
一文讀懂CV中的注意力機(jī)制
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
導(dǎo)讀
?本文配合相關(guān)的論文,講述了多種CV注意力機(jī)制(Non-local Neural Networks、Squeeze-and-Excitation Networks、CBAM、DANet)的概念、特點(diǎn)以及相關(guān)實(shí)驗(yàn)。
Non-local ~ SE ~ CcNet ~ GC-Net ~ Gate ~ CBAM ~ Dual Attention ~ Spatial Attention ~ Channel Attention ~ ...
【只要你能熟練的掌握加法、乘法、并行、串行四大法則,外加知道一點(diǎn)基本矩陣運(yùn)算規(guī)則(如:HW * WH = HH)和sigmoid/softmax操作,那么你就能隨意的生成很多種注意力機(jī)制】
空間注意力模塊?(look where)?對(duì)特征圖每個(gè)位置進(jìn)行attention調(diào)整,(x,y)二維調(diào)整,使模型關(guān)注到值得更多關(guān)注的區(qū)域上。 通道注意力模塊?(look what)?分配各個(gè)卷積通道上的資源,z軸的單維度調(diào)整。
論文:https://arxiv.org/abs/1711.07971v1
計(jì)算機(jī)視覺領(lǐng)域注意力機(jī)制的開篇之作。提出了non-local operations,使用自注意力機(jī)制建立遠(yuǎn)程依賴。- local operations: 卷積(對(duì)局部領(lǐng)域)、recurrent(對(duì)當(dāng)前/前一時(shí)刻)等操作。- non-local operations用于捕獲長(zhǎng)距離依賴(long-range dependencies),即如何建立圖像上兩個(gè)有一定距離的像素之間的聯(lián)系,如何建立視頻里兩幀的聯(lián)系,如何建立一段話中不同詞的聯(lián)系等。Non-local operations 在計(jì)算某個(gè)位置的響應(yīng)時(shí),是考慮所有位置 features 的加權(quán)——所有位置可以是空間的,時(shí)間的,時(shí)空的。
1. Non-local 定義
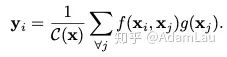
其中x表示輸入信號(hào)(圖片,序列,視頻等,也可能是它們的features),y表示輸出信號(hào),其size和x相同。f(xi,xj)用來計(jì)算i和所有可能關(guān)聯(lián)的位置j之間pairwise的關(guān)系,這個(gè)關(guān)系可以是比如i和j的位置距離越遠(yuǎn),f值越小,表示j位置對(duì)i影響越小。g(xj)用于計(jì)算輸入信號(hào)在j位置的特征值。C(x)是歸一化參數(shù)。理解:?i 代表的是當(dāng)前位置的響應(yīng),j 代表全局響應(yīng),通過加權(quán)得到一個(gè)非局部的響應(yīng)值。
Non-Local的優(yōu)點(diǎn)是什么?
提出的non-local operations通過計(jì)算任意兩個(gè)位置之間的交互直接捕捉遠(yuǎn)程依賴,而不用局限于相鄰點(diǎn),其相當(dāng)于構(gòu)造了一個(gè)和特征圖譜尺寸一樣大的卷積核, 從而可以維持更多信息。 non-local可以作為一個(gè)組件,和其它網(wǎng)絡(luò)結(jié)構(gòu)結(jié)合,經(jīng)過作者實(shí)驗(yàn),證明了其可以應(yīng)用于圖像分類、目標(biāo)檢測(cè)、目標(biāo)分割、姿態(tài)識(shí)別等視覺任務(wù)中,并且效果有不同程度的提升。 Non-local在視頻分類上效果很好,在視頻分類的任務(wù)中效果可觀。
論文中給了通用公式,然后分別介紹f函數(shù)和g函數(shù)的實(shí)例化表示:
g函數(shù):可以看做一個(gè)線性轉(zhuǎn)化(Linear Embedding)公式如下:
是需要學(xué)習(xí)的權(quán)重矩陣,可以通過空間上的1×1卷積實(shí)現(xiàn)(實(shí)現(xiàn)起來比較簡(jiǎn)單)。
f函數(shù):這是一個(gè)用于計(jì)算i和j相似度的函數(shù),作者提出了四個(gè)具體的函數(shù)可以用作f函數(shù)。
1.Gaussian function 2. Embedded Gaussian 3. Dot product 4. Concatenation
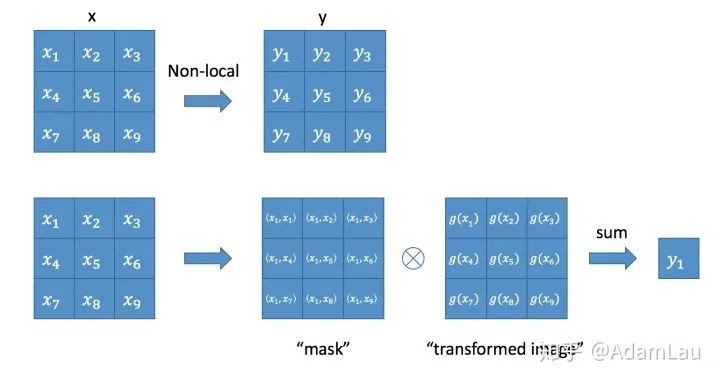
2. Non-local block
實(shí)際上是一個(gè)卷積操作,它的輸出channel數(shù)跟x一致。這樣以來,non-local操作就可以作為一個(gè)組件,組裝到任意卷積神經(jīng)網(wǎng)絡(luò)中。
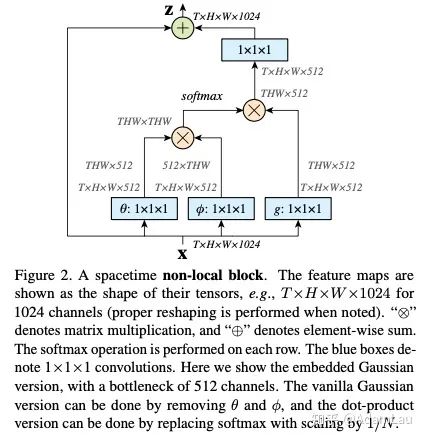
3. 實(shí)驗(yàn)
文中提出了四個(gè)計(jì)算相似度的模型,實(shí)驗(yàn)對(duì)四個(gè)方法都進(jìn)行了實(shí)驗(yàn),發(fā)現(xiàn)了這四個(gè)模型效果相差并不大,于是有一個(gè)結(jié)論:使用non-local對(duì)baseline結(jié)果是有提升的,但是不同相似度計(jì)算方法之間差距并不大,所以可以采用其中一個(gè)做實(shí)驗(yàn)即可,文中用embedding gaussian作為默認(rèn)的相似度計(jì)算方法。 作者做了一系列消融實(shí)驗(yàn)來證明non local NN的有效性: 對(duì)比四個(gè)計(jì)算相似度模型,并無太大差異; 以Resnet50為例:對(duì)比non-local模塊加在不同stage下的結(jié)果,在2,3,4stage處提高較大,可能由于第五層空間信息較少; 對(duì)比加入non-local模塊數(shù)量的結(jié)果,越多性能越好,但速度越慢;作者認(rèn)為這是因?yàn)楦嗟膎on-local block能夠捕獲長(zhǎng)距離多次轉(zhuǎn)接的依賴。信息可以在時(shí)空域上距離較遠(yuǎn)的位置上進(jìn)行來回傳遞,這是通過local models無法實(shí)現(xiàn)的; 時(shí)間、空間及時(shí)空域上做non-local,效果均有提升; non-local VS 3D卷積,non-local更有效率,且性能更好; non-local和3D conv是可以相互補(bǔ)充的; 更長(zhǎng)的輸入序列,所有模型在長(zhǎng)序列上都表現(xiàn)得更好。
論文:https://arxiv.org/abs/1709.01507
很多前面的工作都提出了以空間維度提升網(wǎng)絡(luò)的性能,比如inception結(jié)構(gòu)獲取不同感受野信息、inside-outside結(jié)構(gòu)更多考慮上下文信息、空間注意力機(jī)制等。是否有其他層面去提升性能??
SENet是首個(gè)提出從channel-wise層面提出Squeeze-and-Excitation模塊的通道注意力機(jī)制,可以自適應(yīng)調(diào)整各通道的特征響應(yīng)值。
網(wǎng)絡(luò)應(yīng)用于分類,如何應(yīng)用到分割上?
1. SE模塊
網(wǎng)絡(luò)結(jié)構(gòu)如下所示:
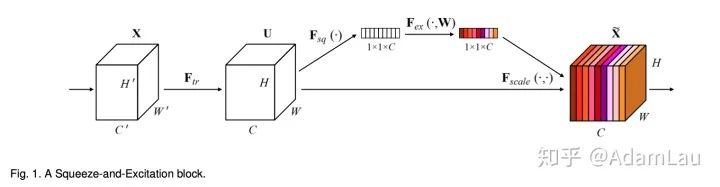
Squeeze?使用全局平均池化(也可用其他方式)生成通道信息統(tǒng)計(jì),實(shí)現(xiàn)通道描述;
將全局空間信息壓縮為一個(gè)通道描述符;
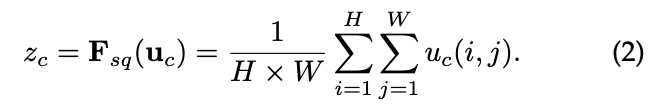
Excitation?實(shí)現(xiàn)方式要靈活,且必須能學(xué)習(xí)一個(gè)非互斥的關(guān)系
使用了sigmoid激活函數(shù)的門限機(jī)制來實(shí)現(xiàn),使權(quán)重在(0,1)上
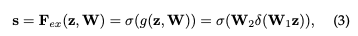
最后通過一個(gè)scale的操作將所求的權(quán)重乘上原來每個(gè)通道的二維特征上
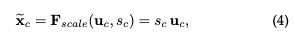
訓(xùn)練全連接網(wǎng)絡(luò)學(xué)習(xí)到每個(gè)特征通道的權(quán)重,權(quán)重可以顯示地建模特征通道的相關(guān)性。
2. 實(shí)驗(yàn)
SE模塊可以應(yīng)用到inception、resblock等多種結(jié)構(gòu),非常靈活。
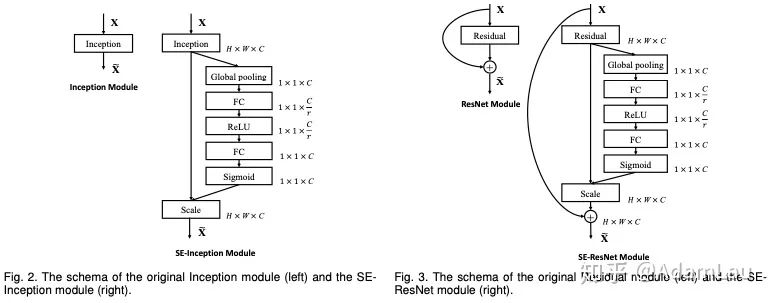
消融實(shí)驗(yàn)非常完備,實(shí)驗(yàn)結(jié)果也是當(dāng)時(shí)的STOA,奪得了ILSVRC2017的冠軍。(較為簡(jiǎn)略,具體看論文)
3. 結(jié)論
SE模塊能夠動(dòng)態(tài)自適應(yīng)完成在通道維度上對(duì)原始特征進(jìn)行重標(biāo)定,首次關(guān)注了模型通道層面的依賴關(guān)系。另外,由SE塊產(chǎn)生的特征重要性值是否能用于網(wǎng)絡(luò)剪枝(模型壓縮)。
論文:https://arxiv.org/pdf/1807.06521.pdf
代碼:https://github.com/luuuyi/CBAM.PyTorch
論文Introduction部分提出了影響卷積神經(jīng)網(wǎng)絡(luò)模型性能的三個(gè)因素:深度、寬度、基數(shù)。并且列舉了一些代表新的網(wǎng)絡(luò)結(jié)構(gòu),比如和深度相關(guān)的VGG和ResNet系列,和寬度相關(guān)的GoogLeNet和wide-ResNet系列,和基數(shù)相關(guān)的Xception和ResNeXt。
除了這三個(gè)因素之外,還有一個(gè)模塊,也能影響網(wǎng)絡(luò)的性能,這就是attention——注意力機(jī)制。
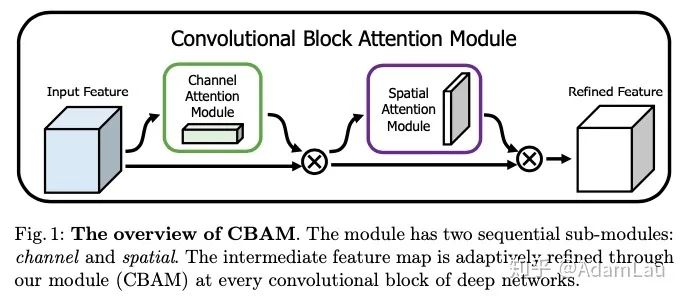
動(dòng)機(jī):所以文章提出了兩個(gè)注意力機(jī)制的模塊,分別是channel attention module和spatial attention module。通過級(jí)聯(lián)方式連接起來。模塊較為靈活,可以嵌入到ResBlock等。
1. Channnel attetion module(通道注意力模塊)
通道注意力模塊主要是探索不同通道之間的feature map的關(guān)系。每一個(gè)通道的feature map本身作為一個(gè)特征檢測(cè)出器(feature detetor),通過這個(gè)通道注意力模塊來告訴模型,我們更應(yīng)該注意哪一部分特征。
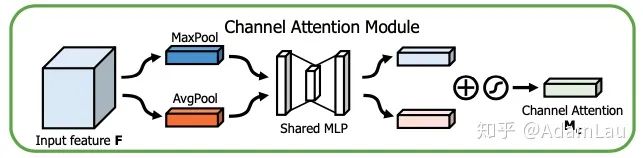
同時(shí)使用average-pooling和max-pooling聚合空間維度特征,產(chǎn)生兩個(gè)空間維度描述符。隨后經(jīng)MLP(fc+Relu+fc)+sigmoid層(和SE-Net相同,只是squeeze操作多了一步max pooling),為每個(gè)通道產(chǎn)生權(quán)重,最后將權(quán)重與原始未經(jīng)channel attention相乘。
2. Spatial attention module(空間注意力模塊)
利用空間注意力模塊來生成一個(gè)spatial attention map,用來利用不同特征圖之間的空間關(guān)系,以此來使模型注意特征圖的哪些特征空間位置。
網(wǎng)絡(luò)應(yīng)用于分類,如何應(yīng)用到分割上?
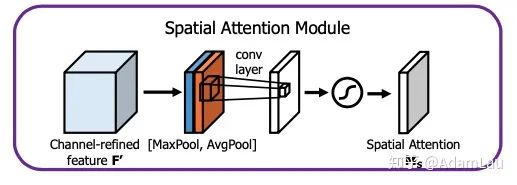
這一次是在軸的方向上對(duì)不同特征圖上相同位置的像素值進(jìn)行全局的MaxPooling和AvgPooling操作,分別得到兩個(gè)spatial attention map并將其concatenate,shape為[2, H, W]。 再利用一個(gè)7*7的卷積對(duì)這個(gè)feature map進(jìn)行卷積。后接一個(gè)sigmoid函數(shù)。得到一個(gè)語言特征圖維數(shù)相同的加上空間注意力權(quán)重的空間矩陣。 最后把得到的空間注意力矩陣對(duì)應(yīng)相乘的原特征圖上,得到的新的特征圖。
3. 實(shí)驗(yàn)
Comparison of different channel attention methods:

用maxpooling與avgpooling一起比SENet(僅用avgpooling)效果更好。
Comparison of different spatial attention methods:
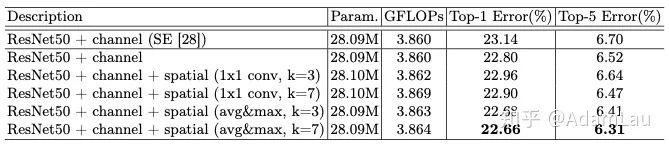
使用7x7卷積核的原因是具有更大的感受野,還有個(gè)人認(rèn)為小卷積核可能會(huì)造成一些特征圖的confusion。
Combining methods of channel and spatial attention:

整體的消融實(shí)驗(yàn)。
論文:https://arxiv.org/pdf/1809.02983.pdf
雖然上下文融合有助于捕獲不同比例的對(duì)象,但卻無法利用全局視圖中對(duì)象之間的關(guān)系。容易忽略不顯眼的對(duì)象,或是沒有綜合考慮各個(gè)位置的聯(lián)系和相關(guān)性,致使分割的類內(nèi)不一致性,產(chǎn)生誤分割。對(duì)于語義分割,每個(gè)通道的map相當(dāng)于是對(duì)每一類的響應(yīng),因此對(duì)于通道間的相關(guān)性也應(yīng)著重考慮。
為解決這一問題,提出了雙注意力網(wǎng)絡(luò)(DANet),基于自注意力機(jī)制來分別捕獲空間維度和通道維度中的特征依賴關(guān)系。具體而言,本文在dilated FCN上附加了2種注意力模塊,分別對(duì)空間維度和通道維度上的語義依賴關(guān)系進(jìn)行建模。
應(yīng)用于分割的注意力網(wǎng)絡(luò),空間注意力模塊與通道注意力模塊并聯(lián)連接,最終將兩個(gè)模塊的結(jié)果進(jìn)行elementwise操作。在特征提取處,作者對(duì)ResNet做出以下改動(dòng),將最后的downsampling取消,采用空洞卷積來達(dá)到即擴(kuò)大感受野又保持較高空間分辨率的目的,最終的特征圖擴(kuò)大到了原圖的1/8。
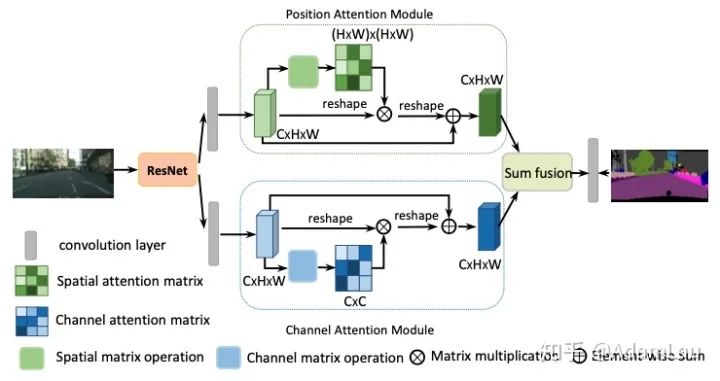
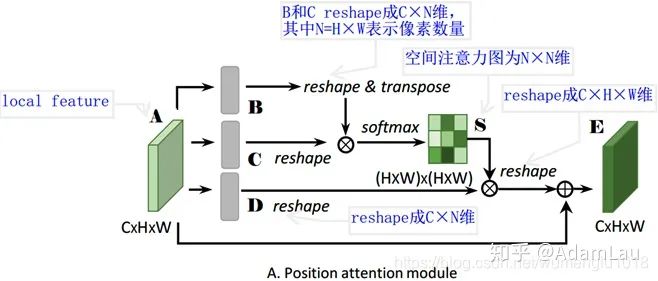
1. Position Attention Module(PAM)
位置注意力模塊旨在利用任意兩點(diǎn)特征之間的關(guān)聯(lián),來相互增強(qiáng)各自特征的表達(dá)。
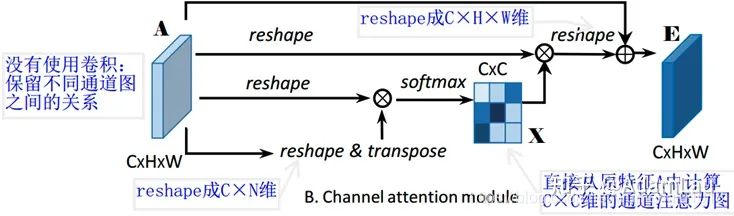
2. Channel Attention Module(CAM)
每個(gè)high level特征的通道圖都可以看作是一個(gè)特定于類的響應(yīng),通過挖掘通道圖之間的相互依賴關(guān)系,可以突出相互依賴的特征圖,提高特定語義的特征表示。
為了進(jìn)一步獲得全局依賴關(guān)系的特征,將兩個(gè)模塊的輸出結(jié)果進(jìn)行相加融合,獲得最終的特征用于像素點(diǎn)的分類。
3. 總結(jié)
總的來說,DANet網(wǎng)絡(luò)主要思想是 CBAM 和 non-local 的融合變形。把deep feature map進(jìn)行spatial-wise self-attention,同時(shí)也進(jìn)行channel-wise self-attetnion,最后將兩個(gè)結(jié)果進(jìn)行 element-wise sum 融合。
在 CBAM 分別進(jìn)行空間和通道 self-attention的思想上,直接使用了 non-local 的自相關(guān)矩陣 Matmul 的形式進(jìn)行運(yùn)算,避免了 CBAM 手工設(shè)計(jì) pooling,多層感知器等復(fù)雜操作。
參考:
https://blog.csdn.net/elaine_bao/article/details/80821306 https://zhuanlan.zhihu.com/p/102984842 https://zhuanlan.zhihu.com/p/93228308 https://zhuanlan.zhihu.com/p/106084464 https://blog.csdn.net/wumenglu1018/article/details/95949039 https://blog.csdn.net/xh_hit/article/details/88575853
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~