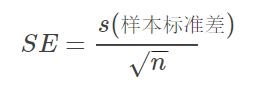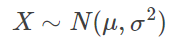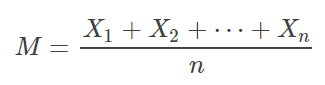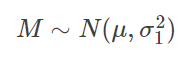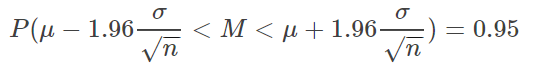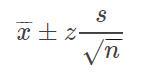點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

來(lái)自?| CSDN博客? 作者 |?bitcarmanlee
編輯 | 深度學(xué)習(xí)這件小事公眾號(hào)
本文僅作學(xué)術(shù)交流,如有侵權(quán),請(qǐng)聯(lián)系后臺(tái)刪除。
? ?1.點(diǎn)估計(jì)與區(qū)間估計(jì)
是用樣本統(tǒng)計(jì)量來(lái)估計(jì)總體參數(shù),因?yàn)闃颖窘y(tǒng)計(jì)量為數(shù)軸上某一點(diǎn)值,估計(jì)的結(jié)果也以一個(gè)點(diǎn)的數(shù)值表示,所以稱為點(diǎn)估計(jì)。點(diǎn)估計(jì)雖然給出了未知參數(shù)的估計(jì)值,但是未給出估計(jì)值的可靠程度,即估計(jì)值偏離未知參數(shù)真實(shí)值的程度。給定置信水平,根據(jù)估計(jì)值確定真實(shí)值可能出現(xiàn)的區(qū)間范圍,該區(qū)間通常以估計(jì)值為中心,該區(qū)間則為置信區(qū)間。???2.中心極限定理與大數(shù)定理
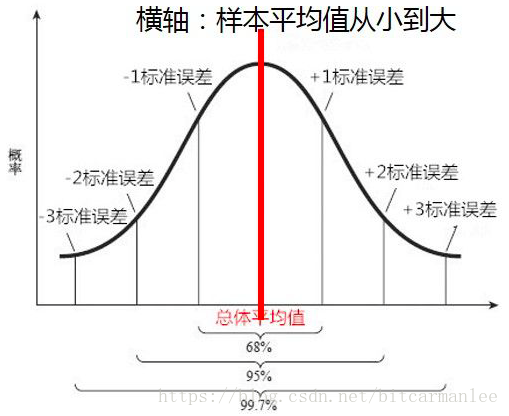
在適當(dāng)?shù)臈l件下,大量相互獨(dú)立隨機(jī)變量的均值經(jīng)適當(dāng)標(biāo)準(zhǔn)化后依分布收斂于正態(tài)分布。例如我們要計(jì)算全中國(guó)人的平均身高。如果每次取10000個(gè)身高作為樣本,對(duì)應(yīng)有一個(gè)樣本均值。如果再?gòu)目傮w中重復(fù)抽取n多次10000個(gè)樣本,就對(duì)應(yīng)有n個(gè)樣本均值。隨著n增大,把所有樣本均值畫出來(lái),得到的就是一個(gè)接近正太分布的曲線。取樣數(shù)趨近無(wú)窮時(shí),樣品平均值按概率收斂于期望值。拋硬幣的次數(shù)越多,越接近正反各一半。???3.置信區(qū)間與置信水平
一般我們用中括號(hào)[a,b]表示樣本估計(jì)總體平均值誤差范圍的區(qū)間。a、b的具體數(shù)值取決于你對(duì)于”該區(qū)間包含總體均值”這一結(jié)果的可信程度,因此[a,b]被稱為置信區(qū)間。一般來(lái)說(shuō),選定某一個(gè)置信區(qū)間,我們的目的是為了讓”ab之間包含總體平均值”的結(jié)果有一特定的概率,這個(gè)概率就是所謂的置信水平。例如我們最常用的95%置信水平,就是說(shuō)做100次抽樣,有95次的置信區(qū)間包含了總體均值。???4.標(biāo)準(zhǔn)差(standard deviation)與標(biāo)準(zhǔn)誤差(standard error)
標(biāo)準(zhǔn)差是描述觀察值(個(gè)體值)之間的變異程度(例如一個(gè)人打十次靶子的成績(jī),這時(shí)有一個(gè)平均數(shù)8,有一個(gè)反映他成績(jī)穩(wěn)定與否的標(biāo)準(zhǔn)差);標(biāo)準(zhǔn)誤是描述樣本均數(shù)的抽樣誤差(例如十次抽樣,每次他成績(jī)平均數(shù)(7,8,6,9,5,6,7,7,8,9)的標(biāo)準(zhǔn)差,也就是抽樣分布的標(biāo)準(zhǔn)差);SE=s(样本标准差)n" role="presentation" style="">???5.如何理解95%的置信區(qū)間
以上面的統(tǒng)計(jì)身高為例,假設(shè)全國(guó)人民的身高服從正態(tài)分布:不斷進(jìn)行采樣,假設(shè)樣本的大小為n,則樣本的均值為:注意σ1" role="presentation" style="">σ1的計(jì)算方法為第4部分提到的標(biāo)準(zhǔn)誤差!對(duì)照上圖,用一句簡(jiǎn)單的話概括就是:有95%的樣本均值會(huì)落在2個(gè)(比較精確的值是1.96)標(biāo)準(zhǔn)誤差范圍內(nèi)。P(μ−1.96σn<M<μ+1.96σn)=0.95" role="presentation" style="">???6.計(jì)算置信區(qū)間的套路
從上面的例子來(lái)看,計(jì)算置信區(qū)間的套路如下:1.首先明確要求解的問(wèn)題。比如我們的例子,就是想通過(guò)樣本來(lái)估計(jì)全國(guó)人民身高的平均值。2.求抽樣樣本的平均值與標(biāo)準(zhǔn)誤差(standard error)。注意標(biāo)準(zhǔn)誤差與標(biāo)準(zhǔn)差(standard deviation)不一樣。3.確定需要的置信水平。比如常用的95%的置信水平,這樣可以保證樣本的均值會(huì)落在總體平均值2個(gè)標(biāo)準(zhǔn)差得范圍內(nèi)。a = 樣本均值 - z*標(biāo)準(zhǔn)誤差
b = 樣本均值 + z*標(biāo)準(zhǔn)誤差其中,x¯" role="presentation" style="">xˉ表示樣本的均值,z" role="presentation" style="">z值表示有多少標(biāo)準(zhǔn)差,s" role="presentation" style="">s為樣本的方差。
原文鏈接:https://blog.csdn.net/bitcarmanlee/article/details/82709774
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。下載2:Python+OpenCV視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。下載3:Pytorch常用函數(shù)手冊(cè)在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):pytorch常用函數(shù)手冊(cè),即可下載含有200余個(gè)Pytorch常用函數(shù)的使用方式,幫助快速入門深度學(xué)習(xí)。交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~