
神經(jīng)網(wǎng)絡(luò)訓(xùn)練trick總結(jié)
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)


很直觀,因?yàn)樯窠?jīng)網(wǎng)絡(luò)可以隨意設(shè)計(jì),先驗(yàn)假設(shè)較少,參數(shù)多,超參數(shù)更多,那模型的自由度就非常高了,精心設(shè)計(jì)對于新手就變得較難了。這里講一些最簡單的trick,肯定不全面,歡迎大家留言補(bǔ)充。因?yàn)槲乙彩切率郑?/span>
下面介紹一些值得注意的部分,有些簡單解釋原理,具體細(xì)節(jié)不能面面俱到,請參考專業(yè)文章。
那我們直接從拿到一個(gè)問題決定用神經(jīng)網(wǎng)絡(luò)說起。一般而言,
首先選定你要采用的結(jié)構(gòu),如一對一,固定窗口,數(shù)據(jù)維度粒度,MLP,RNN或者CNN等
非線性選擇,sigmoid,tanh,ReLU,或者一些變體,一般tanh比sigmoid效果好一點(diǎn)(簡單說明下,兩者很類似,tanh是rescaled的sigmoid,sigmoid輸出都為正數(shù),根據(jù)BP規(guī)則,某層的神經(jīng)元的權(quán)重的梯度的符號(hào)和后層誤差的一樣,也就是說,如果后一層的誤差為正,則這一層的權(quán)重全部都要降低,如果為負(fù),則這一層梯度全部為負(fù),權(quán)重全部增加,權(quán)重要么都增加,要么都減少,這明顯是有問題的;tanh是以0為對稱中心的,這會(huì)消除在權(quán)重更新時(shí)的系統(tǒng)偏差導(dǎo)致的偏向性。當(dāng)然這是啟發(fā)式的,并不是說tanh一定比sigmoid的好),ReLU也是很好的選擇,最大的好處是,當(dāng)tanh和sigmoid飽和時(shí)都會(huì)有梯度消失的問題,ReLU就不會(huì)有這個(gè)問題,而且計(jì)算簡單,當(dāng)然它會(huì)產(chǎn)生dead neurons,下面會(huì)具體說。
Gradient Check,如果你覺得網(wǎng)絡(luò)feedforward沒什么問題,那么GC可以保證BP的過程沒什么bug。值得提的是,如果feedforward有問題,但是得到的誤差是差不多的,GC也會(huì)感覺是對的。大多情況GC可幫你找到很多問題!步驟如下:

那如果GC失敗,可能網(wǎng)絡(luò)某些部分有問題,也有可能整個(gè)網(wǎng)絡(luò)都有問題了!你也不知道哪出錯(cuò)了,那怎么辦呢?構(gòu)建一個(gè)可視化過程監(jiān)控每一個(gè)環(huán)節(jié),這可以讓你清楚知道你的網(wǎng)絡(luò)的每一地方是否有問題!!這里還有一個(gè)trick,先構(gòu)建一個(gè)簡單的任務(wù)(比如你做MNIST數(shù)字識(shí)別,你可以先識(shí)別0和1,如果成功可以再加入更多識(shí)別數(shù)字);然后從簡單到復(fù)雜逐步來檢測你的model,看哪里有問題。舉個(gè)例子吧,先用固定的data通過單層softmax看feedforward效果,然后BP效果,然后增加單層單個(gè)neuron unit看效果;增加一層多個(gè);增加bias。。。。。直到構(gòu)建出最終的樣子,系統(tǒng)化的檢測每一步!
參數(shù)初始化也是重要滴!其主要考慮點(diǎn)在于你的激活函數(shù)的取值范圍和梯度較大的范圍!
隱層的bias一般初始化為0就可以;輸出層的bias可以考慮用reverse activation of mean targets或者mean targets(很直觀對不對) weights初始化一般較小的隨機(jī)數(shù),比如Uniform,Gaussion

更放心一點(diǎn),可視化每一層feedforward輸出的取值范圍,梯度范圍,通過修改使其落入激活函數(shù)的中間區(qū)域范圍(梯度類似線性);如果是ReLU則保證不要輸出大多為負(fù)數(shù)就好,可以給bias一點(diǎn)正直的噪聲等。當(dāng)然還有一點(diǎn)就是不能讓神經(jīng)元輸出一樣,原因很簡單
優(yōu)化算法,一般用mini-batch SGD,絕對不要用full batch gradient(慢)。一般情況下,大數(shù)據(jù)集用2nd order batch method比如L-BFGS較好,但是會(huì)有大量額外計(jì)算2nd過程;小數(shù)據(jù)集,L-BFGS或共軛梯度較好。(Large-batch L-BFGS extends the reach of L-BFGSLe et al. ICML 2001)

學(xué)習(xí)率,跑過神經(jīng)網(wǎng)絡(luò)的都知道這個(gè)影響還蠻大。一般就是要么選用固定的lr,要么隨著訓(xùn)練讓lr逐步變小
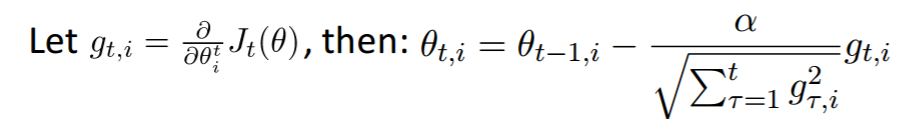
看看你的模型有沒有能力過擬合!(training error vs. validation error)
最后,可以看到一個(gè)網(wǎng)絡(luò)那么多的超參數(shù),怎么去選這些超參數(shù)呢?文章也說了:Random hyperparameter search!
以上提的多是supervised learning,對于unsupervised learning可以做fine tuning
標(biāo)準(zhǔn)化(Normalization)
scale控制特征的重要性:大scale的output特征產(chǎn)生更大的error;大的scale的input的特征可以主導(dǎo)網(wǎng)絡(luò)對此特征更敏感,產(chǎn)生大的update
一些特征本來取值范圍很小需要格外注意,避免產(chǎn)生NaNs
就算沒有標(biāo)準(zhǔn)化你的網(wǎng)絡(luò)可以訓(xùn)練的話,那可能前幾層也是做類似的事情,無形增加了網(wǎng)絡(luò)的復(fù)雜程度
通常都是把所有inputs的特征獨(dú)立地按同樣的規(guī)則標(biāo)準(zhǔn)化,如果對任務(wù)有特殊需求,某些特征可以特別對待
檢查結(jié)果(Results Check)
需要注意的是,你需要理解你設(shè)定的error的意義,就算訓(xùn)練過程error在不斷減少,也需要來和真實(shí)的error比較,雖然training error減少了,但是可能還不夠,真實(shí)世界中需要更小的error,說明模型學(xué)習(xí)的還不夠
當(dāng)在training過程中work后,再去看在validation集上的效果
再更新網(wǎng)絡(luò)結(jié)構(gòu)前,最好確保每一個(gè)環(huán)節(jié)都有“監(jiān)控”,不要盲目做無用功
預(yù)處理(Pre-Processing Data)
神經(jīng)網(wǎng)絡(luò)假設(shè)數(shù)據(jù)的分布空間是連續(xù)的
減少數(shù)據(jù)表示多樣性帶來的誤差;間接減少了網(wǎng)絡(luò)前幾層做沒必要的“等同”映射帶來的復(fù)雜度
正則化(Regularization)
一方面緩解過擬合,另一方面引入的隨機(jī)性,可以平緩訓(xùn)練過程,加速訓(xùn)練過程,處理outliers
Dropout可以看做ensemble,特征采樣,相當(dāng)于bagging很多子網(wǎng)絡(luò);訓(xùn)練過程中動(dòng)態(tài)擴(kuò)展擁有類似variation的輸入數(shù)據(jù)集。(在單層網(wǎng)絡(luò)中,類似折中Naiive bayes(所有特征權(quán)重獨(dú)立)和logistic regression(所有特征之間有關(guān)系);
一般對于越復(fù)雜的大規(guī)模網(wǎng)絡(luò),Dropout效果越好,是一個(gè)強(qiáng)regularizer!
最好的防止over-fitting就是有大量不重復(fù)數(shù)據(jù)
Batch Size太大
如果可以容忍訓(xùn)練時(shí)間過長,最好開始使用盡量小的batch size(16,8,1)
大的batch size需要更多的epoch來達(dá)到較好的水平
原因1:幫助訓(xùn)練過程中跳出local minima
原因2:使訓(xùn)練進(jìn)入較為平緩的local minima,提高泛化性
一般數(shù)據(jù)中的outliers會(huì)產(chǎn)生大的error,進(jìn)而大的gradient,得到大的weight update,會(huì)使最優(yōu)的lr比較難找
預(yù)處理好數(shù)據(jù)(去除outliers),lr設(shè)定好一般無需clipping
如果error explode,那么加gradient clipping只是暫時(shí)緩解,原因還是數(shù)據(jù)有問題
需要仔細(xì)考慮輸入是什么,標(biāo)準(zhǔn)化之后的輸出的取值范圍,如果輸出有正有負(fù),你用ReLU,sigmoid明顯不行;多分類任務(wù)一般用softmax(相當(dāng)于對輸出歸一化為概率分布)
激活只是一個(gè)映射,理論上都可以
如果輸出沒有error明顯也不行,那就沒有g(shù)radient,模型也學(xué)不到什么
一般用tanh,產(chǎn)生一個(gè)問題就是梯度在-1或1附近非常小,神經(jīng)元飽和學(xué)習(xí)很慢,容易產(chǎn)生梯度消息,模型產(chǎn)生更多接近-1或1的值
Bad Gradient(Dead Neurons)
當(dāng)發(fā)現(xiàn)模型隨著epoch進(jìn)行,訓(xùn)練error不變化,可能所以神經(jīng)元都“死”了。這時(shí)嘗試更換激活函數(shù)如leaky ReLU,ELU,再看訓(xùn)練error變化
使用ReLU時(shí)需要給參數(shù)加一點(diǎn)噪聲,打破完全對稱避免0梯度,甚至給biases加噪聲
相對而言對于sigmoid,因?yàn)槠湓?值附近最敏感,梯度最大,初始化全為0就可以啦
任何關(guān)于梯度的操作,比如clipping, rounding, max/min都可能產(chǎn)生類似的問題
ReLU相對Sigmoid優(yōu)點(diǎn):單側(cè)抑制;寬闊的興奮邊界;稀疏激活性;解決梯度消失
太小:信號(hào)傳遞逐漸縮小難以產(chǎn)生作用
太大:信號(hào)傳遞逐漸放大導(dǎo)致發(fā)散和失效
比較流行的有 'he', 'lecun', 'Xavier'(讓權(quán)重滿足0均值,2/(輸入節(jié)點(diǎn)數(shù)+輸出節(jié)點(diǎn)數(shù)))
biases一般初始化為0就可以
每一層初始化都很重要
開始一般用3-8層,當(dāng)效果不錯(cuò)時(shí),為了得到更高的準(zhǔn)確率,再嘗試加深網(wǎng)絡(luò)
所以的優(yōu)化方法在淺層也有用,如果效果不好,絕對不是深度不夠
訓(xùn)練和預(yù)測過程隨著網(wǎng)絡(luò)加深變慢
Hidden neurons的數(shù)量
太多:訓(xùn)練慢,難去除噪聲(over-fitting)
考慮真實(shí)變量有多少信息量需要傳遞,然后再稍微增加一點(diǎn)(考慮dropout;冗余表達(dá);估計(jì)的余地)
分類任務(wù):初始嘗試5-10倍類別個(gè)數(shù)
回歸任務(wù):初始嘗試2-3倍輸入/輸出特征數(shù)
這里直覺很重要
最終影響其實(shí)不大,只是訓(xùn)練過程比較慢,多嘗試
loss function
多分類一般用softmax,在小于0范圍內(nèi)梯度很小,加一個(gè)log可以改善此問題
避免MSE導(dǎo)致的學(xué)習(xí)速率下降,學(xué)習(xí)速率受輸出誤差控制(自己推一下就知道了)
AE降維
SGD
也可采用自適應(yīng)的算法,Adam,Adagrad,Adadelta等減輕調(diào)參負(fù)擔(dān)(一般使用默認(rèn)值就可以)
對于SGD需要對學(xué)習(xí)率,Momentum,Nesterov等進(jìn)行復(fù)雜調(diào)參
值得一提是神經(jīng)網(wǎng)絡(luò)很多局部最優(yōu)解都可能達(dá)到較好的效果,而全局最優(yōu)解反而是容易過擬合的解
CNN其優(yōu)越的性能十分值得使用,參數(shù)數(shù)量只和卷積核大小,數(shù)量有關(guān),保證隱含節(jié)點(diǎn)數(shù)量(與卷積步長相關(guān))的同時(shí),大量降低了參數(shù)的數(shù)量!當(dāng)然CNN更多用于圖像,其他任務(wù)靠你自己抽象啦,多多嘗試!
這里簡單介紹一些CNN的trick
pooling或卷積尺寸和步長不一樣,增加數(shù)據(jù)多樣性
data augumentation,避免過擬合,提高泛化,加噪聲擾動(dòng)
weight regularization
SGD使用decay的訓(xùn)練方法
最后使用pooling(avgpooling)代替全連接,減少參數(shù)量
maxpooling代替avgpooling,避免avgpooling帶來的模糊化效果
2個(gè)3x3代替一個(gè)5x5等,減少參數(shù),增加非線性映射,使CNN對特征學(xué)習(xí)能力強(qiáng)
3x3,2x2窗口
預(yù)訓(xùn)練方法等
數(shù)據(jù)預(yù)處理后(PCA,ZCA)喂給模型
輸出結(jié)果窗口ensemble
中間節(jié)點(diǎn)作為輔助輸出節(jié)點(diǎn),相當(dāng)于模型融合,同時(shí)增加反向傳播的梯度信號(hào),提供了額外的正則化
1x1卷積,夸通道組織信息,提高網(wǎng)絡(luò)表達(dá),可對輸出降維,低成本,性價(jià)比高,增加非線性映射,符合Hebbian原理
NIN增加網(wǎng)絡(luò)對不同尺度的適應(yīng)性,類似Multi-Scale思想
Factorization into small convolution,7x7用1x7和7x1代替,節(jié)約參數(shù),增加非線性映射
BN減少Internal Covariance Shift問題,提高學(xué)習(xí)速度,減少過擬合,可以取消dropout,增大學(xué)習(xí)率,減輕正則,減少光學(xué)畸變的數(shù)據(jù)增強(qiáng)
模型遇到退化問題考慮shortcut結(jié)構(gòu),增加深度
等等
RNN使用
小的細(xì)節(jié)和其他很像,簡單說兩句個(gè)人感覺的其他方面吧,其實(shí)RNN也是shortcut結(jié)構(gòu)
一般用LSTM結(jié)構(gòu)防止BPTT的梯度消失,GRU擁有更少的參數(shù),可以優(yōu)先考慮
預(yù)處理細(xì)節(jié),padding,序列長度設(shè)定,罕見詞語處理等
一般語言模型的數(shù)據(jù)量一定要非常大
Gradient Clipping
Seq2Seq結(jié)構(gòu)考慮attention,前提數(shù)據(jù)量大
序列模型考率性能優(yōu)良的CNN+gate結(jié)構(gòu)
一般生成模型可以參考GAN,VAE,產(chǎn)生隨機(jī)變量
RL的框架結(jié)合
數(shù)據(jù)量少考慮簡單的MLP
預(yù)測采用層級(jí)結(jié)構(gòu)降低訓(xùn)練復(fù)雜度
設(shè)計(jì)采樣方法,增加模型收斂速度
增加多級(jí)shortcut結(jié)構(gòu)
好消息!
小白學(xué)視覺知識(shí)星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會(huì)逐漸細(xì)分),請掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會(huì)請出群,謝謝理解~