卷積核能覆蓋整個(gè)輸入,從而有效的改善了信息的流動(dòng)和準(zhǔn)確率。
文章使用了空洞卷積,實(shí)驗(yàn)證明在Cityscapes數(shù)據(jù)集上Iou有了4%左右的提升。
ENet在卷積層后面使用Spatial Dropout,可以獲得比stochastic depth和L2 weight decay更好的效果。
論文地址:https://arxiv.org/abs/1606.02147
代碼地址:https://github.com/kwotsin/TensorFlow-ENet[Tensorflow]
ICNet
ICNet是針對(duì)于高分辨率圖片的實(shí)時(shí)分割模型,網(wǎng)絡(luò)設(shè)計(jì)的目標(biāo)是能夠快速分割,同時(shí)保證一個(gè)合適的準(zhǔn)確率。ICNet采用了多尺度的圖像輸入,首先讓低分辨率的圖像經(jīng)過(guò)一個(gè)Heavy CNN,得到較為粗糙的預(yù)測(cè)特征圖,然后提出了級(jí)聯(lián)特征融合單元和級(jí)聯(lián)標(biāo)簽指導(dǎo)的策略,來(lái)引入中、高分辨率的特征圖,逐步提高精度。整個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)如下圖所示。
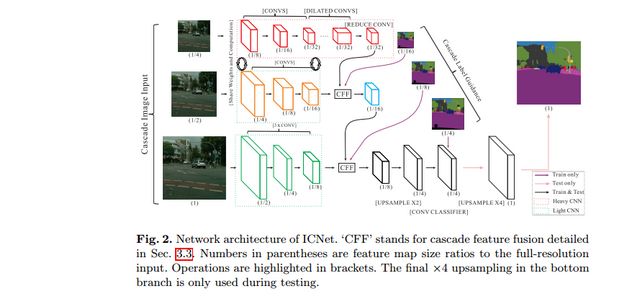
該網(wǎng)絡(luò)結(jié)構(gòu)十分有趣,值得學(xué)習(xí),對(duì)于較低分辨率的輸入圖像,ICNet采用Heavy CNN來(lái)提取網(wǎng)絡(luò)的特征,這里的Heavy CNN可以看作是計(jì)算量較大的編碼器。而針對(duì)于中、高分辨率的輸入圖像而言,ICNet采用的網(wǎng)絡(luò)層數(shù)以此減少,這樣,雖然較低分辨率的輸入圖像經(jīng)過(guò)了最深層的網(wǎng)絡(luò)結(jié)構(gòu),但是由于其分辨率較小,因此計(jì)算量也受到了限制。而較高分辨率的輸入圖像,則是采用較淺的網(wǎng)絡(luò)結(jié)構(gòu),計(jì)算量同樣得到降低。這樣,就利用了低分辨率圖片的高效處理和高分辨率圖片的高推斷質(zhì)量。而這也恰恰是ICNet和其他cascade structures網(wǎng)絡(luò)結(jié)構(gòu)不同的地方,雖然也有其他的網(wǎng)絡(luò)從單一尺度或者多尺度的輸入融合不同層的特征,但是其他的網(wǎng)絡(luò)都是采取的是所有的輸入經(jīng)過(guò)相同的網(wǎng)絡(luò),這就會(huì)造成計(jì)算量的加大,從而使得計(jì)算的速度大大降低。
上圖中的CFF(cascade feature fusion unit) 就是級(jí)聯(lián)特征融合單元。如下圖所示。

CFF模塊用來(lái)融合不同分辨率的輸入,與反卷積相比,CFF使用二線性插值上采樣+空洞卷積的組合只需要更小的卷積核來(lái)獲取相同大小的感受野,而且空洞卷積可以整合相鄰像素的特征信息,而直接上采樣使得每個(gè)元素變得相對(duì)孤立,缺少了像素與周圍像素之間的關(guān)聯(lián)。
ICNet在Cityscapes數(shù)據(jù)集上的表現(xiàn)如下圖所示。
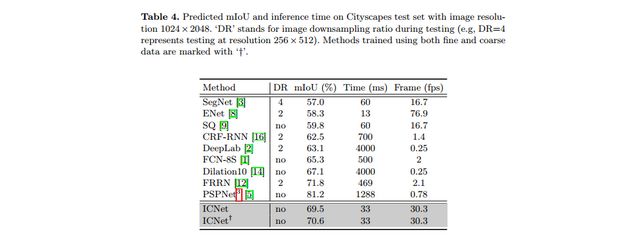
論文地址:https://arxiv.org/abs/1704.08545
代碼實(shí)現(xiàn)地址:https://github.com/hellochick/ICNet-tensorflow[Tensorflow]
CGNet
CGNet網(wǎng)絡(luò)的核心架構(gòu)是文章提出的CG模塊,也就是上下文指導(dǎo)模塊。CG模塊能夠?qū)W習(xí)局部特征和周圍環(huán)境上下文的聯(lián)合特征,并通過(guò)引入全局上下文特征進(jìn)一步改善聯(lián)合特征。文中指出CG模塊的四個(gè)優(yōu)勢(shì),分別是:
CG模塊能夠?qū)W習(xí)局部特征和周圍環(huán)境上下文的聯(lián)合特征。
CG模塊利用全局上下文來(lái)提高聯(lián)合特征。其中,全局上下文用來(lái)逐通道的對(duì)于特征圖的權(quán)重進(jìn)行調(diào)整,以此來(lái)突出有用的部分,而壓制沒(méi)有用的部分(這里可以通過(guò)閱讀SENet的文章,來(lái)進(jìn)一步的理解)。
CG模塊被用在了CGnet的所有階段,因此CGNet可以從語(yǔ)義層(深層網(wǎng)絡(luò))或者空間層(淺層網(wǎng)絡(luò))來(lái)獲取上下文信息,區(qū)別于PSPNet、DFN等網(wǎng)絡(luò),這些網(wǎng)絡(luò)這是在編碼之后獲取上下文特征。
CGNet只應(yīng)用了三個(gè)下采樣,因此能夠更好的保留空間信息。
CGNet的網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。
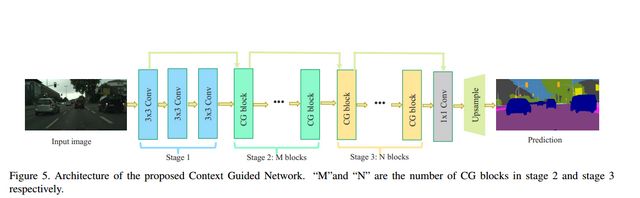
CGNet的網(wǎng)絡(luò)架構(gòu)遵循了“深而淺”的原則,整個(gè)網(wǎng)絡(luò)只有51層。并且CG模塊采用的是逐通道卷積(channel-wise convolutions)的方式。從而降低了計(jì)算的成本。
CG模塊的結(jié)構(gòu)如下圖所示。
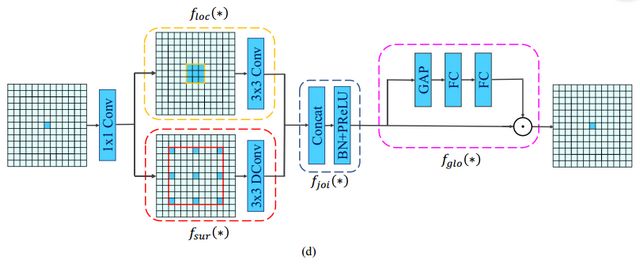
CG模塊主要包含四個(gè)部分,如下所示。
局部特征提取器(local feature extractor) :一個(gè)標(biāo)準(zhǔn)的3x3的卷積層;
:一個(gè)標(biāo)準(zhǔn)的3x3的卷積層;
周圍上下文特征提取器(surrounding context extractor) :一個(gè)3x3的空洞卷積層;聯(lián)合特征提取器(joint feature extractor)
:一個(gè)3x3的空洞卷積層;聯(lián)合特征提取器(joint feature extractor) :將局部特征和周圍上下文特征進(jìn)行拼接后,后面加上BN層和PReLU激活函數(shù)層;全局特征提取器(global context extractor)
:將局部特征和周圍上下文特征進(jìn)行拼接后,后面加上BN層和PReLU激活函數(shù)層;全局特征提取器(global context extractor) :全局池化層后面跟兩個(gè)全連接層抽取特征,得到一個(gè)權(quán)重向量,以此向量來(lái)指導(dǎo)聯(lián)合特征的融合。
:全局池化層后面跟兩個(gè)全連接層抽取特征,得到一個(gè)權(quán)重向量,以此向量來(lái)指導(dǎo)聯(lián)合特征的融合。
CG模塊還采用了殘差學(xué)習(xí)來(lái)學(xué)習(xí)高復(fù)雜度的特征并在訓(xùn)練期間改善梯度反向傳播。文中提出了兩種方式,分別為局部殘差學(xué)習(xí)(LRL)和全局殘差學(xué)習(xí)(GRL)。LRL將輸入和聯(lián)合特征提取器進(jìn)行連接,GRL則是將輸入和全局特征提取器進(jìn)行連接。從直觀上來(lái)說(shuō),GRL比LRL更能促進(jìn)網(wǎng)絡(luò)中的信息傳遞,而文章后面的實(shí)驗(yàn)也證明,GRL更能提升分割精度。
總結(jié)
以上總結(jié)是基于深度學(xué)習(xí)中語(yǔ)義分割領(lǐng)域的經(jīng)典算法和輕量化模型。隨著技術(shù)的發(fā)展和硬件條件的不斷進(jìn)步,基于像素級(jí)別的分割才是圖像分類的主流方向。從FCN至今的短短幾年,語(yǔ)義分割技術(shù)已經(jīng)取得了很大的發(fā)展,越來(lái)越多的新穎的技術(shù)不斷的被提出。小編總結(jié)了最近幾年的文章,總結(jié)了一下未來(lái)的語(yǔ)義分割發(fā)展方向,僅供大家參考。
引入自注意模型。自注意力模型最早的應(yīng)用是在自然語(yǔ)言處理方面。后來(lái)慢慢引入到計(jì)算機(jī)視覺(jué)領(lǐng)域,例如在圖像識(shí)別領(lǐng)域,注意力模型可以讓深度學(xué)習(xí)模型更加關(guān)注某一些局部的關(guān)鍵信息。在CGNet中,同樣也引入了注意力模型,來(lái)調(diào)整特征圖的權(quán)重,從而更加有效的區(qū)分和利用各個(gè)特征。
無(wú)監(jiān)督/弱監(jiān)督的語(yǔ)義分割。由于語(yǔ)義分割是基于像素級(jí)別的分類,而傳統(tǒng)的有監(jiān)督的語(yǔ)義分割需要大量的訓(xùn)練數(shù)據(jù)集,這就需要花費(fèi)大量的人力物力去制作標(biāo)簽數(shù)據(jù)集,而且由于針對(duì)的場(chǎng)景不同,采集到的數(shù)據(jù)集也不一樣,這就會(huì)造成大量的繁重的數(shù)據(jù)集標(biāo)簽制作。因此,基于弱監(jiān)督的語(yǔ)義分割也自然成為了研究的熱門趨勢(shì)。近年來(lái),基于弱監(jiān)督的語(yǔ)義分割文章也越來(lái)越多。
輕量化網(wǎng)絡(luò)。在現(xiàn)有的計(jì)算條件下,雖然準(zhǔn)確率已經(jīng)能夠達(dá)到很好的表現(xiàn),但是在計(jì)算速度上卻不盡如人意,語(yǔ)義分割技術(shù)的落地實(shí)現(xiàn),需要提高分割模型的計(jì)算速度。一方面,可以采用模型壓縮、模型加速的方式來(lái)解決。另一方面,也可以從模型本身入手,設(shè)計(jì)輕量化模型,在盡可能不損失準(zhǔn)確率的情況下,提高模型的計(jì)算速度。
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~