
PP-Structure簡介
pp-Structure整體包括三個方面:版面分析(layout analysis)、表格識別(table recognition)和關(guān)鍵信息抽取(key information extraction)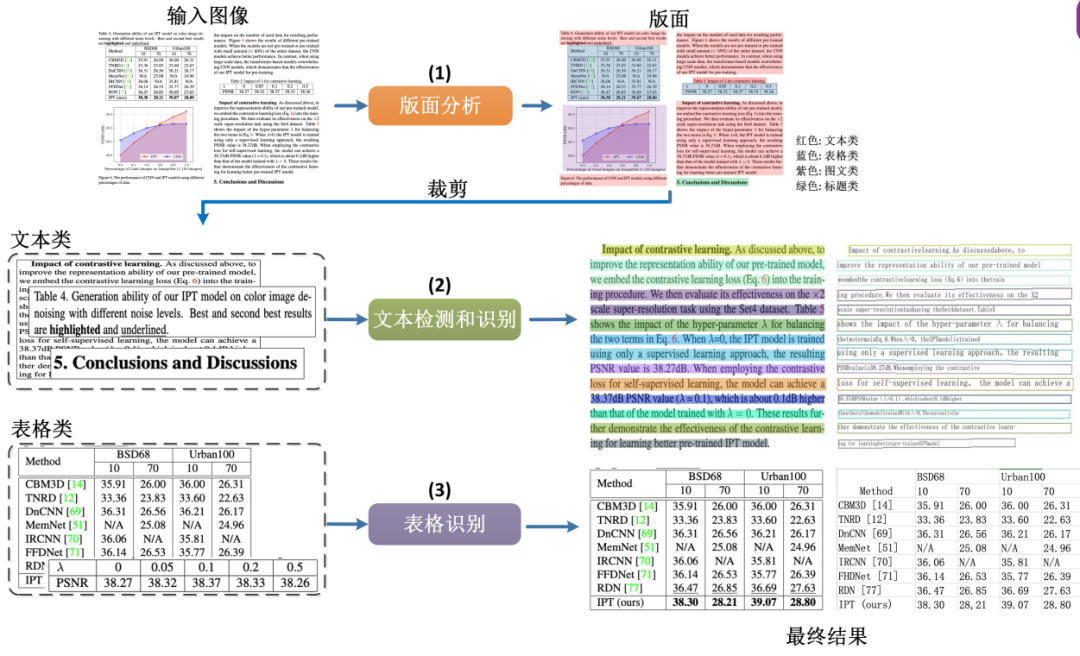
1. 版面分析
-
版面分析指的是對圖片形式的文檔進(jìn)行區(qū)域劃分,定位其中的關(guān)鍵區(qū)域,如文字、標(biāo)題、表格、圖片等。版面分析算法基于PaddleDetection的輕量模型PP-PicoDet進(jìn)行開發(fā),包含英文、中文、表格版面分析3類模型。其中,英文模型支持Text、Title、Tale、Figure、List5類區(qū)域的檢測,中文模型支持Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation10類區(qū)域的檢測,表格版面分析支持Table區(qū)域的檢測,版面分析效果如下圖所示:

-
數(shù)據(jù)集:
dataset 簡介 PubLayNet PubLayNet是一個用于文檔布局分析的數(shù)據(jù)集。它包含了研究論文和文章的圖像,以及這些研究論文圖像中的“文本”、“列表”、“圖形”等頁面中各種元素的注釋。該數(shù)據(jù)集是通過自動匹配PubMed Central上公開的100多萬篇PDF文章的XML表示和內(nèi)容來獲得 cTDaR2019_cTDaR 用于表格檢測(TRACKA)和表格識別(TRACKB)。圖片類型包含歷史數(shù)據(jù)集(以cTDaR_t0開頭,如cTDaR_t00872.jpg)和現(xiàn)代數(shù)據(jù)集(以cTDaR_t1開頭,cTDaR_t10482.jpg) IIIT-AR-13K 手動注釋公開的年度報告中的圖形或頁面而構(gòu)建的數(shù)據(jù)集,包含5類:table, figure, natural image, logo, and signature ?? CDLA 中文文檔版面分析數(shù)據(jù)集,面向中文文獻(xiàn)類(論文)場景,包含10類:Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation ?? TableBank 用于表格檢測和識別大型數(shù)據(jù)集,包含Word和Latex2種文檔格式 DocBank 使用弱監(jiān)督方法構(gòu)建的大規(guī)模數(shù)據(jù)集(500K文檔頁面),用于文檔布局分析,包含12類:Author、Caption、Date、Equation、Figure、Footer、List、Paragraph、Reference、Section、Table、Title -
模型:PP-YOLO V2 / PP-PicoDet(可以嘗試用YOLOv8)
關(guān)于pp-structure的版面分析模型列表,具體可以查看鏈接1
模型名稱 模型簡介 picodet_lcnet_x1_0_fgd_layout 基于PicoDet LCNet_x1_0和FGD蒸餾在PubLayNet 數(shù)據(jù)集訓(xùn)練的英文版面分析模型,可以劃分文字、標(biāo)題、表格、圖片以及列表5類區(qū)域 ppyolov2_r50vd_dcn_365e_publaynet 基于PP-YOLOv2在PubLayNet數(shù)據(jù)集上訓(xùn)練的英文版面分析模型 picodet_lcnet_x1_0_fgd_layout_cdla CDLA數(shù)據(jù)集訓(xùn)練的中文版面分析模型,可以劃分為表格、圖片、圖片標(biāo)題、表格、表格標(biāo)題、頁眉、腳本、引用、公式10類區(qū)域 picodet_lcnet_x1_0_fgd_layout_table 表格數(shù)據(jù)集訓(xùn)練的版面分析模型,支持中英文文檔表格區(qū)域的檢測 ppyolov2_r50vd_dcn_365e_tableBank_word 基于PP-YOLOv2在TableBank Word 數(shù)據(jù)集訓(xùn)練的版面分析模型,支持英文文檔表格區(qū)域的檢測 ppyolov2_r50vd_dcn_365e_tableBank_latex 基于PP-YOLOv2在TableBank Latex數(shù)據(jù)集訓(xùn)練的版面分析模型,支持英文文檔表格區(qū)域的檢測
2. 表格識別
-
表格識別主要包含三個模型
- 單行文本檢測-DB
- 單行文本識別-CRNN
- 表格結(jié)構(gòu)和cell坐標(biāo)預(yù)測-SLANet(數(shù)據(jù)集:PubTabNet)
具體流程圖如下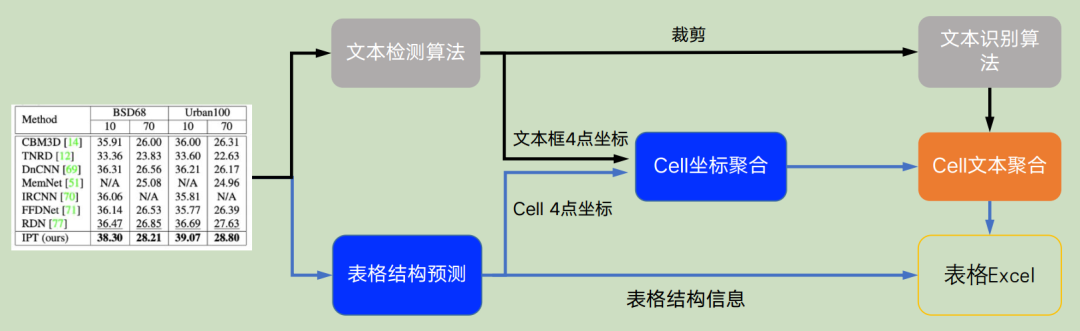 流程說明:
流程說明:
- 圖片由單行文字檢測模型檢測到單行文字的坐標(biāo),然后送入識別模型拿到識別結(jié)果。
- 圖片由SLANet模型拿到表格的結(jié)構(gòu)信息和單元格的坐標(biāo)信息。
- 由單行文字的坐標(biāo)、識別結(jié)果和單元格的坐標(biāo)一起組合出單元格的識別結(jié)果。
- 單元格的識別結(jié)果和表格結(jié)構(gòu)一起構(gòu)造表格的html字符串。
模型列表,具體可以查看鏈接2
| 模型名稱 | 模型簡介 |
|---|---|
| en_ppocr_mobile_v2.0_table_structure | 基于TableRec-RARE在PubTabNet數(shù)據(jù)集上訓(xùn)練的英文表格識別模型 |
| en_ppstructure_mobile_v2.0_SLANet | 基于SLANet在PubTabNet數(shù)據(jù)集上訓(xùn)練的英文表格識別模型 |
| ch_ppstructure_mobile_v2.0_SLANet | 基于SLANet的中文表格識別模型 |
3. 關(guān)鍵信息抽取
-
關(guān)鍵信息抽取 (Key Information Extraction, KIE)指的是是從文本或者圖像中,抽取出關(guān)鍵的信息。針對文檔圖像的關(guān)鍵信息抽取任務(wù)作為OCR的下游任務(wù),存在非常多的實際應(yīng)用場景,如表單識別、車票信息抽取、身份證信息抽取等。
-
基于多模態(tài)模型的關(guān)鍵信息抽取任務(wù)有2種主要的解決方案:
SER: 語義實體識別 (Semantic Entity Recognition),對每一個檢測到的文本進(jìn)行分類,如將其分為姓名,身份證。如下圖中的黑色框和紅色框。
RE: 關(guān)系抽取 (Relation Extraction),對每一個檢測到的文本進(jìn)行分類,如將其分為問題 (key) 和答案 (value) 。然后對每一個問題找到對應(yīng)的答案,相當(dāng)于完成key-value的匹配過程。如下圖中的紅色框和黑色框分別代表問題和答案,黃色線代表問題和答案之間的對應(yīng)關(guān)系。
 (關(guān)于上述解決方案的詳細(xì)介紹,請參考關(guān)鍵信息抽取全流程指南(鏈接3)
(關(guān)于上述解決方案的詳細(xì)介紹,請參考關(guān)鍵信息抽取全流程指南(鏈接3)
- 文本檢測 + 文本識別 + 語義實體識別(SER)
- 文本檢測 + 文本識別 + 語義實體識別(SER) + 關(guān)系抽取(RE)
PP-Structure 中的KIE任務(wù),是基于 LayoutXLM 文檔多模態(tài)系列方法進(jìn)行的研究與優(yōu)化,設(shè)計了視覺特征無關(guān)的多模態(tài)模型結(jié)構(gòu)VI-LayoutXLM,同時引入符合閱讀順序的文本行排序方法以及UDML聯(lián)合互學(xué)習(xí)蒸餾方法,最終在精度與速度均超越LayoutXLM。其主要特性如下:
- 集成LayoutXLM、VI-LayoutXLM等多模態(tài)模型以及PP-OCR預(yù)測引擎。
- 支持基于多模態(tài)方法的語義實體識別 (Semantic Entity Recognition, SER) 以及關(guān)系抽取 (Relation Extraction, RE) 任務(wù)。基于 SER 任務(wù),可以完成對圖像中的文本識別與分類;基于 RE 任務(wù),可以完成對圖象中的文本內(nèi)容的關(guān)系提取,如判斷問題對(pair)。
- 支持SER任務(wù)和RE任務(wù)的自定義訓(xùn)練。
- 支持OCR+SER的端到端系統(tǒng)預(yù)測與評估。
- 支持OCR+SER+RE的端到端系統(tǒng)預(yù)測。
- 支持SER模型的動轉(zhuǎn)靜導(dǎo)出與基于PaddleInfernece的模型推理。
數(shù)據(jù)集:XFUND_zh
模型列表,具體可以查看鏈接4
| 模型名稱 | 模型簡介 |
|---|---|
| ser_VI-LayoutXLM_xfund_zh | 基于VI-LayoutXLM在xfund中文數(shù)據(jù)集上訓(xùn)練的SER模型 |
| re_VI-LayoutXLM_xfund_zh | 基于VI-LayoutXLM在xfund中文數(shù)據(jù)集上訓(xùn)練的RE模型 |
| ser_LayoutXLM_xfund_zh | 基于LayoutXLM在xfund中文數(shù)據(jù)集上訓(xùn)練的SER模型 |
| re_LayoutXLM_xfund_zh | 基于LayoutXLM在xfund中文數(shù)據(jù)集上訓(xùn)練的RE模型 |
| ser_LayoutLMv2_xfund_zh | 基于LayoutLMv2在xfund中文數(shù)據(jù)集上訓(xùn)練的SER模型 |
| re_LayoutLMv2_xfund_zh | 基于LayoutLMv2在xfun中文數(shù)據(jù)集上訓(xùn)練的RE模型 |
| ser_LayoutLM_xfund_zh | 基于LayoutLM在xfund中文數(shù)據(jù)集上訓(xùn)練的SER模型 |
鏈接
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/docs/models_list.md#1-%E7%89%88%E9%9D%A2%E5%88%86%E6%9E%90%E6%A8%A1%E5%9E%8B
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/docs/models_list.md#22-%E8%A1%A8%E6%A0%BC%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/kie/how_to_do_kie.md
- https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/docs/models_list.md#3-kie%E6%A8%A1%E5%9E%8B