
阿里大數(shù)據(jù)之路:數(shù)據(jù)技術(shù)篇大總結(jié)

目錄
一、日志采集
1.1 瀏覽器的頁(yè)面日志采集
1.2 無線客戶端的日志采集
1.3 日志采集的挑戰(zhàn)案例
二、數(shù)據(jù)同步
2.1 數(shù)據(jù)同步基礎(chǔ)
2.2 數(shù)據(jù)同步策略
2.2.1 批量數(shù)據(jù)同步
2.2.2 實(shí)時(shí)數(shù)據(jù)同步
2.3 數(shù)據(jù)同步問題
2.3.1 分庫(kù)分表處理
2.3.2 高效同步和批量同步
2.3.3 增量與全量同步的合并
2.3.4 數(shù)據(jù)同步性能
2.3.5 數(shù)據(jù)漂移
三、離線數(shù)據(jù)開發(fā)
3.1 統(tǒng)一計(jì)算平臺(tái)
3.2 統(tǒng)一開發(fā)平臺(tái)
3.3 任務(wù)調(diào)度系統(tǒng)
3.4 特點(diǎn)
四、實(shí)時(shí)技術(shù)
4.1 流式技術(shù)架構(gòu)
4.1.1 數(shù)據(jù)采集
4.1.2 數(shù)據(jù)處理
4.1.3 數(shù)據(jù)存儲(chǔ)
4.2 流式數(shù)據(jù)模型
4.2.1 數(shù)據(jù)分層
4.2.2 多流關(guān)聯(lián)
五、數(shù)據(jù)服務(wù)
5.1 服務(wù)架構(gòu)演進(jìn)
5.1.1 DWSOA
5.1.2 OpenAPI
5.1.3 SmartDQ
5.1.4 OneService
5.2 性能優(yōu)化
5.2.1 資源分配
5.2.2 緩存優(yōu)化
5.2.3 查詢能力
六、數(shù)據(jù)挖掘
一、日志采集
本章主要介紹數(shù)據(jù)采集中的日志采集部分,阿里巴巴的日志采集體系方案包括兩大體系:
- Aplus.JS是Web端( 基于瀏覽器)日志采集技術(shù)方案;
- UserTrack是APP端(無線客戶端)日志采集技術(shù)方案。
本章從瀏覽器的頁(yè)面日志采集、無線客戶端的日志采集以及我們遇到的日志采集挑戰(zhàn)三塊內(nèi)容來闡述阿里巴巴的日志采集經(jīng)驗(yàn)。
1.1 瀏覽器的頁(yè)面日志采集
(1)頁(yè)面瀏覽(展現(xiàn))日志采集
顧名思義,頁(yè)面瀏覽日志是指當(dāng)一個(gè)頁(yè)面被瀏覽器加載呈現(xiàn)時(shí)采集的日志。此類日志是最基礎(chǔ)的互聯(lián)網(wǎng)日志,也是目前所有互聯(lián)網(wǎng)產(chǎn)品的兩大基本指標(biāo):頁(yè)面瀏覽量(Page View,PV)和訪客數(shù)(UniqueVisitors,UV)的統(tǒng)計(jì)基礎(chǔ)。頁(yè)面瀏覽日志是目前成熟度和完備度最高,同時(shí)也是最具挑戰(zhàn)性的日志采集任務(wù),我們將重點(diǎn)講述此類日志的采集。
(2)頁(yè)面交互日志采集
當(dāng)頁(yè)面加載和渲染完成之后,用戶可以在頁(yè)面上執(zhí)行各類操作。隨著互聯(lián)網(wǎng)前端技術(shù)的不斷發(fā)展,用戶可在瀏覽器內(nèi)與網(wǎng)頁(yè)進(jìn)行的互動(dòng)已經(jīng)豐富到只有想不到?jīng)]有做不到的程度,互動(dòng)設(shè)計(jì)都要求采集用戶的互動(dòng)行為數(shù)據(jù),以便通過量化獲知用戶的興趣點(diǎn)或者體驗(yàn)優(yōu)化點(diǎn)。交互日志采集就是為此類業(yè)務(wù)場(chǎng)景而生的。
除此之外,還有一些專門針對(duì)某些特定統(tǒng)計(jì)場(chǎng)合的日志采集需求,如專門采集特定媒體在頁(yè)面被曝光狀態(tài)的曝光日志、用戶在線狀態(tài)的實(shí)時(shí)監(jiān)測(cè)等,但在基本原理上都脫胎于上述兩大類。
1.2 無線客戶端的日志采集
眾所周知,日志采集多是為了進(jìn)行后續(xù)的數(shù)據(jù)分析。
移動(dòng)端的數(shù)據(jù)采集,一是為了服務(wù)于開發(fā)者,協(xié)助開發(fā)者分析各類設(shè)備信息;二是為了幫助各APP更好地了解自己的用戶,了解用戶在APP上的各類行為,幫助各應(yīng)用不斷進(jìn)行優(yōu)化,提升用戶體驗(yàn)。
無線客戶端的日志采集采用采集SDK來完成,在阿里巴巴內(nèi)部,多使用名為UserTrack的SDK來進(jìn)行無線客戶端的日志采集。無線客戶端的日志采集和瀏覽器的日志采集方式有所不同,移動(dòng)端的日志采集根據(jù)不同的用戶行為分成不同的事件,“事件”為無線客戶端日志行為的最小單位。基于常規(guī)的分析,UserTrack(UT)把事件分成了幾類,常用的包括頁(yè)面事件(同前述的頁(yè)面瀏覽)和控件點(diǎn)擊事件(同前述的頁(yè)面交互)等。
對(duì)事件進(jìn)行分類的原因,除了不同事件的日志觸發(fā)時(shí)機(jī)、日志內(nèi)容和實(shí)現(xiàn)方式有差異之外,另一方面是為了更好地完成數(shù)據(jù)分析。在常見的業(yè)務(wù)分析中,往往較多地涉及某類事件,而非全部事件;故為了降低后續(xù)處理的復(fù)雜性,對(duì)事件進(jìn)行分類尤為重要。要更好地進(jìn)行日志數(shù)據(jù)分析,涉及很多方面的內(nèi)容,如需要處理Hybrid應(yīng)用,實(shí)現(xiàn)H5和Native日志的統(tǒng)一;又如識(shí)別設(shè)備,保證同一設(shè)備上各應(yīng)用獲取到的設(shè)備信息是唯一的。除此之外,對(duì)于采集到的數(shù)據(jù)如何上傳,以及后續(xù)又如何合理處理等,每個(gè)過程都值得我們進(jìn)行深入的研究和探索。
1.3 日志采集的挑戰(zhàn)案例
對(duì)于目前的互聯(lián)網(wǎng)行業(yè)而言,互聯(lián)網(wǎng)日志早已跨越初級(jí)的饑餓階段(大型互聯(lián)網(wǎng)企業(yè)的日均日志收集量均以億為單位計(jì)量),反而面臨海量日志的淹沒風(fēng)險(xiǎn)。各類采集方案提供者所面臨的主要挑戰(zhàn)已不是日志采集技術(shù)本身,而是如何實(shí)現(xiàn)日志數(shù)據(jù)的結(jié)構(gòu)化和規(guī)范化組織,實(shí)現(xiàn)更為高效的下游統(tǒng)計(jì)計(jì)算,提供符合業(yè)務(wù)特性的數(shù)據(jù)展現(xiàn),以及為算法提供更便捷、靈活的支持等方面。
這里介紹兩個(gè)最典型的場(chǎng)景和阿里巴巴所采用的解決方案。
- 日志分流與定制處理
- 采集與計(jì)算一體化設(shè)計(jì)
二、數(shù)據(jù)同步
2.1 數(shù)據(jù)同步基礎(chǔ)
數(shù)據(jù)同步的三種方式:
- 數(shù)據(jù)直抽。
- 數(shù)據(jù)文件同步。
- 數(shù)據(jù)庫(kù)日志解析同步。
2.2 數(shù)據(jù)同步策略
2.2.1 批量數(shù)據(jù)同步
- 數(shù)據(jù)類型統(tǒng)一采用字符串類型(中間狀態(tài))。
- DataX對(duì)不同的數(shù)據(jù)源提供插件,將數(shù)據(jù)從數(shù)據(jù)源讀出并轉(zhuǎn)換為中間狀態(tài)存儲(chǔ)。
- 傳輸過程全內(nèi)存操作,不讀寫磁盤,也沒有進(jìn)程間通信。
2.2.2 實(shí)時(shí)數(shù)據(jù)同步
- 通過解析MySQL的binlog日志來實(shí)時(shí)獲得增量的數(shù)據(jù)更新,并通過消息訂閱模式來實(shí)現(xiàn)數(shù)據(jù)的實(shí)時(shí)同步。
- 日志數(shù)據(jù)——> 日志交換中心——> 訂閱了該數(shù)據(jù)的數(shù)據(jù)倉(cāng)庫(kù)。
- 針對(duì)訂閱功能,可以支持主動(dòng)、被動(dòng)訂閱,訂閱端自動(dòng)負(fù)載均衡。數(shù)據(jù)消費(fèi)者自己把握消費(fèi)策略。可以訂閱歷史數(shù)據(jù),隨意設(shè)置訂閱位置。并具有屬性過濾功能。
2.3 數(shù)據(jù)同步問題
2.3.1 分庫(kù)分表處理
建立了一個(gè)中間層的邏輯表來整合分庫(kù)分表。使得外部訪問中間層的時(shí)候,與訪問單庫(kù)單表一樣簡(jiǎn)潔。中間層介于應(yīng)用持久層和JDBC驅(qū)動(dòng)之間。
2.3.2 高效同步和批量同步
統(tǒng)一管理不同源數(shù)據(jù)庫(kù)的元數(shù)據(jù)信息,強(qiáng)化版的元數(shù)據(jù)管理平臺(tái),要求數(shù)據(jù)同步配置透明化。通過庫(kù)名和表名即可通過元數(shù)據(jù)管理平臺(tái)唯一定位,再由自動(dòng)化的數(shù)據(jù)同步平臺(tái)完成建表、配置任務(wù)、發(fā)布、測(cè)試的一鍵化處理。
2.3.3 增量與全量同步的合并
全外連接與insert overwrite代替merge與update。
采用分區(qū),每天保持一個(gè)最新的全量版本,每個(gè)版本僅保留較短的時(shí)間周期如3天至一周。
方式為當(dāng)天的增量數(shù)據(jù)與前一天的全量數(shù)據(jù)合并,生成當(dāng)天的全量數(shù)據(jù)。
2.3.4 數(shù)據(jù)同步性能
2.3.5 數(shù)據(jù)漂移
常見于0點(diǎn)時(shí)分左右,數(shù)據(jù)按照日期劃分跨天的問題。冗余獲取0點(diǎn)左右的數(shù)據(jù),根據(jù)多種時(shí)間字段來排序去重,重新劃分和補(bǔ)錄數(shù)據(jù)。
三、離線數(shù)據(jù)開發(fā)
3.1 統(tǒng)一計(jì)算平臺(tái)
- 承擔(dān)數(shù)據(jù)導(dǎo)入、存儲(chǔ)、各式計(jì)算。
- 從上至下分為客戶端、接入層、邏輯層、計(jì)算層。
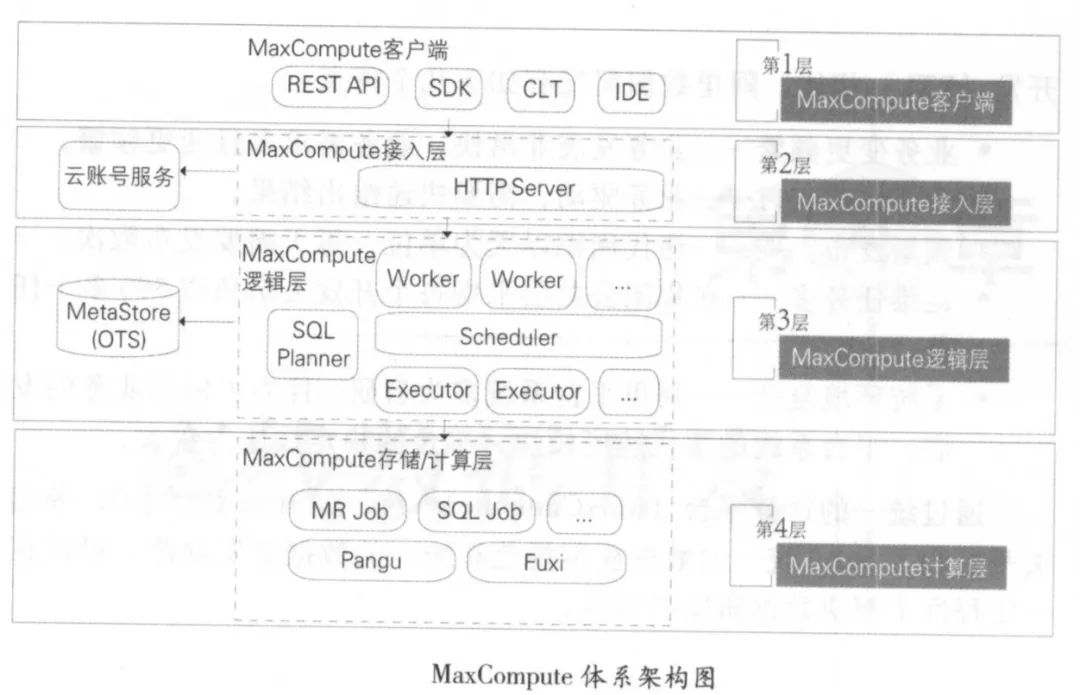
(1)在邏輯層有 Worker Sc heduler Executor 三個(gè)角色:
- Worker 處理所有的阻STful 請(qǐng)求,包括用戶空間( Project )管理操作、資源( Resource )管理操作、作業(yè)管理等,對(duì)于 SQLDMLMR 等需要啟動(dòng) MapReduce 的作業(yè),會(huì)生成 MaxCompute Instance(類似于 Hive 中的 Job) ,提交給 Scheduler 一步處理。
- Scheduler負(fù)責(zé) MaxCompute Instance 的調(diào)度和拆解,并向計(jì)算層的計(jì)算集群詢問資源占用情況以進(jìn)行流控。
- Executor 負(fù)責(zé) MaxCompute Instance 的執(zhí)行,向計(jì)算層的計(jì)算集群提交真正的計(jì)算任務(wù)。
(2)MaxCompute 能保證數(shù)據(jù)的正確性,如對(duì)數(shù)據(jù)的準(zhǔn)確性要求非常高的螞蟻金服小額貸款業(yè)務(wù),就運(yùn)行于Max Compute 平臺(tái)之上。
3.2 統(tǒng)一開發(fā)平臺(tái)
包括開發(fā)調(diào)試與發(fā)布平臺(tái)、代碼質(zhì)量控制平臺(tái)、數(shù)據(jù)質(zhì)量監(jiān)控平臺(tái)、測(cè)試平臺(tái)。
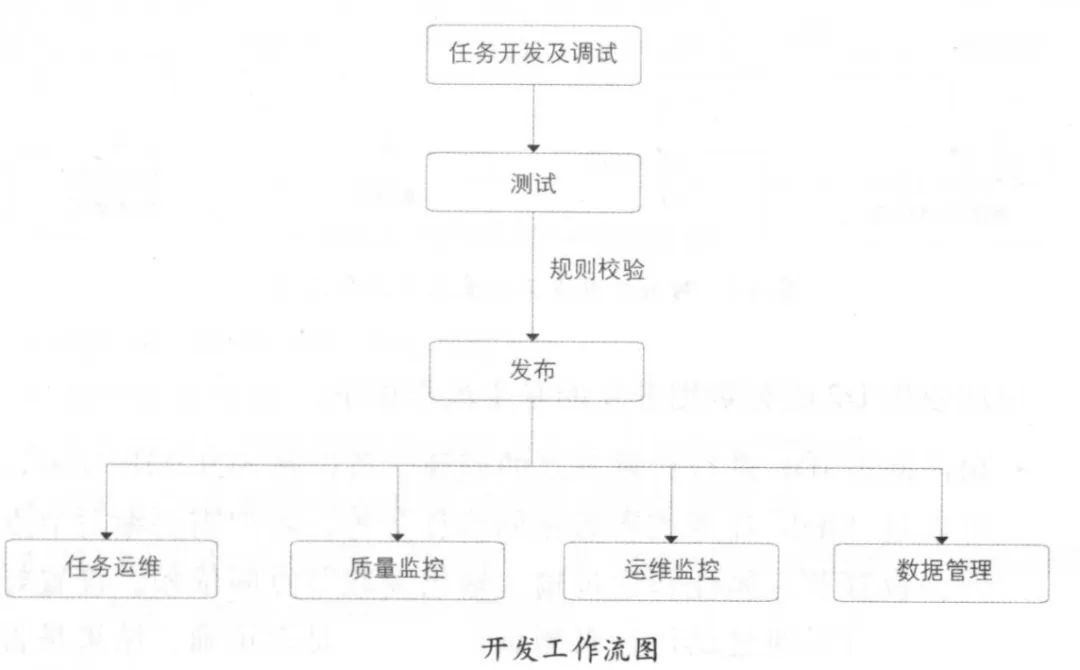
兩張圖對(duì)應(yīng)起來看:
(1) 在彼岸:多路分支進(jìn)行測(cè)試和完成數(shù)據(jù)脫敏(將敏感數(shù)據(jù)模糊化)
(2) SQLSCAN:對(duì)用戶的SQL進(jìn)行規(guī)范,檢查代碼的規(guī)范性
(3) 開發(fā)平臺(tái)(D2)發(fā)布系統(tǒng):實(shí)現(xiàn)和用戶的IDE對(duì)接,用戶可以通過IDE在D2上創(chuàng)建工作節(jié)點(diǎn)。
(4) DQC:清洗和監(jiān)控?cái)?shù)據(jù),接收到到的數(shù)據(jù)與規(guī)則庫(kù)對(duì)比,監(jiān)控相關(guān)數(shù)據(jù)的可用性和對(duì)無用的數(shù)據(jù)進(jìn)行清洗。
3.3 任務(wù)調(diào)度系統(tǒng)
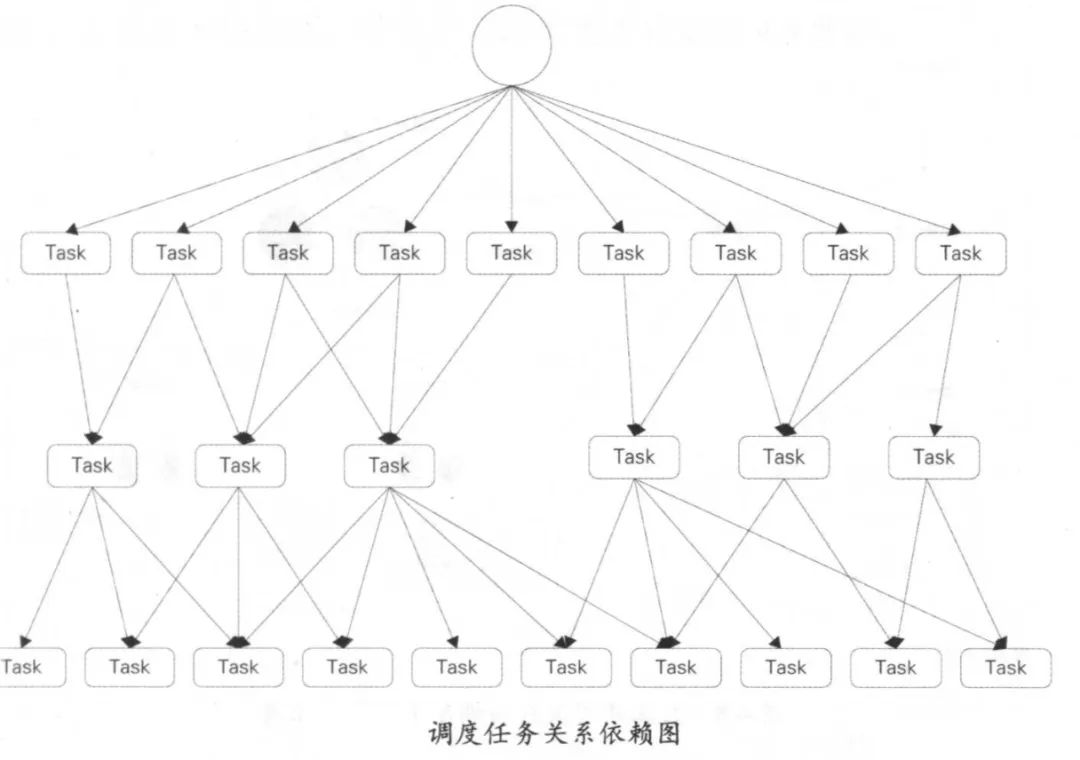
- 調(diào)度系統(tǒng)分為調(diào)度引擎和執(zhí)行引擎。
- 狀態(tài)機(jī)分為工作流狀態(tài)機(jī)與任務(wù)狀態(tài)機(jī),工作流包含待提交、已創(chuàng)建、正在執(zhí)行、成功、失敗等各個(gè)工作節(jié)點(diǎn);而任務(wù)狀態(tài)則是在工作流之下的一系列狀態(tài),例如執(zhí)行中的等待狀態(tài)。
- 通過事件驅(qū)動(dòng),生成調(diào)度實(shí)例,在兩種狀態(tài)機(jī)之間切換執(zhí)行調(diào)度,根據(jù)狀態(tài)的不同也在調(diào)度引擎和執(zhí)行引擎之間切換。
3.4 特點(diǎn)
- 依賴管理。自動(dòng)識(shí)別SQL的輸入輸出表,自動(dòng)關(guān)聯(lián)依賴的任務(wù)。
- 周期調(diào)度。會(huì)根據(jù)資源和上游依賴的情況,自動(dòng)調(diào)整具體執(zhí)行時(shí)間。
- 手動(dòng)運(yùn)行。基于自動(dòng)發(fā)布,可以在開發(fā)平臺(tái)中開發(fā)腳本,發(fā)布到生產(chǎn)后手工調(diào)度。
四、實(shí)時(shí)技術(shù)
4.1 流式技術(shù)架構(gòu)
架構(gòu)分為數(shù)據(jù)采集、數(shù)據(jù)處理、數(shù)據(jù)存儲(chǔ)、數(shù)據(jù)服務(wù)四部分。
4.1.1 數(shù)據(jù)采集
- 從數(shù)據(jù)源采集數(shù)據(jù)均已文件的形式保存,通過監(jiān)控文件內(nèi)容的變化,使用數(shù)據(jù)大小的限制和間隔時(shí)間閾值的限制來共同決定采集的頻率。
- 將數(shù)據(jù)落到數(shù)據(jù)中間件之后,可由流計(jì)算平臺(tái)來訂閱數(shù)據(jù)。
4.1.2 數(shù)據(jù)處理
- SQL語(yǔ)義的流式數(shù)據(jù)分析能力。
- 流式處理的原理:多個(gè)數(shù)據(jù)入口、多個(gè)處理邏輯,處理邏輯可分為多個(gè)層級(jí)逐層執(zhí)行。
- 數(shù)據(jù)傾斜:數(shù)據(jù)量非常大時(shí),分桶執(zhí)行。
- 去重處理:精確去重使用數(shù)據(jù)傾斜的方式,模糊去重使用哈希來減少內(nèi)存占用。
- 事物處理:超時(shí)補(bǔ)發(fā)、每批數(shù)據(jù)自帶ID、將內(nèi)存數(shù)據(jù)備份到外部存儲(chǔ)。
4.1.3 數(shù)據(jù)存儲(chǔ)
- 實(shí)時(shí)系統(tǒng)要求數(shù)據(jù)存儲(chǔ)滿足多線程多并發(fā)以及毫秒級(jí)的低延時(shí)。
- 表名設(shè)計(jì)和rowkey設(shè)計(jì)遵循數(shù)據(jù)均衡分布、同一主維度的數(shù)據(jù)在同一張物理表。
4.2 流式數(shù)據(jù)模型
4.2.1 數(shù)據(jù)分層
- ODS:直接從業(yè)務(wù)采集來的原始數(shù)據(jù),包含所有業(yè)務(wù)的變更過程。存儲(chǔ)于數(shù)據(jù)中間件。
- DWD:根據(jù)業(yè)務(wù)過程建模出來的事實(shí)明細(xì)。存儲(chǔ)于數(shù)據(jù)中間件。
- DWS:各個(gè)維度的匯總指標(biāo),該維度是各個(gè)垂直業(yè)務(wù)線通用的,落地到存儲(chǔ)系統(tǒng)。
- AWS:各個(gè)維度的匯總指標(biāo),適用于某個(gè)業(yè)務(wù)條線獨(dú)有的維度,落地到存儲(chǔ)系統(tǒng)。
- DIM:實(shí)時(shí)維表層,由離線的維表導(dǎo)入,離線處理。
4.2.2 多流關(guān)聯(lián)
多個(gè)流關(guān)聯(lián)時(shí),只有能匹配上的數(shù)據(jù)會(huì)被輸出到下游,否則存儲(chǔ)到外部存儲(chǔ)系統(tǒng)中,當(dāng)有更新進(jìn)來的時(shí)候,從外部存儲(chǔ)系統(tǒng)中重新讀取數(shù)據(jù)到內(nèi)存,從已執(zhí)行完成的部分繼續(xù)執(zhí)行。
五、數(shù)據(jù)服務(wù)
5.1 服務(wù)架構(gòu)演進(jìn)
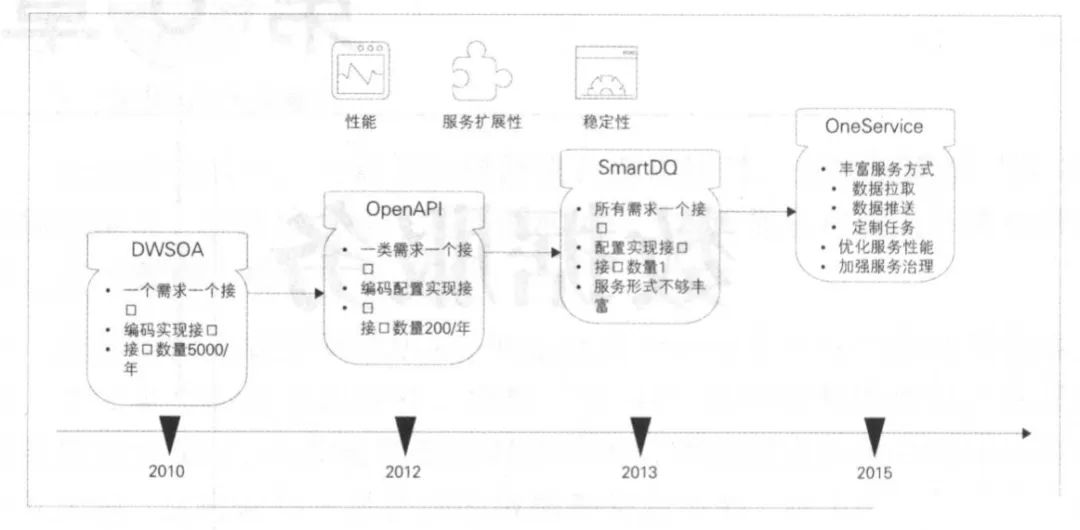
5.1.1 DWSOA
- SOA服務(wù)
- 一個(gè)需求對(duì)應(yīng)一到多個(gè)接口
- 復(fù)用性差、細(xì)微改動(dòng)也要走全套上線流程
5.1.2 OpenAPI
- 為了減少接口數(shù)量,將相同維度的數(shù)據(jù)聚合成一張邏輯寬表,使用相同的接口。
- 維度不可控,隨著維度數(shù)量的增長(zhǎng),關(guān)系映射的維護(hù)變得困難。
5.1.3 SmartDQ
- 為了減少維度,使用ORM框架封裝了邏輯表,業(yè)務(wù)方使用SQL來查詢數(shù)據(jù),只需要關(guān)注邏輯表結(jié)構(gòu),對(duì)真實(shí)數(shù)據(jù)源和數(shù)據(jù)表不關(guān)心。
- 接口易上難下,即使一個(gè)接口也會(huì)綁定一批人。所以對(duì)外提供的數(shù)據(jù)服務(wù)接口一定要盡可能抽象,接口的數(shù)量要盡可能收斂,最后再保障服務(wù)質(zhì)量的情況下,盡可能減少維護(hù)工作量。
5.1.4 OneService
- 但SQL只能滿足簡(jiǎn)單的查詢需求,不能解決復(fù)雜的業(yè)務(wù)邏輯。面對(duì)不同的場(chǎng)景,創(chuàng)建了多種服務(wù)類型。既有支持簡(jiǎn)單SQL查詢的入口,又有面向負(fù)責(zé)業(yè)務(wù)邏輯的定制化插件入口。
5.2 性能優(yōu)化
5.2.1 資源分配
- 剝離復(fù)雜的計(jì)算邏輯,將其交由數(shù)據(jù)共同層處理。
- 將Get類型與List類型的查詢分為不同的線程池。
- 執(zhí)行計(jì)劃優(yōu)化。比如拆分邏輯表的查詢到不同的物理表去執(zhí)行、將List類型的查詢改變?yōu)镚et類型的查詢等。
5.2.2 緩存優(yōu)化
- 元數(shù)據(jù)緩存、邏輯表查詢到物理表查詢的映射緩存、查詢結(jié)果緩存。
5.2.3 查詢能力
- 合并離線數(shù)據(jù)查詢與實(shí)時(shí)數(shù)據(jù)查詢,在離線數(shù)據(jù)無法查到結(jié)果的時(shí)候即時(shí)切換到實(shí)時(shí)查詢。
- 對(duì)于需要輪詢的數(shù)據(jù),采用推送代替輪詢。當(dāng)監(jiān)聽到數(shù)據(jù)有更新時(shí),推送更新的數(shù)據(jù)。
六、數(shù)據(jù)挖掘
數(shù)據(jù)挖掘過程包括商業(yè)理解、數(shù)據(jù)準(zhǔn)備、特征工程、模型訓(xùn)練、模型測(cè)試、模型部署、線上應(yīng)用、效果反饋等環(huán)節(jié)。
數(shù)據(jù)中臺(tái)分為特征層(Featural Data Mining Layer, FDM)、中間層、應(yīng)用層(Application-oriented Data Mining Layer, ADM),其中中間層分為個(gè)體中間層(Individual Data Mining Layer, IDM)、關(guān)系中間層(Relational Data Mining Layer, RDM)。
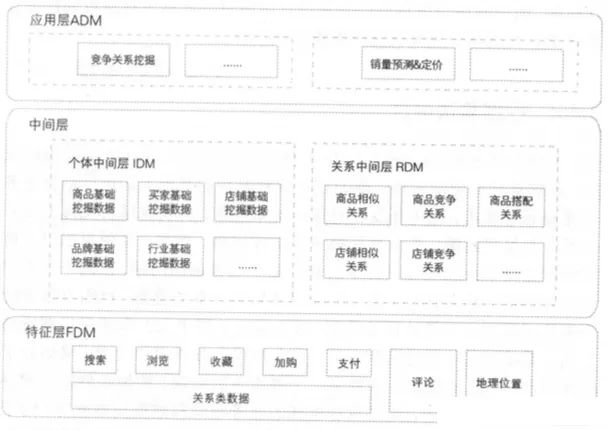
不同數(shù)據(jù)層的作用的區(qū)別:
- FDM層:用于存儲(chǔ)在模型訓(xùn)練前常用的特征指標(biāo),并進(jìn)行統(tǒng)一的清洗和去燥處理,提升機(jī)器學(xué)習(xí)特征工程環(huán)節(jié)的效率。
- IDM層:個(gè)體挖掘指標(biāo)中間層,面向個(gè)體挖掘場(chǎng)景,用于存儲(chǔ)通用性強(qiáng)的結(jié)果數(shù)據(jù),主要包含商品、賣家、買家、行業(yè)等維度的個(gè)體數(shù)據(jù)挖掘的相關(guān)指標(biāo)。
- RDM層:關(guān)系挖掘指標(biāo)中間層,面向關(guān)系挖掘場(chǎng)景,用于存儲(chǔ)通用性強(qiáng)的結(jié)果數(shù)據(jù),主要包含商品間的相似關(guān)系、競(jìng)爭(zhēng)關(guān)系、店鋪間的相似關(guān)系、競(jìng)爭(zhēng)關(guān)系等。
- ADM層:用來沉淀比較個(gè)性化偏應(yīng)用的數(shù)據(jù)挖掘指標(biāo),比如用戶偏好的類目,品牌等,這些數(shù)據(jù)已經(jīng)過深度的加工處理,滿足某一特點(diǎn)業(yè)務(wù)或產(chǎn)品的使用。
常見數(shù)據(jù)挖掘應(yīng)用:
1.個(gè)體挖掘應(yīng)用
- 用戶畫像
- 用戶身份&同人識(shí)別
- 業(yè)務(wù)指標(biāo)預(yù)測(cè)
- ID反作弊
2.關(guān)系挖掘應(yīng)用
- 相似關(guān)系挖掘
- 競(jìng)爭(zhēng)關(guān)系挖掘
- 推薦系統(tǒng)
 2022年全網(wǎng)首發(fā)|大數(shù)據(jù)專家級(jí)技能模型與學(xué)習(xí)指南(勝天半子篇)
互聯(lián)網(wǎng)最壞的時(shí)代可能真的來了
2022年全網(wǎng)首發(fā)|大數(shù)據(jù)專家級(jí)技能模型與學(xué)習(xí)指南(勝天半子篇)
互聯(lián)網(wǎng)最壞的時(shí)代可能真的來了
我在B站讀大學(xué),大數(shù)據(jù)專業(yè)
我們?cè)趯W(xué)習(xí)Flink的時(shí)候,到底在學(xué)習(xí)什么? 193篇文章暴揍Flink,這個(gè)合集你需要關(guān)注一下 Flink生產(chǎn)環(huán)境TOP難題與優(yōu)化,阿里巴巴藏經(jīng)閣YYDS Flink CDC我吃定了耶穌也留不住他!| Flink CDC線上問題小盤點(diǎn) 我們?cè)趯W(xué)習(xí)Spark的時(shí)候,到底在學(xué)習(xí)什么? 在所有Spark模塊中,我愿稱SparkSQL為最強(qiáng)! 硬剛Hive | 4萬(wàn)字基礎(chǔ)調(diào)優(yōu)面試小總結(jié) 數(shù)據(jù)治理方法論和實(shí)踐小百科全書
標(biāo)簽體系下的用戶畫像建設(shè)小指南
4萬(wàn)字長(zhǎng)文 | ClickHouse基礎(chǔ)&實(shí)踐&調(diào)優(yōu)全視角解析
【面試&個(gè)人成長(zhǎng)】2021年過半,社招和校招的經(jīng)驗(yàn)之談 大數(shù)據(jù)方向另一個(gè)十年開啟 |《硬剛系列》第一版完結(jié) 我寫過的關(guān)于成長(zhǎng)/面試/職場(chǎng)進(jìn)階的文章 當(dāng)我們?cè)趯W(xué)習(xí)Hive的時(shí)候在學(xué)習(xí)什么?「硬剛Hive續(xù)集」