
什么是算法?從枚舉到貪心再到啟發(fā)式(上)
??
??
并且假定屏幕前的你只有大一剛學(xué)完譚浩強紅本本的水平
從背包問題說起
 ?kg的物品。
?kg的物品。現(xiàn)在有
 個物品擺在你面前,每個物品都有自己的重量
個物品擺在你面前,每個物品都有自己的重量 和價值
和價值 。
。好了,現(xiàn)在要你做成決策了:究竟選哪些物品裝進背包,才能使得在不超過背包容量的情況下,獲得最大的價值呢?
![]()
★好了,現(xiàn)在我們遇到了一個問題,得想想辦法來解決它!? ? ? 在此之前我們再講一點東西,觀察上面的問題,能發(fā)現(xiàn)什么特點呢?
![]()
一般而言,算法所需要解決的問題,都能分成兩個部分:
·?目標:什么是目標呢?簡單點說就是要優(yōu)化的東西,比如在上述背包問題中,要優(yōu)化的就是所選物品的價值,使其最大。
· 決策:顧名思義就是根據(jù)目標所作出的決策,比如在這里就是決定選取哪些物品裝進我們的背包。
· 約束:那么何又為約束呢?就是說再進行決策時必須遵循的條件,比如上面的背包問題,我們所選取的物品總的重量不能超過背包的容量。要是沒有容量的約束,小學(xué)生才做選擇呢,我全都要!

算例
知道了問題以后就可以生成問題的算例了那么什么又是問題的算例呢?就是問題參數(shù)的具體化
比如在上述的0-1背包問題中,背包的容量
 現(xiàn)在問題知道了算例也有了我們再來談?wù)?strong>什么是Benchmark?
現(xiàn)在問題知道了算例也有了我們再來談?wù)?strong>什么是Benchmark?Benchmark就是求解問題算例的一個基準,比如在剛剛的背包問題算例中,最優(yōu)解很容易看得出是選取第3個物品(注:本文所有序數(shù)都是從1開始,不存在什么第0個的情況。),獲得的價值為7,這個最優(yōu)解可以看成是該算例的一個Benchmark。
當然
Benchmark概念的引出
只是為了方便我們對算法的效果進行一個對比

定義問題實例
 算例的數(shù)據(jù)結(jié)構(gòu)在代碼中的表示方式倒不用我們思考太多,按照給出的樣例,采用合適的數(shù)據(jù)結(jié)構(gòu)表示出來就行。針對上面的背包問題算例,我們還是設(shè)計一個類來表示吧:
算例的數(shù)據(jù)結(jié)構(gòu)在代碼中的表示方式倒不用我們思考太多,按照給出的樣例,采用合適的數(shù)據(jù)結(jié)構(gòu)表示出來就行。針對上面的背包問題算例,我們還是設(shè)計一個類來表示吧:class kp_instance():def __init__(self):self.C = 0 # 背包容量self.N = 0 # 物品個數(shù)self.W_V = [] # 各個物品的重量和價值[(w_1,v_1), ..., (w_n,v_n)]def read_data(self, line):????????pass

這個類有幾個成員變量,表示一個背包問題實例的具體參數(shù)。
它有個read_data()函數(shù),表示從某處讀取這些具體的參數(shù)保存到變量中。
這里呢我們暫時給隱藏掉(防止有些小朋友說太難了……)。
讀取的算例呢是以下格式的文件??
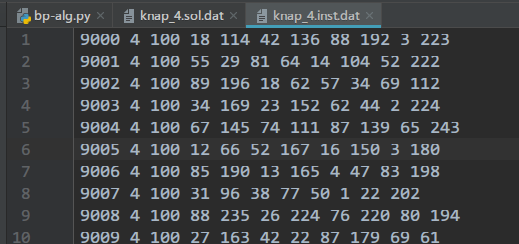
每行代表一個算例,從左到右的數(shù)字依次為:算例ID,物品個數(shù),背包容量,物品1重量,物品1價值,物品2重量,物品2價值,……,物品n重量,物品n價值。
同時,這些算例也提供了一個benchmark??
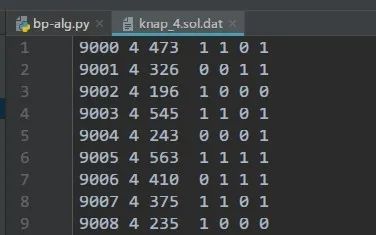
↑
從左到右依次為:算例ID,物品個數(shù),選擇物品的總價值,選擇決策(1選擇該物品,0不選)。
后續(xù)我們將用這個benchmark與我們設(shè)計的算法對比。
解的表示與評價

因為該問題的決策只有兩種狀態(tài),所以我們可以用0表示不拿,1表示拿。N個物品我們就可以用一個N維的數(shù)組x進行表示,當:
class kp_solution():def __init__(self):self.decision = [] # 決策變量self.total_value = 0 # decision決策對應(yīng)的目標值????????self.feasible????=?False?#??decision決策是否滿足所有約束
現(xiàn)在解已經(jīng)用計算機語言表示出來了,如何去評價一個解已經(jīng)十分明了了:根據(jù)問題的參數(shù),計算決策獲得的價值,以及判斷該決策是否可行。

還是再寫一個評價函數(shù)吧評價時呢肯定是需要問題的具體參數(shù),那么需要用到此前定義的kp_instance類:
def evaluate(sol: kp_solution, ins: kp_instance) -> None:total_weight = 0total_value = 0for i in range(len(sol.decision)):if sol.decision[i] == 1: # 選擇了物品itotal_value += ins.W_V[i][1]total_weight += ins.W_V[i][0]if total_weight > ins.C: # 超出了背包的容量,不可行sol.feasible = Falseelse:sol.feasible = True????sol.total_value?=?total_value??#?記錄總的價值
小試牛刀:枚舉
上面我們一步一步將算法需要相關(guān)數(shù)據(jù)給設(shè)計好了有了以上的基礎(chǔ)我們就可以著手相關(guān)的算法設(shè)計求解了
先看看枚舉法吧~?

枚舉就不用我多說了吧,簡單點說就是把問題所有的解給一一枚舉出來,挨個去評價,然后選出最好的那個。
針對上面解的表示方式,很容易得出其所有的解就是N位01的全排列。
來看看代碼
def enum_sol(ins: kp_instance)-> kp_solution:current_sol = kp_solution()best_sol = kp_solution()best_sol.total_value = -INF# 生成決策的全排列all_decisions = list(it.product(range(2), repeat=ins.N)) # 返回N位的01全排列for d in all_decisions:current_sol.decision = devaluate(current_sol, ins) # 評價當前解if best_sol.total_value < current_sol.total_value and current_sol.feasible: # 如果找到新的可行全局最優(yōu)解best_sol = copy.deepcopy(current_sol)????return?best_sol
我們一開始新建兩個解,當前解和全局最優(yōu)解。因為我們要求的是最大值,一開始讓全局最優(yōu)解的價值為負無窮。然后在枚舉的所有決策中挨個評價,如果找到比當前全局最優(yōu)還要好的解(并且該解是可行的!),那么更新全局最優(yōu)解。

可能有小伙伴對it.product(range(2), repeat=ins.N)有疑問
它的意思是生成N位的01全排列
比如:
import itertools as its = list(it.product(range(2), repeat=5))print(s)
結(jié)果如下,是不是很方便呢!
??
[]評測
算法寫出來了
當然還得評測一下啦
為了方便后續(xù)的測評
我們還是寫個函數(shù)吧
def solver_and_compare(method, inst_file_path, solution_file_path):"""Main method that solves knapsack problem using one of the existing methods:param method: knapsack problem solving method:param inst_file_path: path to file with input instances:param solution_file_path: path to file where solver should write output data"""????pass
該函數(shù)使用method算法,對文件inst_file_path中的算例進行求解,輸出最優(yōu)解和時間,并將該最優(yōu)解與solution_file_path中的benchmark進行對比,計算兩者偏差的百分比。
具體計算方式如下:
gap = (mc - bc) / bc
其中:
mc 為我們算法找到的解
bc benchmark為給出的解
當然為了避免讀者抱怨代碼過于復(fù)雜這里還是直接隱藏代碼細節(jié)我們直接來看結(jié)果吧!+---------+--------+-------------+---------+-----------+-------+| inst_id | number | enumeration | time | benckmark | gap % |+---------+--------+-------------+---------+-----------+-------+| 9000 | 4 | 473 | 0.0001 | 473 | 0.0 || 9001 | 4 | 326 | 0.0001 | 326 | 0.0 || 9002 | 4 | 196 | 0.0001 | 196 | 0.0 || 9050 | 10 | 798 | 0.0026 | 798 | 0.0 || 9051 | 10 | 942 | 0.0024 | 942 | 0.0 || 9052 | 10 | 740 | 0.0022 | 740 | 0.0 || 9100 | 15 | 2358 | 0.1028 | 2358 | 0.0 || 9101 | 15 | 1726 | 0.0924 | 1726 | 0.0 || 9102 | 15 | 2064 | 0.0975 | 2064 | 0.0 || 9150 | 20 | 1995 | 3.7705 | 1995 | 0.0 || 9151 | 20 | 2623 | 3.6683 | 2623 | 0.0 || 9152 | 20 | 2607 | 3.6509 | 2607 | 0.0 || 9200 | 22 | 2625 | 15.9776 | 2625 | 0.0 || 9201 | 22 | 2215 | 15.9097 | 2215 | 0.0 || 9202 | 22 | 2479 | 16.0191 | 2479 | 0.0 |+---------+--------+-------------+---------+-----------+-------+
?注:number一欄表示該算例下物品的個數(shù)。

1. 枚舉法能夠找到問題的最優(yōu)解
這是顯而易見的,比較你把所有的解(無論可行的還是不可行的)都比較了一遍,還找不出最優(yōu)的就說不過去了吧。如此看來,這枚舉法是個好東西啊,簡單粗暴,結(jié)果還是最優(yōu)。是嗎?
2. 枚舉法求解時間隨問題規(guī)模增長而呈爆炸式增長
枚舉法致命的缺陷就是其求解所需的資源(直觀上就是時間、內(nèi)存等)隨當問題規(guī)模的增長而呈指數(shù)級別增長。這是什么意思呢?
大家看看上面的求解結(jié)果
當問題的物品數(shù)為4時
求解時間為0.0001
當物品個數(shù)增加到22時
求解時間為16.0191
問題規(guī)模變?yōu)樵瓉淼?span style="color:rgb(12,137,24);">22/4=5.5倍
而求解時間卻變?yōu)樵瓉淼?6.0191/0.0001=160191倍
刺激吧
可能這樣說大家還沒啥感受,那么畫個圖直觀感受下吧
(橫著物品個數(shù),縱軸求解時間)
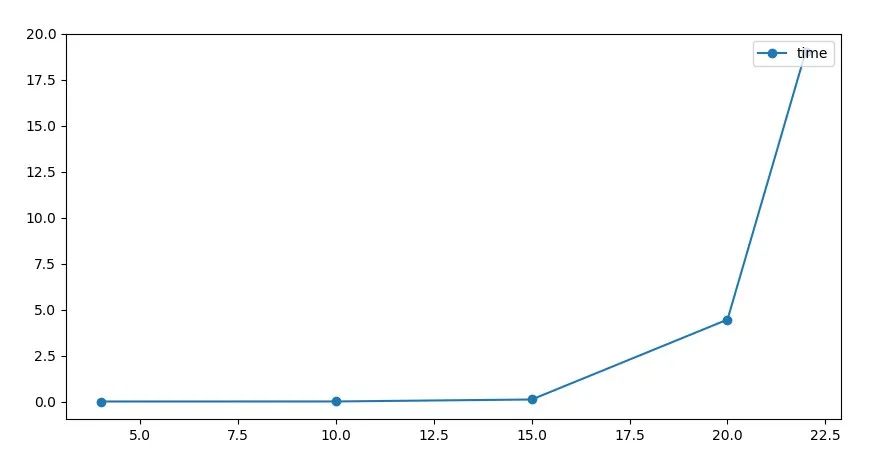
時間增長很明顯的指數(shù)趨勢。當然了,這里為了不再壓榨小編這臺可憐的電腦,算例規(guī)模就沒繼續(xù)增加了。有興趣的小伙伴可以下載源代碼回去自己繼續(xù)做實驗。
總結(jié)起來就是,枚舉雖然能找到問題的最優(yōu)解,但是由于其需要花費的計算資源過大,人們往往都不會采用這種方式去求解一個問題。
再探:貪心
﹏
﹏
﹏
﹏
小王家有一顆很高的果樹,每年結(jié)滿果實的時候因為樹太高小王都沒辦法好好摘取所有的果實,只能拿竹竿捅下來一部分。在某一年里,小王在書上看到了魯迅說要想富先擼樹,于是為了能吃到更多的果實小王把整個樹給擼掉了。當年小王跟全家人飽餐了一頓,并且多余的果子還買了點小錢。但是在后來的日子里,小王就再也沒有果實摘了。

上面就是一個貪心的例子,相信現(xiàn)實中也不乏這樣的事件。大家想想,如果不砍那棵樹,雖然當年收獲的果實會少一點,但是下一年,下下年依然能收獲到果實,子子孫孫無窮無盡,總體下來肯定是不砍樹獲得的收益更大。
但也正是“要想富先擼樹”這種貪心的思想,導(dǎo)致了小王一時被利益蒙蔽了雙眼,就把樹給擼掉了。那么大家想想一個問題:想要在當年吃到更多的果實,非得把樹給連根砍掉嗎?
那可未必!可以選擇在當年把帶有果子的樹干給砍下來,這樣也能在當年獲得更多的果子。并且隨著時間的推移,等樹的新枝長出來了,小王就可以再次進行同樣的操作。這樣一年又一年,顯然能獲得比直接砍樹更多的果子。
我們可以看到,在某一年里“砍樹”和“砍樹枝”都是基于貪心思想的兩種不同的貪心方式。顯然“砍樹枝”這種方式是要優(yōu)于“砍樹”這種方式的。
可見,貪心算法不僅僅是簡單的局部最優(yōu)這么簡單,他最終的結(jié)果跟貪心的方式是密切相關(guān)的。我們回來看背包問題這個例子,寫寫代碼跑一跑大家都明白了。
首先,我們基于第一種貪心的方式:滿足背包容量的前提下,拿價值大的物品。
def greedy1(ins: kp_instance) -> kp_solution:sorted_items = ins.W_V.copy()sorted_items.sort(key=lambda x: x[1], reverse=True) # 對價值進行降序排序current_weight = 0best_sol = kp_solution()best_sol.decision = [0 for _ in range(len(ins.W_V))]best_sol.feasible = True# 在容量范圍內(nèi),不斷挑價值大的往里面裝for item in sorted_items:if current_weight + item[0] > ins.C: # 這個物品裝不下了,看看下一個continuebest_sol.total_value += item[1]current_weight += item[0]best_sol.decision[ins.W_V.index(item)] = 1 # 記錄選擇的物品????return?best_sol
現(xiàn)在依然是和最優(yōu)的benchmark進行對比,看看效果如何:
+---------+--------+---------+--------+-----------+--------+| inst_id | number | greedy1 | time | benckmark | gap % |+---------+--------+---------+--------+-----------+--------+| 9000 | 4 | 415 | 0.0 | 473 | -12.26 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 || 9002 | 4 | 196 | 0.0 | 196 | 0.0 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 || 9052 | 10 | 701 | 0.0 | 740 | -5.27 || 9100 | 15 | 2341 | 0.0 | 2358 | -0.72 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 || 9102 | 15 | 2053 | 0.0 | 2064 | -0.53 || 9150 | 20 | 1924 | 0.0001 | 1995 | -3.56 || 9151 | 20 | 2623 | 0.0001 | 2623 | 0.0 || 9152 | 20 | 2553 | 0.0001 | 2607 | -2.07 || 9200 | 22 | 2607 | 0.0001 | 2625 | -0.69 || 9201 | 22 | 2107 | 0.0001 | 2215 | -4.88 || 9202 | 22 | 2479 | 0.0001 | 2479 | 0.0 |+---------+--------+---------+--------+-----------+--------+
好了,我們現(xiàn)在來試試第二種貪心的方式:滿足背包容量的前提下,拿性價比高的物品。性價比=價值/密度。
def greedy2(ins: kp_instance) -> kp_solution:sorted_items = ins.W_V.copy()sorted_items.sort(key=lambda x: x[1] / x[0], reverse=True) # 對價值進行降序排序current_weight = 0best_sol = kp_solution()best_sol.decision = [0 for _ in range(len(ins.W_V))]best_sol.feasible = True# 在容量范圍內(nèi),不斷挑性價比大的往里面裝for item in sorted_items:if current_weight + item[0] > ins.C: # 這個物品裝不下了,看看下一個continuebest_sol.total_value += item[1]current_weight += item[0]best_sol.decision[ins.W_V.index(item)] = 1 # 記錄選擇的物品????return?best_sol
代碼實現(xiàn)方式和此前的差不多,這里大家應(yīng)該都能看懂就不說了。
看看結(jié)果如何
+---------+--------+---------+------+-----------+--------+| inst_id | number | greedy2 | time | benckmark | gap % |+---------+--------+---------+------+-----------+--------+| 9000 | 4 | 473 | 0.0 | 473 | 0.0 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 || 9002 | 4 | 174 | 0.0 | 196 | -11.22 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 || 9052 | 10 | 740 | 0.0 | 740 | 0.0 || 9100 | 15 | 2321 | 0.0 | 2358 | -1.57 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 || 9102 | 15 | 2064 | 0.0 | 2064 | 0.0 || 9150 | 20 | 1979 | 0.0 | 1995 | -0.8 || 9151 | 20 | 2516 | 0.0 | 2623 | -4.08 || 9152 | 20 | 2564 | 0.0 | 2607 | -1.65 || 9200 | 22 | 2625 | 0.0 | 2625 | 0.0 || 9201 | 22 | 2211 | 0.0 | 2215 | -0.18 || 9202 | 22 | 2433 | 0.0 | 2479 | -1.86 |+---------+--------+---------+------+-----------+--------+
直觀上感覺這種方式的效果更好了一點呢,因為大部分算例都能直接找到最優(yōu)解了。但是至于是不是真的好,大家說了才算,我們比較下兩種貪心的方式:
+---------+--------+---------+--------+---------+--------+--------+| inst_id | number | greedy1 | time1 | greedy2 | time2 | gap % |+---------+--------+---------+--------+---------+--------+--------+| 9000 | 4 | 415 | 0.0 | 473 | 0.0 | -12.26 || 9001 | 4 | 326 | 0.0 | 326 | 0.0 | 0.0 || 9002 | 4 | 196 | 0.0 | 174 | 0.0 | 12.64 || 9050 | 10 | 798 | 0.0 | 798 | 0.0 | 0.0 || 9051 | 10 | 942 | 0.0 | 942 | 0.0 | 0.0 || 9052 | 10 | 701 | 0.0 | 740 | 0.0 | -5.27 || 9100 | 15 | 2341 | 0.0 | 2321 | 0.0 | 0.86 || 9101 | 15 | 1726 | 0.0 | 1726 | 0.0 | 0.0 || 9102 | 15 | 2053 | 0.0 | 2064 | 0.0 | -0.53 || 9150 | 20 | 1924 | 0.0001 | 1979 | 0.0001 | -2.78 || 9151 | 20 | 2623 | 0.0001 | 2516 | 0.0001 | 4.25 || 9152 | 20 | 2553 | 0.0001 | 2564 | 0.0001 | -0.43 || 9200 | 22 | 2607 | 0.0001 | 2625 | 0.0001 | -0.69 || 9201 | 22 | 2107 | 0.0001 | 2211 | 0.0001 | -4.7 || 9202 | 22 | 2479 | 0.0001 | 2433 | 0.0001 | 1.89 |+---------+--------+---------+--------+---------+--------+--------+
其中gap = (greedy1 - greedy2 )/greedy1。
gap一列中,負值的行表示該算例下greedy1要比greedy2找到的解價值少一些,也就是該解差一些。
從上面的結(jié)果中可以看出,負值很明顯比正值多,就測試的算例看來,greedy2的方式效果要好一些。
也就是以密度貪心的方式更為有效一些。
(不知道大家注意到上述結(jié)果的時間沒有,貪心方式求解的速度真的快到?jīng)]朋友)
因為兩種greedy的求解時間沒有太大區(qū)別,我們取greedy1的求解時間與枚舉法的求解時間比較一下:
+---------+--------+--------------+------------------+--------------+| inst_id | number | greedy1_time | enumeration_time | gap % |+---------+--------+--------------+------------------+--------------+| 9000 | 4 | 0.0 | 0.0001 | -434.48 || 9001 | 4 | 0.0 | 0.0001 | -883.33 || 9002 | 4 | 0.0 | 0.0001 | -1378.57 || 9050 | 10 | 0.0 | 0.0029 | -26853.85 || 9051 | 10 | 0.0 | 0.0034 | -28400.0 || 9052 | 10 | 0.0 | 0.0025 | -20143.33 || 9100 | 15 | 0.0 | 0.1056 | -677307.89 || 9101 | 15 | 0.0 | 0.1059 | -220584.62 || 9102 | 15 | 0.0 | 0.1059 | -496103.85 || 9150 | 20 | 0.0 | 4.9548 | -21188157.89 || 9151 | 20 | 0.0 | 4.3277 | -14065001.33 || 9152 | 20 | 0.0 | 4.3265 | -13695871.43 || 9200 | 22 | 0.0 | 22.5842 | -62555795.45 || 9201 | 22 | 0.0001 | 21.4181 | -19700567.17 || 9202 | 22 | 0.0001 | 19.3518 | -23236437.44 |+---------+--------+--------------+------------------+--------------+
其中gap = (greedy1_time - enumeration_time)/greedy1_time * 100%
 這時間差距實在是太大了那么為什么貪心算法這么?快呢?
這時間差距實在是太大了那么為什么貪心算法這么?快呢?
? 其實大家注意到了沒有,貪心算法其實就是一個“構(gòu)造”解的過程而已,相比較于枚舉法而言,貪心是沒有“搜索”這一過程的,他只是按照一定的方式,將解給構(gòu)造起來而已。因此,貪心法大多數(shù)情況下,在取得還算“過得去”的結(jié)果的同時,也能保持較快求解速度。這是貪心算法的一大優(yōu)點。
? 綜合起來:
貪心算法能取得“還可以”的解,有時候甚至能找到最優(yōu)解。
貪心算法由于只是利用“構(gòu)造”的方式生成解,因此速度相對而言會非常快,同時不會隨著問題規(guī)模的增長而大幅度增加,是平緩的線性增長。
? 如果想利用貪心取得較好的結(jié)果,那么就需要設(shè)計出優(yōu)秀的貪心方式了。

 那么大家再想想貪心除了碰巧能取得最優(yōu)解什么情況下一定能取得最優(yōu)解呢?
那么大家再想想貪心除了碰巧能取得最優(yōu)解什么情況下一定能取得最優(yōu)解呢?
?其實很簡單,當貪心過程中決策的每一步都互不影響時,最終的結(jié)果就是最優(yōu)解。
其實真是這種情況的話,那么整個問題的各個步驟的決策都可以重新分解為一個單獨的子問題了,那么由于各個子問題互不影響,貪心獲得子問題的最優(yōu),組合起來最后肯定也是全局的最優(yōu)。

文案&編輯:鄧發(fā)珩(華中科技大學(xué)管理學(xué)院本科三年級)審稿人:秦時明岳(華中科技大學(xué)管理學(xué)院)指導(dǎo)老師:秦時明岳(華中科技大學(xué)管理學(xué)院)排版:程欣悅(荊楚理工學(xué)院本科二年級)
如對文中內(nèi)容有疑問,歡迎交流。PS:部分資料來自網(wǎng)絡(luò)。如有需求,可以聯(lián)系:秦虎老師([email protected])鄧發(fā)珩(華中科技大學(xué)管理學(xué)院本科三年級:[email protected])程欣悅(荊楚理工學(xué)院本科二年級:[email protected])