
OpenAI煉丹秘籍:教你學會訓練大型神經(jīng)網(wǎng)絡

來源:新智元 本文約3000字,建議閱讀5分鐘
本文詳細介紹了一些訓練大型神經(jīng)網(wǎng)絡的相關技術及底層原理。

想知道那些超大規(guī)模神經(jīng)網(wǎng)絡都是怎么訓出來的?OpenAI一篇文章總結:除了顯卡要多,算法也很重要!


訓練流程無并行

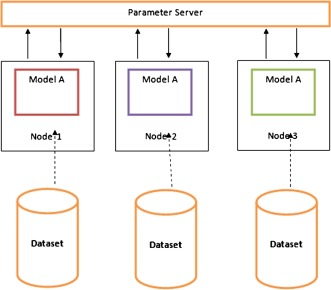
數(shù)據(jù)并行
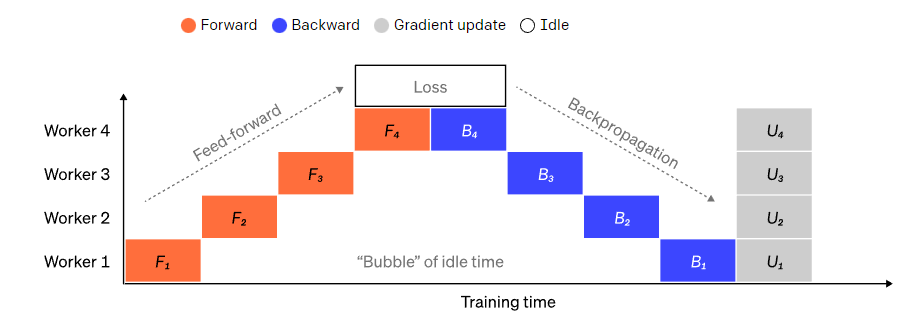
Pipeline并行
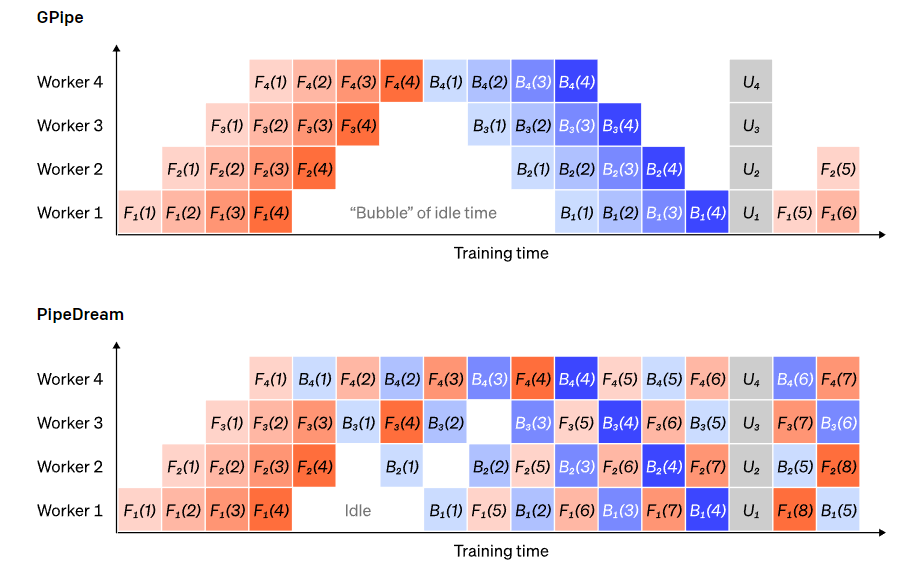
Tensor并行

混合專家系統(tǒng)(MoE)

省內存小妙招

參考資料:
https://openai.com/blog/techniques-for-training-large-neural-networks/
編輯:王菁
校對:龔力
評論
圖片
表情