
如何提升算法工程師的大數(shù)據(jù)開(kāi)發(fā)能力
大家好,我是DASOU;
我之前學(xué)習(xí)Spark的時(shí)候,主要是對(duì)著那本spark數(shù)據(jù)分析敲了一遍代碼,然后在Github上狂搜一些比較好的項(xiàng)目,還真讓我找到一個(gè),這個(gè)后面說(shuō);
我先來(lái)說(shuō)說(shuō)我的想法,就是為啥算法工程師需要大數(shù)據(jù)開(kāi)發(fā)能力。
對(duì)于算法工程師來(lái)說(shuō),開(kāi)發(fā)能力我自己認(rèn)為可以分為兩種。
一種是有能力寫(xiě)個(gè)比較穩(wěn)定的接口,對(duì)外提供服務(wù);如果并發(fā)很大的話(huà),公司一般會(huì)有專(zhuān)門(mén)的團(tuán)隊(duì)進(jìn)行維護(hù)。算法工程師寫(xiě)的接口,公司可能也不放心用,笑;
當(dāng)然如果接口也是組內(nèi)開(kāi)發(fā)同學(xué)寫(xiě)的,比如是C++代碼,需要你進(jìn)行上下線,那么你也要會(huì)相應(yīng)的C++,基本會(huì)用其實(shí)就可以了(如果是大佬,請(qǐng)忽略我這個(gè)渣渣的建議);
但是如果并發(fā)不大,比如幾百個(gè)并發(fā),那么需要自己操刀動(dòng)手。這個(gè)也不難,直接申請(qǐng)資源堆機(jī)器就可以(我開(kāi)玩笑的)。
另一種能力是數(shù)據(jù)獲取的能力。今天我重點(diǎn)說(shuō)這個(gè);一般在找工作的時(shí)候,這個(gè)技能是必備的,如果沒(méi)有這個(gè),基本就是沒(méi)戲了;
之前寫(xiě)個(gè)一個(gè)文章來(lái)聊這個(gè)事情,感興趣的朋友可以讀一下: 算法工程師常說(shuō)的【處理數(shù)據(jù)】究竟是在做什么
在互聯(lián)網(wǎng)公司,數(shù)據(jù)量是很大的。面對(duì)這么大量數(shù)據(jù),在做特征工程的時(shí)候,用numpy或者padas肯定是力有不逮的。
在獲取數(shù)據(jù)的時(shí)候一般就是hive,或者spark;
對(duì)于一個(gè)大型公司來(lái)說(shuō),一般是hive和spark都會(huì)使用;
對(duì)于Hive來(lái)說(shuō),一般只要懂SQL,一般操作hive就沒(méi)啥問(wèn)題;
如果要學(xué)習(xí)Spark,學(xué)習(xí)的時(shí)候一般會(huì)遇到一個(gè)困惑。Spark提供了多種接口,主流就是java,python和scala;那么學(xué)習(xí)哪一種呢?
我自己的建議是直接上手Pyspark,因?yàn)楹?jiǎn)單而且上手快;我自己就是學(xué)習(xí)的pyspark;
我在學(xué)習(xí)spark的時(shí)候,找了很多資源,對(duì)著那本saprk數(shù)據(jù)分析敲了大部分的代碼,然后在github上找到了一個(gè)比較好的項(xiàng)目,叫【10天吃掉那只pyspark】。
這個(gè)項(xiàng)目我自己對(duì)著敲了大部分代碼,然后看了一遍。不禁感嘆,有些人在寫(xiě)教程方面確實(shí)是有天賦的,拍馬難及。
我自己在B站是錄制了一些教學(xué)視頻(TRM視頻已經(jīng)突破2萬(wàn)了,太開(kāi)心了),知道寫(xiě)一個(gè)教程是有多難,時(shí)常因?yàn)樵趺窗褨|西寫(xiě)的淺顯易懂而苦惱。
總之吧,這個(gè)項(xiàng)目我自己還是很推薦的;
整個(gè)教程大綱大概是這樣的:
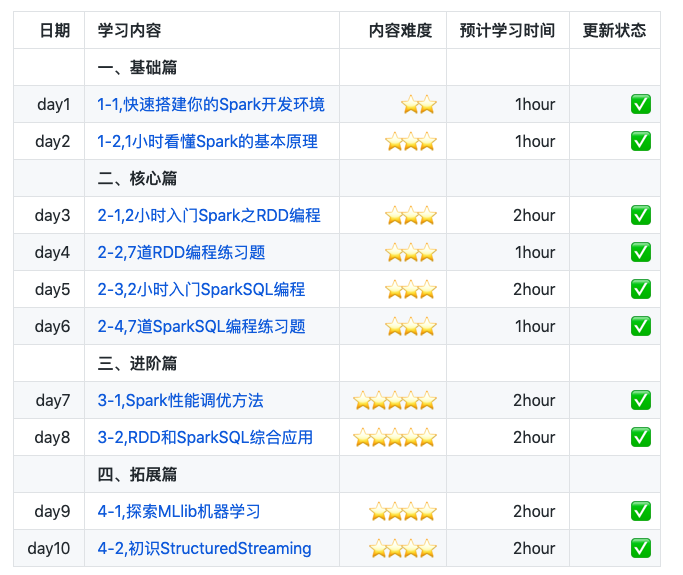
正巧和項(xiàng)目的作者約了一個(gè)互推,就把這個(gè)項(xiàng)目推薦給大家。希望第大家有所幫助。
感興趣的朋友直接關(guān)注下面公眾號(hào),后臺(tái)回復(fù)pyspark,獲取項(xiàng)目《eat pyspark in 10 days》github地址。
下面的內(nèi)容,我就直接照搬原作者的內(nèi)容了,包括項(xiàng)目地址,以及項(xiàng)目特色。感興趣的朋友可以看看,時(shí)間不夠的朋友直接看上面的github也可以;
一,pyspark ?? or spark-scala ?? ?
pyspark強(qiáng)于分析,spark-scala強(qiáng)于工程。
如果應(yīng)用場(chǎng)景有非常高的性能需求,應(yīng)該選擇spark-scala.
如果應(yīng)用場(chǎng)景有非常多的可視化和機(jī)器學(xué)習(xí)算法需求,推薦使用pyspark,可以更好地和python中的相關(guān)庫(kù)配合使用。
此外spark-scala支持spark graphx圖計(jì)算模塊,而pyspark是不支持的。
pyspark學(xué)習(xí)曲線平緩,spark-scala學(xué)習(xí)曲線陡峭。
從學(xué)習(xí)成本來(lái)說(shuō),spark-scala學(xué)習(xí)曲線陡峭,不僅因?yàn)閟cala是一門(mén)困難的語(yǔ)言,更加因?yàn)樵谇胺降牡缆飞蠒?huì)有無(wú)盡的環(huán)境配置痛苦等待著讀者。
而pyspark學(xué)習(xí)成本相對(duì)較低,環(huán)境配置相對(duì)容易。從學(xué)習(xí)成本來(lái)說(shuō),如果說(shuō)pyspark的學(xué)習(xí)成本是3,那么spark-scala的學(xué)習(xí)成本大概是9。
如果讀者有較強(qiáng)的學(xué)習(xí)能力和充分的學(xué)習(xí)時(shí)間,建議選擇spark-scala,能夠解鎖spark的全部技能,并獲得最優(yōu)性能,這也是工業(yè)界最普遍使用spark的方式。
如果讀者學(xué)習(xí)時(shí)間有限,并對(duì)Python情有獨(dú)鐘,建議選擇pyspark。pyspark在工業(yè)界的使用目前也越來(lái)越普遍。
二,本書(shū)?? 面向讀者??
本書(shū)假定讀者具有基礎(chǔ)的的Python編碼能力,熟悉Python中numpy, pandas庫(kù)的基本用法。
并且假定讀者具有一定的SQL使用經(jīng)驗(yàn),熟悉select,join,group by等sql語(yǔ)法。
三,本書(shū)寫(xiě)作風(fēng)格??
本書(shū)是一本對(duì)人類(lèi)用戶(hù)極其友善的pyspark入門(mén)工具書(shū),Don't let me think是本書(shū)的最高追求。
本書(shū)主要是在參考spark官方文檔,并結(jié)合作者學(xué)習(xí)使用經(jīng)驗(yàn)基礎(chǔ)上整理總結(jié)寫(xiě)成的。
不同于Spark官方文檔的繁冗斷碼,本書(shū)在篇章結(jié)構(gòu)和范例選取上做了大量的優(yōu)化,在用戶(hù)友好度方面更勝一籌。
本書(shū)按照內(nèi)容難易程度、讀者檢索習(xí)慣和spark自身的層次結(jié)構(gòu)設(shè)計(jì)內(nèi)容,循序漸進(jìn),層次清晰,方便按照功能查找相應(yīng)范例。
本書(shū)在范例設(shè)計(jì)上盡可能簡(jiǎn)約化和結(jié)構(gòu)化,增強(qiáng)范例易讀性和通用性,大部分代碼片段在實(shí)踐中可即取即用。
如果說(shuō)通過(guò)學(xué)習(xí)spark官方文檔掌握pyspark的難度大概是5,那么通過(guò)本書(shū)學(xué)習(xí)掌握pyspark的難度應(yīng)該大概是2.
僅以下圖對(duì)比spark官方文檔與本書(shū)《10天吃掉那只pyspark》的差異。

四,本書(shū)學(xué)習(xí)方案 ?
1,學(xué)習(xí)計(jì)劃
本書(shū)是作者利用工作之余大概1個(gè)月寫(xiě)成的,大部分讀者應(yīng)該在10天可以完全學(xué)會(huì)。
預(yù)計(jì)每天花費(fèi)的學(xué)習(xí)時(shí)間在30分鐘到2個(gè)小時(shí)之間。
當(dāng)然,本書(shū)也非常適合作為pyspark的工具手冊(cè)在工程落地時(shí)作為范例庫(kù)參考。
2,學(xué)習(xí)環(huán)境
本書(shū)全部源碼在jupyter中編寫(xiě)測(cè)試通過(guò),建議通過(guò)git克隆到本地,并在jupyter中交互式運(yùn)行學(xué)習(xí)。
為了直接能夠在jupyter中打開(kāi)markdown文件,建議安裝jupytext,將markdown轉(zhuǎn)換成ipynb文件。
為簡(jiǎn)單起見(jiàn),本書(shū)按照如下2個(gè)步驟配置單機(jī)版spark3.0.1環(huán)境進(jìn)行練習(xí)。
#step1: 安裝java8#jdk下載地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html#java安裝教程:https://www.runoob.com/java/java-environment-setup.html#step2: 安裝pyspark,findsparkpip install -i https://pypi.tuna.tsinghua.edu.cn/simple pysparkpip install findspark
此外,也可以在和鯨社區(qū)的云端notebook中直接運(yùn)行pyspark,沒(méi)有任何環(huán)境配置痛苦。詳情參考該項(xiàng)目的readme文檔。
import findspark
#指定spark_home,指定python路徑
spark_home = "/Users/liangyun/anaconda3/lib/python3.7/site-packages/pyspark"
python_path = "/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
print("spark version:",pyspark.__version__)
rdd = sc.parallelize(["hello","spark"])
print(rdd.reduce(lambda x,y:x+' '+y))
spark version: 3.0.1
hello spark
五,鼓勵(lì)和聯(lián)系作者
感興趣的小伙伴可以?huà)叽a下方二維碼,關(guān)注公眾號(hào):算法美食屋,后臺(tái)回復(fù)關(guān)鍵字:pyspark,獲取項(xiàng)目《eat pyspark in 10 days》github地址。
也可以在公眾號(hào)后臺(tái)回復(fù)關(guān)鍵字:spark加群,加入spark和大數(shù)據(jù)讀者交流群和大家討論。