
干貨,主流大數(shù)據(jù)技術(shù)總結(jié)

作者:justcodeit
數(shù)據(jù)量不斷增加,企業(yè)需要靈活快速地處理這些數(shù)據(jù)。 處理器主頻和散熱遇到瓶頸,多核處理器成為主流,并行化計算應(yīng)用不斷增加。 開源軟件的成功使得大數(shù)據(jù)技術(shù)得以興起。

批量處理:單位是上百MB的數(shù)據(jù)塊而非一條條數(shù)據(jù),這樣在數(shù)據(jù)讀寫時能夠整體操作,減少IO尋址的時間消耗。 最終線性一致性:大數(shù)據(jù)技術(shù)很多都放棄線性一致性,這主要是跨行/文檔(關(guān)系型模型叫行,文檔型模型叫文檔)時非原子操作,在一行/一個文檔內(nèi)還是會做到原子的。為了讀寫性能而允許跨行/文檔出現(xiàn)讀寫延遲。 增加數(shù)據(jù)冗余:規(guī)范化的數(shù)據(jù)能夠減少數(shù)據(jù)量,但在使用時需要關(guān)聯(lián)才能獲得完整數(shù)據(jù),而在大數(shù)據(jù)下進行多次關(guān)聯(lián)的操作是十分耗時的。為此,一些大數(shù)據(jù)應(yīng)用通過合并寬表減少關(guān)聯(lián)來提高性能。 列式存儲:讀取數(shù)據(jù)時只讀取業(yè)務(wù)所關(guān)心的列而不需要把整行數(shù)據(jù)都取出再做進行截取,而且列式的壓縮率更高,因為一列里一般都是同類的數(shù)據(jù)。
副本:大數(shù)據(jù)存儲通常都會有副本設(shè)置,這樣即便其中一份出現(xiàn)丟失,數(shù)據(jù)也能從副本找到。 高可用:大數(shù)據(jù)應(yīng)用通常都會考慮高可用,即某個節(jié)點掛了,會有其他的節(jié)點來繼續(xù)它的工作。
架構(gòu)原理
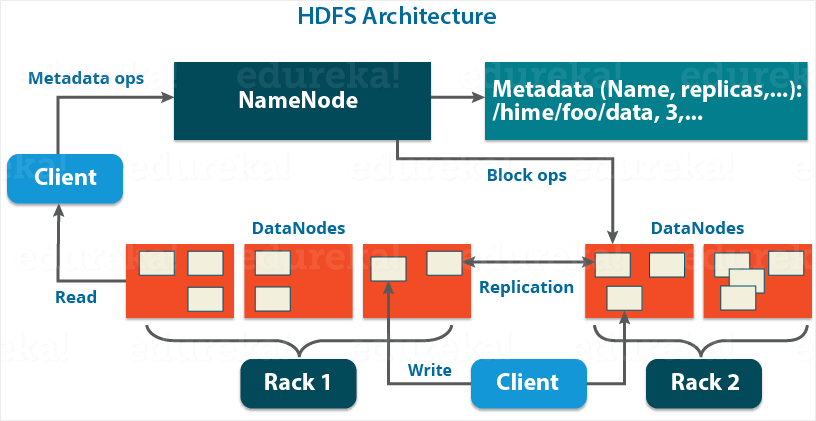
NameNode:作為master,管理元數(shù)據(jù),包括文件名、副本數(shù)、數(shù)據(jù)塊存儲的位置,響應(yīng)client的請求,接收workers的heartbeating和blockreport。 DataNode:管理數(shù)據(jù)(data block,存儲在磁盤,包括數(shù)據(jù)本身和元數(shù)據(jù))和處理master、client端的請求。定期向namenode發(fā)送它們所擁有的塊的列表。 secondary namenode:備用master Block:默認128MB,但小于一個block的文件只會占用相應(yīng)大小的磁盤空間。設(shè)置100+MB是為了盡量減少尋址時間占整個數(shù)據(jù)讀取時間的比例,但如果block過大,又不適合數(shù)據(jù)的分散存儲或計算。將數(shù)據(jù)抽象成block,還有其他好處,比如分離元數(shù)據(jù)和數(shù)據(jù)的存儲、存儲管理(block大小固定方便計算)、容錯等。
讀寫流程
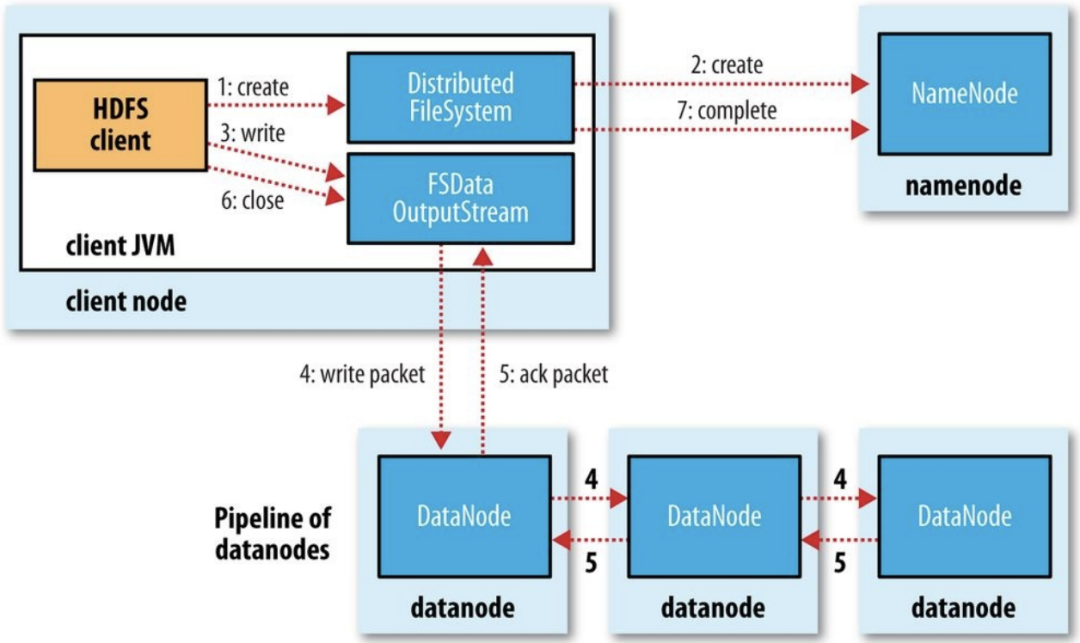
寫入:client端調(diào)用filesystem的create方法,后者通過RPC調(diào)用NN的create方法,在其namespace中創(chuàng)建新的文件。NN會檢查該文件是否存在、client的權(quán)限等。成功時返回FSDataOutputStream對象。client對該對象調(diào)用write方法,這個對象會選出合適存儲數(shù)據(jù)副本的一組datanode,并以此請求DN分配新的block。這組DN會建立一個管線,例如從client node到最近的DN_1,DN_1傳遞自己接收的數(shù)據(jù)包給DN_2。DFSOutputStream自己還有一個確認隊列。當所有的DN確認寫入完成后,client關(guān)閉輸出流,然后告訴NN寫入完成。
索引
| 哈希 | SSTables/LSM樹 | BTree/B+Tree | |
磁盤:一個個獨立文件,里面包含一個個數(shù)據(jù)塊。 寫入:內(nèi)存維護一個有序集合,數(shù)據(jù)大小達到一定閾值寫入磁盤。后臺會按照特定策略合并segment。 讀取:先查詢內(nèi)存,然后磁盤中的最新segment,然后第二新,以此類推。 | |||
簡介
特點
適合: 數(shù)據(jù)量大,單表至少超千萬。對稀疏數(shù)據(jù)尤其適用,因為文檔型數(shù)據(jù)庫的 null 就相當于整個字段沒有,是不需要占用空間的。 高并發(fā)寫入,正如上面 LSM 樹所說。 讀取近期小范圍數(shù)據(jù),效率較高,大范圍需要計算引擎支持。 數(shù)據(jù)多版本 不適合: 小數(shù)據(jù) 復(fù)雜數(shù)據(jù)分析,比如關(guān)聯(lián)、聚合等,僅支持過濾 不支持全局跨行事務(wù),僅支持單行事務(wù)
場景
對象存儲:新聞、網(wǎng)頁、圖片 時序數(shù)據(jù):HBase之上有OpenTSDB模塊,可以滿足時序類場景的需求 推薦畫像:特別是用戶的畫像,是一個比較大的稀疏矩陣,螞蟻的風控就是構(gòu)建在HBase之上 消息/訂單等歷史數(shù)據(jù):在電信領(lǐng)域、銀行領(lǐng)域,不少的訂單查詢底層的存儲,另外不少通信、消息同步的應(yīng)用構(gòu)建在HBase之上 Feeds流:典型的應(yīng)用就是xx朋友圈類似的應(yīng)用
架構(gòu)原理

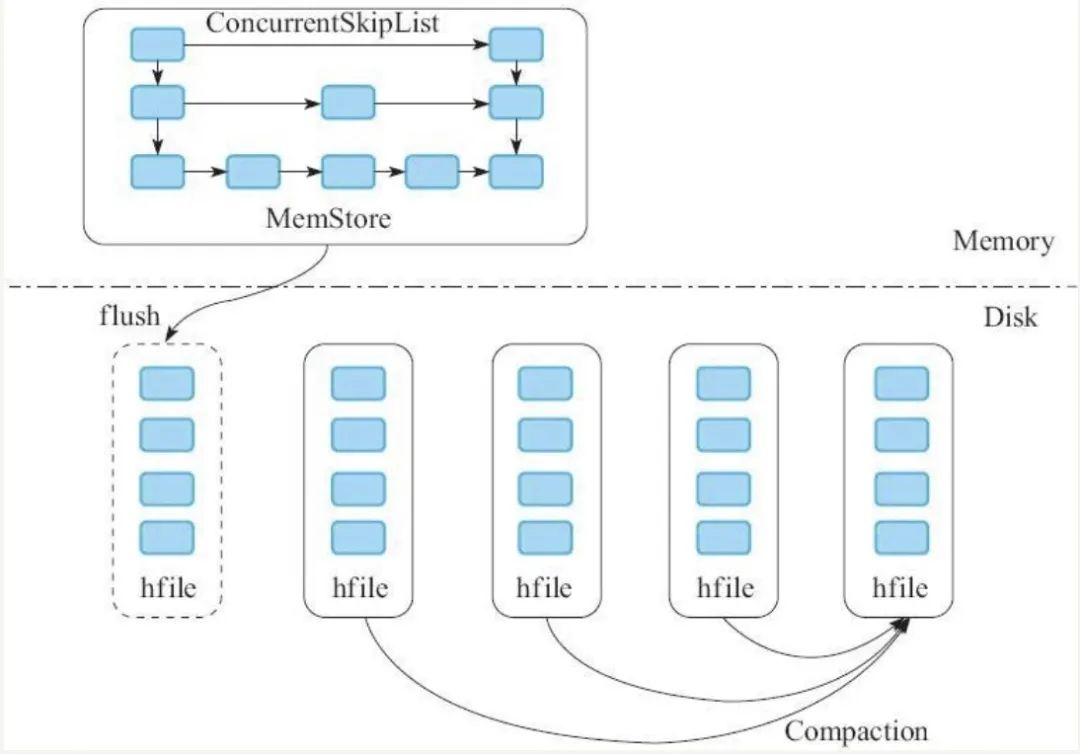
Client:發(fā)送DML、DDL請求,即數(shù)據(jù)的增刪改查和表定義等操作。 ZooKeeper(類似微服務(wù)中的注冊中心) 實現(xiàn)Master的高可用:當active master宕機,會通過選舉機制選取出新master。 管理系統(tǒng)元數(shù)據(jù):比如正常工作的RegionServer列表。 輔助RS的宕處理:發(fā)現(xiàn)宕機,通知master處理。 分布式鎖:方式多個client對同一張表進行表結(jié)構(gòu)修改而產(chǎn)生沖突。 Master 處理 client 的 DDL 請求 RegionServer 數(shù)據(jù)的負載均衡、宕機恢復(fù)等 清理過期日志 RegionServer:處理 client 和 Master 的請求,由 WAL、BlockCache 以及多個 Region 構(gòu)成。 Store:一個Store存儲一個列簇,即一組列。 MemStore和HFile:寫緩存,閾值為128M,達到閾值會flush成HFile文件。后臺有程序?qū)@些HFile進行合并。 HLog(WAL):提高數(shù)據(jù)可靠性。寫入數(shù)據(jù)時先按順序?qū)懭際Log,然后異步刷新落盤。這樣即便 MemoStore 的數(shù)據(jù)丟失,也能通過HLog恢復(fù)。而HBase數(shù)據(jù)的主從復(fù)制也是通過HLog回放實現(xiàn)的。 BlockCache Region:數(shù)據(jù)表的一個分片,當數(shù)據(jù)表大小達到一定閾值后會“水平切分”成多個Region,通常同一張表的Region會分不到不同的機器上。
讀寫過程
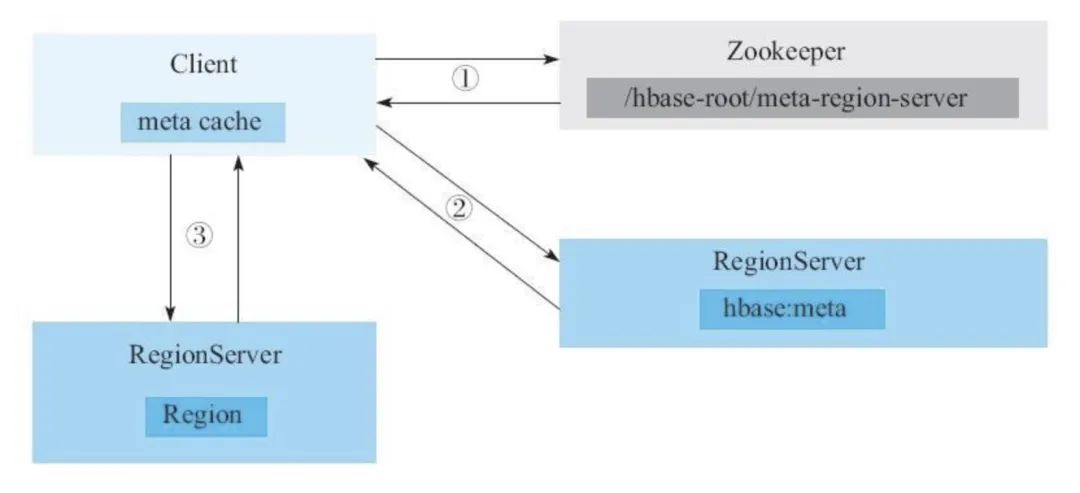
client 根據(jù)待寫入數(shù)據(jù)的主鍵(rowkey)尋找合適的 RegionServer 地址,如果沒有符合的,就向 zookeeper 查詢存儲HBase元數(shù)據(jù)表的 RegionServer 地址。 client 從第一步找到的 RegionServer 查詢HBase元數(shù)據(jù)表,找出合適的寫入地址。 將數(shù)據(jù)寫入對應(yīng)的 RegionServer 的 Region。
簡介
利用 Logstash 同步 Mysql 數(shù)據(jù)時并非使用 binlog,而且不支持同步刪除操作。
特點
適合: 全文檢索,like "%word%" 一定寫入延遲的高效查詢 多維度數(shù)據(jù)分析 不合適: 關(guān)聯(lián) 數(shù)據(jù)頻繁更新 不支持全局跨行事務(wù),僅支持單行事務(wù)
場景
數(shù)據(jù)分析場景 時序數(shù)據(jù)監(jiān)控 搜索服務(wù)
框架原理
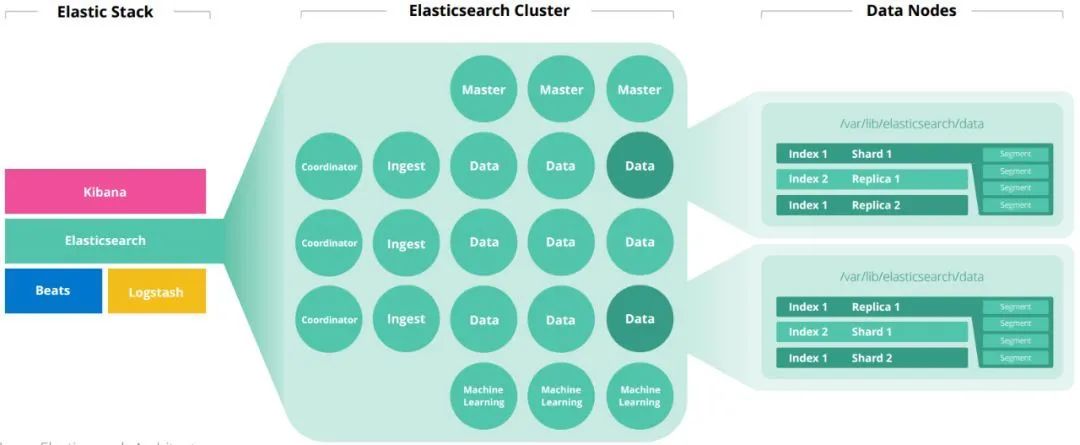
Master:主要負責集群中索引的創(chuàng)建、刪除以及數(shù)據(jù)的Rebalance等操作。 Data:存儲和檢索數(shù)據(jù) Coordinator:請求轉(zhuǎn)發(fā)和合并檢索結(jié)果 Ingest:轉(zhuǎn)換輸入的數(shù)據(jù)
增刪改查原理
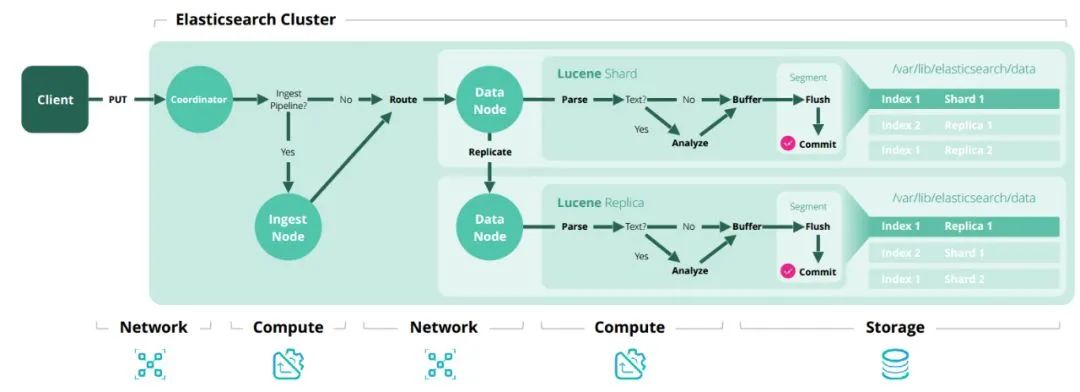
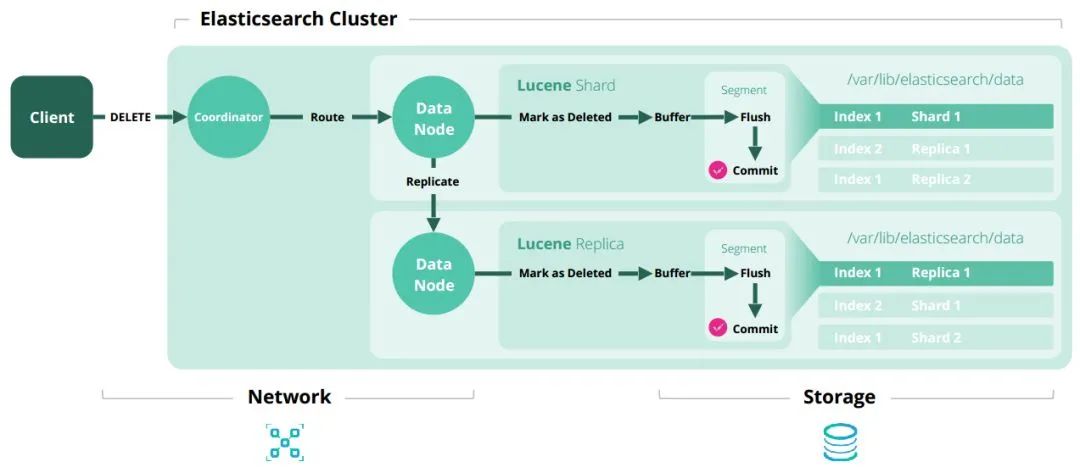
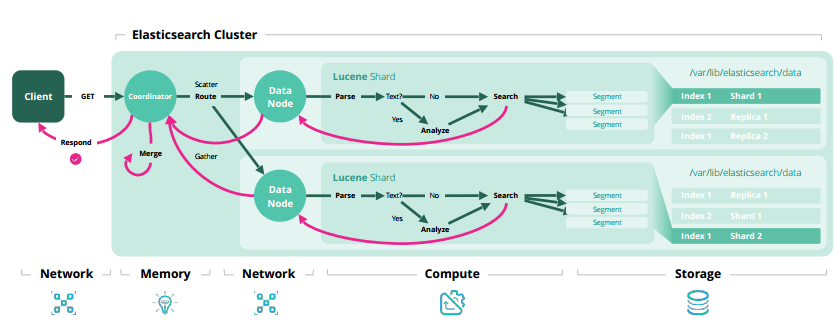
細節(jié)補充
倒排索引
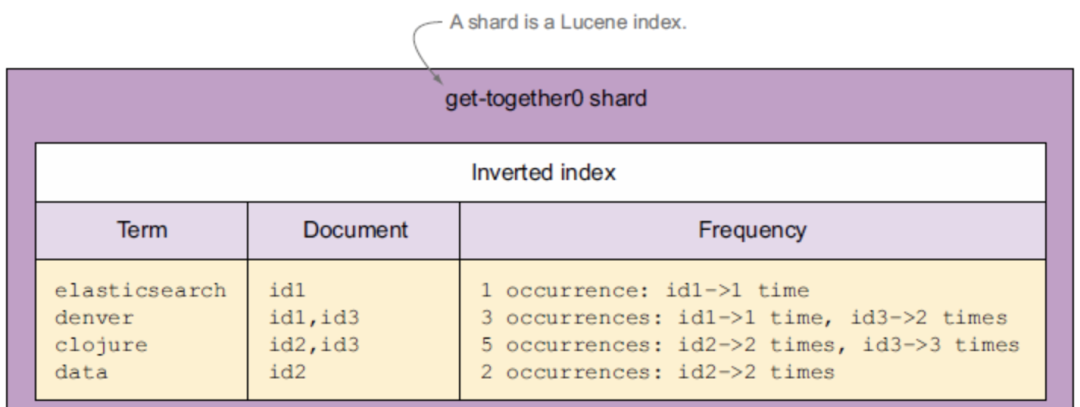
為什么全文檢索中 ES 比 Mysql 快?
select field1, field2
from tbl1
where field2 = a
and field3 in (1,2,3,4)
這里如果 field2 和 field3 都建立了索引,理論上速度跟 es 差不多。es最多把 field2 和 field3 concat 起來,做到查詢時只走一次索引來提高查詢效率。
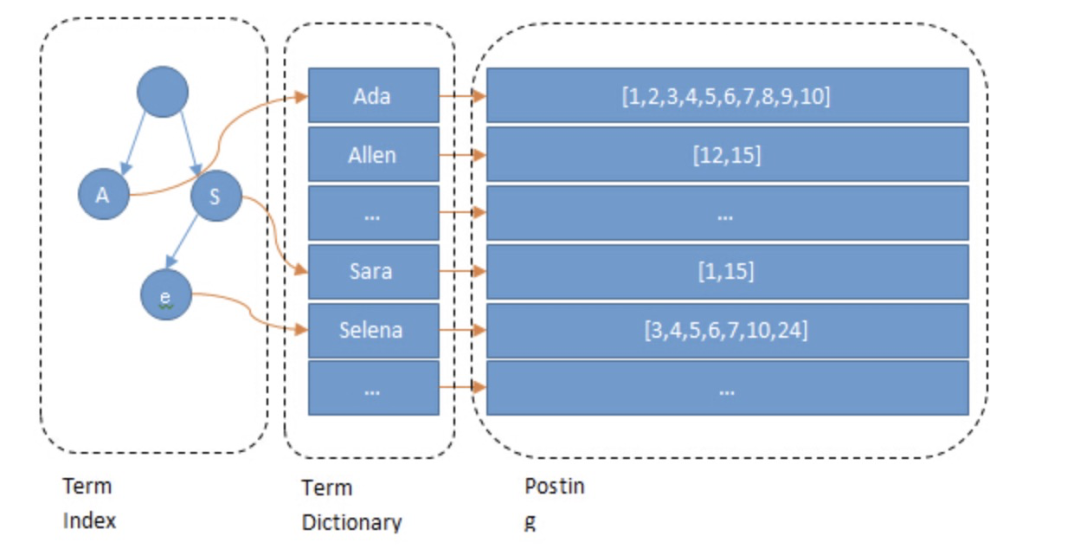
內(nèi)存消耗大
目前觸漫 ES 情況
適合:大批量數(shù)據(jù)的靈活計算,包括關(guān)聯(lián)、機器學(xué)習、圖計算、實時計算等。 不適合:小量數(shù)據(jù)的交互式計算。
Spark
架構(gòu)原理
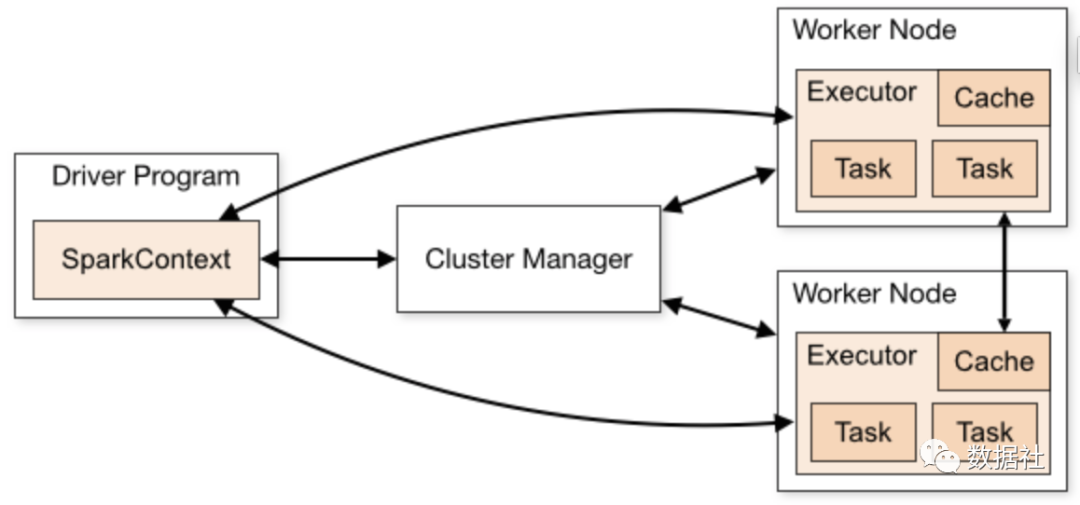
作業(yè)例子
object SparkSQLExample {def main(args: Array[String]): Unit = {// 創(chuàng)建 SparkSession,里面包含 sparkcontextval spark = SparkSession.builder().appName("Spark SQL basic example").getOrCreate()import spark.implicits._// 讀取數(shù)據(jù)val df1 = spark.read.load("path1...")val df2 = spark.read.load("path2...")// 注冊表df1.createOrReplaceTempView("tb1")df2.createOrReplaceTempView("tb2")// sqlval joinedDF = sql("""|select tb1.id, tb2.field|from tb1 inner join tb2|on tb1.id = tb2.id""".stripMargin)// driver 終端顯示結(jié)果joinedDF.show()// 退出 sparkspark.stop()}}
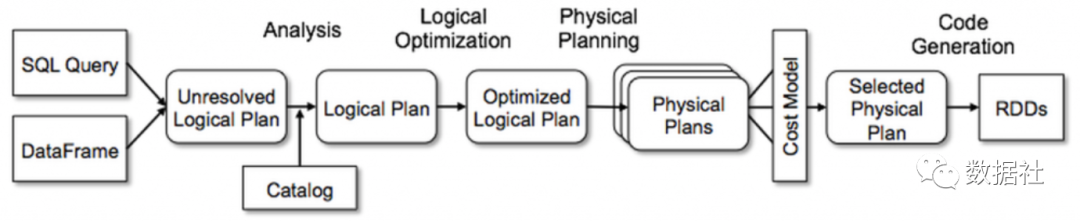
文檔型數(shù)據(jù)庫:大部分都不支持關(guān)聯(lián),因為效率低。關(guān)聯(lián)基本都要全文檔掃描。因為文檔是 schemaless 的,并不確定某個文檔是否有關(guān)聯(lián)所需字段。而且個文檔的讀取都是整個對象的讀取,并不會只讀某個字段來減少內(nèi)存開銷。另外,這兩個組件在內(nèi)存中本身就有各自的數(shù)據(jù)結(jié)構(gòu)來服務(wù)讀寫,所以額外的內(nèi)存用于這類大開銷計算也是不現(xiàn)實的。因此,HBase 本身只支持簡單的過濾,不支持關(guān)聯(lián)。ES 即便支持過濾、聚合,但依然不支持關(guān)聯(lián)。 傳統(tǒng)關(guān)系型數(shù)據(jù)庫:可以完成較大數(shù)據(jù)關(guān)聯(lián),然而效率低,這主要是受到其大量的磁盤 IO、自身服務(wù)(讀寫、事務(wù)等、數(shù)據(jù)同步)的干擾。在真正大數(shù)據(jù)情況下,這關(guān)聯(lián)還涉及數(shù)據(jù)在不同機器的移動,數(shù)據(jù)庫需要維持其數(shù)據(jù)結(jié)構(gòu),如 BTree,數(shù)據(jù)的移動效率較低。 計算引擎: 基于內(nèi)存:計算引擎留有大量內(nèi)存空間專門用于計算,盡量減少磁盤 IO。 計算并行化 算法優(yōu)化
BroadcastJoin:當一個大表和一個小表進行Join操作時,為了避免數(shù)據(jù)的Shuffle,可以將小表的全部數(shù)據(jù)分發(fā)到每個節(jié)點上。算法復(fù)雜度:O(n). ShuffledHashJoinExec:先對兩個表進行hash shuffle,然后把小表變成map完全存儲到內(nèi)存,最后進行join。算法復(fù)雜度:O(n)。不適合兩個表都很大的情況,因為其中一個表的hash部分要全部放到內(nèi)存。 SortMergeJoinExec:先hash shuffle將兩表數(shù)據(jù)數(shù)據(jù)相同key的分到同一個分區(qū),然后sort,最后join。由于排序的特性,每次處理完一條記錄后只需要從上一次結(jié)束的位置開始繼續(xù)查找。算法復(fù)雜度:O(nlogn),主要來源于排序。適合大表join大表。之所以適合大表,是因為 join 階段,可以只讀取一部分數(shù)據(jù)到內(nèi)存,但其中一塊遍歷完了,再把下一塊加載到內(nèi)存,這樣關(guān)聯(lián)的量就能突破內(nèi)存限制了。
數(shù)據(jù)流動
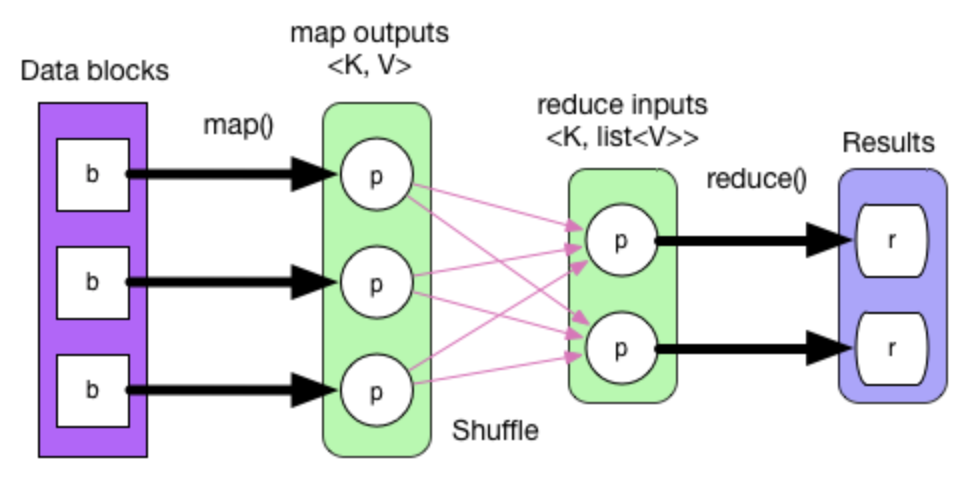
這是一張簡單的數(shù)據(jù)流程圖。描述了一個 WorkCount 的數(shù)據(jù)流向。其主要代碼如下:
val textFile = sc.textFile("hdfs://...")val counts = textFile.map(word => (word, 1)).reduceByKey(_ + _)counts.saveAsTextFile("hdfs://...")
Flink
實時分析/BI指標:比如某天搞活動或新版本上線,需要盡快根據(jù)用戶情況來調(diào)整策略或發(fā)現(xiàn)異常。 實時監(jiān)控:通過實時統(tǒng)計日志數(shù)據(jù)來盡快發(fā)現(xiàn)線上問題。 實時特征/樣本:模型預(yù)測和訓(xùn)練
架構(gòu)原理
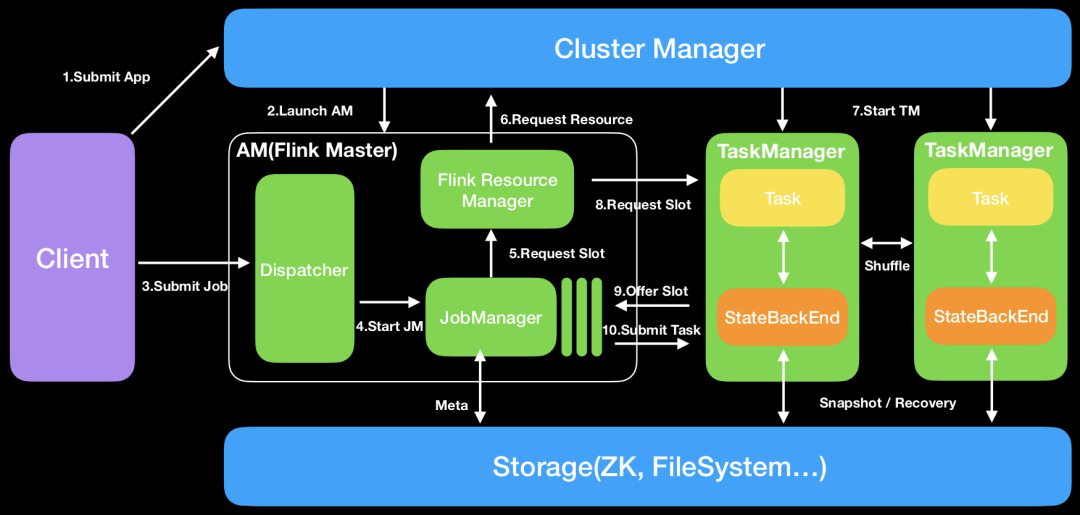
細節(jié)補充
保證數(shù)據(jù)剛好被處理一次,即便在計算過程中出現(xiàn)網(wǎng)絡(luò)異常或者宕機。 event-time處理,即按照數(shù)據(jù)中的時間作為計算引擎的時間,這樣即便數(shù)據(jù)上報出現(xiàn)一定的延遲,數(shù)據(jù)仍然可以被劃分到對應(yīng)的時間窗口。而且還能對一定時間內(nèi)的數(shù)據(jù)順序進行修正。 在版本升級,修改程序并行度時不需要重啟。 反壓機制,即便數(shù)據(jù)量極大,F(xiàn)link 也可以通過自身的機制減緩甚至拒絕接收數(shù)據(jù),以免程序被壓垮。
拉模型 系統(tǒng)更加成熟,尤其是離線計算 生態(tài)更加完善
推模型 實時計算更優(yōu)秀 阿里推動,正在迅速發(fā)展 生態(tài)對國內(nèi)更為友好
小紅書實時技術(shù)
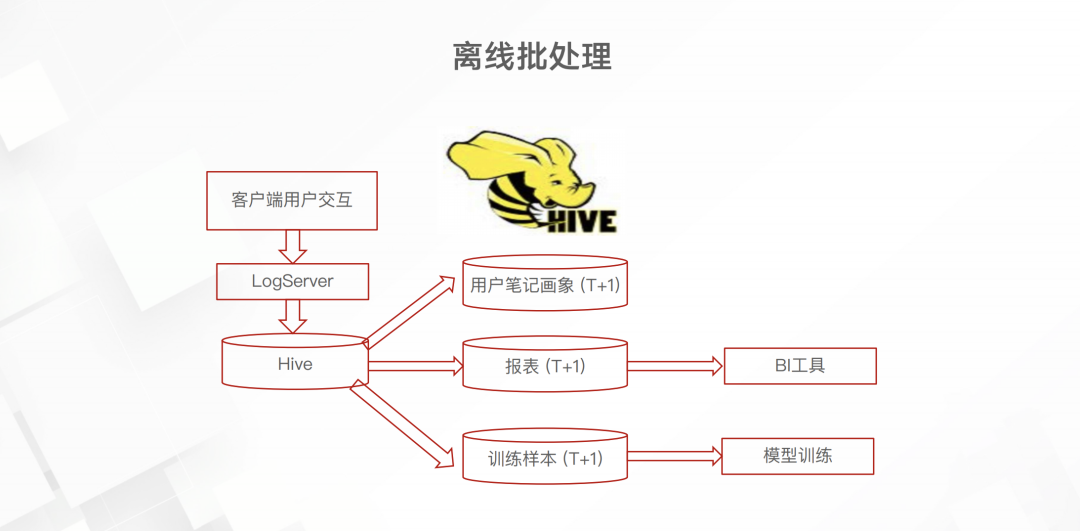
而后續(xù)的實時框架是這樣的
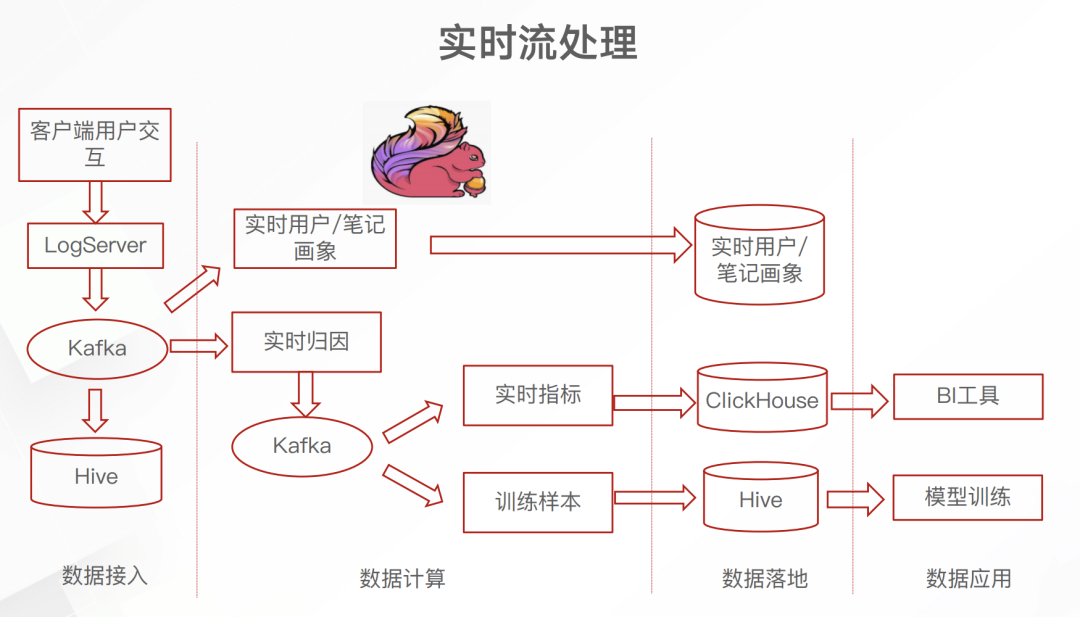
日志服務(wù)的埋點數(shù)據(jù)先進入 Kafka 這一消息隊列里面。不太清楚為什么要加上 Kafka 這一中間件,或許當時并沒有開源的 日志服務(wù)到Flink 的 connecter 吧。但總之,引入 Flink 之后就可以實時累計埋點中的數(shù)據(jù),進而產(chǎn)生實時的畫像、BI指標和訓(xùn)練數(shù)據(jù)了。下面介紹一下這個實時歸因
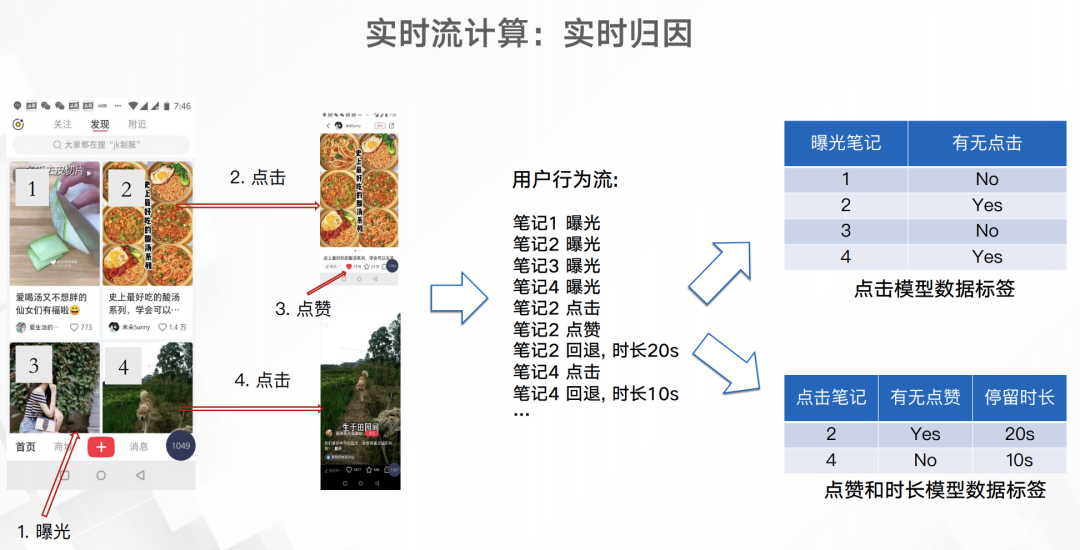
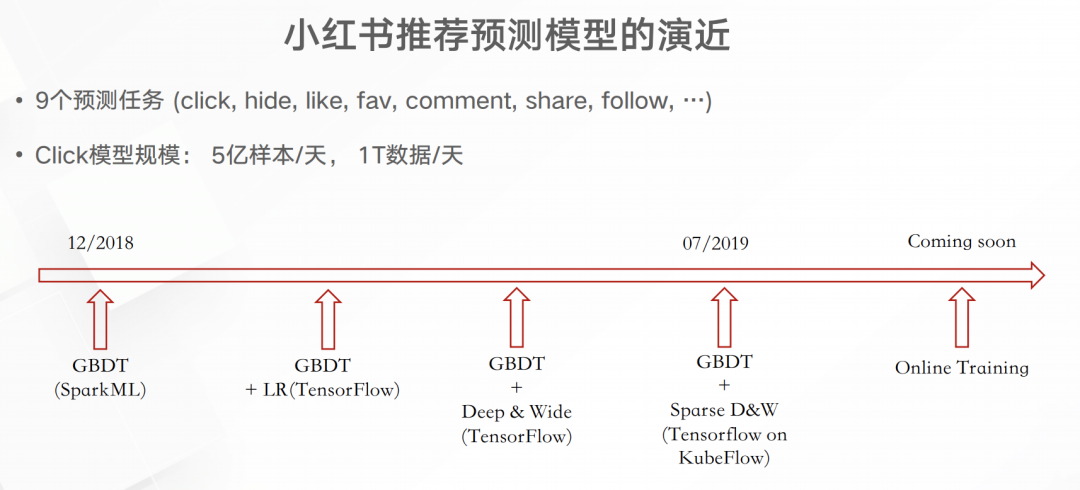
如上圖所以,用戶app屏幕展示了4個筆記,然后就會有4條曝光埋點,而如果點擊筆記、點贊筆記以及從筆記中退出都會有相應(yīng)的埋點。通過這些埋點就可以得出右面兩份簡單的訓(xùn)練或分析數(shù)據(jù)。這些數(shù)據(jù)跟原來已經(jīng)積累的筆記/用戶畫像進行關(guān)聯(lián)就能得出一份維度更多的數(shù)據(jù),用于實時的分析或模型預(yù)測。實時模型訓(xùn)練這一塊至少小紅書在19年8月都還沒有實現(xiàn)。下圖是小紅書推薦預(yù)測模型的演進
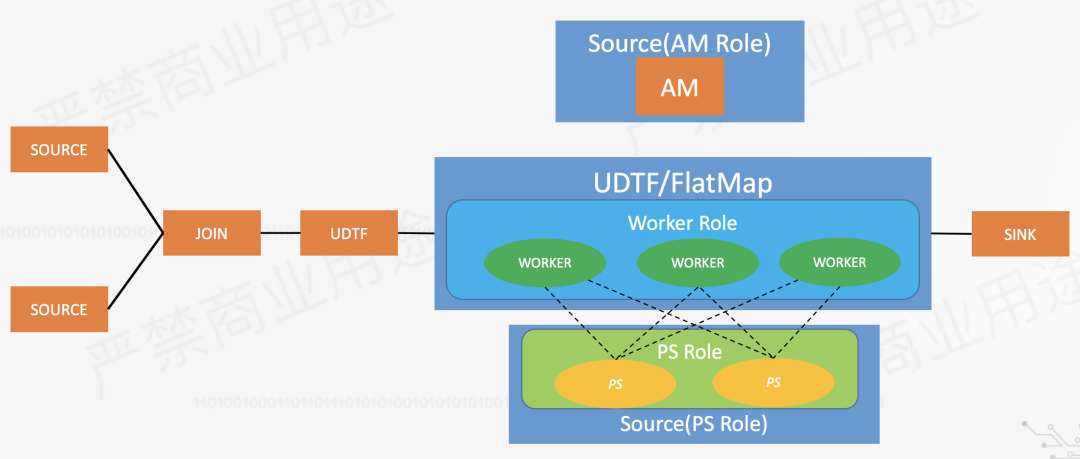
那么如何進行實時訓(xùn)練深度學(xué)習模型呢?以下是我的一些想法。借助一個阿里的開源框架flink-ai-extended。
Martin Kleppmann: “Designing Data-Intensive Applications”, O’Reilly Media, March 2017 Tom White: “Hadoop: The Definitive Guide”, 4th edition. O’Reilly Media, March 2015 胡爭, 范欣欣: “HBase原理與實踐”, 機械工業(yè)出版社, 2019年9月 朱鋒, 張韶全, 黃明: “Spark SQL 內(nèi)核剖析”, 電子工業(yè)出版社, 2018年8月 Fabian Hueske and Vasiliki Kalavri: “Stream Processing with Apache Flink”, O’Reilly Media, April 2019
再談 HBase 八大應(yīng)用場景:https://cloud.tencent.com/developer/article/1369824 Elasticsearch讀寫原理:https://blog.csdn.net/laoyang360/article/details/103545432 ES文章集:https://me.csdn.net/wojiushiwo987 MySQL和Lucene索引對比分析:https://www.cnblogs.com/luxiaoxun/p/5452502.html 深入淺出理解 Spark:環(huán)境部署與工作原理:https://mp.weixin.qq.com/s/IdrX4Hh1HQaJZx-VnB7XsQ
ES官方文檔:https://www.elastic.co/guide/index.html Spark官方文檔:http://spark.apache.org/docs/latest/ Flink官方文檔:https://flink.apache.org/
基于Flink的高性能機器學(xué)習算法庫?https://www.bilibili.com/video/av57447841?p=4 “Redefining Computation”?https://www.bilibili.com/video/av42325467?p=3 Flink 實時數(shù)倉的應(yīng)用?https://www.bilibili.com/video/av66782142 Flink runtime 核心機制剖析?https://www.bilibili.com/video/av42427050?p=4 小紅書大數(shù)據(jù)在推薦中的應(yīng)用?https://mp.weixin.qq.com/s/o7JM7DDkUNuGZEGKBtAmIw TensorFlow 與 Apache Flink 的結(jié)合?https://www.bilibili.com/video/av60808586/