
漫畫趣解Flink實(shí)時(shí)數(shù)倉(cāng)~
我是Flink,最近我抑郁了~
1 引子(搬橡果)
過冬了,我和小伙伴灰灰開始屯年貨。
今年勞動(dòng)了大半年,我們收獲了整整一車的橡果。眾所周知,我們小松鼠們都喜歡把這些心愛的橡果放到儲(chǔ)藏室。
于是今天起了個(gè)大早,開始搬運(yùn)這些橡果。

不一會(huì),灰灰突然對(duì)我說想要吃一顆昨天摘的灰色小橡果。
我望了望眼前堆積如山的年貨,苦惱的摸了摸腦袋:等我搬到了那顆再給你。

灰灰很不開心,嘴里嘟囔著:為啥昨天不能一摘下來我們就搬呢?
我解釋道: 我們每年都是攢夠一車才一起搬的呀?
看著一邊氣鼓鼓的灰灰,我放緩了搬運(yùn)的速度~
抬頭望著高高的橡果堆嘆了口氣。一邊搬運(yùn),一邊翻找他要的那顆小橡果。。。
今天怕是搬不完了~
2 慢 OR 快?
總結(jié)下,在故事中我們遇到了幾個(gè)小煩惱:
每次都是攢了整車橡果才開始搬運(yùn),無法 及時(shí)拿到想要的灰色小橡果就算我 實(shí)時(shí)搬運(yùn)。之后再要其他小橡果,我還是不能快速找到,完全記不住之前拿過哪些?放到了哪里?
關(guān)鍵詞:速度慢、體量大、及時(shí)性差、 快速查找、可回溯。。
借由這個(gè)小故事,回歸到本文主題。
這些關(guān)鍵詞也是企業(yè)實(shí)時(shí)數(shù)倉(cāng)建設(shè)中常遇到的一些難點(diǎn)和訴求。
2.1 企業(yè)實(shí)時(shí)數(shù)倉(cāng)建設(shè)訴求
大多數(shù)企業(yè)面臨數(shù)據(jù)源多、結(jié)構(gòu)復(fù)雜的問題,為了更好的管理數(shù)據(jù)和賦能價(jià)值,常常會(huì)在集團(tuán)、部門內(nèi)進(jìn)行數(shù)倉(cāng)建設(shè)。
其中一般初期的數(shù)倉(cāng)開發(fā)流程大致如下:
獲取數(shù)據(jù)源,進(jìn)行數(shù)據(jù)清洗、擴(kuò)維、加工,最終輸出業(yè)務(wù)指標(biāo) 根據(jù)不同業(yè)務(wù),重復(fù)進(jìn)行上述流程開發(fā),即 煙囪式開發(fā)。
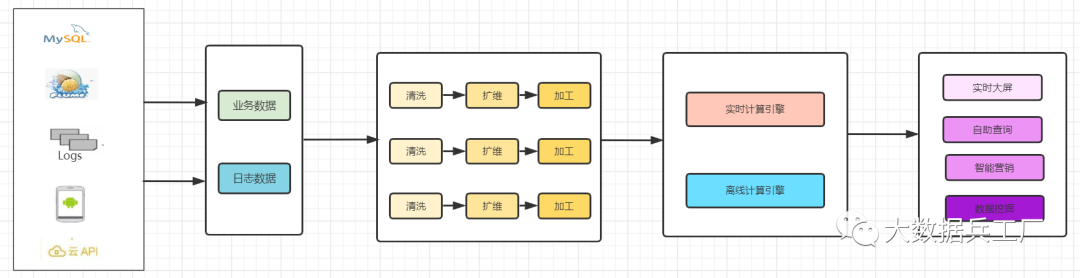
可想而知,隨著業(yè)務(wù)需求的不斷增多,這種煙囪式的開發(fā)模式會(huì)暴露很多問題:
代碼耦合度高 重復(fù)開發(fā) 資源成本高 監(jiān)控難
為此大量企業(yè)的數(shù)據(jù)團(tuán)隊(duì)開始著手?jǐn)?shù)倉(cāng)規(guī)劃,對(duì)數(shù)據(jù)進(jìn)行分層。
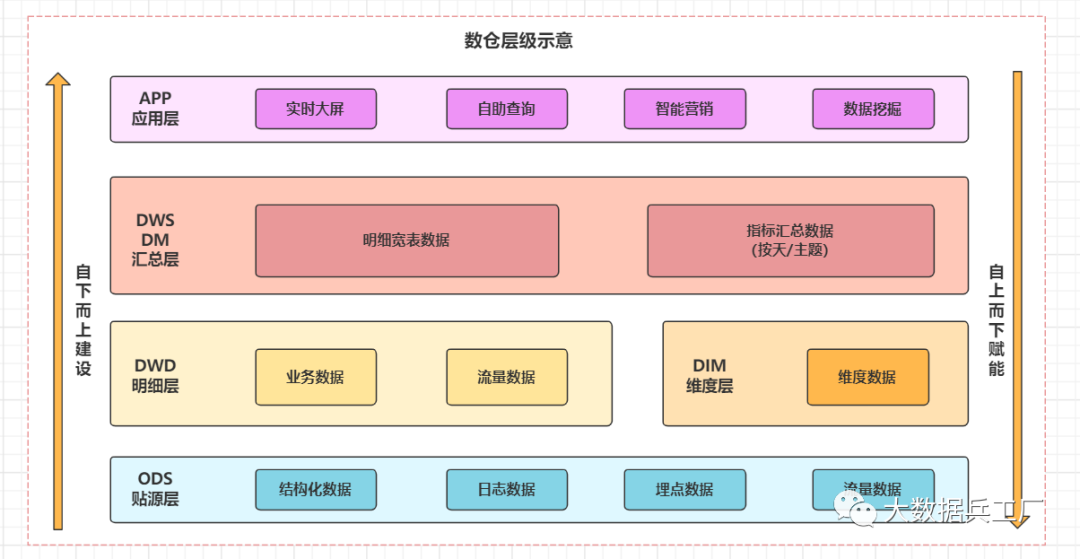
數(shù)據(jù)規(guī)整為層級(jí)存儲(chǔ),每層獨(dú)立加工。整體遵循由下向上建設(shè)思想,最大化數(shù)據(jù)賦能。
數(shù)據(jù)源: 分為 日志數(shù)據(jù)和業(yè)務(wù)數(shù)據(jù)兩大類,包括結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。數(shù)倉(cāng)類型:根據(jù)及時(shí)性分為 離線數(shù)倉(cāng)和實(shí)時(shí)數(shù)倉(cāng)技術(shù)棧: 采集(Sqoop、Flume、CDC) 存儲(chǔ)(Hive、Hbase、Mysql、Kafka、數(shù)據(jù)湖) 加工(Hive、Spark、Flink) OLAP查詢(Kylin、Clickhous、ES、Dorisdb)等。
2.2 穩(wěn)定的離線數(shù)倉(cāng)
業(yè)務(wù)場(chǎng)景
要求每天出一個(gè)當(dāng)日用戶訪問PV、UV流量報(bào)表,結(jié)果輸出到業(yè)務(wù)數(shù)據(jù)庫(kù)
早期規(guī)劃中,在數(shù)據(jù)實(shí)時(shí)性要求不高的前提下,基本一開始都會(huì)選擇建設(shè)離線數(shù)倉(cāng)。
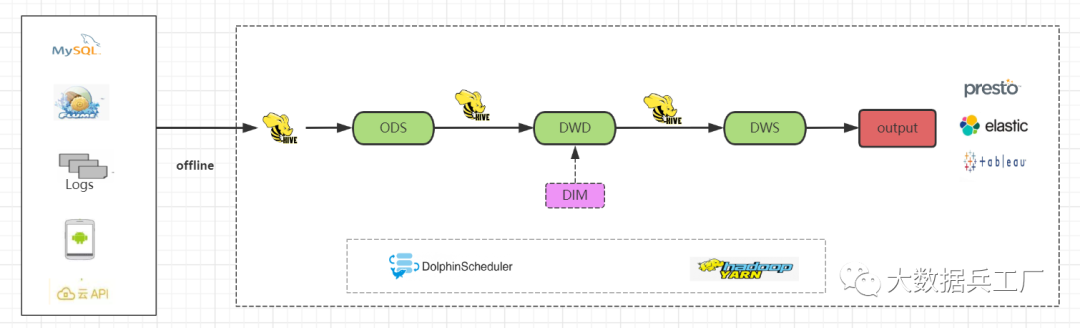
1) 技術(shù)實(shí)現(xiàn)
使用Hive作為數(shù)據(jù)存儲(chǔ)、計(jì)算技術(shù)棧 編寫數(shù)據(jù)同步腳本,抽取數(shù)據(jù)到Hive的ODS層中 在Hive中完成dwd清洗加工、維度建模和dws匯總、主題建模 依賴調(diào)度工具(dophinScheduler)自動(dòng) T+1調(diào)度 olap引擎查詢分析、報(bào)表展示
2) 優(yōu)缺點(diǎn)
配合調(diào)度工具,能夠自動(dòng)化實(shí)現(xiàn)T+1的數(shù)據(jù)采集、加工等全流程處理。技術(shù)棧 簡(jiǎn)單易操作Hive存儲(chǔ)性能高、適合交互式查詢 計(jì)算速度受Hive自身限制,可能因參數(shù)和數(shù)據(jù)分布等差異造成不同程度的數(shù)據(jù) 延遲
3) 改良
既然我們知道了Hive的運(yùn)算速度比較慢,但是又不想放棄其高效的存儲(chǔ)和查詢功能。
那我們?cè)囋嚀Q一種計(jì)算引擎: Spark。
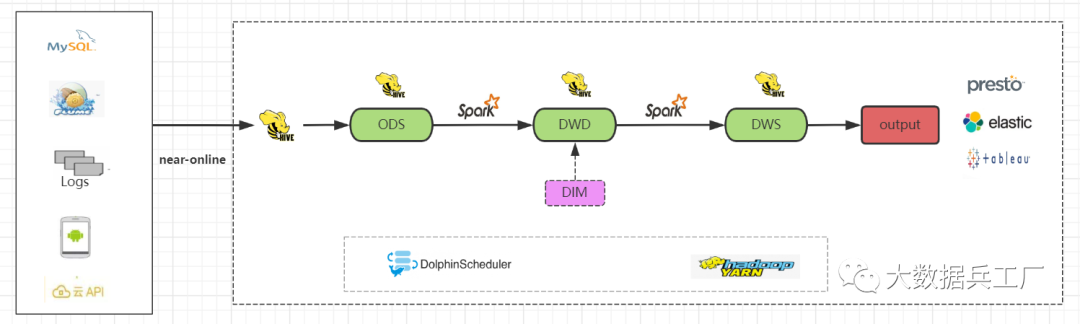
整體流程不變,主要是在ods->dwd->dws層的數(shù)據(jù)加工由Spark負(fù)責(zé)。效果是顯而易見的,比Hive計(jì)算快了不少。
注意Spark是內(nèi)存級(jí)計(jì)算引擎,需要合理規(guī)劃內(nèi)存大小,防止出現(xiàn)OOM(內(nèi)存泄露)。
目前兩種離線數(shù)倉(cāng)均完美的實(shí)現(xiàn)了業(yè)務(wù)需求。領(lǐng)導(dǎo)第二天一看報(bào)表統(tǒng)計(jì),結(jié)果皆大歡喜~
現(xiàn)在考慮換一種場(chǎng)景:不想等到第二天才能看到結(jié)果,要求實(shí)時(shí)展示指標(biāo),此時(shí)需要建設(shè)實(shí)時(shí)數(shù)倉(cāng)。
3 冗余 OR 可回溯 ?
業(yè)務(wù)場(chǎng)景
實(shí)時(shí)統(tǒng)計(jì)每秒用戶訪問PV、UV流量報(bào)表,結(jié)果輸出到業(yè)務(wù)數(shù)據(jù)庫(kù),并支持歷史數(shù)據(jù)回看
既然要求達(dá)到實(shí)時(shí)效果,首先考慮優(yōu)化加工計(jì)算過程。因此需要替換Spark,使用Flink計(jì)算引擎。
在技術(shù)實(shí)現(xiàn)方面,業(yè)內(nèi)常用的實(shí)時(shí)數(shù)倉(cāng)架構(gòu)分為兩種:Lambda架構(gòu)和Kappa架構(gòu)。
3.1 Lambda架構(gòu)
顧名思義,Lambda架構(gòu)保留實(shí)時(shí)、離線兩條處理流程,即最終會(huì)同時(shí)構(gòu)建實(shí)時(shí)數(shù)倉(cāng)和離線數(shù)倉(cāng)。
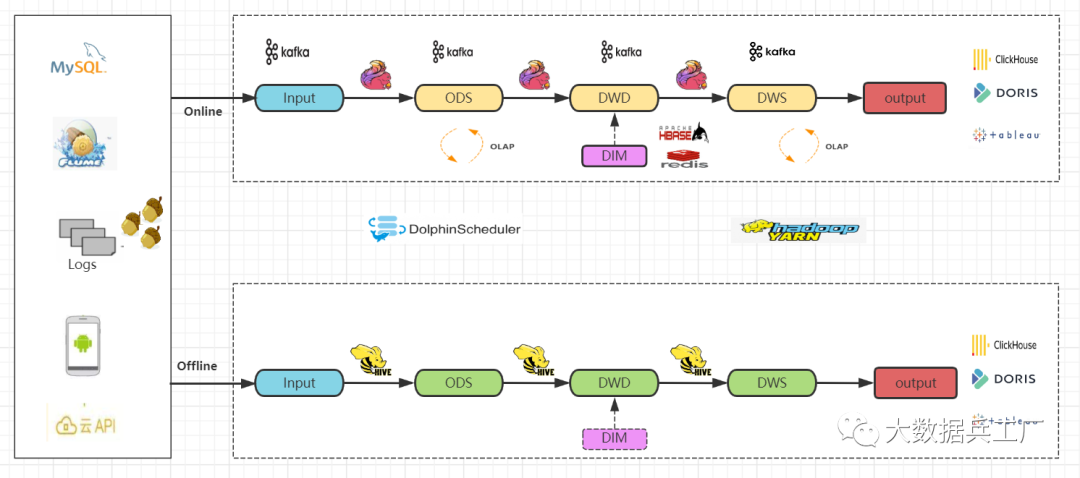
1) 技術(shù)實(shí)現(xiàn)
使用Flink和Kafka、Hive為主要技術(shù)棧 實(shí)時(shí)技術(shù)流程。通過實(shí)時(shí)采集程序同步數(shù)據(jù)到Kafka消息隊(duì)列 Flink實(shí)時(shí)讀取Kafka數(shù)據(jù),回寫到 kafka ods貼源層topicFlink實(shí)時(shí)讀取Kafka的ods層數(shù)據(jù),進(jìn)行實(shí)時(shí)清洗和加工,結(jié)果寫入到 kafka dwd明細(xì)層topic同樣的步驟,F(xiàn)link讀取dwd層數(shù)據(jù)寫入到 kafka dws匯總層topic離線技術(shù)流程和前面章節(jié)一致 實(shí)時(shí)olap引擎查詢分析、報(bào)表展示
2) 優(yōu)缺點(diǎn)
兩套技術(shù)流程,全面保障實(shí)時(shí)性和歷史數(shù)據(jù)完整性 同時(shí)維護(hù)兩套技術(shù)架構(gòu),維護(hù)成本高,技術(shù)難度大 相同數(shù)據(jù)源處理兩次且存儲(chǔ)兩次,產(chǎn)生大量數(shù)據(jù)冗余和操作重復(fù) 容易產(chǎn)生數(shù)據(jù)不一致問題
3) 改良
針對(duì)相同數(shù)據(jù)源被處理兩次這個(gè)點(diǎn),對(duì)上面的Lambda架構(gòu)進(jìn)行改良。
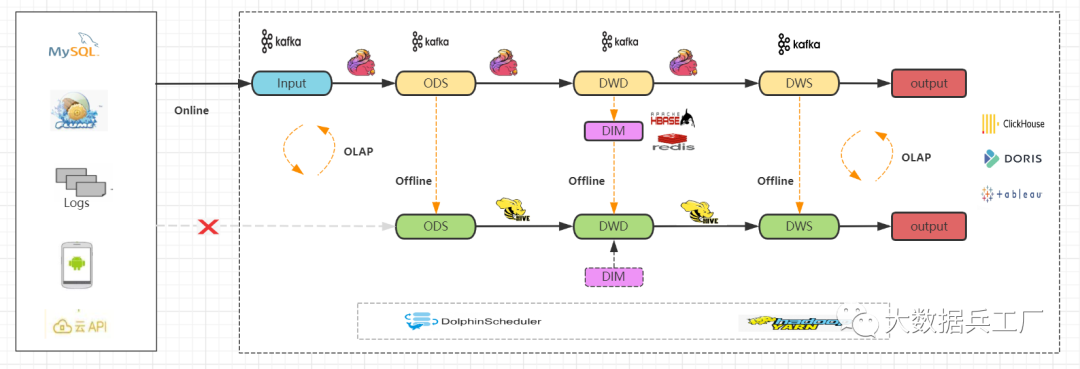
通過將實(shí)時(shí)技術(shù)流的每一層計(jì)算結(jié)果定時(shí)刷新到離線數(shù)倉(cāng)中,數(shù)據(jù)源讀取唯一。大幅減少了數(shù)據(jù)的重復(fù)計(jì)算,加快了程序運(yùn)行時(shí)間。
總結(jié): 數(shù)據(jù)存儲(chǔ)、計(jì)算冗余;歷史數(shù)據(jù)可追溯
3.2 Kappa架構(gòu)
為了解決上述模式下數(shù)據(jù)的冗余存儲(chǔ)和計(jì)算的問題,同時(shí)降低技術(shù)架構(gòu)復(fù)雜度,這里介紹另外一種模式: Kappa架構(gòu)。
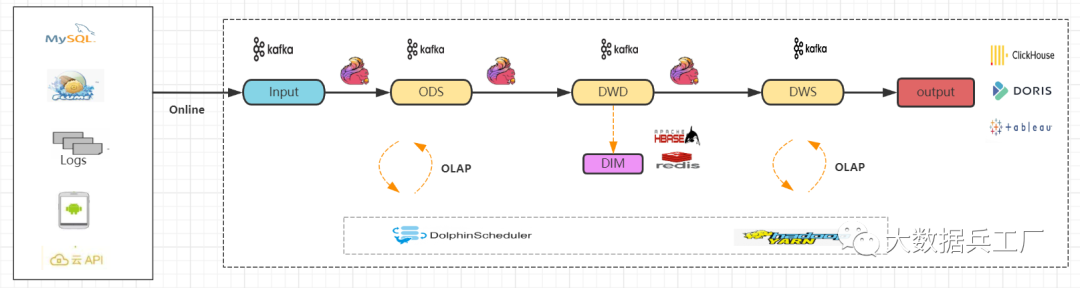
1) 技術(shù)實(shí)現(xiàn)
使用Flink和Kafka為主要技術(shù)棧 實(shí)時(shí)技術(shù)流和Lambda架構(gòu)保持一致 不再進(jìn)行離線數(shù)倉(cāng)構(gòu)建 實(shí)時(shí)olap引擎查詢分析、報(bào)表展示
2) 優(yōu)缺點(diǎn)
單一實(shí)時(shí)數(shù)倉(cāng),強(qiáng)實(shí)時(shí)性,程序性能高 維護(hù)成本和技術(shù)棧復(fù)雜度遠(yuǎn)遠(yuǎn)低于Lambda架構(gòu) 源頭數(shù)據(jù)僅作為實(shí)時(shí)數(shù)據(jù)流被計(jì)算、存儲(chǔ),數(shù)據(jù)僅被處理一次。 數(shù)據(jù)回溯難。依賴Kafka存儲(chǔ),歷史數(shù)據(jù)會(huì)丟失 olap查詢難。Kafka需要引入其他對(duì)接工具實(shí)現(xiàn)olap查詢,Kafka天生不適合olap分析。
總結(jié): 數(shù)據(jù)存儲(chǔ)計(jì)算僅一次;歷史數(shù)據(jù)回溯難
總體而言,第一種Lambda架構(gòu)雖然有諸多缺點(diǎn),但是具備程序穩(wěn)健性和數(shù)據(jù)完整性,因此在企業(yè)中用的會(huì)比較多。
相反Kappa架構(gòu)用的比較少。因?yàn)镵appa架構(gòu)僅使用Kafka作為存儲(chǔ)組件,需要同時(shí)滿足數(shù)據(jù)完整性和實(shí)時(shí)讀寫,這明顯很難做到。
Kappa架構(gòu)的實(shí)時(shí)數(shù)倉(cāng)道路將何去何從?
4 數(shù)據(jù)湖&實(shí)時(shí)數(shù)倉(cāng)
我們明白,Kafka的定位是消息隊(duì)列,可作為熱點(diǎn)數(shù)據(jù)的緩存介質(zhì),對(duì)于數(shù)據(jù)查詢和存儲(chǔ)其實(shí)并不適合。
如果能夠找到一個(gè)替代Kafka的實(shí)時(shí)數(shù)據(jù)庫(kù)就好了。。
預(yù)期要求
1)能夠支持?jǐn)?shù)據(jù)回溯和數(shù)據(jù)更新
2)實(shí)現(xiàn)數(shù)據(jù)批流讀寫,支持實(shí)時(shí)接入
4.1 數(shù)據(jù)湖技術(shù)
近些年,隨著數(shù)據(jù)湖技術(shù)的興起,仿佛看到了一絲希望。
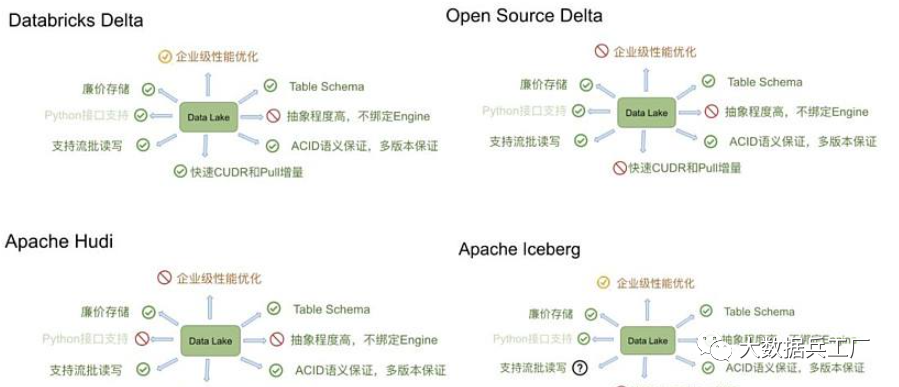
目前市場(chǎng)上最流行的數(shù)據(jù)湖為三種: Delta、Apache Hudi和Apache Iceberg。
其中Delta和Apache Hudi對(duì)于多數(shù)計(jì)算引擎的支持度不夠,特別是Delta完全是由Spark衍生而來,不支持Flink。
其中的Iceberg,F(xiàn)link是完全實(shí)現(xiàn)了對(duì)接機(jī)制。看看其具備的功能:
基于 快照的讀寫分離和回溯流批統(tǒng)一的寫入和讀取非強(qiáng)制綁定計(jì)算引擎 支持 ACID語義支持表、分區(qū)的 變更特性
4.2 kappa架構(gòu)升級(jí)
因此考慮對(duì)Kappa架構(gòu)進(jìn)行升級(jí),使用Flink + Iceberg(Hudi)技術(shù)架構(gòu),可以解決Kappa架構(gòu)中的一些問題。
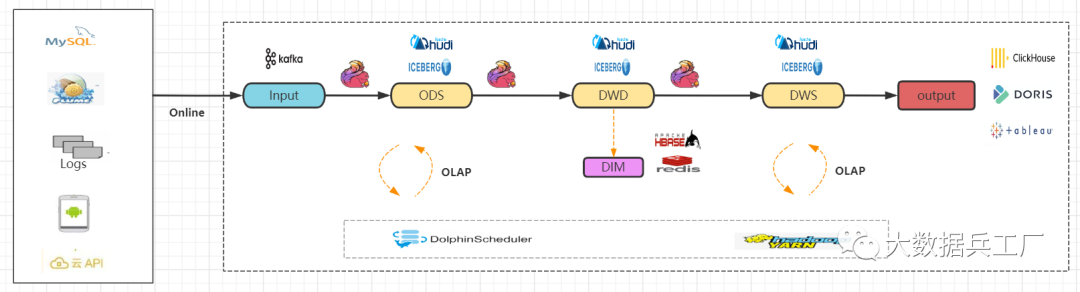
存儲(chǔ)介質(zhì)由Kafka換成Iceberg(Hudi),其余技術(shù)棧保持不變 Flink讀取源頭Kafka數(shù)據(jù),結(jié)果存儲(chǔ)到Iceberg ods層 繼續(xù)執(zhí)行后續(xù)的ods->dwd->dws層計(jì)算、結(jié)果存儲(chǔ) Iceberg(Hudi)支持流批一體查詢,過程中支持olap查詢 實(shí)時(shí)olap引擎查詢分析、報(bào)表展示
目前Flink社區(qū)關(guān)于Iceberg(Hudi)的建設(shè)已經(jīng)逐漸成熟,其中很多大廠開始基于Flink + Iceberg(Hudi)打造企業(yè)級(jí)實(shí)時(shí)數(shù)倉(cāng)。
更多實(shí)時(shí)數(shù)倉(cāng)問題,可以咨詢我的wx: youlong525.
5 電商零售實(shí)時(shí)數(shù)倉(cāng)實(shí)戰(zhàn)
紙上得來終覺淺,這里簡(jiǎn)單介紹一下老兵之前做過的實(shí)時(shí)數(shù)倉(cāng)案例。
使用的技術(shù)棧可能有點(diǎn)老,主要探討下建設(shè)思路。
5.1 技術(shù)架構(gòu)
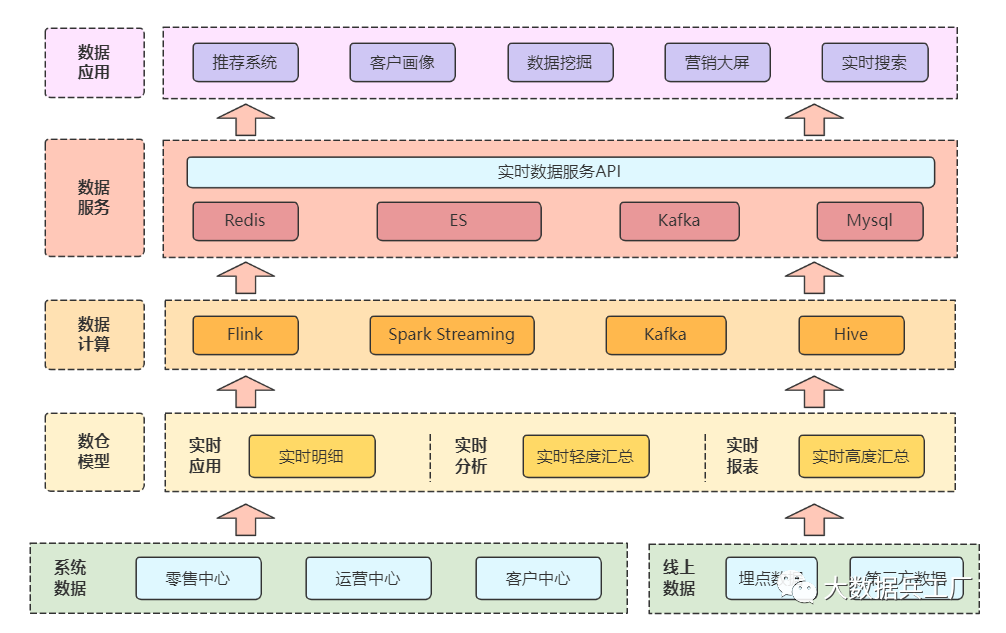
系統(tǒng)整體采用Flink + Spark + Kafka為主要技術(shù)棧,由底向上構(gòu)建電商零售實(shí)時(shí)數(shù)倉(cāng),最終提供統(tǒng)一的數(shù)據(jù)服務(wù)。
1)底層使用Flink CDC技術(shù)實(shí)時(shí)抽取源數(shù)據(jù),包括業(yè)務(wù)系統(tǒng)和第三方埋點(diǎn)數(shù)據(jù)(客戶中心、營(yíng)銷中心、銷售中心)。
// data格式
{
"data": [
{
"id": "13",
"order_id": "6BB4837EB74E4568DDA7DC67ED2CA2AD9",
"order_code": "order_x001",
"price": "135.00"
}
]
}
// flink cdc (示例)
CREATE TABLE order_detail_table (
id BIGINT,
order_id STRING,
order_code STRING,
price DECIMAL(10, 2)
) WITH (
'connector' = 'kafka',
'topic' = 'order_binlog',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'group001',
'canal-json.ignore-parse-errors'='true'
);
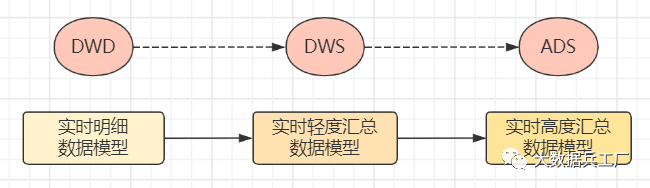
2)數(shù)據(jù)源經(jīng)過計(jì)算引擎和決策引擎轉(zhuǎn)換,構(gòu)建實(shí)時(shí)明細(xì)、實(shí)時(shí)輕度匯總、實(shí)時(shí)高度匯總模型,即對(duì)應(yīng)數(shù)倉(cāng)分層: DWD、DWS、ADS層。
初步規(guī)劃技術(shù)棧為Spark Streaming + Kafka。后期因?qū)崟r(shí)性要求,改為Flink + Kafka,滿足秒級(jí)響應(yīng)。
3)構(gòu)建完實(shí)時(shí)數(shù)倉(cāng)模型后,數(shù)據(jù)轉(zhuǎn)存至存儲(chǔ)介質(zhì)。包括ES、Redis、Mysql、Kafka等,并最終向外提供API共享服務(wù)訪問。
// 存儲(chǔ)介質(zhì)API服務(wù)
val esServices = new EsHandler[BaseHandler](dataFlows)
val kafkaServices = new KafkaHandler[BaseHandler](dataFlows)
val redisServices = new RedisHandler[BaseHandler](dataFlows)
val jdbcServices = new JDBCHandler[BaseHandler](dataFlows)
esServices.handle(args)
kafkaServices.handle(args)
redisServices.handle(args)
jdbcServices.handle(args)
4)最終向外提供API服務(wù),為企業(yè)的智能推薦、會(huì)員畫像、數(shù)據(jù)挖掘、營(yíng)銷大屏等應(yīng)用服務(wù)提供數(shù)據(jù)支撐。
5.2 數(shù)據(jù)流程
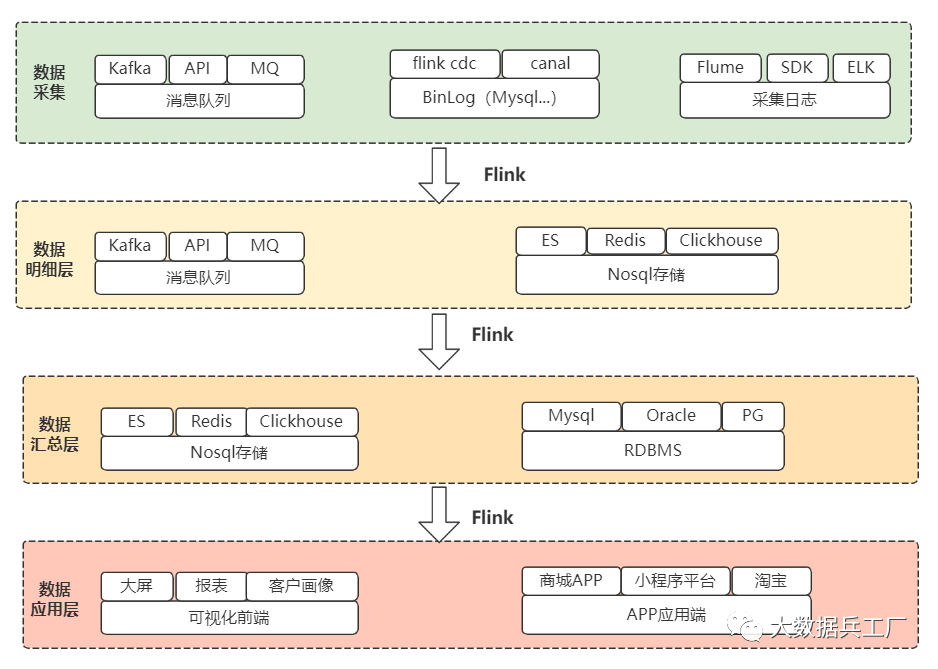
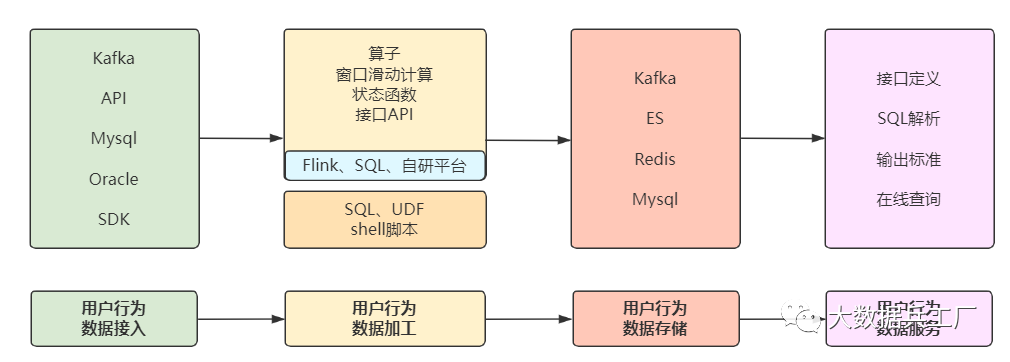
整體從上而下,數(shù)據(jù)經(jīng)過采集 -> 數(shù)倉(cāng)明細(xì)加工、匯總 -> 應(yīng)用步驟,提供實(shí)時(shí)數(shù)倉(cāng)服務(wù)。
這里列舉用戶分析的數(shù)據(jù)流程和技術(shù)路線:
采集用戶行為數(shù)據(jù),統(tǒng)計(jì)用戶曝光點(diǎn)擊信息,構(gòu)建用戶畫像。
6 實(shí)時(shí)數(shù)倉(cāng)的優(yōu)化與總結(jié)
1)實(shí)時(shí)數(shù)倉(cāng)到底是Lambda架構(gòu)還是Kappa架構(gòu)好?
這個(gè)沒有標(biāo)準(zhǔn)答案。這里給個(gè)建議:一般中小型項(xiàng)目或需要保證歷史數(shù)據(jù)的完整性,建議使用Lambda架構(gòu)構(gòu)建,提供離線流程保障。目前Kappa架構(gòu)用的不多,受場(chǎng)景和實(shí)時(shí)技術(shù)棧因素影響。
2)數(shù)據(jù)丟失怎么辦?
如果是數(shù)據(jù)源丟失,可以重新消費(fèi)(offset位置);如果是Flink窗口數(shù)據(jù)延遲:可手動(dòng)調(diào)大延遲時(shí)間,延緩窗口關(guān)閉;或者使用側(cè)輸出流保存延遲數(shù)據(jù),再合并處理;也可以延遲數(shù)據(jù)寫入存儲(chǔ)介質(zhì),后續(xù)統(tǒng)一處理。
3)實(shí)時(shí)計(jì)算中數(shù)據(jù)重復(fù)怎么辦?
內(nèi)存去重:數(shù)據(jù)量不大建議使用flink的 state結(jié)構(gòu)或者借助bitmap結(jié)構(gòu)稍微大點(diǎn)可以用 布隆過濾器或hyperlog(借助工具)外部介質(zhì)(redis或hbase)設(shè)計(jì)好 key實(shí)現(xiàn)自動(dòng)去重,存在存儲(chǔ)成本
4)如何進(jìn)行多條實(shí)時(shí)流JOIN
Flink內(nèi)部提供JOIN算子操作,包括JOIN、window JOIN、Interval Join和connect等算子,詳情請(qǐng)查看我的Flink雙流JOIN文章。
5)實(shí)時(shí)任務(wù)和離線任務(wù)怎么調(diào)度
給YARN任務(wù)打上標(biāo)簽,將離線和實(shí)時(shí)分開,提交作業(yè)時(shí)指定Lable;同時(shí)調(diào)整Yarn的調(diào)度參數(shù),合理分配多container執(zhí)行。
--END--

非常歡迎大家加我個(gè)人微信,有關(guān)大數(shù)據(jù)的問題我們?cè)?strong style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;">群內(nèi)一起討論
長(zhǎng)按上方掃碼二維碼,加我微信,拉你進(jìn)群