
【小白學(xué)PyTorch】8.實戰(zhàn)之MNIST小試牛刀
<<小白學(xué)PyTorch>>
小白學(xué)PyTorch | 7 最新版本torchvision.transforms常用API翻譯與講解
小白學(xué)PyTorch | 6 模型的構(gòu)建訪問遍歷存儲(附代碼)
小白學(xué)PyTorch | 5 torchvision預(yù)訓(xùn)練模型與數(shù)據(jù)集全覽
小白學(xué)PyTorch | 4 構(gòu)建模型三要素與權(quán)重初始化
小白學(xué)PyTorch | 3 淺談Dataset和Dataloader
小白學(xué)PyTorch | 2 淺談訓(xùn)練集驗證集和測試集
小白學(xué)PyTorch | 1 搭建一個超簡單的網(wǎng)絡(luò)
小白學(xué)PyTorch | 動態(tài)圖與靜態(tài)圖的淺顯理解
參考目錄:
1 探索性數(shù)據(jù)分析
1.1 數(shù)據(jù)集基本信息
1.2 數(shù)據(jù)集可視化
1.3 類別是否均衡
2 訓(xùn)練與推理
2.1 構(gòu)建dataset
2.2 構(gòu)建模型類
2.3 訓(xùn)練模型
2.4 推理預(yù)測
1 探索性數(shù)據(jù)分析
一般在進(jìn)行模型訓(xùn)練之前,都要做一個數(shù)據(jù)集分析的任務(wù)。這個在英文中一般縮寫為EDA,也就是Exploring Data Analysis(好像是這個)。
數(shù)據(jù)集獲取方面,這里本來是要使用之前課程提到的torchvision.datasets.MNIST(),但是考慮到這個torchvision提供的MNIST完整下載下來需要200M的大小,所以我就直接提供了MNIST的數(shù)據(jù)的CSV文件(包含train.csv和test.csv),大小壓縮成.zip之后只有14M,代碼就基于了這個數(shù)據(jù)文件。
1.1 數(shù)據(jù)集基本信息
import?pandas?as?pd
#?讀取訓(xùn)練集
train_df?=?pd.read_csv('./MNIST_csv/train.csv')
n_train?=?len(train_df)
n_pixels?=?len(train_df.columns)?-?1
n_class?=?len(set(train_df['label']))
print('Number?of?training?samples:?{0}'.format(n_train))
print('Number?of?training?pixels:?{0}'.format(n_pixels))
print('Number?of?classes:?{0}'.format(n_class))
#?讀取測試集
test_df?=?pd.read_csv('./MNIST_csv/test.csv')
n_test?=?len(test_df)
n_pixels?=?len(test_df.columns)
print('Number?of?test?samples:?{0}'.format(n_test))
print('Number?of?test?pixels:?{0}'.format(n_pixels))
輸出結(jié)果: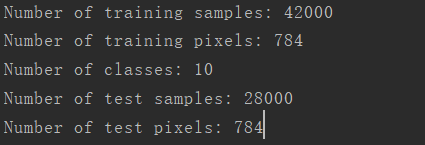
訓(xùn)練集有42000個圖片,每個圖片有784個像素(所以變成圖片的話需要將784的像素變成),樣本總共有10個類別,也就是0到9。測試集中有28000個樣本。
1.2 數(shù)據(jù)集可視化
#?展示一些圖片
import?numpy?as?np
from?torchvision.utils?import?make_grid
import?torch
import?matplotlib.pyplot?as?plt
random_sel?=?np.random.randint(len(train_df),?size=8)
data?=?(train_df.iloc[random_sel,1:].values.reshape(-1,1,28,28)/255.)
grid?=?make_grid(torch.Tensor(data),?nrow=8)
plt.rcParams['figure.figsize']?=?(16,?2)
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.axis('off')
plt.show()
print(*list(train_df.iloc[random_sel,?0].values),?sep?=?',?')
輸出結(jié)果有一個圖片:
以及一行打印: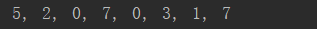
隨機(jī)挑選了8個樣本進(jìn)行可視化,然后打印出來的是樣本對應(yīng)的標(biāo)簽值。
1.3 類別是否均衡
然后我們需要檢查一下訓(xùn)練樣本中類別是否均衡,利用直方圖來檢查:
#?檢查類別是否不均衡
plt.figure(figsize=(8,5))
plt.bar(train_df['label'].value_counts().index,?train_df['label'].value_counts())
plt.xticks(np.arange(n_class))
plt.xlabel('Class',?fontsize=16)
plt.ylabel('Count',?fontsize=16)
plt.grid('on',?axis='y')
plt.show()
輸出圖像: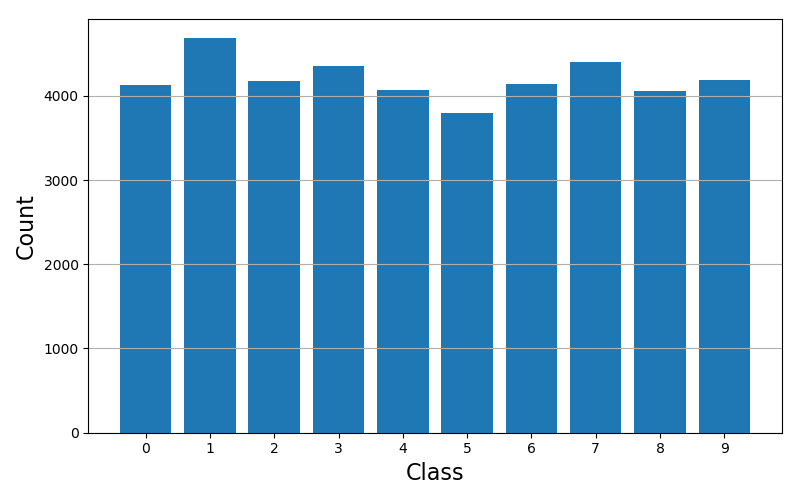
基本沒毛病,是均衡的。
2 訓(xùn)練與推理
2.1 構(gòu)建dataset
我們可以重新寫一個python腳本,首先還是導(dǎo)入庫和讀取文件:
import?pandas?as?pd
train_df?=?pd.read_csv('./MNIST_csv/train.csv')
test_df?=?pd.read_csv('./MNIST_csv/test.csv')
n_train?=?len(train_df)
n_test?=?len(test_df)
n_pixels?=?len(train_df.columns)?-?1
n_class?=?len(set(train_df['label']))
然后構(gòu)建一個Dataset,Dataset和Dataloader的知識前面的課程已經(jīng)講過了,這里直接構(gòu)建一個:
import?torch
from?torch.utils.data?import?Dataset,DataLoader
from?torchvision?import?transforms
class?MNIST_data(Dataset):
????def?__init__(self,?file_path,
?????????????????transform=transforms.Compose([transforms.ToPILImage(),?transforms.ToTensor(),
???????????????????????????????????????????????transforms.Normalize(mean=(0.5,),?std=(0.5,))])
?????????????????):
????????df?=?pd.read_csv(file_path)
????????if?len(df.columns)?==?n_pixels:
????????????#?test?data
????????????self.X?=?df.values.reshape((-1,?28,?28)).astype(np.uint8)[:,?:,?:,?None]
????????????self.y?=?None
????????else:
????????????#?training?data
????????????self.X?=?df.iloc[:,?1:].values.reshape((-1,?28,?28)).astype(np.uint8)[:,?:,?:,?None]
????????????self.y?=?torch.from_numpy(df.iloc[:,?0].values)
????????self.transform?=?transform
????def?__len__(self):
????????return?len(self.X)
????def?__getitem__(self,?idx):
????????if?self.y?is?not?None:
????????????return?self.transform(self.X[idx]),?self.y[idx]
????????else:
????????????return?self.transform(self.X[idx])
可以看到,這個dataset中,根據(jù)是否有標(biāo)簽分成返回兩個不同的值。(訓(xùn)練集的話,同時返回數(shù)據(jù)和標(biāo)簽,測試集中僅僅返回數(shù)據(jù))。
batch_size?=?64
train_dataset?=?MNIST_data('./MNIST_csv/train.csv',
???????????????????????????transform=?transforms.Compose([
????????????????????????????transforms.ToPILImage(),
????????????????????????????transforms.RandomRotation(degrees=20),
????????????????????????????transforms.ToTensor(),
????????????????????????????transforms.Normalize(mean=(0.5,),?std=(0.5,))]))
test_dataset?=?MNIST_data('./MNIST_csv/test.csv')
train_loader?=?torch.utils.data.DataLoader(dataset=train_dataset,
???????????????????????????????????????????batch_size=batch_size,?shuffle=True)
test_loader?=?torch.utils.data.DataLoader(dataset=test_dataset,
???????????????????????????????????????????batch_size=batch_size,?shuffle=False)
關(guān)于這段代碼:
構(gòu)建了一個train的dataset和test的dataset,然后再分別構(gòu)建對應(yīng)的dataloader train_dataset中使用了隨機(jī)旋轉(zhuǎn),因為這個函數(shù)是作用在PIL圖片上的,所以需要將數(shù)據(jù)先轉(zhuǎn)成PIL再進(jìn)行旋轉(zhuǎn),然后轉(zhuǎn)成Tensor做標(biāo)準(zhǔn)化,這里標(biāo)準(zhǔn)化就隨便選取了0.5,有需要的可以做進(jìn)一步的更改。 需要注意的是,轉(zhuǎn)成PIL之前的數(shù)據(jù)是numpy的格式,所以數(shù)據(jù)應(yīng)該是的形式,因為這里是單通道圖像,所以數(shù)據(jù)的shape為:(72000,28,28,1).(72000為樣本數(shù)量) 像是旋轉(zhuǎn)、縮放等圖像增強(qiáng)方法在訓(xùn)練集中才會使用,這是增強(qiáng)模型訓(xùn)練難度的操作,讓模型增加魯棒性;在測試集中常規(guī)情況是不使用旋轉(zhuǎn)、縮放這樣的圖像增強(qiáng)方法的。(訓(xùn)練階段是讓模型學(xué)到內(nèi)容,測試階段主要目的是提高預(yù)測的準(zhǔn)確度,這句話感覺是廢話。。。)
2.2 構(gòu)建模型類
import?torch.nn?as?nn
class?Net(nn.Module):
????def?__init__(self):
????????super(Net,?self).__init__()
????????self.features1?=?nn.Conv2d(1,?32,?kernel_size=3,?stride=1,?padding=1)
????????self.features?=?nn.Sequential(
????????????nn.BatchNorm2d(32),
????????????nn.ReLU(inplace=True),
????????????nn.Conv2d(32,?32,?kernel_size=3,?stride=1,?padding=1),
????????????nn.BatchNorm2d(32),
????????????nn.ReLU(inplace=True),
????????????nn.MaxPool2d(kernel_size=2,?stride=2),
????????????nn.Conv2d(32,?64,?kernel_size=3,?padding=1),
????????????nn.BatchNorm2d(64),
????????????nn.ReLU(inplace=True),
????????????nn.Conv2d(64,?64,?kernel_size=3,?padding=1),
????????????nn.BatchNorm2d(64),
????????????nn.ReLU(inplace=True),
????????????nn.MaxPool2d(kernel_size=2,?stride=2)
????????)
????????self.classifier?=?nn.Sequential(
????????????nn.Dropout(p=0.5),
????????????nn.Linear(64?*?7?*?7,?512),
????????????nn.BatchNorm1d(512),
????????????nn.ReLU(inplace=True),
????????????nn.Dropout(p=0.5),
????????????nn.Linear(512,?512),
????????????nn.BatchNorm1d(512),
????????????nn.ReLU(inplace=True),
????????????nn.Dropout(p=0.5),
????????????nn.Linear(512,?10),
????????)
????????for?m?in?self.modules():
????????????if?isinstance(m,?nn.Conv2d)?or?isinstance(m,?nn.Linear):
????????????????nn.init.xavier_uniform_(m.weight)
????????????elif?isinstance(m,?nn.BatchNorm2d):
????????????????m.weight.data.fill_(1)
????????????????m.bias.data.zero_()
????def?forward(self,?x):
????????x?=?self.features1(x)
????????x?=?self.features(x)
????????x?=?x.view(x.size(0),?-1)
????????x?=?self.classifier(x)
????????return?x
這個模型類整體來看中規(guī)中矩,都是之前講到的方法。小測試:還記得xavier初始化時怎么回事嗎?xavier初始化方法是一個非常常用的方法,在之前的文章中也詳細(xì)的推導(dǎo)了這個。
之后呢,我們對模型實例化,然后給模型的參數(shù)傳到優(yōu)化器中,然后設(shè)置一個學(xué)習(xí)率衰減的策略,學(xué)習(xí)率衰減就是訓(xùn)練的epoch越多,學(xué)習(xí)率就越低的這樣一個方法,在后面的文章中會詳細(xì)講述 。
import?torch.optim?as?optim
device?=?'cuda'?if?torch.cuda.is_available()?else?'cpu'
model?=?Net().to(device)
#?model?=?torchvision.models.resnet50(pretrained=True).to(device)
optimizer?=?optim.Adam(model.parameters(),?lr=0.003)
criterion?=?nn.CrossEntropyLoss().to(device)
exp_lr_scheduler?=?optim.lr_scheduler.StepLR(optimizer,?step_size=7,?gamma=0.1)
print(model)
運行結(jié)果自然是把整個模型打印出來了:
Net(
??(features1):?Conv2d(1,?32,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
??(features):?Sequential(
????(0):?BatchNorm2d(32,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(1):?ReLU(inplace=True)
????(2):?Conv2d(32,?32,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
????(3):?BatchNorm2d(32,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(4):?ReLU(inplace=True)
????(5):?MaxPool2d(kernel_size=2,?stride=2,?padding=0,?dilation=1,?ceil_mode=False)
????(6):?Conv2d(32,?64,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
????(7):?BatchNorm2d(64,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(8):?ReLU(inplace=True)
????(9):?Conv2d(64,?64,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
????(10):?BatchNorm2d(64,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(11):?ReLU(inplace=True)
????(12):?MaxPool2d(kernel_size=2,?stride=2,?padding=0,?dilation=1,?ceil_mode=False)
??)
??(classifier):?Sequential(
????(0):?Dropout(p=0.5,?inplace=False)
????(1):?Linear(in_features=3136,?out_features=512,?bias=True)
????(2):?BatchNorm1d(512,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(3):?ReLU(inplace=True)
????(4):?Dropout(p=0.5,?inplace=False)
????(5):?Linear(in_features=512,?out_features=512,?bias=True)
????(6):?BatchNorm1d(512,?eps=1e-05,?momentum=0.1,?affine=True,?track_running_stats=True)
????(7):?ReLU(inplace=True)
????(8):?Dropout(p=0.5,?inplace=False)
????(9):?Linear(in_features=512,?out_features=10,?bias=True)
??)
)
2.3 訓(xùn)練模型
def?train(epoch):
????model.train()
????for?batch_idx,?(data,?target)?in?enumerate(train_loader):
????????#?讀入數(shù)據(jù)
????????data?=?data.to(device)
????????target?=?target.to(device)
????????#?計算模型預(yù)測結(jié)果和損失
????????output?=?model(data)
????????loss?=?criterion(output,?target)
????????optimizer.zero_grad()?#?計算圖梯度清零
????????loss.backward()?#?損失反向傳播
????????optimizer.step()#?然后更新參數(shù)
????????if?(batch_idx?+?1)?%?50?==?0:
????????????print('Train?Epoch:?{}?[{}/{}?({:.0f}%)]\tLoss:?{:.6f}'.format(
????????????????epoch,?(batch_idx?+?1)?*?len(data),?len(train_loader.dataset),
???????????????????????100.?*?(batch_idx?+?1)?/?len(train_loader),?loss.item()))
???????????????
????exp_lr_scheduler.step()
先定義了一個訓(xùn)練一個epoch的函數(shù),然后下面是訓(xùn)練10個epoch的主函數(shù)代碼。
log?=?[]?#?記錄一下loss的變化情況
n_epochs?=?2
for?epoch?in?range(n_epochs):
????train(epoch)
#?把log化成折線圖
import?matplotlib.pyplot?as?plt
plt.plot(log)
plt.show()
注意注意,這時候會報一個錯誤,我們來看一下,我詳細(xì)標(biāo)注了我個人看報錯時候的一個習(xí)慣: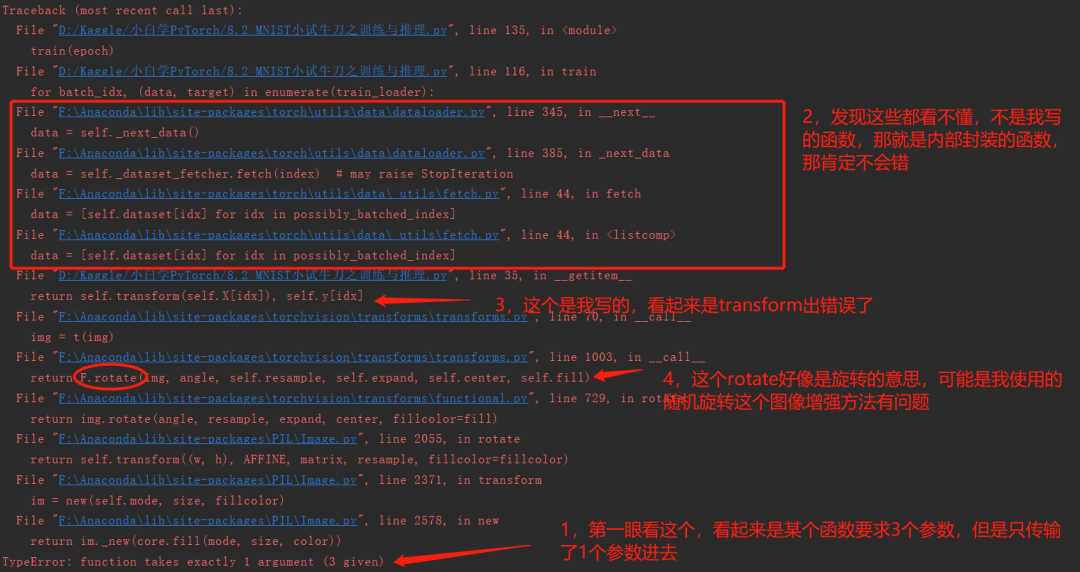
這時候我大概可以猜到,因為我們這個圖片是灰度圖片,是單通道的,可能這個RandomRotate函數(shù)要求輸入圖片是3個通道的(這個官方API上也沒有細(xì)說),怎么辦呢?完全可以直接在轉(zhuǎn)成PIL格式之前,把numpy的那個(72000,28,28,1)復(fù)制第四維度,變成(72000,28,28,3).但是這里我想用上一節(jié)課教的一個方法torchvision.transforms.GrayScale(num_output_channels), 活學(xué)活用嘛.
所以把train_dataset那一塊改成:
train_dataset?=?MNIST_data('./MNIST_csv/train.csv',
???????????????????????????transform=?transforms.Compose([
????????????????????????????transforms.ToPILImage(),
????????????????????????????transforms.Grayscale(num_output_channels=3),
????????????????????????????transforms.RandomRotation(degrees=20),
????????????????????????????transforms.ToTensor(),
????????????????????????????transforms.Normalize(mean=(0.5,),?std=(0.5,))]))
test_dataset?=?MNIST_data('./MNIST_csv/test.csv',
??????????????????????????transform=transforms.Compose([
??????????????????????????????transforms.ToPILImage(),
??????????????????????????????transforms.Grayscale(num_output_channels=3),
??????????????????????????????transforms.ToTensor(),
??????????????????????????????transforms.Normalize(mean=(0.5,),?std=(0.5,))]))
然后不要忘記把模型類中的第一個卷積層的輸入通道改成3哦~
#?self.features1?=?nn.Conv2d(1,?32,?kernel_size=3,?stride=1,?padding=1)
self.features1?=?nn.Conv2d(3,?32,?kernel_size=3,?stride=1,?padding=1)
然后重新運行代碼,發(fā)現(xiàn)可以正常訓(xùn)練了,打印輸出的部分截圖如下: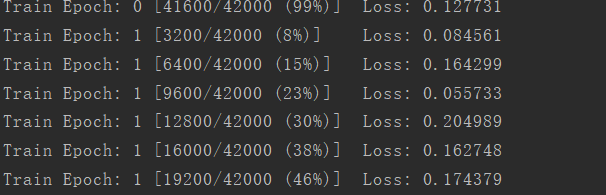
然后看一下?lián)p失下降的情況,算是收斂了,訓(xùn)練的epoch更多應(yīng)該會更好: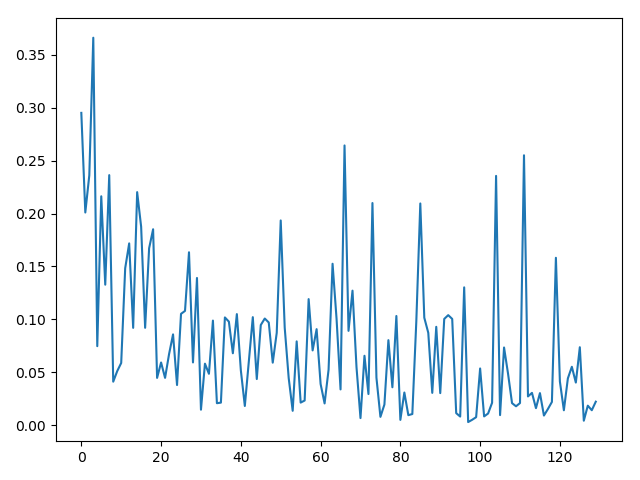 發(fā)現(xiàn)訓(xùn)練是收斂的。這里需要注意的是,現(xiàn)在用全部的數(shù)據(jù)進(jìn)行訓(xùn)練,沒有使用驗證集的做法,是有可能過擬合情況出現(xiàn)的(但是這里只是訓(xùn)練了10個epoch應(yīng)該不會過擬合),更穩(wěn)妥的做法是把數(shù)據(jù)分成訓(xùn)練集和驗證機(jī)(可以是2:1,3:1,4:1)都可以,4:1比較常用,這也就是n-fold的方法。 在之后的學(xué)習(xí)中會詳細(xì)介紹這個,不過這個知識點也不難,也可以自行查閱。
發(fā)現(xiàn)訓(xùn)練是收斂的。這里需要注意的是,現(xiàn)在用全部的數(shù)據(jù)進(jìn)行訓(xùn)練,沒有使用驗證集的做法,是有可能過擬合情況出現(xiàn)的(但是這里只是訓(xùn)練了10個epoch應(yīng)該不會過擬合),更穩(wěn)妥的做法是把數(shù)據(jù)分成訓(xùn)練集和驗證機(jī)(可以是2:1,3:1,4:1)都可以,4:1比較常用,這也就是n-fold的方法。 在之后的學(xué)習(xí)中會詳細(xì)介紹這個,不過這個知識點也不難,也可以自行查閱。
2.4 推理預(yù)測
def?prediciton(data_loader):
????model.eval()
????test_pred?=?torch.LongTensor()
????for?i,?data?in?enumerate(data_loader):
????????data?=?data.to(device)
????????output?=?model(data)
????????pred?=?output.cpu().data.max(1,?keepdim=True)[1]
????????test_pred?=?torch.cat((test_pred,?pred),?dim=0)
????return?test_pred
test_pred?=?prediciton(test_loader)
類似trian,寫一個預(yù)測的函數(shù),返回預(yù)測的值。然后像是在EDA中那樣,抽取測試集的8個數(shù)字,看看圖像和預(yù)測結(jié)果的匹配情況
from?torchvision.utils?import?make_grid
random_sel?=?np.random.randint(len(test_df),?size=8)
data?=?(test_df.iloc[random_sel,:].values.reshape(-1,1,28,28)/255.)
grid?=?make_grid(torch.Tensor(data),?nrow=8)
plt.rcParams['figure.figsize']?=?(16,?2)
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.axis('off')
plt.show()
print(*list(test_pred[random_sel].numpy()),?sep?=?',?')
輸出圖像是: 打印輸出:
打印輸出: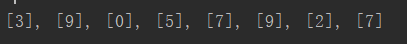
OK了,恭喜你,完成了MNIST手寫數(shù)字集的分類。
- END -往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群請掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請說明):