
IDEFICS 簡介: 最先進視覺語言模型的開源復現
我們很高興發(fā)布 IDEFICS ( Image-aware Decoder Enhanced à la Flamingo with Ininterleaved Cross-attention S ) 這一開放視覺語言模型。IDEFICS 基于 Flamingo,Flamingo 作為最先進的視覺語言模型,最初由 DeepMind 開發(fā),但目前尚未公開發(fā)布。與 GPT-4 類似,該模型接受任意圖像和文本輸入序列并生成輸出文本。IDEFICS 僅基于公開可用的數據和模型 (LLaMA v1 和 OpenCLIP) 構建,它有兩個變體: 基礎模型和指令模型。每個變體又各有 90 億參數和 800 億參數兩個版本。
最先進的人工智能模型的開發(fā)應該更加透明。IDEFICS 的目標是重現并向 AI 社區(qū)提供與 Flamingo 等大型私有模型的能力相媲美的公開模型。因此,我們采取了很多措施,以增強其透明度: 我們只使用公開數據,并提供工具以供大家探索訓練數據集; 我們分享我們在系統(tǒng)構建過程中的 在技術上犯過的錯誤及學到的教訓,并在模型最終發(fā)布前使用對抗性提示來評估模型的危害性。我們希望 IDEFICS 能夠與 OpenFlamingo (Flamingo 的另一個 90 億參數的開放的復現模型) 等模型一起,為更開放的多模態(tài) AI 系統(tǒng)研究奠定堅實的基礎。
你可以在 Hub 上試一試我們的 演示 及 模型!
IDEFICS 是什么?
IDEFICS 是一個 800 億參數的多模態(tài)模型,其接受圖像和文本序列作為輸入,并生成連貫的文本作為輸出。它可用于回答有關圖像的問題、描述視覺內容、創(chuàng)建基于多張圖像的故事等。
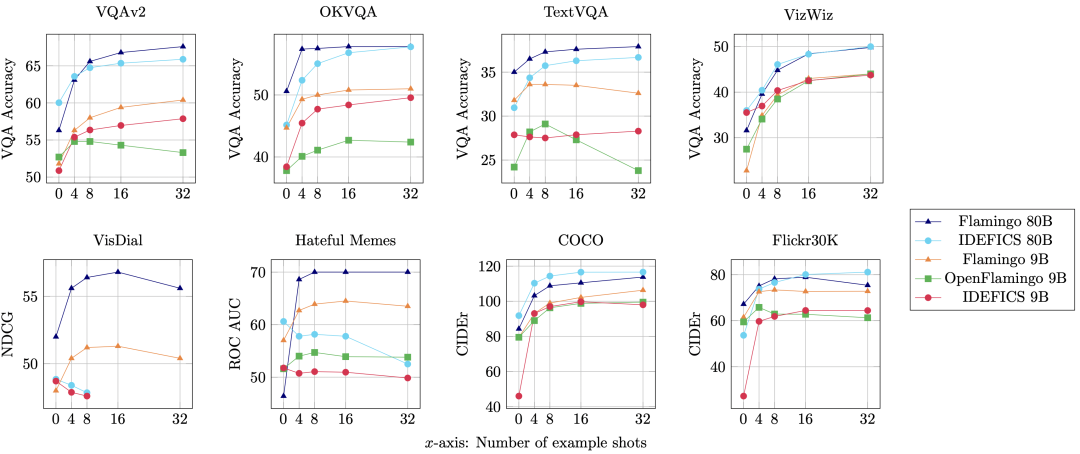
IDEFICS 是 Flamingo 的開放復刻版,在各種圖像文本理解基準上的性能可與原始閉源模型相媲美。它有兩個版本 - 800 億參數版和 90 億參數版。
我們還提供了兩個指令微調變體 idefics-80B-instruct 及 idefics-9B-instruct,可用于對話場景。
訓練數據
IDEFICS 基于由多個公開可用的數據集組成的混合數據集訓練而得,它們是: 維基百科、公開多模態(tài)數據集 (Public Multimodal Dataset) 和 LAION,以及我們創(chuàng)建的名為 OBELICS 的新的 115B 詞元數據集。OBELICS 由從網絡上抓取的 1.41 億個圖文文檔組成,其中包含 3.53 億張圖像。
我們提供了 OBELICS 的 交互式可視化 頁面,以供大家使用 Nomic AI 來探索數據集的內容。

你可在 模型卡 和我們的 研究論文 中找到 IDEFICS 架構、訓練方法及評估數據等詳細信息,以及數據集相關的信息。此外,我們還記錄了在模型訓練過程中得到的 所思、所想、所學,為大家了解 IDEFICS 的研發(fā)提供了寶貴的視角。
倫理評估
在項目開始時,經過一系列討論,我們制定了一份 倫理章程,以幫助指導項目期間的決策。該章程規(guī)定了我們在執(zhí)行項目和發(fā)布模型過程中所努力追求的價值觀,包括自我批判、透明和公平。
作為發(fā)布流程的一部分,我們內部對模型的潛在偏見進行了評估,方法是用對抗性圖像和文本來提示模型,這些圖像和文本可能會觸發(fā)一些我們不希望模型做出的反應 (這一過程稱為紅隊)。
請通過 演示應用 來試一試 IDEFICS,也可以查看相應的 模型卡 和 數據集卡,并通過社區(qū)欄告訴我們你的反饋!我們致力于改進這些模型,并讓機器學習社區(qū)能夠用上大型多模態(tài)人工智能模型。
許可證
該模型建立在兩個預訓練模型之上: laion/CLIP-ViT-H-14-laion2B-s32B-b79K 和 huggyllama/llama-65b。第一個是在 MIT 許可證下發(fā)布的。而第二個是在一個特定的研究性非商用許可證下發(fā)布的,因此,用戶需遵照該許可的要求直接填寫 Meta 的表單 來申請訪問它。
https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
這兩個預訓練的模型通過我們的新訓練的參數相互連接。訓練時,連接部分的參數會隨機初始化,且其與兩個凍結的基礎模型無關。這一部分權重是在 MIT 許可證下發(fā)布的。
IDEFICS 入門
IDEFICS 模型已上傳至 Hugging Face Hub,最新版本的 transformers 也已支持該模型。以下是一個如何使用 IDEFICS 的代碼示例:
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
?? 寶子們可以戳 閱讀原文 查看文中所有的外部鏈接喲!
英文原文: https://hf.co/blog/idefics
原文作者: Hugo Lauren?on,Daniel van Strien,Stas Bekman,Leo Tronchon,Lucile Saulnier,Thomas Wang,Siddharth Karamcheti,Amanpreet Singh,Giada Pistilli,Yacine Jernite,Victor Sanh
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態(tài)數據上的應用及大規(guī)模模型的訓練推理。
審校/排版: zhongdongy (阿東)