
視覺詞袋模型簡介
點擊上方“小白學(xué)視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
視覺單詞袋是一種描述計算圖像之間相似度的技術(shù)。常用于用于圖像分類當中。該方法起源于文本檢索(信息檢索),是對NLP“單詞袋”算法的擴展。在“單詞袋”中,我們掃描整個文檔,并保留文檔中出現(xiàn)的每個單詞的計數(shù)。然后,我們創(chuàng)建單詞頻率的直方圖,并使用此直方圖來描述文本文檔。在“視覺單詞袋”中,我們的輸入是圖像而不是文本文檔,并且我們使用視覺單詞來描述圖像。
文字文檔袋
圖像視覺詞袋

視覺單詞
在BovW中,我們將圖像分解為一組獨立的特征,特征由關(guān)鍵點和描述符組成,關(guān)鍵點與興趣點是同一件事。它們某些是空間位置或圖像中的點,這些位置定義了圖像中的突出部分。它們受圖像的旋轉(zhuǎn)、縮放、平移,變形等等因素的影響。描述符是這些關(guān)鍵點的值(描述),而創(chuàng)建字典時所使用聚類算法是基于這些描述符進行的。我們遍歷圖像并檢查圖像中是否存在單詞。如果有,則增加該單詞的計數(shù)。最后我們?yōu)樵搱D像創(chuàng)建直方圖。
要創(chuàng)建字典,我們需要使用特征提取器(例如SIFT,BRISK等)。正如前面所描述的那樣,這些技術(shù)檢測圖像中的關(guān)鍵點并為輸入圖像計算其值(描述符)。這些特征檢測器返回包含描述符的數(shù)組。我們對訓(xùn)練數(shù)據(jù)集中的每個圖像都執(zhí)行此操作。
現(xiàn)在,假設(shè)我們將擁有N個(訓(xùn)練數(shù)據(jù)集中沒有圖像)數(shù)組。將這些數(shù)組垂直堆疊,使用類似與K-Means的聚類算法來形成K個聚類.K-Means將數(shù)據(jù)點分組為K個組,并將返回每個組的中心(見下圖)。每個聚類的中心(質(zhì)心)都充當一個視覺單詞,所有這些K組的重心構(gòu)成了我們的字典。
K均值聚類

檢測視覺單詞
現(xiàn)在我們將創(chuàng)建一個(N,K)的二維數(shù)組,我們將在接下來的幾行中看到如何填充此數(shù)組。一旦檢測到字典和圖像中都存在一個單詞,就會增加該特定單詞的計數(shù)(即array [i] [w] + = 1,其中i是當前圖像,w是該單詞)。
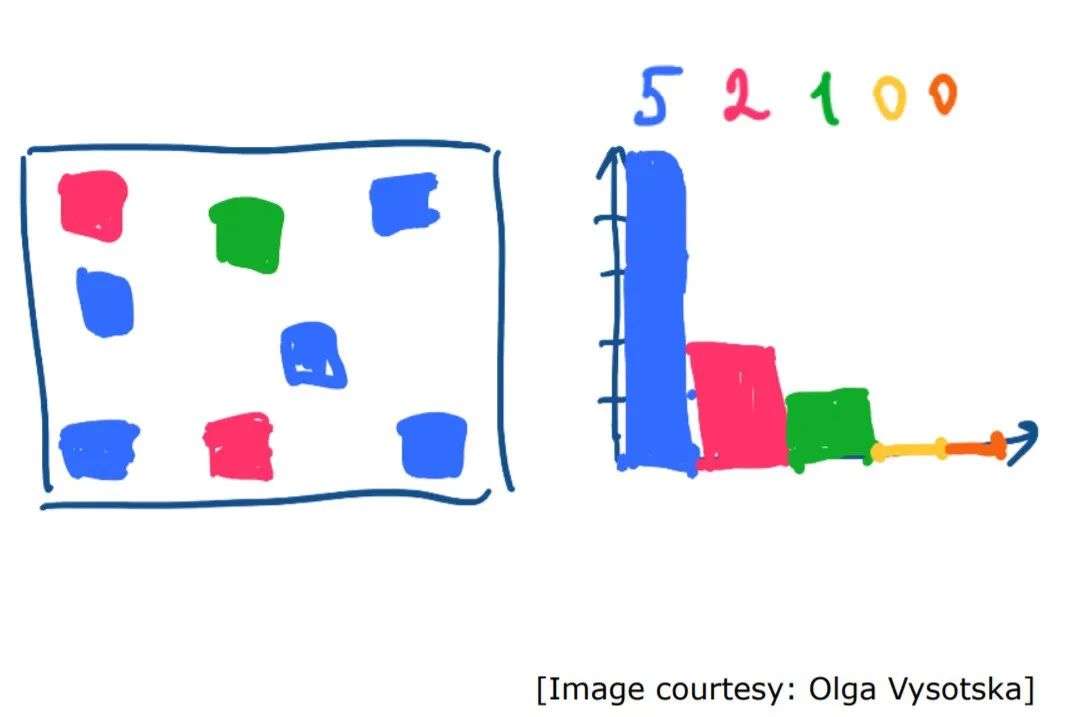
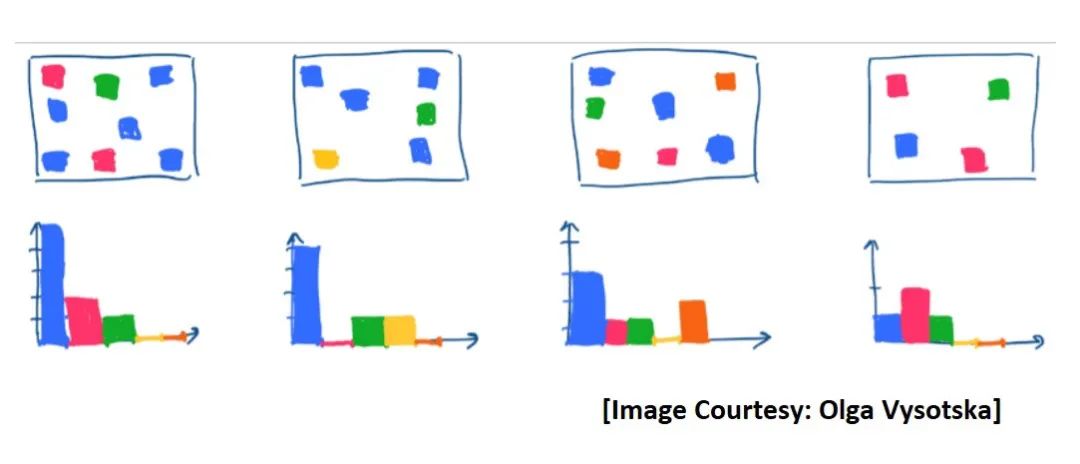
創(chuàng)建直方圖
BoVW方法適用于捕獲多細節(jié)的大型顯微鏡圖像。但是,這種方法存在的問題是。當視覺單詞出現(xiàn)在圖像數(shù)據(jù)庫的很多圖像或每幅圖像中時,就會導(dǎo)致一些并沒有實際意義的單詞的統(tǒng)計值較大。大家想想一個文本文檔中像is,are之類的單詞并沒有多大幫助,因為它們幾乎會出現(xiàn)在所有的文本當中。這些單詞會導(dǎo)致分類任務(wù)變得更加困難。為了解決這個問題,我們可以使用TF-IDF(術(shù)語頻率-逆文檔頻率)重加權(quán)方法。它可以對直方圖的每個像素進行加權(quán),來降低“非信息性”單詞的權(quán)重(即,出現(xiàn)在許多圖像/各處的特征),并增強了稀有單詞的重要性。使用下圖中給出的TF-IDF公式就可以計算出直方圖中的每個單詞的新權(quán)重。

TF-IDF加權(quán)
該公式清楚的表達了圖像中每個的單詞的重要性是如何定義的。
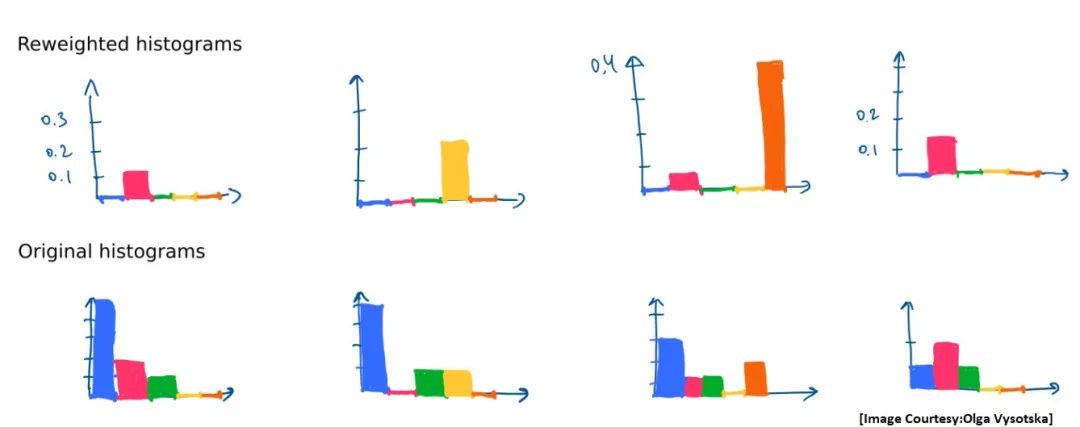
在經(jīng)過加權(quán)之后的直方圖中可以看出,藍色單詞的權(quán)重幾乎為零。

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~