
Apache Iceberg技術(shù)調(diào)研&在各大公司的實(shí)踐應(yīng)用大總結(jié)
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”
回復(fù)”資源“獲取更多驚喜

作者在實(shí)際工作中調(diào)研了Iceberg的一些優(yōu)缺點(diǎn)和在各大廠的應(yīng)用,總結(jié)在下面。希望能給大家?guī)硪恍﹩⑹尽?/span>
隨著大數(shù)據(jù)存儲和處理需求越來越多樣化,如何構(gòu)建一個(gè)統(tǒng)一的數(shù)據(jù)湖存儲,并在其上進(jìn)行多種形式的數(shù)據(jù)分析,成了企業(yè)構(gòu)建大數(shù)據(jù)生態(tài)的一個(gè)重要方向。如何快速、一致、原子性地在數(shù)據(jù)湖存儲上構(gòu)建起 Data Pipeline,成了亟待解決的問題。
為此,Uber 開源了 Apache Hudi,Databricks 提出了 Delta Lake,而 Netflix 則發(fā)起了 Apache Iceberg 項(xiàng)目,一時(shí)間這種具備 ACID 能力的表格式中間件成為了大數(shù)據(jù)、數(shù)據(jù)湖領(lǐng)域炙手可熱的方向。
我們曾經(jīng)在之前曾經(jīng)介紹過數(shù)據(jù)湖的概念和具體應(yīng)用:
關(guān)于數(shù)據(jù)倉庫、數(shù)據(jù)湖、數(shù)據(jù)平臺和數(shù)據(jù)中臺的概念和區(qū)別
企業(yè)數(shù)據(jù)湖構(gòu)建和分析方案
為什么選擇 Iceberg?
談及引入 Iceberg 的原因,在構(gòu)建大數(shù)據(jù)生態(tài)的過程中遇到的一些痛點(diǎn) Iceberg 恰好能解決:
T+0 的數(shù)據(jù)落地和處理。傳統(tǒng)的數(shù)據(jù)處理流程從數(shù)據(jù)入庫到數(shù)據(jù)處理通常需要一個(gè)較長的環(huán)節(jié)、涉及許多復(fù)雜的邏輯來保證數(shù)據(jù)的一致性,由于架構(gòu)的復(fù)雜性使得整個(gè)流水線具有明顯的延遲。Iceberg 的 ACID 能力可以簡化整個(gè)流水線的設(shè)計(jì),降低整個(gè)流水線的延遲。
降低數(shù)據(jù)修正的成本。傳統(tǒng) Hive/Spark 在修正數(shù)據(jù)時(shí)需要將數(shù)據(jù)讀取出來,修改后再寫入,有極大的修正成本。Iceberg 所具有的修改、刪除能力能夠有效地降低開銷,提升效率。
至于為何最終選擇采用 Iceberg,而不是其他兩個(gè)開源項(xiàng)目,技術(shù)方面的考量主要有以下幾點(diǎn):
Iceberg 的架構(gòu)和實(shí)現(xiàn)并未綁定于某一特定引擎,它實(shí)現(xiàn)了通用的數(shù)據(jù)組織格式,利用此格式可以方便地與不同引擎(如 Flink、Hive、Spark)對接,這對于騰訊內(nèi)部落地是非常重要的,因?yàn)樯舷掠螖?shù)據(jù)管道的銜接往往涉及到不同的計(jì)算引擎;
良好的架構(gòu)和開放的格式。相比于 Hudi、Delta Lake,Iceberg 的架構(gòu)實(shí)現(xiàn)更為優(yōu)雅,同時(shí)對于數(shù)據(jù)格式、類型系統(tǒng)有完備的定義和可進(jìn)化的設(shè)計(jì);
面向?qū)ο蟠鎯Φ膬?yōu)化。Iceberg 在數(shù)據(jù)組織方式上充分考慮了對象存儲的特性,避免耗時(shí)的 listing 和 rename 操作,使其在基于對象存儲的數(shù)據(jù)湖架構(gòu)適配上更有優(yōu)勢。
除去技術(shù)上的考量,代碼質(zhì)量、社區(qū)等方面詳細(xì)的評估如下:
整體的代碼質(zhì)量以及未來的進(jìn)化能力。整體架構(gòu)代碼上的抽象和優(yōu)勢,以及這些優(yōu)勢對于未來進(jìn)行演化的能力是團(tuán)隊(duì)非常關(guān)注的。一門技術(shù)需要能夠在架構(gòu)上持續(xù)演化,而不會具體實(shí)現(xiàn)上需要大量的不兼容重構(gòu)才能支持。
社區(qū)的潛力以及騰訊能夠在社區(qū)發(fā)揮的價(jià)值。社區(qū)的活躍度是另一個(gè)考量,更重要的是在這個(gè)社區(qū)中騰訊能做些什么,能發(fā)揮什么樣的價(jià)值。如果社區(qū)相對封閉或已經(jīng)足夠成熟,那么騰訊再加入后能發(fā)揮的價(jià)值就沒有那么大了,在選擇技術(shù)時(shí)這也是團(tuán)隊(duì)的一個(gè)重要考量點(diǎn)。
技術(shù)的中立性和開放性。社區(qū)能夠以開放的態(tài)度去推動(dòng)技術(shù)的演化,而不是有所保留地向社區(qū)貢獻(xiàn),同時(shí)社區(qū)各方相對中立而沒有一個(gè)相對的強(qiáng)勢方來完全控制社區(qū)的演進(jìn)。
騰訊對Iceberg的優(yōu)化和改進(jìn)
從正式投入研發(fā)到現(xiàn)在,騰訊在開源版本的基礎(chǔ)上對 Iceberg 進(jìn)行了一些優(yōu)化和改進(jìn),主要包括:
實(shí)現(xiàn)了行級的刪除和更新操作,極大地節(jié)省了數(shù)據(jù)修正和刪除所帶來的開銷;
對 Spark 3.0 的 DataSource V2 進(jìn)行了適配,使用 Spark 3.0 的 SQL 和 DataFrame 可以無縫對接 Iceberg 進(jìn)行操作;
增加了對 Flink 的支持,可以對接 Flink 以 Iceberg 的格式進(jìn)行數(shù)據(jù)落地。
這些改進(jìn)點(diǎn)提高了 Iceberg 在落地上的可用性,也為它在騰訊內(nèi)部落地提供了更為吸引人的特性。同時(shí)騰訊也在積極擁抱社區(qū),大部分的內(nèi)部改進(jìn)都已推往社區(qū),一些內(nèi)部定制化的需求也會以更為通用的方式貢獻(xiàn)回社區(qū)。
目前團(tuán)隊(duì)正在積極嘗試將 Iceberg 融入到騰訊的大數(shù)據(jù)生態(tài)中,其中最主要的挑戰(zhàn)在于如何與騰訊現(xiàn)有系統(tǒng)以及自研系統(tǒng)適配,以及如何在一個(gè)成熟的大數(shù)據(jù)體系中尋找落地點(diǎn)并帶來明顯的收益。
Iceberg 的上下游配套能力的建設(shè)相對缺乏,需要較多的配套能力的建設(shè),比如 Spark、Hive、Flink 等不同引擎的適配;
其次是 Iceberg 核心能力成熟度的驗(yàn)證,它是否能夠支撐起騰訊大數(shù)據(jù)量級的考驗(yàn),其所宣稱的能力是否真正達(dá)到了企業(yè)級可用,都需要進(jìn)一步驗(yàn)證和加強(qiáng);
最后,騰訊內(nèi)部大數(shù)據(jù)經(jīng)過多年發(fā)展,已經(jīng)形成了一整套完整的數(shù)據(jù)接入分析方案,Iceberg 如何能夠在內(nèi)部落地,優(yōu)化現(xiàn)有的方案非常重要。
典型實(shí)踐
Flink 集成 Iceberg 在同程藝龍的實(shí)踐
痛點(diǎn)
由于采用的是列式存儲格式 ORC,無法像行式存儲格式那樣進(jìn)行追加操作,所以不可避免的產(chǎn)生了一個(gè)大數(shù)據(jù)領(lǐng)域非常常見且非常棘手的問題,即 HDFS 小文件問題。
Flink+Iceberg 的落地
Iceberg 技術(shù)調(diào)研
基于 HDFS 小文件、查詢慢等問題,結(jié)合我們的現(xiàn)狀,我調(diào)研了目前市面上的數(shù)據(jù)湖技術(shù):Delta、Apache Iceberg 和 Apache Hudi,考慮了目前數(shù)據(jù)湖框架支持的功能和以后的社區(qū)規(guī)劃,最終我們是選擇了 Iceberg,其中考慮的原因有以下幾方面:
Iceberg 深度集成 Flink
我們的絕大部分任務(wù)都是 Flink 任務(wù),包括批處理任務(wù)和流處理任務(wù),目前這三個(gè)數(shù)據(jù)湖框架,Iceberg 是集成 Flink 做的最完善的,如果采用 Iceberg 替代 Hive 之后,遷移的成本非常小,對用戶幾乎是無感知的,
比如我們原來的 SQL 是這樣的:
INSERT INTO hive_catalog.db.hive_table SELECT * FROM kafka_table
遷移到 Iceberg 以后,只需要修改 catalog 就行。
INSERT INTO iceberg_catalog.db.iIcebergceberg_table SELECT * FROM kafka_table
Presto 查詢也是和這個(gè)類似,只需要修改 catalog 就行了。
Iceberg 的設(shè)計(jì)架構(gòu)使得查詢更快
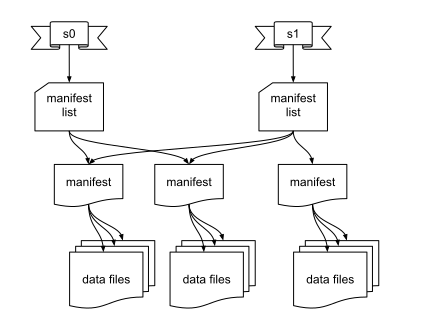
在 Iceberg 的設(shè)計(jì)架構(gòu)中,manifest 文件存儲了分區(qū)相關(guān)信息、data files 的相關(guān)統(tǒng)計(jì)信息(max/min)等,去查詢一些大的分區(qū)的數(shù)據(jù),就可以直接定位到所要的數(shù)據(jù),而不是像 Hive 一樣去 list 整個(gè) HDFS 文件夾,時(shí)間復(fù)雜度從 O(n)降到了 O(1),使得一些大的查詢速度有了明顯的提升,在 Iceberg PMC Chair Ryan Blue 的演講中,我們看到命中 filter 的任務(wù)執(zhí)行時(shí)間從 61.5 小時(shí)降到了 22 分鐘。
使用 Flink SQL 將 CDC 數(shù)據(jù)寫入 Iceberg:Flink CDC 提供了直接讀取 MySQL binlog 的方式,相對以前需要使用 canal 讀取 binlog 寫入 Iceberg,然后再去消費(fèi) Iceberg 數(shù)據(jù)。少了兩個(gè)組件的維護(hù),鏈路減少了,節(jié)省了維護(hù)的成本和出錯(cuò)的概率。并且可以實(shí)現(xiàn)導(dǎo)入全量數(shù)據(jù)和增量數(shù)據(jù)的完美對接,所以使用 Flink SQL 將 MySQL binlog 數(shù)據(jù)導(dǎo)入 Iceberg 來做 MySQL->Iceberg 的導(dǎo)入將會是一件非常有意義的事情。
此外對于我們最初的壓縮小文件的需求,雖然 Iceberg 目前還無法實(shí)現(xiàn)自動(dòng)壓縮,但是它提供了一個(gè)批處理任務(wù),已經(jīng)能滿足我們的需求。
Iceberg 優(yōu)化實(shí)踐
壓縮小文件
代碼示例參考:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Actions.forTable(env, table)
.rewriteDataFiles()
//.maxParallelism(parallelism)
//.filter(Expressions.equal("day", day))
//.targetSizeInBytes(targetSizeInBytes)
.execute();
目前系統(tǒng)運(yùn)行穩(wěn)定,已經(jīng)完成了幾萬次任務(wù)的壓縮。
查詢優(yōu)化
批處理定時(shí)任務(wù)
/home/flink/bin/fFlinklinklink run -p 10 -m yarn-cluster /home/work/iceberg-scheduler.jar my.sql
批任務(wù)的查詢這塊,我做了一些優(yōu)化工作,比如 limit 下推,filter 下推,查詢并行度推斷等,可以大大提高查詢的速度,這些優(yōu)化都已經(jīng)推回給社區(qū),并且在 Iceberg 0.11 版本中發(fā)布。
運(yùn)維管理
清理 orphan 文件
快照過期處理
數(shù)據(jù)管理
Flink + Iceberg 全場景實(shí)時(shí)數(shù)倉的建設(shè)實(shí)踐
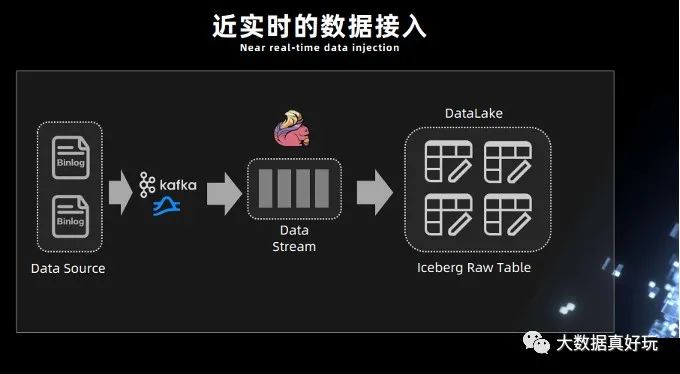
1.近實(shí)時(shí)的數(shù)據(jù)接入
Iceberg 既支持讀寫分離,又支持并發(fā)讀、增量讀、小文件合并,還可以支持秒級到分鐘級的延遲,基于這些優(yōu)勢我們嘗試采用 Iceberg 這些功能來構(gòu)建基于 Flink 的實(shí)時(shí)全鏈路批流一體化的實(shí)時(shí)數(shù)倉架構(gòu)。
如下圖所示,Iceberg 每次的 commit 操作,都是對數(shù)據(jù)的可見性的改變,比如說讓數(shù)據(jù)從不可見變成可見,在這個(gè)過程中,就可以實(shí)現(xiàn)近實(shí)時(shí)的數(shù)據(jù)記錄。
2.實(shí)時(shí)數(shù)倉 - 數(shù)據(jù)湖分析系統(tǒng)
此前需要先進(jìn)行數(shù)據(jù)接入,比如用 Spark 的離線調(diào)度任務(wù)去跑一些數(shù)據(jù),拉取,抽取最后再寫入到 Hive 表里面,這個(gè)過程的延時(shí)比較大。有了 Iceberg 的表結(jié)構(gòu),可以中間使用 Flink,或者 spark streaming,完成近實(shí)時(shí)的數(shù)據(jù)接入。
Iceberg 既然能夠作為一個(gè)優(yōu)秀的表格式,既支持 Streaming reader,又可以支持 Streaming sink,是否可以考慮將 Kafka 替換成 Iceberg?
Iceberg 底層依賴的存儲是像 HDFS 或 S3 這樣的廉價(jià)存儲,而且 Iceberg 是支持 parquet、orc、Avro 這樣的列式存儲。有列式存儲的支持,就可以對 OLAP 分析進(jìn)行基本的優(yōu)化,在中間層直接進(jìn)行計(jì)算。例如謂詞下推最基本的 OLAP 優(yōu)化策略,基于 Iceberg snapshot 的 Streaming reader 功能,可以把離線任務(wù)天級別到小時(shí)級別的延遲大大的降低,改造成一個(gè)近實(shí)時(shí)的數(shù)據(jù)湖分析系統(tǒng)。
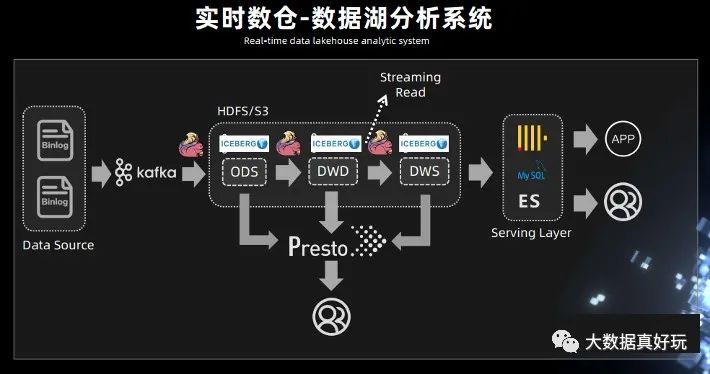
在中間處理層,可以用 presto 進(jìn)行一些簡單的查詢,因?yàn)?Iceberg 支持 Streaming read,所以在系統(tǒng)的中間層也可以直接接入 Flink,直接在中間層用 Flink 做一些批處理或者流式計(jì)算的任務(wù),把中間結(jié)果做進(jìn)一步計(jì)算后輸出到下游。
Iceberg 替換 Kafka 的優(yōu)勢主要包括:
實(shí)現(xiàn)存儲層的流批統(tǒng)一
中間層支持 OLAP 分析
完美支持高效回溯
存儲成本降低
在 Iceberg 底層支持 Alluxio 這樣一個(gè)緩存,借助于緩存的能力可以實(shí)現(xiàn)數(shù)據(jù)湖的加速。
3.最佳實(shí)踐
實(shí)時(shí)小文件合并
Flink 實(shí)時(shí)增量讀取
SQL Extension 管理文件
Flink + Iceberg 在去哪兒的實(shí)時(shí)數(shù)倉實(shí)踐
1. 小文件處理
Iceberg 0.11 以前,通過定時(shí)觸發(fā) batch api 進(jìn)行小文件合并,這樣雖然能合并,但是需要維護(hù)一套 Actions 代碼,而且也不是實(shí)時(shí)合并的。
Table table = findTable(options, conf); Actions.forTable(table).rewriteDataFiles() .targetSizeInBytes(10 * 1024) // 10KB .execute();
Iceberg 0.11 新特性,支持了流式小文件合并。
通過分區(qū)/存儲桶鍵使用哈希混洗方式寫數(shù)據(jù)、從源頭直接合并文件,這樣的好處在于,一個(gè) task 會處理某個(gè)分區(qū)的數(shù)據(jù),提交自己的 Datafile 文件,比如一個(gè) task 只處理對應(yīng)分區(qū)的數(shù)據(jù)。這樣避免了多個(gè) task 處理提交很多小文件的問題,且不需要額外的維護(hù)代碼,只需在建表的時(shí)候指定屬性 write.distribution-mode,該參數(shù)與其它引擎是通用的,比如 Spark 等。
CREATE TABLE city_table ( province BIGINT, city STRING ) PARTITIONED BY (province, city) WITH ( 'write.distribution-mode'='hash' );
2. Iceberg 0.11 排序
2.1 排序介紹
在 Iceberg 0.11 之前,F(xiàn)link 是不支持 Iceberg 排序功能的,所以之前只能結(jié)合 Spark 以批模式來支持排序功能,0.11 新增了排序特性的支持,也意味著,我們在實(shí)時(shí)也可以體會到這個(gè)好處。
排序的本質(zhì)是為了掃描更快,因?yàn)榘凑?sort key 做了聚合之后,所有的數(shù)據(jù)都按照從小到大排列,max-min 可以過濾掉大量的無效數(shù)據(jù)。

2.2 排序 demo
insert into Iceberg_table select days from Kafka_tbl order by days, province_id;
3. Iceberg 排序后 manifest 詳解
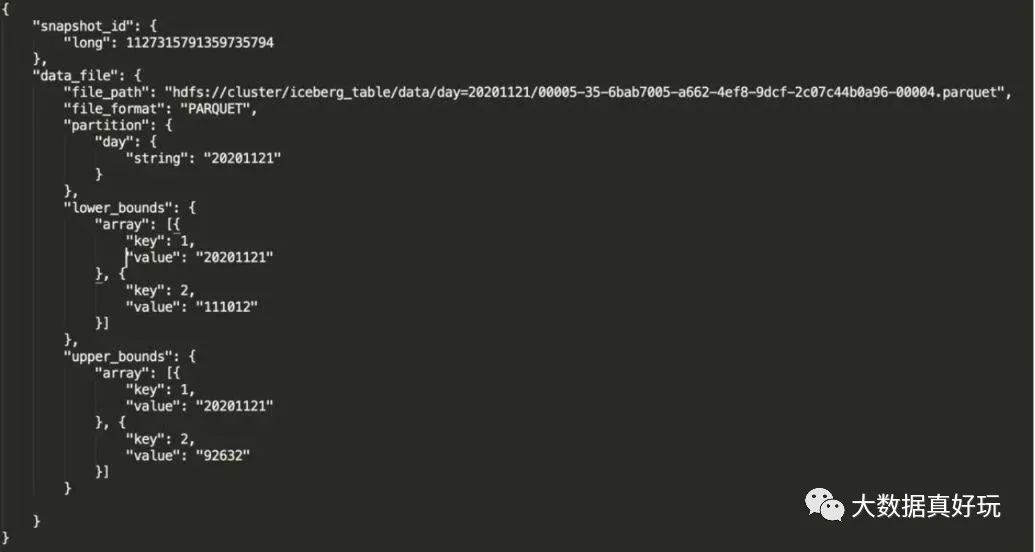
參數(shù)解釋
file_path:物理文件位置。
partition:文件所對應(yīng)的分區(qū)。
lower_bounds:該文件中,多個(gè)排序字段的最小值,下圖是我的 days 和 province_id 最小值。
upper_bounds:該文件中,多個(gè)排序字段的最大值,下圖是我的 days 和 province_id 最大值。
通過分區(qū)、列的上下限信息來確定是否讀取 file_path 的文件,數(shù)據(jù)排序后,文件列的信息也會記錄在元數(shù)據(jù)中,查詢計(jì)劃從 manifest 去定位文件,不需要把信息記錄在 Hive metadata,從而減輕 Hive metadata 壓力,提升查詢效率。
利用 Iceberg 0.11 的排序特性,將天作為分區(qū)。按天、小時(shí)、分鐘進(jìn)行排序,那么 manifest 文件就會記錄這個(gè)排序規(guī)則,從而在檢索數(shù)據(jù)的時(shí)候,提高查詢效率,既能實(shí)現(xiàn) Hive 分區(qū)的檢索優(yōu)點(diǎn),還能避免 Hive metadata 元數(shù)據(jù)過多帶來的壓力。
基于 Flink+Iceberg 構(gòu)建企業(yè)級實(shí)時(shí)數(shù)據(jù)湖
目前 Apache Iceberg 0.10.0 版本上實(shí)現(xiàn) Flink 流批入湖功能,同時(shí)還支持 Flink 批作業(yè)查詢 Iceberg 數(shù)據(jù)湖的數(shù)據(jù)。
我們知道,F(xiàn)link iceberg sink 的設(shè)計(jì)原理是由 Iceberg 采用樂觀鎖的方式來實(shí)現(xiàn) Transaction 的提交,也就是說兩個(gè)人同時(shí)提交更改事務(wù)到 Iceberg 時(shí),后開始的一方會不斷重試,等先開始的一方順利提交之后再重新讀取 metadata 信息提交 transaction。考慮到這一點(diǎn),采用多個(gè)并發(fā)算子去提交 transaction 是不合適的,容易造成大量事務(wù)沖突,導(dǎo)致重試。
所以,把 Flink 寫入流程拆成了兩個(gè)算子,一個(gè)叫做 IcebergStreamWriter,主要用來寫入記錄到對應(yīng)的 avro、parquet、orc 文件,生成一個(gè)對應(yīng)的 Iceberg DataFile,并發(fā)送給下游算子;另外一個(gè)叫做 IcebergFilesCommitter,主要用來在 checkpoint 到來時(shí)把所有的 DataFile 文件收集起來,并提交 Transaction 到 Apache iceberg,完成本次 checkpoint 的數(shù)據(jù)寫入。
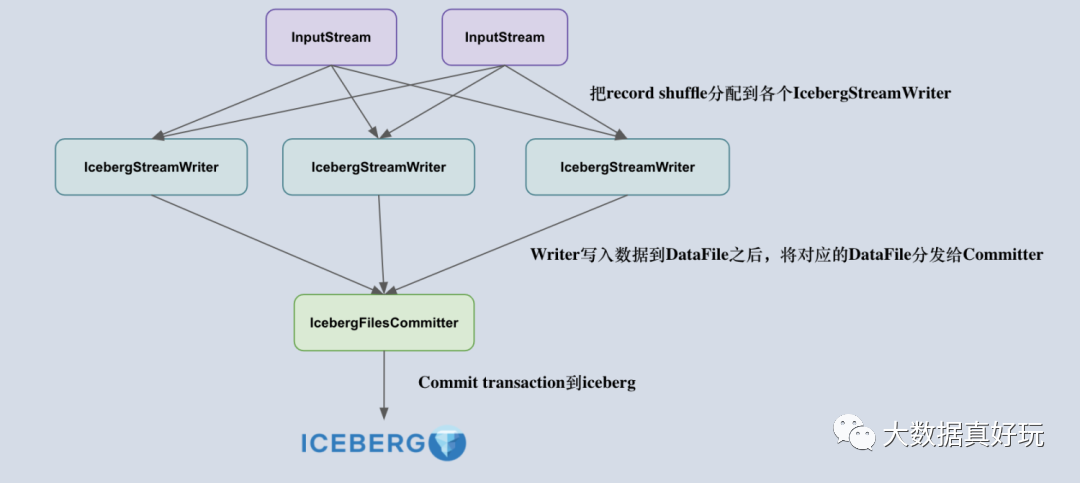
理解了 Flink Sink 算子的設(shè)計(jì)后,下一個(gè)比較重要的問題就是:如何正確地設(shè)計(jì)兩個(gè)算子的 state ?
首先,IcebergStreamWriter 的設(shè)計(jì)比較簡單,主要任務(wù)是把記錄轉(zhuǎn)換成 DataFile,并沒有復(fù)雜的 State 需要設(shè)計(jì)。IcebergFilesCommitter 相對復(fù)雜一點(diǎn),它為每個(gè) checkpointId 維護(hù)了一個(gè) DataFile 文件列表,即 map>,這樣即使中間有某個(gè) checkpoint 的 transaction 提交失敗了,它的 DataFile 文件仍然維護(hù)在 State 中,依然可以通過后續(xù)的 checkpoint 來提交數(shù)據(jù)到 Iceberg 表中。
Iceberg0.11 與 Spark3.0 結(jié)合
1.安裝編譯 Iceberg0.11
此處我下載的是 Iceberg0.11.1 版本需要提前安裝 gradle,iceberg 的編譯,此處使用的是 gradle5.4.1 版本
wget https://downloads.gradle.org/distributions/gradle-5.4-bin.zip
unzip -d /opt/gradle gradle-5.4-bin.zip
vim /etc/profile
# 加入下面的
#GREDLE
export GRADLE_HOME=/opt/gradle/gradle-5.4
export PATH=$PATH:$GRADLE_HOME/bin
source /etc/profile
編譯 Iceberg,github 上下載源碼進(jìn)行編譯,此處略過下載過程直接進(jìn)行編譯
cd iceberg-apache-iceberg-0.11.1
gradle build -x test
2. Iceberg 編譯與 SparkSQL 相結(jié)合
2.1 上述編譯成功后到 spark3 目錄下取出我們所需的 jar 包
cd spark3-runtime/build/libs
ll

iceberg-spark3-runtime-0.11.1.jar 為我們所需的插件包
2.2 將插件包放入到 spark 目錄下
cd $SPARK_HOME/jars
cp iceberg-apache-iceberg-0.11.1/spark3-runtime/build/libs/iceberg-spark3-runtime-0.11.1.jar .
2.3 修改 spark 相應(yīng)的配置
模式一:用 hadoop 當(dāng)元數(shù)據(jù)
在 spark-defaults.confspark.sql.catalog.iceberg=org.apache.iceberg.spark.SparkCatalogspark.sql.catalog.iceberg.type=hadoopmapreduce.output.fileoutputformat.outputdir=/tmpspark.sql.catalog.iceberg.warehouse=hdfs://mycluster/iceberg/warehouse
模式二:元數(shù)據(jù)共用 hive.metastore
在 spark-defaults.confspark.sql.catalog.hive_iceberg = org.apache.iceberg.spark.SparkCatalogspark.sql.catalog.hive_iceberg.type = hivespark.sql.catalog.hive_iceberg.uri = thrift://node182:9083
下面的例子都是按模式二:元數(shù)據(jù)共用 hive.metastore進(jìn)行。
1.spark 進(jìn)行安裝完畢,此處不再詳述,conf 目錄下需要有 hdfs-site.xml,core-site.xml,mared-reduce.xml,hive-site.xml,yarn-site.xml,這里就不多描述了
2.在 spark-defaults.conf 下加入下面的語句
spark.sql.catalog.iceberg = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.iceberg.type = hive
spark.sql.catalog.iceberg.uri = thrift://node182:9083
其中 spark.sql.catalog.iceberg.uri 是參照 hive-site.xml 中配置 spark.sql.catalog.iceberg,其中的 iceberg 為 namespace 的意思命名空間,下面我們創(chuàng)建 database 都要在此命名空間之下。
<property>
<name>hive.metastore.uris</name>
<value>thrift://172.16.129.182:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
2.4 啟動(dòng) Spark
1)啟動(dòng) Spark 的 thriftserver 服務(wù)
sh start-thriftserver.sh --master yarn
2)用 beeline 進(jìn)行連接
bin/beeline
!connect jdbc:hive2://node182:25001 spark spark

此處連接的端口號從 hive-site.xml 中配置讀取
<property>
<name>hive.server2.thrift.port</name>
<value>25001</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
2.5 創(chuàng)建 iceberg 源表
1)創(chuàng)建 database
create database iceberg.jzhou_test;

想看當(dāng)前 namespace 用下面命令
show current namespace;

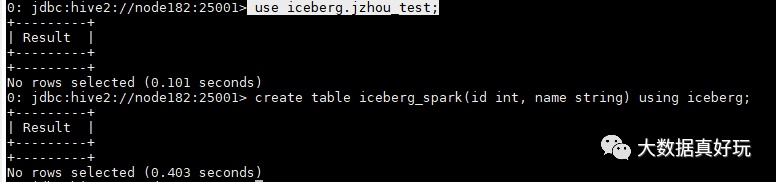
2)創(chuàng)建 iceberg 源的表
use iceberg.jzhou_test;
create table iceberg_spark(id int, name string) using iceberg;
可以修改底層 file_format,此處默認(rèn)為 parquet,但是我想修改為 orc,兩種方法:
方法一:
ALTER TABLE iceberg_spark SET TBLPROPERTIES('write.format.default' = 'orc');
方法二:
create table iceberg_spark(id int, name string) using iceberg TBLPROPERTIES ('write.format.default' = 'orc');
3)插入數(shù)據(jù),并看 hdfs 上表的元數(shù)據(jù)
元數(shù)據(jù)所在 hdfs 目錄可以從 hive-site.xml 的配置中得到:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
看到 hdfs 上數(shù)據(jù)與元數(shù)據(jù)
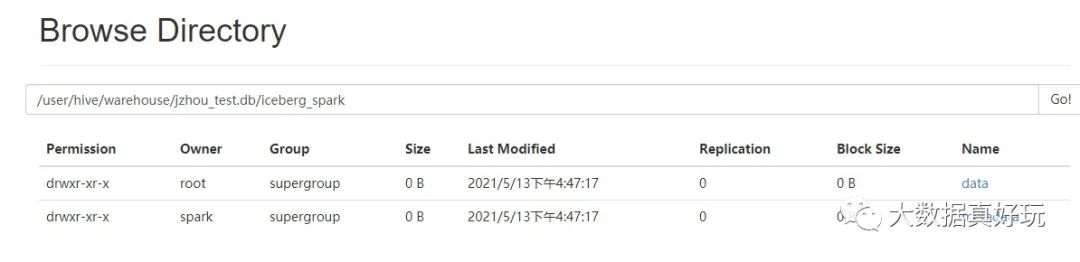

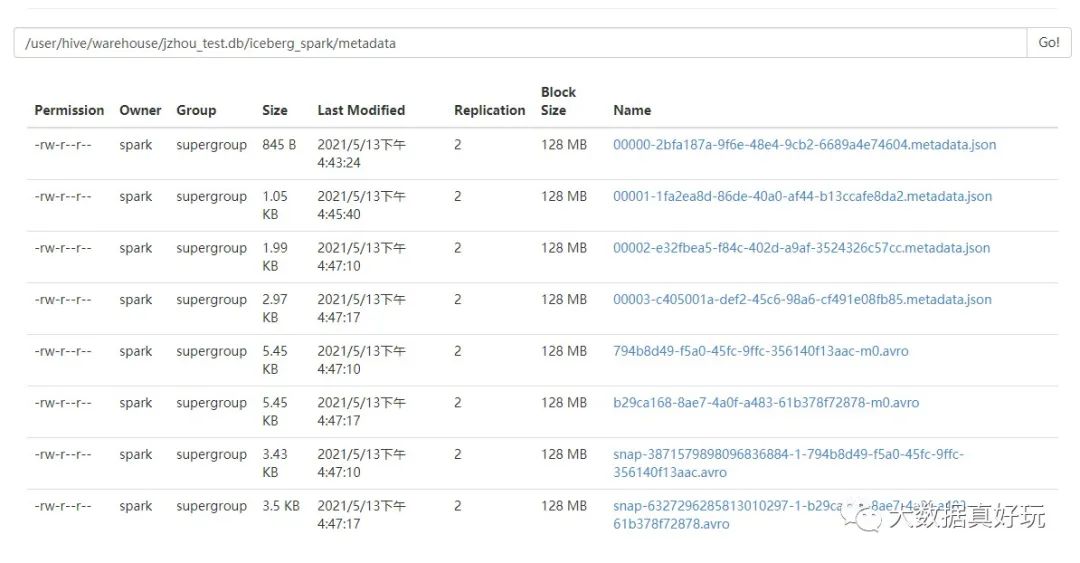
總結(jié)
IceBerg目前在高速迭代中,越來越多大公司加入到了 Iceberg 的貢獻(xiàn)中,包括 Netflix、Apple、Adobe、Expedia 等國外大廠,也包括騰訊、阿里、網(wǎng)易等國內(nèi)公司。一個(gè)好的技術(shù)架構(gòu)最終會得到更多人的認(rèn)可。隨著國內(nèi)推廣的增多,以及國內(nèi)開發(fā)者在這個(gè)項(xiàng)目上的投入、運(yùn)營,未來在國內(nèi) Iceberg 前景可期。

企業(yè)數(shù)據(jù)湖構(gòu)建和分析方案
關(guān)于數(shù)據(jù)倉庫、數(shù)據(jù)湖、數(shù)據(jù)平臺和數(shù)據(jù)中臺的概念和區(qū)別
騰訊數(shù)據(jù)湖實(shí)踐 | IceBerg在騰訊的優(yōu)化和實(shí)踐