
Java8 的這個(gè)特性,用起來真的很爽!


汪偉俊 | 作者
Java技術(shù)迷 | 出品
Java8新特性中最為重要的便是Lambda表達(dá)式和Stream API了,先來了解一下Lambda表達(dá)式吧。
Lambda表達(dá)式
Lambda表達(dá)式是一個(gè)匿名函數(shù),我們可以將Lambda表達(dá)式理解為一段可以作為參數(shù)傳遞的代碼,通過Lambda表達(dá)式,我們可以將Java程序變得更加簡(jiǎn)潔和靈活。
來看一段程序:
@Test
public void test() {
Comparator<Integer> comparator = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
};
Set<Integer> set = new TreeSet<>(comparator);
set.add(3);
set.add(2);
set.add(1);
System.out.println(set);
}
在JDK8以前,若是想實(shí)現(xiàn)對(duì)TreeSet的自定義排序,我們可以創(chuàng)建匿名的比較器類將其傳入TreeSet的構(gòu)造方法,而JDK8之后,使用Lambda表達(dá)式可以簡(jiǎn)化匿名內(nèi)部類的代碼:
@Test
public void test() {
Comparator<Integer> comparator = (o1, o2) -> o2 - o1;
Set<Integer> set = new TreeSet<>(comparator);
set.add(3);
set.add(2);
set.add(1);
System.out.println(set);
}
原本匿名內(nèi)部類的創(chuàng)建現(xiàn)在直接被簡(jiǎn)化成了一行代碼:
Comparator<Integer> comparator = (o1, o2) -> o2 - o1;
下面就來看看Lambda該如何使用,也就是學(xué)習(xí)一下它的語法。
Lambda表達(dá)式語法
在Java8中新引入了一個(gè)操作符:-> ,它被稱為箭頭操作符或Lambda操作符,箭頭操作符將Lambda表達(dá)式拆分成了左側(cè)和右側(cè)的兩部分,其中左側(cè)為L(zhǎng)ambda表達(dá)式的 參數(shù)列表 ,右側(cè)為L(zhǎng)ambda表達(dá)式的功能代碼,也叫 Lambda體 。對(duì)應(yīng)一個(gè)具體的Lambda表達(dá)式:
Comparator<Integer> comparator = (o1, o2) -> o2 - o1;
此時(shí)箭頭操作符的左側(cè)就是Comparator接口中compare方法的參數(shù)列表,右側(cè)即為該方法所需要實(shí)現(xiàn)的功能:
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
......
}
基于接口中方法聲明的不同,Lambda表達(dá)式的編寫方式也會(huì)隨之發(fā)生相應(yīng)的變化,大體分為以下幾類:
無參無返回值: Runnable runnable = () -> System.out.println("Hello Lambda!");有一個(gè)參數(shù)但無返回值: Consumer consumer = (s) -> System.out.println(s);若是方法只有一個(gè)參數(shù),則可以省略小括號(hào),所以可以簡(jiǎn)寫為: Consumer consumer = s -> System.out.println(s);有多個(gè)參數(shù)有返回值,且Lambda體中有多條語句:
Comparator<Integer> comparator = (o1, o2) -> {
System.out.println("從大到小排列");
return o2 - o1;
};
若是Lambda體中有多條語句,則Lambda體必須用大括號(hào)包裹起來,若是只有一條語句,則可以省略大括號(hào)。
有多個(gè)參數(shù)有返回值,但Lambda體中只有一條返回語句: Comparator comparator = (o1, o2) -> o2 - o1;對(duì)于這種情況,可以省略大括號(hào)和return關(guān)鍵字,Lambda體中只剩下需要return的內(nèi)容
會(huì)發(fā)現(xiàn)在所有的Lambda表達(dá)式中我們并沒有為參數(shù)定義任何類型,這是因?yàn)镴VM編譯器能夠通過上下文自動(dòng)推斷出參數(shù)類型。
需要注意的是,并不是所有的接口實(shí)現(xiàn)都可以使用Lambda表達(dá)式,它需要 函數(shù)式接口 的支持,那么什么是函數(shù)式接口呢?
函數(shù)式接口指的是接口中只有一個(gè)抽象方法的接口
這非常好理解,若是接口中存在多個(gè)抽象方法,Lambda表達(dá)式是無法知曉我們到底需要實(shí)現(xiàn)哪個(gè)方法的,所以Lambda表達(dá)式的使用必須基于函數(shù)式接口。
JDK1.8為此專門提供了 @FunctionalInterface 注解來聲明一個(gè)函數(shù)式接口,倘若在接口中聲明了該注解,則該接口必須擁有且只能擁有一個(gè)方法:
@FunctionalInterface
interface calc{
void add();
}
若不滿足要求則會(huì)編譯報(bào)錯(cuò)。
有些同學(xué)可能會(huì)發(fā)現(xiàn)在使用Lambda表達(dá)式實(shí)現(xiàn)一些功能時(shí),還需要自己去額外編寫一個(gè)函數(shù)式接口,而事實(shí)上,JDK1.8已經(jīng)為我們內(nèi)置了四大核心函數(shù)式接口,分別是:
Consumer :消費(fèi)型接口,抽象方法為: void accept(T t);Supplier :供給型接口,抽象方法為: T get();Function<T, R>:函數(shù)型接口,抽象方法為: R apply(T t);Predicate :斷言型接口,抽象方法為: boolean test(T t);
通過它們就已經(jīng)能夠解決大部分的問題了,具體使用哪個(gè)接口可以根據(jù)自己的實(shí)際需求決定,比如若是需要實(shí)現(xiàn)的功能帶參數(shù)而無返回值,則使用消費(fèi)型接口;若是需要實(shí)現(xiàn)的功能無參數(shù)但有返回值,則使用供給型接口。
這里以供給型接口為例,實(shí)現(xiàn)一個(gè)需求,產(chǎn)生指定個(gè)數(shù)的整數(shù),并放入集合中,代碼如下:
@Test
public void test() {
List<Integer> list = getList(5, () -> new Random().nextInt(20));
System.out.println(list);
}
public List<Integer> getList(int len, Supplier<Integer> supplier) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < len; i++) {
list.add(supplier.get());
}
return list;
}
方法引用
若Lambda體中的內(nèi)容有方法已經(jīng)實(shí)現(xiàn)了,那么就可以使用方法引用,可以理解為方法引用是Lambda表達(dá)式的另一種表現(xiàn)形式,方法引用主要有以下三種形式:
對(duì)象::實(shí)例方法名 類::靜態(tài)方法名 類::實(shí)例方法名
來看一個(gè)例子:
@Test
public void test() {
Consumer<String> consumer = (x)-> System.out.println(x);
consumer.accept("Hello!");
}
這里使用Consumer消費(fèi)型接口實(shí)現(xiàn)了一個(gè)輸出字符串的功能,由于Lambda體中的內(nèi)容已經(jīng)被 System.out.println 實(shí)現(xiàn)了,所以可以簡(jiǎn)寫為:
@Test
public void test() {
Consumer<String> consumer = System.out::println; // 簡(jiǎn)寫為...
consumer.accept("Hello!");
}
然而方法引用需要遵循一個(gè)原則,即:Lambda體中的方法參數(shù)和返回值需要與函數(shù)式接口中的抽象方法聲明一致,比如這里的Consumer接口中的抽象方法為:
void accept(T t);
而輸出語句的聲明如下:
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
它們都帶有一個(gè)參數(shù)且無返回值,所以可以使用方法引用。
又比如:
@Test
public void test() {
User user = new User();
user.setName("aaa");
Supplier<String> supplier = () -> user.getName();
String str = supplier.get();
System.out.println(str);
}
這里的 user.getName() 也可以使用方法引用,簡(jiǎn)寫為:
Supplier<String> supplier = user::getName;
這也是因?yàn)閁ser中g(shù)et方法與函數(shù)式接口中方法參數(shù)和返回值的聲明相同:
// User對(duì)象的getName方法
public String getName() {
return name;
}
// Supplier接口的get方法
T get();
我們還可以方法引用類的靜態(tài)方法,例如:
@Test
public void test() {
Comparator<Integer> comparator = Integer::compare;
int result = comparator.compare(1, 2);
System.out.println(result);
}
因?yàn)長(zhǎng)ambda體中的內(nèi)容已經(jīng)被compare方法實(shí)現(xiàn)且參數(shù)和返回值聲明與Comparator接口中的抽象方法聲明相同,它就能夠使用方法引用:
Comparator<Integer> comparator = Integer::compare;
且compare是Integer類的靜態(tài)方法,這種引用方式被稱為類的靜態(tài)方法引用。
最后一種形式是類的實(shí)例方法引用,比如:
@Test
public void test() {
BiPredicate<String, String> biPredicate = (s1, s2) -> s1.equals(s2);
boolean flag = biPredicate.test("abc", "abc");
System.out.println(flag);
}
這里實(shí)現(xiàn)了函數(shù)式接口的方法使其能夠判斷兩個(gè)字符串的內(nèi)容是否相同,它能夠被簡(jiǎn)寫為:
BiPredicate<String, String> biPredicate = String::equals;
對(duì)于類的實(shí)例方法引用,也有它的要求,必須滿足第一個(gè)參數(shù)是方法的調(diào)用者,第二個(gè)參數(shù)是調(diào)用方法的參數(shù)才能使用該引用方式。
構(gòu)造器引用
構(gòu)造器引用與方法引用類似,它通過 類名::new 實(shí)現(xiàn),比如:
@Test
public void test() {
Supplier<User> supplier = ()->new User();
User user = supplier.get();
System.out.println(user);
}
此時(shí)創(chuàng)建User對(duì)象的過程就可以使用構(gòu)造器引用來簡(jiǎn)化:
Supplier<User> supplier = User::new;
我們都知道一個(gè)類可以有多個(gè)重載的構(gòu)造器,那么構(gòu)造器引用調(diào)用的是類中的哪個(gè)構(gòu)造器呢?和方法引用類似,我們?nèi)匀煌ㄟ^構(gòu)造器方法與接口中抽象方法參數(shù)和返回值的聲明來判斷調(diào)用哪個(gè)構(gòu)造器,這里的Supplier接口中的抽象方法是一個(gè)不帶參數(shù)的方法:
T get();
所以它將調(diào)用對(duì)象的無參構(gòu)造方法,又比如:
@Test
public void test() {
Function<String, User> function = User::new;
User user = function.apply("zhangsan");
System.out.println(user);
}
來看看Function接口中的抽象方法:
R apply(T t);
它帶有一個(gè)參數(shù),所以調(diào)用的是User對(duì)象帶一個(gè)參數(shù)的構(gòu)造方法:
public class User {
private String name;
public User(String name){
this.name = name;
}
......
}
Stream API
JDK8中另一重要的新特性就是Stream API,通過Stream,我們能夠在集合數(shù)據(jù)中進(jìn)行一些非常復(fù)雜的查找、過濾、映射等操作,而且實(shí)現(xiàn)起來會(huì)非常高效和簡(jiǎn)單。
@Test
public void test() {
// 通過集合的stream方法獲取流
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();
// 通過Arrays工具類的stream方法獲取流
Stream<String> stream1 = Arrays.stream(new String[]{"1", "2", "3", "4", "5"});
// 通過Stream類的of方法獲取流
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5);
// 創(chuàng)建無限流
Stream<Integer> stream3 = Stream.iterate(0, (x) -> x + 2);
}
以上是四種獲取Stream的方式,最后一種創(chuàng)建的是無限流,也就是說,該流創(chuàng)建的是從0開始,每次加2的無限序列。
使用Stream我們能夠很輕松地實(shí)現(xiàn)過濾操作,比如獲取無限流中前5個(gè)元素,代碼如下:
@Test
public void test() {
Stream<Integer> stream = Stream.iterate(0, (x) -> x + 2);
Stream<Integer> stream1 = stream.limit(5);
stream1.forEach(System.out::println);
}
通過limit方法即可實(shí)現(xiàn)獲取前5個(gè)元素,這里使用了forEach方法進(jìn)行遍歷,并使用了Lambda表達(dá)式,我們一起來復(fù)習(xí)一下,查看forEach方法的源碼:
void forEach(Consumer<? super T> action);
可以看到該方法的參數(shù)是一個(gè)消費(fèi)型的函數(shù)式接口,其接口的抽象方法是帶參而無返回值的,所以若是想輸出元素,則可以如此做:
stream1.forEach((i) -> System.out.println(i));
又因?yàn)檩敵稣Z句的參數(shù)和返回值與接口抽象方法的聲明一致,所以可以使用方法引用,最終簡(jiǎn)化為:
stream1.forEach(System.out::println);
我們還可以通過Stream類的generate方法生成無限流:
@Test
public void test() {
Stream.generate(Math::random)
.limit(5)
.forEach(System.out::println);
}
generate方法需要的是一個(gè)供給型接口,它的抽象方法是不帶參而有返回值的,我們通過 Math.random() 方法生成隨機(jī)數(shù)作為返回值,又因?yàn)閞andom方法也是帶一個(gè)參而有返回值的,所以可以使用類的靜態(tài)方法引用,后續(xù)的Stream操作中將涉及大量的Lambda表達(dá)式,屆時(shí)將不再過多介紹Lambda表達(dá)式的寫法。
Stream的篩選操作
剛才我們通過limit方法簡(jiǎn)單地了解到Stream的篩選功能,當(dāng)然了,Stream的篩選能力可遠(yuǎn)不止如此,這里介紹四種篩選方法:
filter limit skip distinct
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 30, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
// 篩選出年齡大于25的用戶
Stream<User> stream = userList.stream()
.filter((user) -> user.getAge() > 25);
stream.forEach(System.out::println);
}
通過filter方法,我們能夠?qū)崿F(xiàn)很多的篩選功能,比如這里就可以篩選出年齡大于25的用戶,filter方法的參數(shù)是一個(gè)斷言型接口,接收一個(gè)參數(shù),返回值為boolean類型,即:為true則滿足篩選條件,為false則不滿足。
limit方法我們已經(jīng)使用過了,它用來截?cái)郤tream,使得Stream獲取從開始位置到指定位置的元素內(nèi)容。
第三個(gè)方法是skip:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 30, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
// 篩選出年齡大于25的用戶
Stream<User> stream = userList.stream()
.skip(2);
stream.forEach(System.out::println);
}
它與limit方法正好相反,skip會(huì)丟棄掉從開始位置到指定位置的元素內(nèi)容,比如上面這段程序便會(huì)將 張三 和 李四 用戶的信息丟掉。
最后一個(gè)方法是distinct:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 30, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
// 篩選出年齡大于25的用戶
Stream<User> stream = userList.stream()
.distinct();
stream.forEach(System.out::println);
}
該方法用于去除流中重復(fù)的元素,需要注意的是該方法依賴于equals和hashCode方法,所以User對(duì)象必須重寫這兩個(gè)方法:
public class User {
private String name;
private Integer age;
private Integer sex;
......
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(name, user.name) && Objects.equals(age, user.age) && Objects.equals(sex, user.sex);
}
@Override
public int hashCode() {
return Objects.hash(name, age, sex);
}
}
Stream的映射操作
Stream中的map方法用于映射操作,它能將元素轉(zhuǎn)換成其它形式或提取信息,接收一個(gè)函數(shù)作為參數(shù),該函數(shù)會(huì)被應(yīng)用到Stream中的每個(gè)元素上,并將其映射成為一個(gè)新的元素。
@Test
public void test() {
List<String> list = Arrays.asList("aa", "bb", "cc", "dd", "ee");
list.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
}
map方法的參數(shù)是一個(gè)函數(shù)型接口,Stream中的每個(gè)元素都會(huì)被應(yīng)用到該接口方法的實(shí)現(xiàn)上,所以每個(gè)元素都會(huì)被轉(zhuǎn)換成大寫字母。
map方法也能用于提取Stream中每個(gè)元素的信息:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 30, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
userList.stream()
.map(User::getName)
.forEach(System.out::println);
}
此時(shí)所有用戶的名字就都被提取出來了。
Stream的排序操作
Stream中的排序也分為兩種,自然排序和自定義排序,首先是自然排序,調(diào)用sorted方法即可實(shí)現(xiàn):
@Test
public void test() {
List<Integer> list = Arrays.asList(3, 1, 6, 7, 5, 9);
list.stream()
.sorted()
.forEach(System.out::println);
}
自定義排序就需要傳入自己實(shí)現(xiàn)的比較器:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
userList.stream()
.sorted((u1, u2) -> {
if (u1.getAge().equals(u2.getAge())) {
return u1.getName().compareTo(u2.getName());
} else {
return u1.getAge().compareTo(u2.getAge());
}
})
.forEach(System.out::println);
}
該程序段實(shí)現(xiàn)了按照年齡對(duì)User信息進(jìn)行排序,若年齡相同,則再按照姓名排序。
Stream的匹配操作
Stream中提供了豐富的匹配方法用于校驗(yàn)數(shù)據(jù),分別如下:
allMatch:是否匹配所有元素 anyMatch:是否至少匹配一個(gè)元素 noneMatch:是否沒有匹配所有元素 findFirst:返回第一個(gè)元素 findAny:返回流中的任意元素 count:返回元素個(gè)數(shù) max:返回最大值 min:返回最小值
比如:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
boolean flag = userList.stream()
.allMatch((u) -> u.getSex().equals(1));
System.out.println(flag);
}
這段程序中,它會(huì)判斷Stream中的所有User對(duì)象的sex值是否為1,若滿足,則返回true,否則返回false,這里的結(jié)果當(dāng)然就是false了。
若是將匹配方法修改為 anyMatch ,則結(jié)果會(huì)變?yōu)閠rue:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
boolean flag = userList.stream()
.anyMatch((u) -> u.getSex().equals(1));
System.out.println(flag);
}
當(dāng)所有User對(duì)象的sex為0時(shí)結(jié)果才為false。
noneMatch方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
boolean flag = userList.stream()
.noneMatch((u) -> u.getSex().equals(1));
System.out.println(flag);
}
因?yàn)镾tream中有User對(duì)象的sex值為1,所以沒有匹配所有元素是不成立的,故結(jié)果為false,只有當(dāng)所有User對(duì)象的sex值均為0,此時(shí)沒有匹配所有元素成立,結(jié)果才為true。
findFirst方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Optional<User> optional = userList.stream()
.sorted(Comparator.comparing(User::getAge))
.findFirst();
User user = optional.get();
System.out.println(user);
}
該程序段對(duì)Stream中的User對(duì)象按年齡進(jìn)行升序,并使用findFirst方法獲取第一個(gè)User對(duì)象,注意這里的返回值是Optional,這也是JDK1.8的新特性,它是用來避免頻繁出現(xiàn)的空指針異常的,這個(gè)我們后面會(huì)介紹。
findAny方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Optional<User> optional = userList.stream()
.filter((u) -> u.getAge().equals(20))
.findAny();
User user = optional.get();
System.out.println(user);
}
這里首先使用filter過濾出年齡為20的用戶,此時(shí)張三和李四都符合條件,而findAny方法便會(huì)從這兩個(gè)對(duì)象中隨機(jī)選擇一個(gè)返回,然而這種情況它只會(huì)一直返回姓名為張三的User對(duì)象,因?yàn)楫?dāng)前的Stream是串行流,我們需要獲取并行流才能實(shí)現(xiàn)隨機(jī)獲取的效果:
// parallelStream()方法獲取并行流
Optional<User> optional = userList.parallelStream()
.filter((u) -> u.getAge().equals(20))
.findAny();
count方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
long count = userList.stream()
.count();
System.out.println(count);
}
獲取當(dāng)前Stream中的元素個(gè)數(shù),結(jié)果為4。
max方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Optional<User> optional = userList.stream()
.max(Comparator.comparing(User::getAge));
User user = optional.get();
System.out.println(user);
}
該程序段獲取的是Stream中年齡最大的User對(duì)象。
min方法:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Optional<User> optional = userList.stream()
.min(Comparator.comparing(User::getAge));
User user = optional.get();
System.out.println(user);
}
將調(diào)用方法換為min,則它將獲取Stream中年齡最小的User對(duì)象。
Stream的收集操作
@Test
public void test() {
List<Integer> list = Arrays.asList(3, 1, 6, 7, 5, 9);
Integer result = list.stream()
.reduce(0, Integer::sum);
System.out.println(result);
}
該程序段中使用了一個(gè)新的方法:reduce ,它的作用是將流中的元素按規(guī)則反復(fù)地結(jié)合起來,得到一個(gè)值,比如這里的結(jié)果就是將流中的元素全部相加得到和,我們先將方法引用展開再說說其原理:
@Test
public void test() {
List<Integer> list = Arrays.asList(3, 1, 6, 7, 5, 9);
Integer result = list.stream()
.reduce(0, (i, j) -> i + j);
System.out.println(result);
}
reduce會(huì)將第一個(gè)參數(shù)值0作為起始值,其第一次迭代便是將0作為變量i的值,并從流中取出第一個(gè)元素作為變量j的值,所以第一次的執(zhí)行結(jié)果為:0 + 1 = 1 ,并將該結(jié)果作為變量i的值,從流中取出第二個(gè)元素作為變量j的值進(jìn)行下一次運(yùn)算,結(jié)果為:1 + 3 = 4 ,以此類推,最終得到總和。
Stream提供了collect方法用于收集操作,它可以將那些經(jīng)過過濾、映射、排序等操作后的Stream數(shù)據(jù)重新收集起來,成為一個(gè)新的集合數(shù)據(jù),代碼如下:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
List<String> nameList = userList.stream()
.map(User::getName)
.collect(Collectors.toList());
System.out.println(nameList);
}
此時(shí)我們便將所有User對(duì)象的姓名取出,并收集到了一個(gè)新的集合中。Collectors類提供了非常多的靜態(tài)方法供我們更方便地進(jìn)行收集,toList、toSet、toMap、toCollection等等,比如將數(shù)據(jù)收集成Set集合:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Set<String> nameSet = userList.stream()
.map(User::getName)
.collect(Collectors.toSet());
System.out.println(nameSet);
}
則這樣便取出了所有User對(duì)象的姓名且不重復(fù)。若是想將數(shù)據(jù)收集成HashSet呢?Collectors類中并未提供toHashSet方法,但我們可以通過toCollection方法實(shí)現(xiàn):
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Set<String> nameSet = userList.stream()
.map(User::getName)
.collect(Collectors.toCollection(HashSet::new));
System.out.println(nameSet);
}
toCollection方法需要接收一個(gè)供給型接口,通過構(gòu)造器引用創(chuàng)建HashSet對(duì)象即可。
Collectors還提供了一些類似SQL的聚合操作,比如求元素個(gè)數(shù):
Long count = userList.stream()
.map(User::getName).count();
求平均值:
Double avgAge = userList.stream()
.collect(Collectors.averagingDouble(User::getAge));
求總和:
Integer sumAge = userList.stream()
.collect(Collectors.summingInt(User::getAge));
最大值:
Optional<User> optional = userList.stream()
.collect(Collectors.maxBy(Comparator.comparingInt(User::getAge)));
User user = optional.get();
最小值:
Optional<User> optional = userList.stream()
.collect(Collectors.minBy(Comparator.comparingInt(User::getAge)));
User user = optional.get();
它甚至能夠?qū)崿F(xiàn)分組,比如按照年齡分組:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Map<Integer, List<User>> map = userList.stream()
.collect(Collectors.groupingBy(User::getAge));
System.out.println(map);
}
運(yùn)行結(jié)果:
{20=[User{name='張三', age=20, sex=0}, User{name='李四', age=20, sex=0}], 25=[User{name='王五', age=25, sex=1}, User{name='王五', age=25, sex=1}], 42=[User{name='趙六', age=42, sex=1}]}
還能夠進(jìn)行多級(jí)分組,比如先按照年齡分組,再按照性別分組:
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Map<Integer, Map<String, List<User>>> map = userList.stream()
.collect(Collectors.groupingBy(User::getAge, Collectors.groupingBy((u) -> {
if (u.getSex() == 0) {
return "男";
} else {
return "女";
}
})));
System.out.println(map);
}
運(yùn)行結(jié)果:
{20={男=[User{name='張三', age=20, sex=0}, User{name='李四', age=20, sex=0}]}, 25={女=[User{name='王五', age=25, sex=1}, User{name='王五', age=25, sex=1}]}, 42={女=[User{name='趙六', age=42, sex=1}]}}
按年齡進(jìn)行分區(qū):
@Test
public void test() {
List<User> userList = Arrays.asList(
new User("張三", 20, 0),
new User("李四", 20, 0),
new User("王五", 25, 1),
new User("王五", 25, 1),
new User("趙六", 42, 1)
);
Map<Boolean, List<User>> map = userList.stream()
.collect(Collectors.partitioningBy((u) -> u.getAge() > 20));
System.out.println(map);
}
運(yùn)行結(jié)果:
{false=[User{name='張三', age=20, sex=0}, User{name='李四', age=20, sex=0}], true=[User{name='王五', age=25, sex=1}, User{name='王五', age=25, sex=1}, User{name='趙六', age=42, sex=1}]}
它會(huì)按照年齡大于20和小于等于20的規(guī)則將User對(duì)象分為兩組。
Optional
Optional類是一個(gè)容器類,代表一個(gè)值存在或者不存在,JDK1.8中使用Optional來更好地表示一個(gè)null值,可以大大地避免空指針異常的產(chǎn)生。
該類下有一些常用的方法:
of(T t):創(chuàng)建Optional實(shí)例 empty():創(chuàng)建一個(gè)空的Optional實(shí)例 ofNullable(T t):若t不為null,創(chuàng)建Optional實(shí)例,否則創(chuàng)建空的Optional實(shí)例 isPresent():判斷是否包含值 orElse(T t):如果調(diào)用對(duì)象包含值,返回該值,否則返回t orElseGet(Suppiler s):如果調(diào)用對(duì)象包含值,返回該值,否則返回s獲取的值 map(Function f):如果有值對(duì)其處理,并返回處理后的Optional,否則返回空的Optional實(shí)例
@Test
public void test() {
Optional<User> optional = Optional.of(new User());
User user = optional.get();
System.out.println(user);
}
需要注意,of方法不能接收一個(gè)為null的參數(shù),否則仍然會(huì)報(bào)空指針異常,此時(shí)應(yīng)該使用_ofNullable_方法來處理:
@Test
public void test() {
Optional<Object> optional = Optional.ofNullable(null);
System.out.println(optional.get());
}
它不會(huì)報(bào)空指針異常,隨之而來的是NoSuchElementException異常:
java.util.NoSuchElementException: No value present
at java.util.Optional.get(Optional.java:135)
at com.wwj.test.TestDemo.test(TestDemo.java:15)
其它方法的使用非常簡(jiǎn)單,這里直接列出:
@Test
public void test() {
Optional<User> optional = Optional.of(new User("張三", 20, 0));
// 獲取值
User user = optional.get();
// 判斷是否有值,結(jié)果為true
boolean flag = optional.isPresent();
// 若optional中有值,則返回該值,否則返回orElse新創(chuàng)建的值
User user1 = optional.orElse(new User("李四", 22, 0));
// 該方法與orElse功能相同,區(qū)別在于該方法的參數(shù)是一個(gè)供給型接口,通過接口實(shí)現(xiàn)可以編寫更加復(fù)雜的功能
User user2 = optional.orElseGet(() -> new User("李四", 22, 0));
// 若Optional中有值,則返回處理后的結(jié)果,否則返回一個(gè)Optional.empty實(shí)例
Optional<String> str = optional.map(User::getName);
// 該方法與map方法功能相同,區(qū)別在于該方法的返回值必須是Optional類型
Optional<String> str2 = optional.flatMap((u) -> Optional.of(u.getName()));
}
接口可以有默認(rèn)方法和靜態(tài)方法了
public class TestDemo {
@Test
public void test() {
TestInterface testInterface = new TestInterface();
int result = testInterface.calc(1, 2);
System.out.println(result);
}
}
interface MyInterface {
default int calc(int x, int y) {
return x + y;
}
}
class TestInterface implements MyInterface {
}
JDK1.8以后,接口中可以提供已實(shí)現(xiàn)的默認(rèn)方法了,此時(shí)類在實(shí)現(xiàn)該接口時(shí)就無需實(shí)現(xiàn)默認(rèn)方法了,但有這么一種情況:
public class TestDemo {
@Test
public void test() {
TestClass testClass = new TestClass();
int result = testClass.calc(1, 2);
System.out.println(result);
}
}
class TestClass extends MyClass implements MyInterface{
}
interface MyInterface {
default int calc(int x, int y) {
return x + y;
}
}
class MyClass {
public int calc(int x, int y) {
return x - y;
}
}
TestClass類分別繼承了MyClass類和實(shí)現(xiàn)了MyInterface接口,然而MyClass類和MyInterface接口中都有一個(gè)相同的方法,此時(shí)調(diào)用TestClass對(duì)象的calc方法,執(zhí)行的究竟是誰的方法呢?
事實(shí)上,JDK1.8規(guī)定,接口的默認(rèn)方法遵循 類優(yōu)先 的原則,即:一個(gè)接口中定義了一個(gè)默認(rèn)方法,而另外一個(gè)父類或者接口中又定義了一個(gè)相同的方法,那么它會(huì)優(yōu)先選擇父類中的方法,而忽略掉接口中的默認(rèn)方法。
若是兩個(gè)接口中都有一個(gè)相同的默認(rèn)方法,則某個(gè)類在同時(shí)實(shí)現(xiàn)這兩個(gè)接口的時(shí)候便會(huì)發(fā)生沖突,此時(shí)實(shí)現(xiàn)類就必須覆蓋方法來解決沖突:
class TestClass implements MyInterface,MyInterfac2{
@Override
public int calc(int x, int y) {
return x + y;
}
}
interface MyInterface {
default int calc(int x, int y) {
return x + y;
}
}
interface MyInterfac2 {
default int calc(int x, int y) {
return x + y;
}
}
除了默認(rèn)方法,JDK1.8中還可以擁有靜態(tài)方法:
public class TestDemo {
@Test
public void test() {
MyInterface.show();
}
}
interface MyInterface {
static void show() {
System.out.println("Hello!");
}
}
全新的日期時(shí)間API
傳統(tǒng)的日期時(shí)間API大部分已經(jīng)過期,比如Date類中的方法,而且方法比較難用,傳參復(fù)雜,多線程環(huán)境下還會(huì)有安全問題:
@Test
public void test() throws ExecutionException, InterruptedException {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
Callable<Date> callable = () -> format.parse("2021-04-11");
ExecutorService pool = Executors.newFixedThreadPool(10);
List<Future<Date>> result = new ArrayList<>();
for (int i = 0; i < 10; i++) {
result.add(pool.submit(callable));
}
for (Future<Date> dateFuture : result) {
System.out.println(dateFuture.get());
}
}
運(yùn)行結(jié)果:
Sun Apr 11 00:00:00 CST 2021
java.util.concurrent.ExecutionException: java.lang.NumberFormatException: multiple points
at com.wwj.test.TestDemo.test(TestDemo.java:23)
當(dāng)然了,解決這一線程安全問題的方法有很多,在每個(gè)線程中都新創(chuàng)建SimpleDateFormat對(duì)象:
Callable<Date> callable = () -> new SimpleDateFormat("yyyy-MM-dd").parse("2021-04-11");
或者使用ThreadLocal類:
public class DateFormatThreadLocal {
private static final ThreadLocal<DateFormat> format = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
};
public static Date convert(String date) throws ParseException {
return format.get().parse(date);
}
}
然后使用該類進(jìn)行日期格式化:
Callable<Date> callable = () -> DateFormatThreadLocal.convert("2021-04-11");
而JDK1.8提供了一套全新的日期時(shí)間API用于簡(jiǎn)化對(duì)日期時(shí)間的處理,先來看一個(gè)簡(jiǎn)單示例:
@Test
public void test() throws ExecutionException, InterruptedException {
DateTimeFormatter formatter = DateTimeFormatter.ISO_LOCAL_DATE;
LocalDate date = LocalDate.parse("2021-04-11", formatter);
System.out.println(date);
}
通過DateTimeFormatter可以指定轉(zhuǎn)換日期的格式,它內(nèi)置了非常多的日期格式: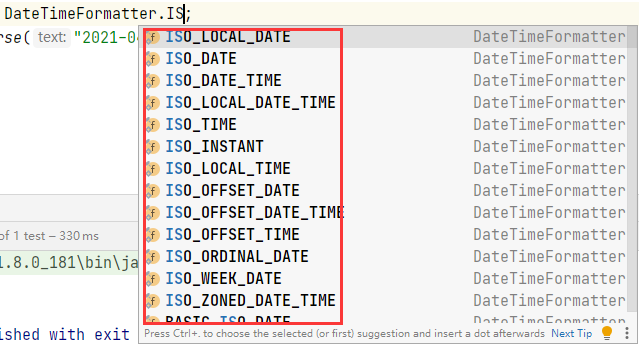 若是這里沒有自己需要的日期格式,也可以自定義:
若是這里沒有自己需要的日期格式,也可以自定義:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");
LocalDate date = LocalDate.parse("20210411", formatter);
System.out.println(date);
因?yàn)檫@些新的日期時(shí)間API都是被final修飾的,所以它們天生就是線程安全的。
先來介紹三個(gè)提供日期時(shí)間的API:
LocalDate LocalTime LocalDateTime
它們的用法完全相同,所以這里只介紹LocalDate類的使用:
@Test
public void test() {
// 獲取當(dāng)前日期的LocalDate實(shí)例
LocalDate date = LocalDate.now();
System.out.println(date);
// 獲取指定日期的LocalDate實(shí)例
LocalDate date2 = LocalDate.of(2021, 4, 10);
System.out.println(date2);
System.out.println("------------");
System.out.println("一天后的日期:" + date.plusDays(1));
System.out.println("一星期后的日期:" + date.plusWeeks(1));
System.out.println("一個(gè)月后的日期:" + date.plusMonths(1));
System.out.println("一年后的日期:" + date.plusYears(1));
System.out.println("------------");
System.out.println("一天前的日期:" + date.minusDays(1));
System.out.println("一星期前的日期:" + date.minusWeeks(1));
System.out.println("一個(gè)月前的日期:" + date.minusMonths(1));
System.out.println("一年前的日期:" + date.minusYears(1));
System.out.println("------------");
System.out.println("獲取日:" + date.getDayOfMonth());
System.out.println("獲取月:" + date.getMonthValue());
System.out.println("獲取年:" + date.getYear());
}
運(yùn)行結(jié)果:
2021-04-11
2021-04-10
------------
一天后的日期:2021-04-12
一星期后的日期:2021-04-18
一個(gè)月后的日期:2021-05-11
一年后的日期:2022-04-11
------------
一天前的日期:2021-04-10
一星期前的日期:2021-04-04
一個(gè)月前的日期:2021-03-11
一年前的日期:2020-04-11
------------
獲取日:11
獲取月:4
獲取年:2021
若是想獲取時(shí)間戳,可以使用Instant類:
@Test
public void test() throws InterruptedException {
Instant instant = Instant.now();
// 默認(rèn)是UTC時(shí)區(qū)
System.out.println(instant);
// 向后偏移8個(gè)小時(shí)即為我國的時(shí)間
OffsetDateTime offsetDateTime = instant.atOffset(ZoneOffset.ofHours(8));
System.out.println(offsetDateTime);
// 獲取時(shí)間戳的毫秒數(shù)
System.out.println(instant.toEpochMilli());
// 獲取向后偏移1個(gè)小時(shí)的時(shí)間戳,時(shí)間戳默認(rèn)以1970年1月1日00:00:00開始
Instant instant1 = Instant.ofEpochSecond(60 * 60);
System.out.println(instant1);
// 計(jì)算兩個(gè)時(shí)間戳之間的間隔
Instant instant2 = Instant.now();
Thread.sleep(1000);
Instant instant3 = Instant.now();
Duration duration = Duration.between(instant2, instant3);
System.out.println(duration);
// 計(jì)算兩個(gè)時(shí)間之間的間隔
LocalTime localTime = LocalTime.now();
Thread.sleep(1000);
LocalTime localTime2 = LocalTime.now();
Duration duration1 = Duration.between(localTime, localTime2);
System.out.println(duration1);
// 計(jì)算兩個(gè)日期之間的間隔
LocalDate localDate = LocalDate.now();
LocalDate localDate1 = LocalDate.of(2021, 4, 9);
Period period = Period.between(localDate, localDate1);
System.out.println(period);
}
運(yùn)行結(jié)果:
2021-04-11T09:53:33.836Z
2021-04-11T17:53:33.836+08:00
1618134813836
1970-01-01T01:00:00Z
PT1.012S
PT1.005S
P-2D
為了更加方便地操作日期時(shí)間,JDK1.8還為我們提供了時(shí)間校正器 TemporalAdjuster ,通過它我們就能夠非常方便地操縱日期和時(shí)間:
@Test
public void test() {
LocalDateTime dateTime = LocalDateTime.now();
System.out.println(dateTime);
// 計(jì)算下一個(gè)周日
LocalDateTime nextSunday = dateTime.with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
System.out.println(nextSunday);
// 自定義日期標(biāo)識(shí),計(jì)算下一個(gè)工作日
LocalDateTime localDateTime = dateTime.with((d) -> {
LocalDateTime ldt = (LocalDateTime) d;
DayOfWeek dayOfWeek = ldt.getDayOfWeek();
if (dayOfWeek.equals(DayOfWeek.FRIDAY)) {
return ldt.plusDays(3); // 如果是周五,則三天后就是工作日
} else if (dayOfWeek.equals(DayOfWeek.SATURDAY)) {
return ldt.plusDays(2); // 如果是周六,則兩天后就是工作日
} else {
return ldt.plusDays(1); // 其它時(shí)間都加一天
}
});
System.out.println(localDateTime);
}
最后是時(shí)間格式化操作,JDK1.8中使用DateTimeFormatter類來格式化日期和時(shí)間:
@Test
public void test() {
// 使用內(nèi)置的日期格式
DateTimeFormatter formatter = DateTimeFormatter.ISO_DATE;
LocalDateTime localDateTime = LocalDateTime.now();
String strDate = localDateTime.format(formatter);
System.out.println(strDate);
// 使用自定義格式
DateTimeFormatter formatter2 = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH時(shí)mm分ss秒");
String strDate2 = localDateTime.format(formatter2);
System.out.println(strDate2);
// 將日期時(shí)間字符串解析成LocalDateTime實(shí)例
LocalDateTime parse = localDateTime.parse(strDate2, formatter2);
System.out.println(parse);
}
還有時(shí)區(qū)的操作:
@Test
public void test() {
// 獲取所有支持的時(shí)區(qū)
Set<String> set = ZoneId.getAvailableZoneIds();
// 在獲取日期時(shí)設(shè)置時(shí)區(qū)
LocalDateTime localDateTime = LocalDateTime.now(ZoneId.of("America/Cuiaba"));
System.out.println(localDateTime);
LocalDateTime localDateTime2 = LocalDateTime.now();
// 獲取日期后設(shè)置時(shí)區(qū)
ZonedDateTime zonedDateTime = localDateTime2.atZone(ZoneId.of("Asia/Shanghai"));
System.out.println(zonedDateTime);
}
運(yùn)行結(jié)果:
2021-04-11T08:00:44.308
2021-04-11T20:00:44.334+08:00[Asia/Shanghai]
以上便是有關(guān)Java8新特性的全部?jī)?nèi)容。
本文作者:汪偉俊 為Java技術(shù)迷專欄作者 投稿,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載。

往 期 推 薦 1、網(wǎng)曝IDEA2020.3.2,自動(dòng)注釋類和方法注釋模板配置
2、牛逼!IntelliJ IDEA居然支持視頻聊天了~速來嘗鮮!快來沖一波
4、知名國產(chǎn)網(wǎng)盤翻車?清空免費(fèi)用戶文件后,又開始清理付費(fèi)用戶資源
1、網(wǎng)曝IDEA2020.3.2,自動(dòng)注釋類和方法注釋模板配置
2、牛逼!IntelliJ IDEA居然支持視頻聊天了~速來嘗鮮!快來沖一波
4、知名國產(chǎn)網(wǎng)盤翻車?清空免費(fèi)用戶文件后,又開始清理付費(fèi)用戶資源

點(diǎn)分享

點(diǎn)收藏

點(diǎn)點(diǎn)贊

點(diǎn)在看