
3萬字史詩級 Hive 性能調(diào)優(yōu)(建議收藏)

前言
??????? Hive 作為大數(shù)據(jù)領(lǐng)域常用的數(shù)據(jù)倉庫組件,在平時設(shè)計和查詢的時候要特別注意效率 。影響 Hive 效率的幾乎從不是數(shù)據(jù)量過大,而是數(shù)據(jù)傾斜、數(shù)據(jù)冗余、Job或I/O過多、MapReduce 分配不合理等等。 對Hive 的調(diào)優(yōu)既包含 Hive 的建表設(shè)計方面,對 HiveHQL 語句本身的優(yōu)化,也包含 Hive 配置參數(shù) 和 底層引擎 MapReduce 方面的調(diào)整 。
????????本篇文章,我將帶著大家主要從以下四個方面展開。
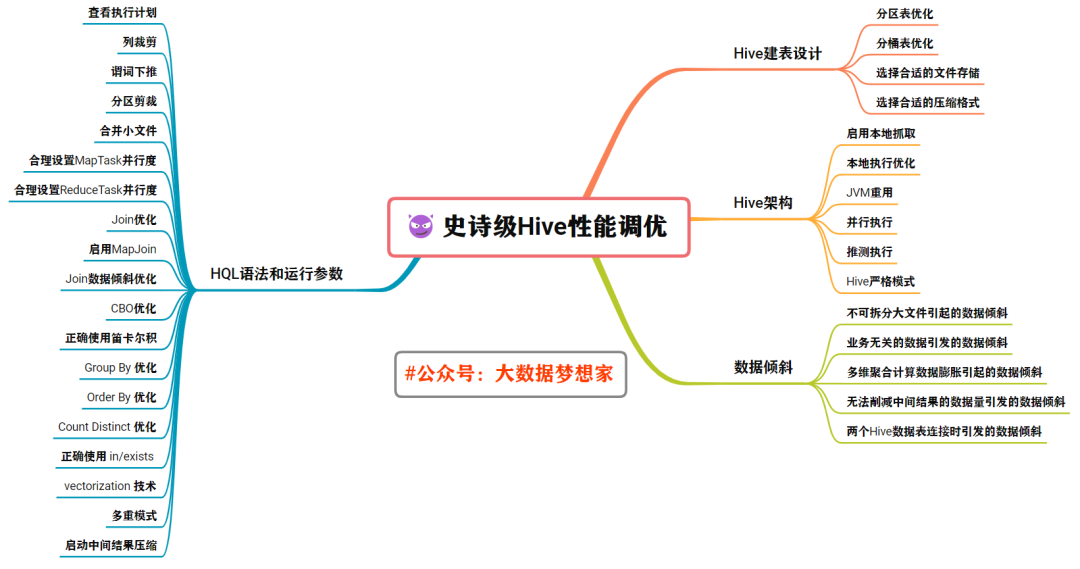 目錄結(jié)構(gòu)
目錄結(jié)構(gòu)
????????內(nèi)容較硬核,建議轉(zhuǎn)發(fā)收藏,分享給更多朋友,文章?PDF?版本已經(jīng)整理好,掃描下方二維碼,添加夢想家微信,備注 Hive 發(fā)你 PDF 版本。
????????為了不盲目地學習,我們需要先知道 Hive 調(diào)優(yōu)的重要性:在保證業(yè)務(wù)結(jié)果不變的前提下,降低資源的使用量,減少任務(wù)的執(zhí)行時間。
調(diào)優(yōu)須知
????????在開始之前,需要對下面的“ 注意事項” 有個大致的印象 。
對于大數(shù)據(jù)計算引擎來說:數(shù)據(jù)量大不是問題,數(shù)據(jù)傾斜是個問題。 Hive的復(fù)雜HQL底層會轉(zhuǎn)換成多個MapReduce Job并行或者串行執(zhí)行,Job數(shù)比較多的作業(yè)運行效率相對比較低,比如即使只有幾百行數(shù)據(jù)的表,如果多次關(guān)聯(lián)多次匯總,產(chǎn)生十幾個Job,耗時很長。原因是 MapReduce 作業(yè)初始化的時間是比較長的 。 在進行Hive大數(shù)據(jù)分析時,常見的聚合操作比如 sum,count,max,min,UDAF等 ,不怕數(shù)據(jù)傾斜問題,MapReduce 在 Mappe階段 的預(yù)聚合操作,使數(shù)據(jù)傾斜不成問題 。 好的建表設(shè)計,模型設(shè)計事半功倍。 設(shè)置合理的 MapReduce 的 Task 并行度,能有效提升性能。(比如,10w+數(shù)據(jù)量 級別的計算,用 100 個 reduceTask,那是相當?shù)睦速M,1個足夠,但是如果是 億級別的數(shù)據(jù)量,那么1個Task又顯得捉襟見肘) 了解數(shù)據(jù)分布,自己動手解決數(shù)據(jù)傾斜問題是個不錯的選擇。這是通用的算法優(yōu)化,但算法優(yōu)化有時不能適應(yīng)特定業(yè)務(wù)背景,開發(fā)人員了解業(yè)務(wù),了解數(shù)據(jù),可以通過業(yè)務(wù)邏輯精確有效地解決數(shù)據(jù)傾斜問題。 數(shù)據(jù)量較大的情況下,慎用 count(distinct),group by 容易產(chǎn)生傾斜問題。 對小文件進行合并,是行之有效地提高調(diào)度效率的方法,假如所有的作業(yè)設(shè)置合理的文件數(shù),對任務(wù)的整體調(diào)度效率也會產(chǎn)生積極的正向影響 。 優(yōu)化時把握整體,單個作業(yè)最優(yōu)不如整體最優(yōu)。
調(diào)優(yōu)具體細節(jié)
????????好了, 下面正式開始談?wù)撜{(diào)優(yōu)過程中的細節(jié)。
Hive建表設(shè)計層面
????????Hive的建表設(shè)計層面調(diào)優(yōu),主要講的怎么樣合理的組織數(shù)據(jù),方便后續(xù)的高效計算。比如建表的類型,文件存儲格式,是否壓縮等等。
利用分區(qū)表優(yōu)化
????????先來回顧一下 hive 的表類型有哪些?
1、分區(qū)表?
2、分桶表
????????分區(qū)表 是在某一個或者幾個維度上對數(shù)據(jù)進行分類存儲,一個分區(qū)對應(yīng)一個目錄。如果篩選條件里有分區(qū)字段,那么 Hive 只需要遍歷對應(yīng)分區(qū)目錄下的文件即可,不需要遍歷全局數(shù)據(jù),使得處理的數(shù)據(jù)量大大減少,從而提高查詢效率 。
????????你也可以這樣理解:當一個 Hive 表的查詢大多數(shù)情況下,會根據(jù)某一個字段進行篩選時,那么非常適合創(chuàng)建為分區(qū)表,該字段即為分區(qū)字段。
????????舉個例子:
select1:?select?....?where?country?=?"china"?
select2:?select?....?where?country?=?"china"?
select3:?select?....?where?country?=?"china"?
select4:?select?....?where?country?=?"china"
????????這就像是分門別類:這個city字段的每個值,就單獨形成為一個分區(qū)。其實每個分區(qū)就對應(yīng)著 HDFS的一個目錄 。在創(chuàng)建表時通過啟用 partitioned by 實現(xiàn),用來 partition 的維度并不是實際數(shù)據(jù)的某一列,具體分區(qū)的標志是由插入內(nèi)容時給定的。當要查詢某一分區(qū)的內(nèi)容時可以采用 where 語句,形似 where tablename.partition_column = a 來實現(xiàn) 。
????????接下來,請嘗試操作一下:
1、創(chuàng)建含分區(qū)的表:
CREATE?TABLE?page_view
?????????????(
??????????????????????????viewTime?INT
????????????????????????,?userid???BIGINT
????????????????????????,?page_url?STRING
????????????????????????,?referrer_url?STRING
????????????????????????,?ip?STRING?COMMENT?'IP?Address?of?the?User'
?????????????)
?????????????PARTITIONED?BY
?????????????(
??????????????????????????date?STRING
????????????????????????,?country?STRING
?????????????)
?????????????ROW?FORMAT?DELIMITED?FIELDS?TERMINATED?BY?'1'?STORED?AS?TEXTFILE
;
2、載入內(nèi)容,并指定分區(qū)標志:
load?data?local?inpath?'/home/bigdata/pv_2018-07-08_us.txt'?into?table?page_view?partition(date='2018-07-08',?country='US');
3、查詢指定標志的分區(qū)內(nèi)容:
SELECT
???????page_views.*
FROM
???????page_views
WHERE
???????page_views.date???????????????>=?'2008-03-01'
???????AND?page_views.date???????????<=?'2008-03-31'
???????AND?page_views.referrer_url?like?'%xyz.com'
;
????????讓我們來簡單總結(jié)一下:
1、當你意識到一個字段經(jīng)常用來做where,建分區(qū)表,使用這個字段當做分區(qū)字段 ?????????
2、在查詢的時候,使用分區(qū)字段來過濾,就可以避免全表掃描。只需要掃描這張表的一個分區(qū)的數(shù)據(jù)即可
利用分桶表優(yōu)化
????????分桶跟分區(qū)的概念很相似,都是把數(shù)據(jù)分成多個不同的類別,區(qū)別就是規(guī)則不一樣!
1、分區(qū):按照字段值來進行:一個分區(qū),就只是包含這個這一個值的所有記錄 不是當前分區(qū)的數(shù)據(jù)一定不在當前分區(qū) 當前分區(qū)也只會包含當前這個分區(qū)值的數(shù)據(jù) ?????????
2、分桶:默認規(guī)則:Hash散列 一個分桶中會有多個不同的值 如果一個分桶中,包含了某個值,這個值的所有記錄,必然都在這個分桶
??????? Hive Bucket,分桶,是指將數(shù)據(jù)以指定列的值為 key 進行 hash,hash 到指定數(shù)目的桶中,這樣做的目的和分區(qū)表類似,使得篩選時不用全局遍歷所有的數(shù)據(jù),只需要遍歷所在桶就可以了。這樣也可以支持高效采樣 。
????????分桶表的主要應(yīng)用場景有:
1、采樣? ? ? ? ?
2、join
????????如下例就是以 userid 這一列為 bucket 的依據(jù),共設(shè)置 32 個 buckets 。
CREATE?TABLE?page_view
?????????????(
??????????????????????????viewTime?INT
????????????????????????,?userid???BIGINT
????????????????????????,?page_url?STRING
????????????????????????,?referrer_url?STRING
????????????????????????,?ip?STRING?COMMENT?'IP?Address?of?the?User'
?????????????)
?????????????COMMENT?'This?is?the?page?view?table'?PARTITIONED?BY
?????????????(
??????????????????????????dt?STRING
????????????????????????,?country?STRING
?????????????)
?????????????CLUSTERED?BY
?????????????(
??????????????????????????userid
?????????????)
?????????????SORTED?BY
?????????????(
??????????????????????????viewTime
?????????????)
INTO
?????????????32?BUCKETS?ROW?FORMAT?DELIMITED?FIELDS?TERMINATED?BY?'1'?COLLECTION?ITEMS?TERMINATED?BY?'2'?MAP?KEYS?TERMINATED?BY?'3'?STORED?AS?SEQUENCEFILE
;
????????分桶的語法也很簡單:
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
CLUSTERED BY(userid) 表示按照 userid 來分桶????????
SORTED BY(viewTime) 按照 viewtime 來進行桶內(nèi)排序 ????????
INTO 32 BUCKETS 分成多少個桶
????????通常情況下,抽樣會在全體數(shù)據(jù)上進行采樣,這樣效率自然就低,它要去訪問所有數(shù)據(jù)。而如果一個表已經(jīng)對某一列制作了 bucket,就可以采樣所有桶中指定序號的某個桶,這就減少了訪問量 。
????????如下例所示就是采樣了 page_view 中 32 個桶中的第三個桶的全部數(shù)據(jù):
SELECT?*
FROM
???????page_view?TABLESAMPLE(BUCKET?3?OUT?OF?32)
;
????????如下例所示就是采樣了 page_view 中 32 個桶中的第三個桶的一半數(shù)據(jù):
SELECT?*
FROM
???????page_view?TABLESAMPLE(BUCKET?3?OUT?OF?64)
;
????????總結(jié)一下常見的三種采樣方式:
分桶抽樣:?
select?*?from?student?tablesample(bucket?3?out?of?32);?
隨機采樣:rand()?函數(shù)?
select?*?from?student?order?by?rand()?limit?100;?//?效率低?
select?*?from?student?distribute?by?rand()?sort?by?rand()?limit?100;?//?推薦使用這種?
數(shù)據(jù)塊抽樣:tablesample()函數(shù)?
select?*?from?student?tablesample(10?percent);?#?百分比?
select?*?from?student?tablesample(5?rows);?#?行數(shù)?
select?*?from?student?tablesample(5?M);?#?大小
選擇合適的文件存儲格式
????????在 HiveSQL 的 create table 語句中,可以使用 stored as ... 指定表的存儲格式。Apache Hive 支持 Apache Hadoop 中使用的幾種熟悉的文件格式,比如 TextFile、SequenceFile、RCFile、Avro、ORC、ParquetFile 等 。
????????存儲格式一般需要根據(jù)業(yè)務(wù)進行選擇,在我們的實操中,絕大多數(shù)表都采用TextFile與Parquet兩種存儲格式之一。TextFile是最簡單的存儲格式,它是純文本記錄,也是Hive的默認格式。雖然它的磁盤開銷比較大,查詢效率也低,但它更多的是作為跳板來使用。RCFile、ORC、Parquet等格式的表都不能由文件直接導(dǎo)入數(shù)據(jù),必須由TextFile來做中轉(zhuǎn)。Parquet和ORC都是 Apache 旗下的開源列式存儲格式。列式存儲比起傳統(tǒng)的行式存儲更適合批量OLAP查詢,并且也支持更好的壓縮和編碼。
????????創(chuàng)建表時,特別是寬表,盡量使用 ORC、ParquetFile這些列式存儲格式,因為列式存儲的表,每一列的數(shù)據(jù)在物理上是存儲在一起的,Hive查詢時會只遍歷需要列數(shù)據(jù),大大減少處理的數(shù)據(jù)量。
1、TextFile
存儲方式:行存儲。默認格式,如果建表時不指定默認為此格式。 每一行都是一條記錄,每行都以換行符"\n"結(jié)尾。數(shù)據(jù)不做壓縮時,磁盤會開銷比較大,數(shù)據(jù)解析開銷也 比較大。 可結(jié)合 Gzip、Bzip2等壓縮方式一起使用(系統(tǒng)會自動檢查,查詢時會自動解壓), 推薦選用可切分的壓縮算法。
2、Sequence File
一種 Hadoop API提供的二進制文件,使用方便、可分割壓縮的特點。 支持三種壓縮選擇: NONE、RECORD、BLOCK。RECORD壓縮率低,一般建議使用BLOCK壓縮 。
3、RC File
存儲方式:數(shù)據(jù)按行分塊,每塊按照列存儲 。A、首先,將數(shù)據(jù)按行分塊,保證同一個 record 在一個塊上,避免讀一個記錄需要讀取多個 block。B、其次,塊數(shù)據(jù)列式存儲,有利于數(shù)據(jù)壓縮和快速的列存取。 相對來說,RCFile對于提升任務(wù)執(zhí)行性能提升不大,但是能節(jié)省一些存儲空間。可以使用升級版的ORC格式。
4、ORC File
存儲方式:數(shù)據(jù)按行分塊,每塊按照列存儲 Hive提供的新格式,屬于RCFile的升級版,性能有大幅度提升,而且數(shù)據(jù)可以壓縮存儲,壓縮快,快速列存取。 ORC File會基于列創(chuàng)建索引,當查詢的時候會很快。
5、Parquet File
存儲方式:列式存儲。 Parquet 對于大型查詢的類型是高效的。對于掃描特定表格中的特定列查詢,Parquet 特別有用。Parquet 一般使用Snappy、Gzip壓縮。默認Snappy。 Parquet 支持 Impala 查詢引擎。 表的文件存儲格式盡量采用 Parquet或ORC,不僅降低存儲量,還優(yōu)化了查詢,壓縮,表關(guān)聯(lián)等性能。
選擇合適的壓縮格式
????????Hive 語句最終是轉(zhuǎn)化為 MapReduce 程序來執(zhí)行的,而 MapReduce 的性能瓶頸在與網(wǎng)絡(luò)IO 和 磁盤 IO,要解決性能瓶頸,最主要的是 減少數(shù)據(jù)量,對數(shù)據(jù)進行壓縮是個好方式。壓縮雖然是減少了數(shù)據(jù)量,但是壓縮過程要消耗 CPU,但是在 Hadoop 中,往往性能瓶頸不在于 CPU,CPU 壓力并不大,所以壓縮充分利用了比較空閑的 CPU。
????????常用的壓縮方法對比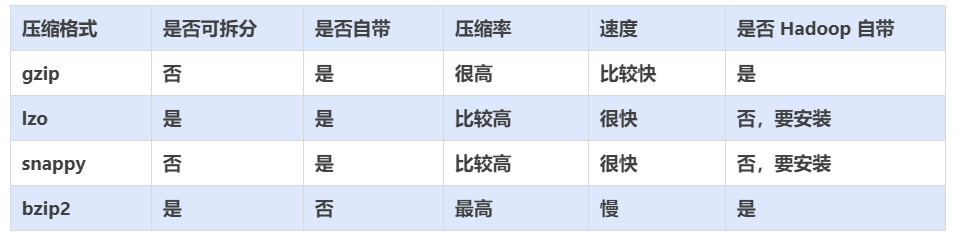 ????????
????????
? ? ? ??如何選擇壓縮方式
1、壓縮比率?
2、壓縮解壓速度?
3、是否支持split
????????支持分割的文件可以并行的有多個 mapper 程序處理大數(shù)據(jù)文件,大多數(shù)文件不支持可分割是因為這些文件只能從頭開始讀。
????????是否壓縮
1、計算密集型,不壓縮,否則進一步增加了CPU的負擔?
2、網(wǎng)絡(luò)密集型,推薦壓縮,減小網(wǎng)絡(luò)數(shù)據(jù)傳輸
????????各個壓縮方式所對應(yīng)的Class類 ????????壓縮使用:
????????壓縮使用:
??????? Job 輸出文件按照 Block 以 GZip 的方式進行壓縮:
##?默認值是false?
set?mapreduce.output.fileoutputformat.compress=true;?
##?默認值是Record?
set?mapreduce.output.fileoutputformat.compress.type=BLOCK?
##?默認值是org.apache.hadoop.io.compress.DefaultCodec?
set?mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.G?zipCodec
????????Map 輸出結(jié)果也以 Gzip 進行壓縮:
##?啟用map端輸出壓縮?
set?mapred.map.output.compress=true
##?默認值是org.apache.hadoop.io.compress.DefaultCodec?
set?mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCod
????????對 Hive 輸出結(jié)果和中間都進行壓縮:
##?默認值是false,不壓縮?
set?hive.exec.compress.output=true?
##?默認值是false,為true時MR設(shè)置的壓縮才?啟用
set?hive.exec.compress.intermediate=true?
HQL語法和運行參數(shù)層面
????????為了寫出高效的SQL,我們有必要知道HQL的執(zhí)行語法,以及通過一些控制參數(shù)來調(diào)整 HQL 的執(zhí)行。
1、查看Hive執(zhí)行計劃
??????? Hive 的 SQL 語句在執(zhí)行之前需要將 SQL 語句轉(zhuǎn)換成 MapReduce 任務(wù),因此需要了解具體的轉(zhuǎn)換過程,可以在 SQL 語句中輸入如下命令查看具體的執(zhí)行計劃 。
##?查看執(zhí)行計劃,添加extended關(guān)鍵字可以查看更加詳細的執(zhí)行計劃?
explain?[extended]?query
2、列裁剪
? ? ? ??列裁剪就是在查詢時只讀取需要的列,分區(qū)裁剪就是只讀取需要的分區(qū)。當列很多或者數(shù)據(jù)量很大時,如果 select * 或者不指定分區(qū),全列掃描和全表掃描效率都很低。
????????Hive 在讀數(shù)據(jù)的時候,可以只讀取查詢中所需要用到的列,而忽略其他的列。這樣做可以節(jié)省讀取開銷:中間表存儲開銷和數(shù)據(jù)整合開銷。
##?列裁剪,取數(shù)只取查詢中需要用到的列,默認是true
set?hive.optimize.cp?=?true;?
3、謂詞下推
????????將 SQL 語句中的 where 謂詞邏輯都盡可能提前執(zhí)行,減少下游處理的數(shù)據(jù)量。對應(yīng)邏輯優(yōu)化器是 PredicatePushDown 。
##?默認是true
set?hive.optimize.ppd=true;
????????示例程序:
##?優(yōu)化之前
SELECT
????a.*,
????b.*
FROM
????a
????JOIN?b?ON?a.id?=?b.id
WHERE
????b.age?>?20;
##?優(yōu)化之后
SELECT
????a.*,
????c.*
FROM
????a
????JOIN?(
????????SELECT
????????????*
????????FROM
????????????b
????????WHERE
????????????age?>?20
????)?c?ON?a.id?=?c.id;
4、分區(qū)裁剪
????????列裁剪就是在查詢時只讀取需要的列,分區(qū)裁剪就是只讀取需要的分區(qū) 。當列很多或者數(shù)據(jù)量很大時,如果 select * 或者不指定分區(qū),全列掃描和全表掃描效率都很低 。
????????在查詢的過程中只選擇需要的分區(qū),可以減少讀入的分區(qū)數(shù)目,減少讀入的數(shù)據(jù)量 。
??????? Hive 中與分區(qū)裁剪優(yōu)化相關(guān)的則是:
##?默認是true
set?hive.optimize.pruner=true;?
????????在 HiveQL 解析階段對應(yīng)的則是 ColumnPruner 邏輯優(yōu)化器 。
SELECT
????*
FROM
????student
WHERE
????department?=?"AAAA";
5、合并小文件
????????Map 輸入合并
????????在執(zhí)行 MapReduce 程序的時候,一般情況是一個文件的一個數(shù)據(jù)分塊需要一個 mapTask 來處理。但是如果數(shù)據(jù)源是大量的小文件,這樣就會啟動大量的 mapTask 任務(wù),這樣會浪費大量資源。可以將輸入的小文件進行合并,從而減少 mapTask 任務(wù)數(shù)量 。
##?Map端輸入、合并文件之后按照block的大小分割(默認)?
set?hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;?
##?Map端輸入,不合并?
set?hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
????????Map/Reduce輸出合并
????????大量的小文件會給 HDFS 帶來壓力,影響處理效率。可以通過合并 Map 和 Reduce 的結(jié)果文件來消除影響 。
##?是否合并Map輸出文件,?默認值為true?
set?hive.merge.mapfiles=true;?
##?是否合并Reduce端輸出文件,默認值為false?
set?hive.merge.mapredfiles=true;?
##?合并文件的大小,默認值為256000000?
set?hive.merge.size.per.task=256000000;?
##?每個Map?最大分割大小?
set?mapred.max.split.size=256000000;?
##?一個節(jié)點上split的最少值?
set?mapred.min.split.size.per.node=1;??//?服務(wù)器節(jié)點?
##?一個機架上split的最少值?
set?mapred.min.split.size.per.rack=1;??//?服務(wù)器機架
????????hive.merge.size.per.task 和 mapred.min.split.size.per.node 聯(lián)合起來:
1、默認情況先把這個節(jié)點上的所有數(shù)據(jù)進行合并,如果合并的那個文件的大小超過了256M就開啟另外一個文件繼續(xù)合并 2、如果當前這個節(jié)點上的數(shù)據(jù)不足256M,那么就都合并成一個邏輯切片。
6、合理設(shè)置MapTask并行度
第一:MapReduce中的MapTask的并行度機制
????????Map數(shù)過大:當輸入文件特別大,MapTask 特別多,每個計算節(jié)點分配執(zhí)行的 MapTask 都很多,這時候可以考慮減少 MapTask 的數(shù)量 ,增大每個 MapTask 處理的數(shù)據(jù)量。如果 MapTask 過多,最終生成的結(jié)果文件數(shù)會太多 。
原因:
1、Map階段輸出文件太小,產(chǎn)生大量小文件?
2、初始化和創(chuàng)建Map的開銷很大
????????Map數(shù)太小:當輸入文件都很大,任務(wù)邏輯復(fù)雜,MapTask 執(zhí)行非常慢的時候,可以考慮增加 MapTask 數(shù),來使得每個 MapTask 處理的數(shù)據(jù)量減少,從而提高任務(wù)的執(zhí)行效率 。
原因:
1、文件處理或查詢并發(fā)度小,Job執(zhí)行時間過長?
2、大量作業(yè)時,容易堵塞集群
????????在 MapReduce 的編程案例中,我們得知,一個 MapReduce Job 的 MapTask 數(shù)量是由輸入分片 InputSplit 決定的。而輸入分片是由 FileInputFormat.getSplit() 決定的。一個輸入分片對應(yīng)一個 MapTask,而輸入分片是由三個參數(shù)決定的:
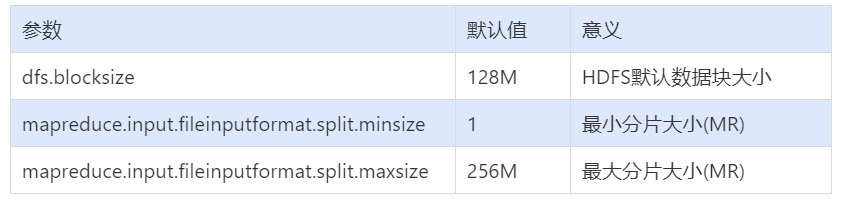 ????????輸入分片大小的計算是這么計算出來的:
????????輸入分片大小的計算是這么計算出來的:
long?splitSize?=?Math.max(minSize,?Math.min(maxSize,?blockSize))
????????默認情況下,輸入分片大小和 HDFS 集群默認數(shù)據(jù)塊大小一致,也就是默認一個數(shù)據(jù)塊,啟用一個 MapTask 進行處理,這樣做的好處是避免了服務(wù)器節(jié)點之間的數(shù)據(jù)傳輸,提高 job 處理效率 。
????????兩種經(jīng)典的控制 MapTask 的個數(shù)方案:減少 MapTask 數(shù) 或者 增加 MapTask 數(shù):
1、減少 MapTask 數(shù)是通過合并小文件來實現(xiàn),這一點主要是針對數(shù)據(jù)源
2、增加 MapTask 數(shù)可以通過控制上一個 job 的 reduceTask 個數(shù) 重點注意:不推薦把這個值進行隨意設(shè)置!推薦的方式:使用默認的切塊大小即可。如果非要調(diào)整,最好是切塊的N倍數(shù)
第二:合理控制 MapTask 數(shù)量
減少 MapTask 數(shù)可以通過合并小文件來實現(xiàn) 增加 MapTask 數(shù)可以通過控制上一個 ReduceTask 默認的 MapTask 個數(shù)
計算方式
輸入文件總大小:total_size HDFS 設(shè)置的數(shù)據(jù)塊大小:dfs_block_size default_mapper_num = total_size / dfs_block_size
????????MapReduce 中提供了如下參數(shù)來控制 map 任務(wù)個數(shù),從字面上看,貌似是可以直接設(shè)置 MapTask 個數(shù)的樣子,但是很遺憾不行,這個參數(shù)設(shè)置只有在大于 default_mapper_num 的時候,才會生效 。
##?默認值是2
set?mapred.map.tasks=10;?
????????那如果我們需要減少 MapTask 數(shù)量,但是文件大小是固定的,那該怎么辦呢?
????????可以通過 mapred.min.split.size 設(shè)置每個任務(wù)處理的文件的大小,這個大小只有在大于 dfs_block_size 的時候才會生效
split_size = max(mapred.min.split.size, dfs_block_size)?
split_num = total_size / split_size?
compute_map_num = Math.min(split_num, Math.max(default_mapper_num, mapred.map.tasks))
????????這樣就可以減少 MapTask 數(shù)量了 。
????????總結(jié)一下控制 mapper 個數(shù)的方法:
1、如果想增加 MapTask 個數(shù),可以設(shè)置 mapred.map.tasks 為一個較大的值
2、如果想減少 MapTask 個數(shù),可以設(shè)置 maperd.min.split.size 為一個較大的值?
3、如果輸入是大量小文件,想減少 mapper 個數(shù),可以通過設(shè)置 hive.input.format 合并小文件
????????如果想要調(diào)整 mapper 個數(shù),在調(diào)整之前,需要確定處理的文件大概大小以及文件的存在形式(是大量小文件,還是單個大文件),然后再設(shè)置合適的參數(shù)。不能盲目進行暴力設(shè)置,不然適得其反。
????????MapTask 數(shù)量與輸入文件的 split 數(shù)息息相關(guān),在 Hadoop 源碼org.apache.hadoop.mapreduce.lib.input.FileInputFormat 類中可以看到 split 劃分的具體邏輯。可以直接通過參數(shù) mapred.map.tasks (默認值2)來設(shè)定 MapTask 數(shù)的期望值,但它不一定會生效 。
7、合理設(shè)置ReduceTask并行度
????????如果 ReduceTask 數(shù)量過多,一個 ReduceTask 會產(chǎn)生一個結(jié)果文件,這樣就會生成很多小文件,那么如果這些結(jié)果文件會作為下一個 Job 的輸入,則會出現(xiàn)小文件需要進行合并的問題,而且啟動和初始化ReduceTask 需要耗費資源 。
????????如果 ReduceTask 數(shù)量過少,這樣一個 ReduceTask 就需要處理大量的數(shù)據(jù),容易拖慢運行時間或者造成 OOM,可能會出現(xiàn)數(shù)據(jù)傾斜的問題,使得整個查詢耗時長。默認情況下,Hive 分配的 reducer 個數(shù)由下列參數(shù)決定:
參數(shù)1:hive.exec.reducers.bytes.per.reducer (默認256M)?
參數(shù)2:hive.exec.reducers.max (默認為1009)?
參數(shù)3:mapreduce.job.reduces (默認值為-1,表示沒有設(shè)置,那么就按照以上兩個參數(shù) 進行設(shè)置)
??????? ReduceTask 的計算公式為:
N = Math.min(參數(shù)2,總輸入數(shù)據(jù)大小 / 參數(shù)1)
????????可以通過改變上述兩個參數(shù)的值來控制 ReduceTask 的數(shù)量。也可以通過
set?mapred.map.tasks=10;?
set?mapreduce.job.reduces=10;
????????通常情況下,有必要手動指定 ReduceTask 個數(shù)。考慮到 Mapper 階段的輸出數(shù)據(jù)量通常會比輸入有大幅減少,因此即使不設(shè)定 ReduceTask 個數(shù),重設(shè) 參數(shù)2 還是必要的 。
????????依據(jù)經(jīng)驗,可以將 參數(shù)2 設(shè)定為 M * (0.95 * N) (N為集群中 NodeManager 個數(shù))。一般來說,NodeManage 和 DataNode 的個數(shù)是一樣的。
8、 Join優(yōu)化
Join優(yōu)化整體原則:
1、優(yōu)先過濾后再進行Join操作,最大限度的減少參與join的數(shù)據(jù)量?
2、小表join大表,最好啟動mapjoin,hive自動啟用mapjoin, 小表不能超過25M,可以更改?
3、Join on的條件相同的話,最好放入同一個job,并且join表的排列順序從小到大:select a., b., c.* from a join b on a.id = b.id join c on a.id = c.i?
4、如果多張表做join, 如果多個鏈接條件都相同,會轉(zhuǎn)換成一個JOb
優(yōu)先過濾數(shù)據(jù)
盡量減少每個階段的數(shù)據(jù)量,對于分區(qū)表能用上分區(qū)字段的盡量使用,同時只選擇后面需要使用到的列,最大 限度的減少參與 Join 的數(shù)據(jù)量。
小表 join 大表原則
小表 join 大表的時應(yīng)遵守小表 join 大表原則,原因是 join 操作的 reduce 階段,位于 join 左邊 的表內(nèi)容會被加載進內(nèi)存,將條目少的表放在左邊,可以有效減少發(fā)生內(nèi)存溢出的幾率。join 中執(zhí)行順序是從左到右生成 Job,應(yīng)該保證連續(xù)查詢中的表的大小從左到右是依次增加的。
使用相同的連接鍵
在 hive 中,當對 3 個或更多張表進行 join 時,如果 on 條件使用相同字段,那么它們會合并為一個 MapReduce Job,利用這種特性,可以將相同的 join on 放入一個 job 來節(jié)省執(zhí)行時間 。
盡量原子操作
盡量避免一個SQL包含復(fù)雜的邏輯,可以使用中間表來完成復(fù)雜的邏輯。
大表Join大表
1、空key過濾:有時join超時是因為某些key對應(yīng)的數(shù)據(jù)太多,而相同key對應(yīng)的數(shù)據(jù)都會發(fā)送到相同的 reducer上,從而導(dǎo)致內(nèi)存不夠。此時我們應(yīng)該仔細分析這些異常的key,很多情況下,這些key對應(yīng)的數(shù)據(jù)是異常數(shù)據(jù),我們需要在SQL語句中進行過濾。?????????
2、空key轉(zhuǎn)換:有時雖然某個key為空對應(yīng)的數(shù)據(jù)很多,但是相應(yīng)的數(shù)據(jù)不是異常數(shù)據(jù),必須要包含在join 的結(jié)果中,此時我們可以表a中key為空的字段賦一個隨機的值,使得數(shù)據(jù)隨機均勻地分到不同的reducer 上 。
9、 啟用 MapJoin
這個優(yōu)化措施,但凡能用就用!
大表 join 小表 小表滿足需求:小表數(shù)據(jù)小于控制條件時 。
??????? MapJoin 是將 join 雙方比較小的表直接分發(fā)到各個 map 進程的內(nèi)存中,在 map 進程中進行 join 操作,這樣就不用進行 reduce 步驟,從而提高了速度。只有 join 操作才能啟用 MapJoin 。
##?是否根據(jù)輸入小表的大小,自動將reduce端的common join 轉(zhuǎn)化為map join,將小表刷入內(nèi)存中。?
##?對應(yīng)邏輯優(yōu)化器是MapJoinProcessor?
set?hive.auto.convert.join?=?true;?
##?刷入內(nèi)存表的大小(字節(jié))?
set?hive.mapjoin.smalltable.filesize?=?25000000;?
##?hive會基于表的size自動的將普通join轉(zhuǎn)換成mapjoin?
set?hive.auto.convert.join.noconditionaltask=true;?
##?多大的表可以自動觸發(fā)放到內(nèi)層?LocalTask?中,默認大小10M?
set?hive.auto.convert.join.noconditionaltask.size=10000000;
??????? Hive 可以進行多表 Join。Join 操作尤其是 Join 大表的時候代價是非常大的。MapJoin 特別適合大小表 join 的情況。在Hive join場景中,一般總有一張相對小的表和一張相對大的表,小表叫 build table,大表叫 probe table。Hive 在解析帶 join 的 SQL 語句時,會默認將最后一個表作為 probe table,將前面的表作為 build table 并試圖將它們讀進內(nèi)存。如果表順序?qū)懛矗琾robe table 在前面,引發(fā) OOM 的風險就高了。在維度建模數(shù)據(jù)倉庫中,事實表就是 probe table,維度表就是 build table。這種 Join 方式在 map 端直接完成 join 過程,消滅了 reduce,效率很高。而且 MapJoin 還支持非等值連接 。
????????當 Hive 執(zhí)行 Join 時,需要選擇哪個表被流式傳輸(stream),哪個表被緩存(cache)。Hive 將JOIN 語句中的最后一個表用于流式傳輸,因此我們需要確保這個流表在兩者之間是最大的。如果要在不同的 key 上 join 更多的表,那么對于每個 join 集,只需在 ON 條件右側(cè)指定較大的表 。
????????也可以手動開啟mapjoin:
--?SQL方式,在SQL語句中添加MapJoin標記(mapjoin?hint)?
--?將小表放到內(nèi)存中,省去shffle操作?
//?在沒有開啟mapjoin的情況下,執(zhí)行的是reduceJoin?
SELECT?/*+?MAPJOIN(smallTable)?*/??smallTable.key,?bigTable.value?FROM?smallTable?JOIN?bigTable?ON?smallTable.key?=?bigTable.key;
?/*+mapjoin(smalltable)*/
Sort-Merge-Bucket(SMB) Map Join????????
它是另一種Hive Join優(yōu)化技術(shù),使用這個技術(shù)的前提是所有的表都必須是分桶表(bucket)和分桶排序的(sort)。分桶表的優(yōu)化!
具體實現(xiàn):
1、針對參與join的這兩張做相同的hash散列,每個桶里面的數(shù)據(jù)還要排序
2、這兩張表的分桶個數(shù)要成倍數(shù)。
3、開啟 SMB join 的開關(guān)!
一些常見參數(shù)設(shè)置:
##?當用戶執(zhí)行bucket?map?join的時候,發(fā)現(xiàn)不能執(zhí)行時,禁止查詢;
set?hive.enforce.sortmergebucketmapjoin=false;?
##?如果join的表通過sort?merge?join的條件,join是否會自動轉(zhuǎn)換為sort?merge?join;?
set?hive.auto.convert.sortmerge.join=true;?
##?當兩個分桶表 join 時,如果 join on的是分桶字段,小表的分桶數(shù)是大表的倍數(shù)時,可以啟用 mapjoin 來提高效率。?# bucket map join優(yōu)化,默認值是 false
set?hive.optimize.bucketmapjoin=false;?
##?bucket?map?join?優(yōu)化,默認值是?false;?
set?hive.optimize.bucketmapjoin.sortedmerge=false;
10、Join數(shù)據(jù)傾斜優(yōu)化
在編寫 Join 查詢語句時,如果確定是由于 join 出現(xiàn)的數(shù)據(jù)傾斜,那么請做如下設(shè)置:
#?join的鍵對應(yīng)的記錄條數(shù)超過這個值則會進行分拆,值根據(jù)具體數(shù)據(jù)量設(shè)置?
set?hive.skewjoin.key=100000;?
#?如果是join過程出現(xiàn)傾斜應(yīng)該設(shè)置為true?
set?hive.optimize.skewjoin=false;
????????如果開啟了,在 Join 過程中 Hive 會將計數(shù)超過閾值 hive.skewjoin.key(默認100000)的傾斜 key 對應(yīng)的行臨時寫進文件中,然后再啟動另一個 job 做 map join 生成結(jié)果。
????????通過 hive.skewjoin.mapjoin.map.tasks 參數(shù)還可以控制第二個 job 的 mapper 數(shù)量,默認10000 。
set hive.skewjoin.mapjoin.map.tasks=10000;
11、CBO優(yōu)化
??????? join的時候表的順序的關(guān)系:前面的表都會被加載到內(nèi)存中。后面的表進行磁盤掃描 。
select a., b., c.* from a join b on a.id = b.id join c on a.id = c.id ;
????????Hive 自 0.14.0 開始,加入了一項 Cost based Optimizer 來對 HQL 執(zhí)行計劃進行優(yōu)化,這個功能通過 hive.cbo.enable 來開啟。在 Hive 1.1.0 之后,這個 feature 是默認開啟的,它可以 自動優(yōu)化 HQL 中多個 Join 的順序,并選擇合適的 Join 算法 。
????????CBO,成本優(yōu)化器,代價最小的執(zhí)行計劃就是最好的執(zhí)行計劃。傳統(tǒng)的數(shù)據(jù)庫,成本優(yōu)化器做出最優(yōu)化的執(zhí)行計劃是依據(jù)統(tǒng)計信息來計算的。Hive 的成本優(yōu)化器也一樣。
??????? Hive 在提供最終執(zhí)行前,優(yōu)化每個查詢的執(zhí)行邏輯和物理執(zhí)行計劃。這些優(yōu)化工作是交給底層來完成的。根據(jù)查詢成本執(zhí)行進一步的優(yōu)化,從而產(chǎn)生潛在的不同決策:如何排序連接,執(zhí)行哪種類型的連接,并行度等等。
????????要使用基于成本的優(yōu)化(也稱為CBO),請在查詢開始設(shè)置以下參數(shù):
set hive.cbo.enable=true;?
set hive.compute.query.using.stats=true;?
set hive.stats.fetch.column.stats=true;?
set hive.stats.fetch.partition.stats=true;
12、怎樣做笛卡爾積
????????當 Hive 設(shè)定為嚴格模式(hive.mapred.mode=strict)時,不允許在 HQL 語句中出現(xiàn)笛卡爾積,這實
際說明了 Hive 對笛卡爾積支持較弱。因為找不到 Join key,Hive 只能使用 1 個 reducer 來完成笛卡爾積 。
????????當然也可以使用 limit 的辦法來減少某個表參與 join 的數(shù)據(jù)量,但對于需要笛卡爾積語義的需求來說,經(jīng)常是一個大表和一個小表的 Join 操作,結(jié)果仍然很大(以至于無法用單機處理),這時 MapJoin 才是最好的解決辦法。MapJoin,顧名思義,會在 Map 端完成 Join 操作。這需要將 Join 操作的一個或多個表完全讀入內(nèi)存。
??????? PS:MapJoin 在子查詢中可能出現(xiàn)未知 BUG。在大表和小表做笛卡爾積時,規(guī)避笛卡爾積的方法是, 給 Join 添加一個 Join key,原理很簡單:將小表擴充一列 join key,并將小表的條目復(fù)制數(shù)倍,join key 各不相同;將大表擴充一列 join key 為隨機數(shù)。
? ? ? ??精髓就在于復(fù)制幾倍,最后就有幾個 reduce 來做,而且大表的數(shù)據(jù)是前面小表擴張 key 值范圍里面隨機出來的,所以復(fù)制了幾倍 n,就相當于這個隨機范圍就有多大 n,那么相應(yīng)的,大表的數(shù)據(jù)就被隨機的分為了 n 份。并且最后處理所用的 reduce 數(shù)量也是 n,而且也不會出現(xiàn)數(shù)據(jù)傾斜 。
13、Group By 優(yōu)化
? ? ? ??默認情況下,Map 階段同一個 Key 的數(shù)據(jù)會分發(fā)到一個 Reduce 上,當一個 Key 的數(shù)據(jù)過大時會產(chǎn)生數(shù)據(jù)傾斜。進行 group by 操作時可以從以下兩個方面進行優(yōu)化:
1. Map端部分聚合???????
? ? ? ??事實上并不是所有的聚合操作都需要在 Reduce 部分進行,很多聚合操作都可以先在 Map 端進行部分聚合,然后在 Reduce 端的得出最終結(jié)果 。
##?開啟Map端聚合參數(shù)設(shè)置?
set?hive.map.aggr=true;?
##?設(shè)置map端預(yù)聚合的行數(shù)閾值,超過該值就會分拆job,默認值100000?
set?hive.groupby.mapaggr.checkinterval=100000
2. 有數(shù)據(jù)傾斜時進行負載均衡
? ? ? ??當 HQL 語句使用 group by 時數(shù)據(jù)出現(xiàn)傾斜時,如果該變量設(shè)置為 true,那么 Hive 會自動進行負載均衡。策略就是把 MapReduce 任務(wù)拆分成兩個:第一個先做預(yù)匯總,第二個再做最終匯總 。
#?自動優(yōu)化,有數(shù)據(jù)傾斜的時候進行負載均衡(默認是false)
?set?hive.groupby.skewindata=false;
????????當選項設(shè)定為 true 時,生成的查詢計劃有兩個 MapReduce 任務(wù) 。
1、在第一個 MapReduce 任務(wù)中,map 的輸出結(jié)果會隨機分布到 reduce 中,每個 reduce 做部分聚合操作,并輸出結(jié)果,這樣處理的結(jié)果是相同的
group by key有可能分發(fā)到不同的 reduce 中,從而達到負載均衡的目的;?????????2、第二個 MapReduce 任務(wù)再根據(jù)預(yù)處理的數(shù)據(jù)結(jié)果按照 group by key 分布到各個 reduce 中,最 后完成最終的聚合操作。
??????? Map 端部分聚合:并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端進行部分聚合,最后在 Reduce 端得出最終結(jié)果,對應(yīng)的優(yōu)化器為 GroupByOptimizer 。
????????那么如何用 group by 方式同時統(tǒng)計多個列?
SELECT
????t.a,
????SUM(t.b),
????COUNT(t.c),
????COUNT(t.d)
FROM
????some_table?t
GROUP?BY
????t.a;
????????下面是解決方法:
select?t.a,?sum(t.b),?count(t.c),?count(t.d)?from?(?
?select?a,b,null?c,null?d?from?some_table?
?union?all?
?select?a,0?b,c,null?d?from?some_table?group?by?a,c?
?union?all?
?select?a,0?b,null?c,d?from?some_table?group?by?a,d?
)?t;
14、Order By優(yōu)化
????????order by 只能是在一個 reduce 進程中進行,所以如果對一個大數(shù)據(jù)集進行 order by ,會導(dǎo)致一個 reduce 進程中處理的數(shù)據(jù)相當大,造成查詢執(zhí)行緩慢 。
1、在最終結(jié)果上進行order by,不要在中間的大數(shù)據(jù)集上進行排序。如果最終結(jié)果較少,可以在一個 reduce上進行排序時,那么就在最后的結(jié)果集上進行order by。
2、如果是取排序后的前N條數(shù)據(jù),可以使用distribute by和sort by在各個reduce上進行排序后前N 條,然后再對各個reduce的結(jié)果集合合并后在一個reduce中全局排序,再取前N條,因為參與全局排序的 order by的數(shù)據(jù)量最多是reduce個數(shù) * N,所以執(zhí)行效率會有很大提升。
????????在Hive中,關(guān)于數(shù)據(jù)排序,提供了四種語法,一定要區(qū)分這四種排序的使用方式和適用場景。
1、
order by:全局排序,缺陷是只能使用一個reduce2、
sort by:單機排序,單個reduce結(jié)果有序?3、
cluster by:對同一字段分桶并排序,不能和sort by連用?4、
distribute by+sort by:分桶,保證同一字段值只存在一個結(jié)果文件當中,結(jié)合sort by保證每 個reduceTask結(jié)果有序
??????? Hive HQL 中的 order by 與其他 SQL 方言中的功能一樣,就是將結(jié)果按某字段全局排序,這會導(dǎo)致所有 map 端數(shù)據(jù)都進入一個 reducer 中,在數(shù)據(jù)量大時可能會長時間計算不完 。
????????如果使用 sort by,那么還是會視情況啟動多個 reducer 進行排序,并且保證每個 reducer 內(nèi)局部有序。為了控制 map 端數(shù)據(jù)分配到 reducer 的 key,往往還要配合 distribute by 一同使用。如果不加 distribute by 的話,map 端數(shù)據(jù)就會隨機分配到 reducer。
????????提供一種方式實現(xiàn)全局排序:兩種方式:
1、建表導(dǎo)入數(shù)據(jù)準備
CREATE?TABLE?if?NOT?EXISTS?student(
????id?INT,
????name?string,
????sex?string,
????age?INT,
????department?string
)?ROW?format?delimited?fields?terminated?BY?",";
load?data?LOCAL?inpath?"/home/bigdata/students.txt"?INTO?TABLE?student;
2、第一種方式
--?直接使用order by來做。如果結(jié)果數(shù)據(jù)量很大,這個任務(wù)的執(zhí)行效率會非常低;
SELECT
????id,
????name,
????age
FROM
????student
ORDER?BY
????age?desc
LIMIT
????3;
3、第二種方式
--?使用distribute?by?+?sort?by?多個reduceTask,每個reduceTask分別有序
SET?mapreduce.job.reduces?=?3;
DROP?TABLE?student_orderby_result;
--?范圍分桶?0?
CREATE?TABLE?student_orderby_result?AS
SELECT
????*
FROM
????student?distribute?BY?(
????????CASE
????????????WHEN?age?>?20?THEN?0
????????????WHEN?age?18?THEN?2
????????????ELSE?1
????????END
????)?sort?BY?(age?desc);
????????關(guān)于分界值的確定,使用采樣的方式,來估計數(shù)據(jù)分布規(guī)律 。
15、Count Distinct優(yōu)化
????????當要統(tǒng)計某一列去重數(shù)時,如果數(shù)據(jù)量很大,count(distinct) 就會非常慢,原因與 order by 類似,count(distinct) 邏輯只會有很少的 reducer 來處理。這時可以用 group by 來改寫:
--?先?group?by?再?count
SELECT
????COUNT(1)
FROM
????(
????????SELECT
????????????age
????????FROM
????????????student
????????WHERE
????????????department?>=?"MA"
????????GROUP?BY
????????????age
????)?t;
再來一個例子:
????????優(yōu)化前 ,一個普通的只使用一個reduceTask來進行count(distinct) 操作
--?優(yōu)化前(只有一個reduce,先去重再count負擔比較大):
SELECT
????COUNT(DISTINCT?id)
FROM
????tablename;
????????優(yōu)化后 ,但是這樣寫會啟動兩個MR job(單純 distinct 只會啟動一個),所以要確保數(shù)據(jù)量大到啟動 job 的 overhead 遠小于計算耗時,才考慮這種方法。當數(shù)據(jù)集很小或者 key 的傾斜比較明顯時,group by 還可能會比 distinct 慢。
--?優(yōu)化后(啟動兩個job,一個job負責子查詢(可以有多個reduce),另一個job負責count(1)):
SELECT
????COUNT(1)
FROM
????(
????????SELECT
????????????DISTINCT?id
????????FROM
????????????tablename
????)?tmp;
SELECT
????COUNT(1)
FROM
????(
????????SELECT
????????????id
????????FROM
????????????tablename
????????GROUP?BY
????????????id
????)?tmp;
/?/?推薦使用這種
16、怎樣寫in/exists語句
????????在Hive的早期版本中,in/exists語法是不被支持的,但是從 hive-0.8x 以后就開始支持這個語法。但是不推薦使用這個語法。雖然經(jīng)過測驗,Hive-2.3.6 也支持 in/exists 操作,但還是推薦使用 Hive 的一個高效替代方案:left semi join
????????比如說:
-- in / exists 實現(xiàn)
SELECT
a.id,
a.name
FROM
a
WHERE
a.id IN (
SELECT
b.id
FROM
b
);
SELECT
a.id,
a.name
FROM
a
WHERE
EXISTS (
SELECT
id
FROM
b
WHERE
a.id = b.id
);
????????可以使用join來改寫:
SELECT
????a.id,
????a.namr
FROM
????a
????JOIN?b?ON?a.id?=?b.id;
????????應(yīng)該轉(zhuǎn)換成:
--?left?semi?join?實現(xiàn)
SELECT
????a.id,
????a.name
FROM
????a?LEFT?semi
????JOIN?b?ON?a.id?=?b.id;
17、使用 vectorization 技術(shù)
????????在計算類似 scan, filter, aggregation 的時候, vectorization 技術(shù)以設(shè)置批處理的增量大小為 1024 行單次來達到比單條記錄單次獲得更高的效率。
set hive.vectorized.execution.enabled=true ;?
set hive.vectorized.execution.reduce.enabled=true;
18、多重模式
????????如果你碰到一堆SQL,并且這一堆SQL的模式還一樣。都是從同一個表進行掃描,做不同的邏輯。有可優(yōu)化的地方:如果有n條SQL,每個SQL執(zhí)行都會掃描一次這張表 。
????????如果一個 HQL 底層要執(zhí)行 10 個 Job,那么能優(yōu)化成 8 個一般來說,肯定能有所提高,多重插入就是一
個非常實用的技能。一次讀取,多次插入,有些場景是從一張表讀取數(shù)據(jù)后,要多次利用,這時可以使用 multi insert 語法:
FROM
????sale_detail?INSERT?overwrite?TABLE?sale_detail_multi?PARTITION?(sale_date?=?'2019',?region?=?'china')
SELECT
????shop_name,
????customer_id,
????total_price
WHERE
.....insert?overwrite?TABLE?sale_detail_multi?PARTITION?(sale_date?=?'2020',?region?=?'china')
SELECT
????shop_name,
????customer_id,
????total_price
WHERE
.....;
????????需要的是,multi insert 語法有一些限制
1、一般情況下,單個SQL中最多可以寫128路輸出,超過128路,則報語法錯誤。
2、在一個multi insert中:對于分區(qū)表,同一個目標分區(qū)不允許出現(xiàn)多次。對于未分區(qū)表,該表不能出現(xiàn)多次。
3、對于同一張分區(qū)表的不同分區(qū),不能同時有insert overwrite和insert into操作,否則報錯返回
????????Multi-Group by 是 Hive 的一個非常好的特性,它使得 Hive 中利用中間結(jié)果變得非常方便。例如:
FROM
????(
????????SELECT
????????????a.status,
????????????b.school,
????????????b.gender
????????FROM
????????????status_updates?a
????????????JOIN?profiles?b?ON?(
????????????????a.userid?=?b.userid
????????????????AND?a.ds?=?'2019-03-20'
????????????)
????)?subq1?INSERT?OVERWRITE?TABLE?gender_summary?PARTITION(ds?=?'2019-03-20')
SELECT
????subq1.gender,
????COUNT(1)
GROUP?BY
????subq1.gender?INSERT?OVERWRITE?TABLE?school_summary?PARTITION(ds?=?'2019-03-20')
SELECT
????subq1.school,
????COUNT(1)
GROUP?BY
????subq1.school;
????????上述查詢語句使用了 Multi-Group by 特性連續(xù) group by 了 2 次數(shù)據(jù),使用不同的 Multi-Group by。這一特性可以減少一次 MapReduce 操作。
19、啟動中間結(jié)果壓縮
map 輸出壓縮
set mapreduce.map.output.compress=true;?
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
中間數(shù)據(jù)壓縮
????????中間數(shù)據(jù)壓縮就是對 hive 查詢的多個 Job 之間的數(shù)據(jù)進行壓縮。最好是選擇一個節(jié)省CPU耗時的壓縮方式。可以采用 snappy 壓縮算法,該算法的壓縮和解壓效率都非常高。
set hive.exec.compress.intermediate=true;?
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;?
set hive.intermediate.compression.type=BLOCK;
結(jié)果數(shù)據(jù)壓縮
????????最終的結(jié)果數(shù)據(jù)(Reducer輸出數(shù)據(jù))也是可以進行壓縮的,可以選擇一個壓縮效果比較好的,可以減少數(shù)據(jù)的大小和數(shù)據(jù)的磁盤讀寫時間 。
????????需要注意:常用的 gzip,snappy 壓縮算法是不支持并行處理的,如果數(shù)據(jù)源是 gzip/snappy壓縮文件大文件,這樣只會有有個 mapper 來處理這個文件,會嚴重影響查詢效率。所以如果結(jié)果數(shù)據(jù)需要作為其他查詢?nèi)蝿?wù)的數(shù)據(jù)源,可以選擇支持 splitable 的 LZO 算法,這樣既能對結(jié)果文件進行壓縮,還可以并行的處理,這樣就可以大大的提高 job 執(zhí)行的速度了。
set hive.exec.compress.output=true;?
set mapreduce.output.fileoutputformat.compress=true;?
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.G zipCodec;?
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
??????? Hadoop集群支持的壓縮算法:
org.apache.hadoop.io.compress.DefaultCodec?org.apache.hadoop.io.compress.GzipCodec?
org.apache.hadoop.io.compress.BZip2Codec?org.apache.hadoop.io.compress.DeflateCodec?
org.apache.hadoop.io.compress.SnappyCodec?org.apache.hadoop.io.compress.Lz4Codec?
com.hadoop.compression.lzo.LzoCodec?com.hadoop.compression.lzo.LzopCodec
Hive 架構(gòu)層面
1、啟用本地抓取
??????? Hive 的某些 SQL 語句需要轉(zhuǎn)換成 MapReduce 的操作,某些 SQL 語句就不需要轉(zhuǎn)換成 MapReduce 操作,但是同學們需要注意,理論上來說,所有的 SQL 語句都需要轉(zhuǎn)換成 MapReduce 操作,只不過 Hive 在轉(zhuǎn)換 SQL 語句的過程中會做部分優(yōu)化,使某些簡單的操作不再需要轉(zhuǎn)換成 MapReduce,例如:
1、只是 select * 的時候?
2、where 條件針對分區(qū)字段進行篩選過濾時?
3、帶有 limit 分支語句時
??????? Hive 從 HDFS 中讀取數(shù)據(jù),有兩種方式:啟用MapReduce讀取 和 直接抓取 。
????????直接抓取數(shù)據(jù)比 MapReduce 方式讀取數(shù)據(jù)要快的多,但是只有少數(shù)操作可以使用直接抓取方式 。
????????可以通過 hive.fetch.task.conversion 參數(shù)來配置在什么情況下采用直接抓取方式:
minimal:只有 select * 、在分區(qū)字段上 where 過濾、有 limit 這三種場景下才啟用直接抓取方式。
more:在 select、where 篩選、limit 時,都啟用直接抓取方式 。
????????查看 Hive 的抓取策略:
>?##?查看?
>?set?hive.fetch.task.conversion;
????????設(shè)置Hive的抓取策略:
##?默認more?
set?hive.fetch.task.conversion=more;
????????如果有疑惑,請看hive-default.xml中關(guān)于這個參數(shù)的解釋:
<property>
????<name>hive.fetch.task.conversionname>
????<value>morevalue>
????<description>
Expects?one?of?[none,?mi?nimal,?more].
Some?select?queri?es?can?be?converted?to?single?FETCH?task?minimizing?latency.
Currently?the?query?should?be?si?ngle?sourced?not?havi?ng?any?subquery?and?should?not?have
any?aggregations?or?di?sti?ncts?(whi?ch?i?ncurs?RS),?lateral?vi?ews?and
joi?ns.
0.?none?:?di?sable?hive.fetch.task.conversion
1.minimal?:?select?star,?filter?on?partition?columns,?limit?only
2.more?:?SELECT,?FILTER,?LIMIT?only?(support?TABLESAMPLE?and?vi?rtual
columns)
????descri?ption>
property>
<property>
????<name>hive.fetch.task.conversion.thresholdname>
????<value>1073741824value>
????<descri?pti?on>
input?threshold?for?applying?hive.fetch.task.conversion,?if?target?table?is?native,?input?1ength
is?calculated?by?summation?of?file?1engths.?if?it's?not?native,?storage?handler?for?the?table
can?optionally?implement
org.apache,?hadoop.?hive,?ql.?metadata.?inputEstimator?iinterface.
descri?ption>
property>
2、本地執(zhí)行優(yōu)化
??????? Hive在集群上查詢時,默認是在集群上多臺機器上運行,需要多個機器進行協(xié)調(diào)運行,這種方式很好地解決了大數(shù)據(jù)量的查詢問題。但是在Hive查詢處理的瓣量比較小的時候,其實沒有必要啟動分布 式模式去執(zhí)行,因為以分布式方式執(zhí)行設(shè)計到跨網(wǎng)絡(luò)傳輸、多節(jié)點協(xié)調(diào)等,并且消耗資源。對于小數(shù)據(jù) 集,可以通過本地模式,在單臺機器上處理所有任務(wù),執(zhí)行時間明顯被縮短 。
????????啟動本地模式涉及到三個參數(shù):
##打開hive自動判斷是否啟動本地模式的開關(guān)
set?hive.exec.mode.local.auto=true;
## map任務(wù)晝專大值,*啟用本地模式的task最大皋數(shù)
set?hive.exec.mode.1ocal.auto.input.files.max=4;
##?map輸入文件最大大小,不啟動本地模式的最大輸入文件大小
set?hive.exec.mode.1ocal.auto.inputbytes.max=134217728;
3、JVM 重用
??????? Hive語句最終會轉(zhuǎn)換為一系的MapReduce任務(wù),每一個MapReduce任務(wù)是由一系的MapTask 和ReduceTask組成的,默認情況下,MapReduce中一個MapTask或者ReduceTask就會啟動一個 JVM進程,一個Task執(zhí)行完畢后,JVM進程就會退出。這樣如果任務(wù)花費時間很短,又要多次啟動 JVM的情況下,JVM的啟動時間會變成一個比較大的消耗,這時,可以通過重用JVM來解決 。
set?mapred.job.reuse.jvm.num.tasks=5;
??????? JVM也是有缺點的,開啟JVM重用會一直占用使用到的task的插槽,以便進行重用,直到任務(wù)完成后才 會釋放。如果某個不平衡的job中有幾個reduce task執(zhí)行的時間要比其他的reduce task消耗的時間 要多得多的話,那么保留的插槽就會一直空閑卻無法被其他的job使用,直到所有的task都結(jié)束了才 會釋放。
????????根據(jù)經(jīng)驗,一般來說可以使用一個cpu core啟動一個JVM,假如服務(wù)器有16個cpu core,但是這個 節(jié)點,可能會啟動32個 mapTask ,完全可以考慮:啟動一個JVM,執(zhí)行兩個Task 。
4、并行執(zhí)行
????????有的查詢語句,Hive會將其轉(zhuǎn)化為一個或多個階段,包括:MapReduce階段、抽樣階段、合并階段、 limit階段等。默認情況下,一次只執(zhí)行一個階段。但是,如果某些階段不是互相依賴,是可以并行執(zhí)行的。多階段并行是比較耗系統(tǒng)資源的 。
????????一個 Hive SQL語句可能會轉(zhuǎn)為多個MapReduce Job,每一個 job 就是一個 stage , 這些Job順序執(zhí)行,這個在 client 的運行日志中也可以看到。但是有時候這些任務(wù)之間并不是相互依賴的,如果集群資源允許的話,可以讓多個并不相互依賴 stage 并發(fā)執(zhí)行,這樣就節(jié)約了時間,提高了執(zhí)行速度,但是如 果集群資源匱乏時,啟用并行化反倒是會導(dǎo)致各個 Job 相互搶占資源而導(dǎo)致整體執(zhí)行性能的下降。啟用 并行化:
##可以開啟并發(fā)執(zhí)行。
set?hive.exec.parallei=true;
##同一個sql允許最大并行度,默認為8。
set?hive.exec.paral1?el.thread.number=16;
5、推測執(zhí)行
????????在分布式集群環(huán)境下,因為程序Bug(包括Hadoop本身的bug),負載不均衡或者資源分布不均等原因,會造成同一個作業(yè)的多個任務(wù)之間運行速度不一致,有些任務(wù)的運行速度可能明顯慢于其他任務(wù)(比如一個作業(yè)的某個任務(wù)進度只有50%,而其他所有任務(wù)已經(jīng)運行完畢),則這些任務(wù)會拖慢作業(yè)的整體執(zhí)行進度。為了避免這種情況發(fā)生,Hadoop采用了推測執(zhí)行(Speculative Execution)機制,它根據(jù)一定的法則推測出“拖后腿”的任務(wù),并為這樣的任務(wù)啟動一個備份任務(wù),讓該任務(wù)與原始任務(wù)同時處理同一份數(shù)據(jù),并最終選用最先成功運行完成任務(wù)的計算結(jié)果作為最終結(jié)果 。
#?啟動mapper階段的推測執(zhí)行機制?
set?mapreduce.map.speculative=true;?
#?啟動reducer階段的推測執(zhí)行機制?
set?mapreduce.reduce.speculative=true;
設(shè)置開啟推測執(zhí)行參數(shù):Hadoop 的 mapred-site.xml 文件中進行配置:
<property>
????<name>mapreduce.map.speculativename>
????<value>truevalue>
????<description>lf?true,?then?multiple?i?nstances?of?some?map?tasks?may?be?executed?i?n?parallel.description>
property>
<property>
????<name>mapreduce.reduce.speculati?vename>
????<value>truevalue>
????<descri?pti?on>lf?true,?then?multi?ple?i?nstances?of?some?reduce?tasks?may?be?executed?in?parallel.
????description>
property>
Hive本身也提供了配置項來控制reduce-side的推測執(zhí)行
????hive.mapped.reduce.tasks.speculative.executi?on
????true
????whether?speculative?execution?for?reducers?should?be?turned?on.?
建議:
如果用戶對于運行時的偏差非常敏感的話,那么可以將這些功能關(guān)閉掉。如果用戶因為輸入數(shù)據(jù)量很大而需要 執(zhí)行長時間的MapTask或者ReduceTask的話,那么啟動推測執(zhí)行造成的浪費是非常巨大的。
6、Hive嚴格模式
????????所謂嚴格模式,就是強制不允許用戶執(zhí)行有風險的 HiveQL 語句,一旦執(zhí)行會直接失敗。但是Hive中為了提高SQL語句的執(zhí)行效率,可以設(shè)置嚴格模式,充分利用 Hive 的某些特點 。
##?設(shè)置Hive的嚴格模式?
set?hive.mapred.mode=strict;?
set?hive.exec.dynamic.partition.mode=nostrict;
????????注意:當設(shè)置嚴格模式之后,會有如下限制:
1、對于分區(qū)表,必須添加where對于分區(qū)字段的條件過濾?
select?*?from?student_ptn?where?age?>?25?
2、order?by語句必須包含limit輸出限制?
select?*?from?student?order?by?age?limit?100;?
3、限制執(zhí)行笛卡爾積的查詢?
select?a.*,?b.*?from?a,?b;?
4、在hive的動態(tài)分區(qū)模式下,如果為嚴格模式,則必須需要一個分區(qū)列是靜態(tài)分區(qū)
數(shù)據(jù)傾斜
網(wǎng)上關(guān)于如何定位并解決數(shù)據(jù)傾斜的教程很多,但是大多只是點到為止,浮于表面 。這里我們直接引用了《Hive性能調(diào)優(yōu)實戰(zhàn)》中數(shù)據(jù)傾斜部分的內(nèi)容,讓大家能夠體系化學習,徹底掌握 。
????????數(shù)據(jù)傾斜,即單個節(jié)點任務(wù)所處理的數(shù)據(jù)量遠大于同類型任務(wù)所處理的數(shù)據(jù)量,導(dǎo)致該節(jié)點成為整個作業(yè)的瓶頸,這是分布式系統(tǒng)不可能避免的問題。從本質(zhì)來說,導(dǎo)致數(shù)據(jù)傾斜有兩種原因,一是任務(wù)讀取大文件,二是任務(wù)需要處理大量相同鍵的數(shù)據(jù) 。
????????任務(wù)讀取大文件,最常見的就是讀取壓縮的不可分割的大文件。任務(wù)需要處理大量相同鍵的數(shù)據(jù),這種情況有以下4種表現(xiàn)形式:
數(shù)據(jù)含有大量無意義的數(shù)據(jù),例如空值(NULL)、空字符串等 含有傾斜數(shù)據(jù)在進行聚合計算時無法聚合中間結(jié)果,大量數(shù)據(jù)都需要 經(jīng)過Shuffle階段的處理,引起數(shù)據(jù)傾斜 數(shù)據(jù)在計算時做多維數(shù)據(jù)集合,導(dǎo)致維度膨脹引起的數(shù)據(jù)傾斜 兩表進行Join,都含有大量相同的傾斜數(shù)據(jù)鍵
1、不可拆分大文件引發(fā)的數(shù)據(jù)傾斜
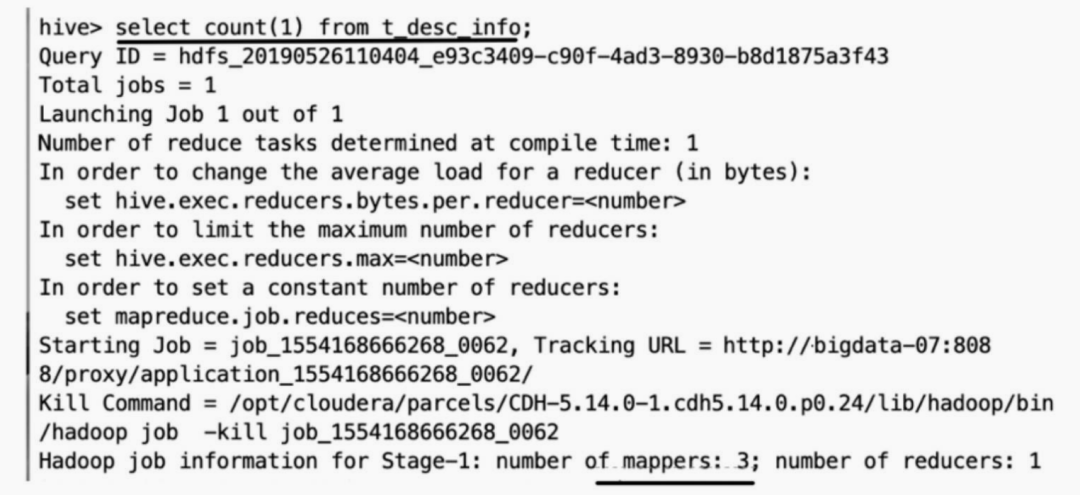
????????當集群的數(shù)據(jù)量增長到一定規(guī)模,有些數(shù)據(jù)需要歸檔或者轉(zhuǎn)儲,這時候往往會對數(shù)據(jù)進行壓縮;當對文件使用GZIP壓縮等不支持文件分割操作的壓縮方式,在日后有作業(yè)涉及讀取壓縮后的文件時,該壓縮文件只會被一個任務(wù)所讀取。如果該壓縮文件很大,則處理該文件的Map需要花費的時間會 遠多于讀取普通文件的Map時間,該Map任務(wù)會成為作業(yè)運行的瓶頸。這種情況也就是Map讀取文件的數(shù)據(jù)傾斜。例如存在這樣一張表t_des_info 。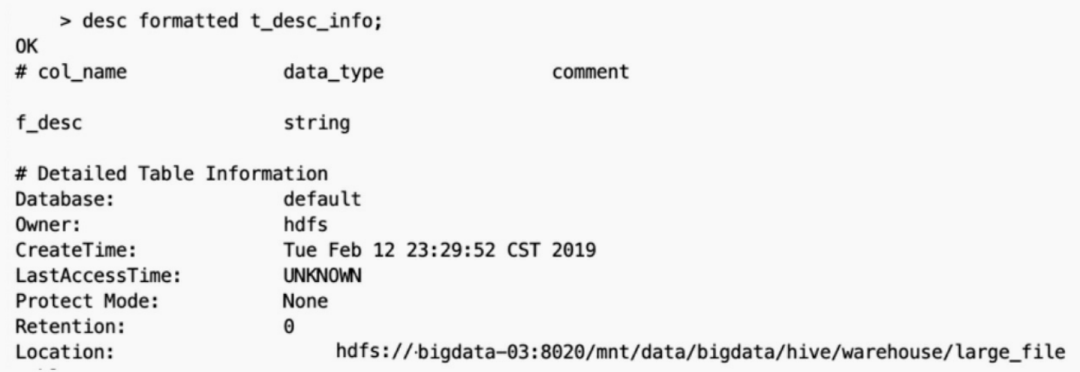 ??????? t_des_info表由3個GZIP壓縮后的文件組成 。
??????? t_des_info表由3個GZIP壓縮后的文件組成 。 ????????其中,
????????其中,large_file.gz文件約200MB,在計算引擎在運行時,預(yù)先設(shè)置每 個Map處理的數(shù)據(jù)量為128MB,但是計算引擎無法切分large_file.gz文件,所 以該文件不會交給兩個Map任務(wù)去讀取,而是有且僅有一個任務(wù)在操作 。
??????? t_des_info表有3個gz文件,任何涉及處理該表的數(shù)據(jù)都只會使用3個 Map。
 ????????為避免因不可拆分大文件而引發(fā)數(shù)據(jù)讀取的傾斜,在數(shù)據(jù)壓縮的時 候可以采用
????????為避免因不可拆分大文件而引發(fā)數(shù)據(jù)讀取的傾斜,在數(shù)據(jù)壓縮的時 候可以采用bzip2和Zip等支持文件分割的壓縮算法。
2、業(yè)務(wù)無關(guān)的數(shù)據(jù)引發(fā)的數(shù)據(jù)傾斜
????????實際業(yè)務(wù)中有些大量的NULL值或者一些無意義的數(shù)據(jù)參與到計算作業(yè) 中,這些數(shù)據(jù)可能來自業(yè)務(wù)未上報或因數(shù)據(jù)規(guī)范將某類數(shù)據(jù)進行歸一化變成空值或空字符串等形式。這些與業(yè)務(wù)無關(guān)的數(shù)據(jù)引入導(dǎo)致在進行分組聚合或者在執(zhí)行表連接時發(fā)生數(shù)據(jù)傾斜。對于這類問題引發(fā)的數(shù)據(jù)傾斜,在計算過 程中排除含有這類“異常”數(shù)據(jù)即可 。
3、 多維聚合計算數(shù)據(jù)膨脹引起的數(shù)據(jù)傾斜
????????在多維聚合計算時存在這樣的場景:select a,b,c,count(1)from T group by a,b,c with rollup。對于上述的SQL,可以拆解成4種類型的鍵進行分組聚合,它們分別是(a,b,c)、(a,b,null)、(a,null,null) 和(null,null,null)。
????????如果T表的數(shù)據(jù)量很大,并且Map端的聚合不能很好地起到數(shù)據(jù)壓縮的 情況下,會導(dǎo)致Map端產(chǎn)出的數(shù)據(jù)急速膨脹,這種情況容易導(dǎo)致作業(yè)內(nèi)存溢 出的異常。如果T表含有數(shù)據(jù)傾斜鍵,會加劇Shuffle過程的數(shù)據(jù)傾斜 。
????????對上述的情況我們會很自然地想到拆解上面的SQL語句,將rollup拆解成如下多個普通類型分組聚合的組合。
select?a,?b,?c,?count(1)?from?T?group?by?a,?b,?c;?
select?a,?b,?null,?count(1)?from?T?group?by?a,?b;?
select?a,?null,?null,?count(1)?from?T?group?by?a;?
select?null,?null,?null,?count(1)?from?T;
????????這是很笨拙的方法,如果分組聚合的列遠不止3個列,那么需要拆解的 SQL語句會更多。在Hive中可以通過參數(shù) (hive.new.job.grouping.set.cardinality)配置的方式自動控制作業(yè)的拆解,該 參數(shù)默認值是30。該參數(shù)表示針對grouping sets/rollups/cubes這類多維聚合的 操作,如果最后拆解的鍵組合(上面例子的組合是4)大于該值,會啟用新的任務(wù)去處理大于該值之外的組合。如果在處理數(shù)據(jù)時,某個分組聚合的列 有較大的傾斜,可以適當調(diào)小該值 。
4、無法削減中間結(jié)果的數(shù)據(jù)量引發(fā)的數(shù)據(jù)傾斜
????????在一些操作中無法削減中間結(jié)果,例如使用collect_list聚合函數(shù),存在如下SQL:
SELECT
????s_age,
????collect_list(s_score)?list_score
FROM
????student_tb_txt
GROUP?BY
????s_age
????????在student_tb_txt表中,s_age有數(shù)據(jù)傾斜,但如果數(shù)據(jù)量大到一定的數(shù) 量,會導(dǎo)致處理傾斜的Reduce任務(wù)產(chǎn)生內(nèi)存溢出的異常。針對這種場景,即 使開啟hive.groupby.skewindata配置參數(shù),也不會起到優(yōu)化的作業(yè),反而會拖累整個作業(yè)的運行。
????????啟用該配置參數(shù)會將作業(yè)拆解成兩個作業(yè),第一個作業(yè)會盡可能將 Map 的數(shù)據(jù)平均分配到Reduce階段,并在這個階段實現(xiàn)數(shù)據(jù)的預(yù)聚合,以減少第二個作業(yè)處理的數(shù)據(jù)量;第二個作業(yè)在第一個作業(yè)處理的數(shù)據(jù)基礎(chǔ)上進行結(jié)果的聚合。
????????hive.groupby.skewindata的核心作用在于生成的第一個作業(yè)能夠有效減少數(shù)量。但是對于collect_list這類要求全量操作所有數(shù)據(jù)的中間結(jié)果的函數(shù)來說,明顯起不到作用,反而因為引入新的作業(yè)增加了磁盤和網(wǎng)絡(luò)I/O的負擔,而導(dǎo)致性能變得更為低下 。
????????解決這類問題,最直接的方式就是調(diào)整Reduce所執(zhí)行的內(nèi)存大小,使用 mapreduce.reduce.memory.mb這個參數(shù)(如果是Map任務(wù)內(nèi)存瓶頸可以調(diào)整 mapreduce.map.memory.mb)。但還存在一個問題,如果Hive的客戶端連接 的HIveServer2一次性需要返回處理的數(shù)據(jù)很大,超過了啟動HiveServer2設(shè)置的Java堆(Xmx),也會導(dǎo)致HiveServer2服務(wù)內(nèi)存溢出。
5、兩個Hive數(shù)據(jù)表連接時引發(fā)的數(shù)據(jù)傾斜
????????兩表進行普通的repartition join時,如果表連接的鍵存在傾斜,那么在 Shuffle階段必然會引起數(shù)據(jù)傾斜 。
????????遇到這種情況,Hive的通常做法還是啟用兩個作業(yè),第一個作業(yè)處理沒有傾斜的數(shù)據(jù),第二個作業(yè)將傾斜的數(shù)據(jù)存到分布式緩存中,分發(fā)到各個 Map任務(wù)所在節(jié)點。在Map階段完成join操作,即MapJoin,這避免了 Shuffle,從而避免了數(shù)據(jù)傾斜。
參考資料
中國好胖子 《hive調(diào)優(yōu)全方位指南》
[2]林志煌 《Hive性能調(diào)優(yōu)實戰(zhàn)》
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!