
終于有人把數(shù)據(jù)湖講明白了


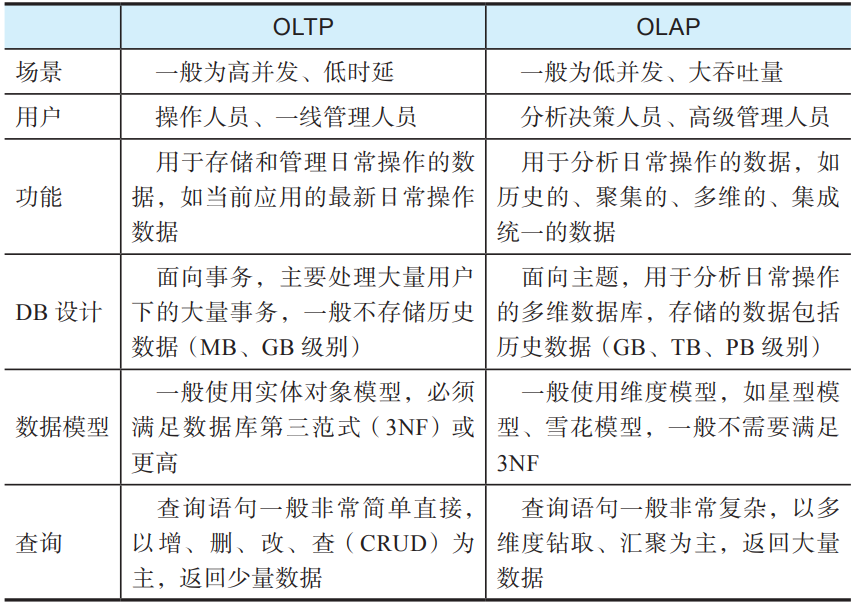
數(shù)據(jù)倉庫的架構(gòu)設(shè)計是事先定好的,很難做到全面覆蓋,因此基于數(shù)據(jù)倉庫的分析是受到事先定義的分析目標(biāo)及數(shù)據(jù)庫Schema限制的; 從OLTP的實時狀態(tài)到OLAP的分析數(shù)據(jù)的轉(zhuǎn)換中會有不少信息損失,例如某個賬戶在某個具體時間點的余額,在OLTP系統(tǒng)里一般只存儲最新的值,在OLAP系統(tǒng)里只會存儲對賬戶操作的交易,一般不會專門存儲歷史余額,這就使得進(jìn)行基于歷史余額的分析非常困難。

高效采集和存儲盡可能多的數(shù)據(jù)。將盡可能多的有用數(shù)據(jù)存放在數(shù)據(jù)湖中,為后續(xù)的數(shù)據(jù)分析和業(yè)務(wù)迭代做準(zhǔn)備。一般來說,這里的“有用數(shù)據(jù)”就是指能夠提高業(yè)務(wù)還原度的數(shù)據(jù)。 對數(shù)據(jù)倉庫的支持。數(shù)據(jù)湖可以看作數(shù)據(jù)倉庫的主要數(shù)據(jù)來源。業(yè)務(wù)用戶需要高性能的數(shù)據(jù)湖來對PB級數(shù)據(jù)運行復(fù)雜的SQL查詢,以返回復(fù)雜的分析輸出。 數(shù)據(jù)探索、發(fā)現(xiàn)和共享。允許高效、自由、基于數(shù)據(jù)湖的數(shù)據(jù)探索、發(fā)現(xiàn)和共享。在很多情況下,數(shù)據(jù)工程師和數(shù)據(jù)分析師需要運行SQL查詢來分析海量數(shù)據(jù)湖數(shù)據(jù)。諸如Hive、Presto、Impala之類的工具使用數(shù)據(jù)目錄來構(gòu)建友好的SQL邏輯架構(gòu),以查詢存儲在選定格式文件中的基礎(chǔ)數(shù)據(jù)。這允許直接在數(shù)據(jù)文件中查詢結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。 機(jī)器學(xué)習(xí)。數(shù)據(jù)科學(xué)家通常需要對龐大的數(shù)據(jù)集運行機(jī)器學(xué)習(xí)算法以進(jìn)行預(yù)測。數(shù)據(jù)湖提供對企業(yè)范圍數(shù)據(jù)的訪問,以便于用戶通過探索和挖掘數(shù)據(jù)來獲取業(yè)務(wù)洞見。
數(shù)據(jù)源的全面性:數(shù)據(jù)湖應(yīng)該能夠從任何來源高速、高效地收集數(shù)據(jù),幫助執(zhí)行完整而深入的數(shù)據(jù)分析。 數(shù)據(jù)可訪問性:以安全授權(quán)的方式支持組織/部門范圍內(nèi)的數(shù)據(jù)訪問,包括數(shù)據(jù)專業(yè)人員和企業(yè)等的訪問,而不受IT部門的束縛。 數(shù)據(jù)及時性和正確性:數(shù)據(jù)很重要,但前提是及時接收正確的數(shù)據(jù)。所有用戶都有一個有效的時間窗口,在此期間正確的信息會影響他們的決策。 工具的多樣性:借助組織范圍的數(shù)據(jù),數(shù)據(jù)湖應(yīng)使用戶能夠使用所需的工具集構(gòu)建其報告和模型。

傳統(tǒng)數(shù)據(jù)庫數(shù)據(jù)采集:數(shù)據(jù)庫采集是通過Sqoop或DataX等采集工具,將數(shù)據(jù)庫中的數(shù)據(jù)上傳到Hadoop的分布式文件系統(tǒng)中,并創(chuàng)建對應(yīng)的Hive表的過程。數(shù)據(jù)庫采集分為全量采集和增量采集,全量采集是一次性將某個源表中的數(shù)據(jù)全部采集過來,增量采集是定時從源表中采集新數(shù)據(jù)。 Kafka實時數(shù)據(jù)采集:Web服務(wù)的數(shù)據(jù)常常會寫入Kafka,通過Kafka快速高效地傳輸?shù)紿adoop中。由Confluent開源的Kafka Connect架構(gòu)能很方便地支持將Kafka中的數(shù)據(jù)傳輸?shù)紿ive表中。 日志文件采集:對于日志文件,通常會采用Flume或Logstash來采集。 爬蟲程序采集:很多網(wǎng)頁數(shù)據(jù)需要編寫爬蟲程序模擬登錄并進(jìn)行頁面分析來獲取。 Web Service數(shù)據(jù)采集:有的數(shù)據(jù)提供商會提供基于HTTP的數(shù)據(jù)接口,用戶需要編寫程序來訪問這些接口以持續(xù)獲取數(shù)據(jù)。
HDFS:一般用來存儲日志數(shù)據(jù)和作為通用文件系統(tǒng)。 Hive:一般用來存儲ODS和導(dǎo)入的關(guān)系型數(shù)據(jù)。 鍵-值存儲(Key-value Store):例如Cassandra、HBase、ClickHouse等,適合對性能和可擴(kuò)展性有要求的加載和查詢場景,如物聯(lián)網(wǎng)、用戶推薦和個性化引擎等。 文檔數(shù)據(jù)庫(Document Store):例如MongoDB、Couchbase等,適合對數(shù)據(jù)存儲有擴(kuò)展性要求的場景,如處理游戲賬號、票務(wù)及實時天氣警報等。 圖數(shù)據(jù)庫(Graph Store):例如Neo4j、JanusGraph等,用于在處理大型數(shù)據(jù)集時建立數(shù)據(jù)關(guān)系并提供快速查詢,如進(jìn)行相關(guān)商品的推薦和促銷,建立社交圖譜以增強(qiáng)內(nèi)容個性化等。 對象存儲(Object Store):例如Ceph、Amazon S3等,適合更新變動較少的對象文件數(shù)據(jù)、沒有目錄結(jié)構(gòu)的文件和不能直接打開或修改的文件,如圖片存儲、視頻存儲等。


關(guān)于作者:彭鋒,智領(lǐng)云科技聯(lián)合創(chuàng)始人兼CEO。武漢大學(xué)計算機(jī)系本科及碩士,美國馬里蘭大學(xué)計算機(jī)專業(yè)博士,主要研究方向是流式半結(jié)構(gòu)化數(shù)據(jù)的高性能查詢引擎,在數(shù)據(jù)庫頂級會議和期刊SIGMOD、ICDE、TODS上發(fā)表多篇開創(chuàng)性論文。2011年加入Twitter,任大數(shù)據(jù)平臺主任工程師、公司架構(gòu)師委員會大數(shù)據(jù)負(fù)責(zé)人,負(fù)責(zé)公司大數(shù)據(jù)平臺及流水線的建設(shè)和管理。
宋文欣,智領(lǐng)云科技聯(lián)合創(chuàng)始人兼CTO。武漢大學(xué)計算機(jī)系本科及碩士,美國紐約州立大學(xué)石溪分校計算機(jī)專業(yè)博士。曾先后就職于Ask.com和EA(電子藝界)。2016年回國聯(lián)合創(chuàng)立智領(lǐng)云科技有限公司,組建智領(lǐng)云技術(shù)團(tuán)隊,開發(fā)了BDOS大數(shù)據(jù)平臺操作系統(tǒng)。
孫浩峰,智領(lǐng)云科技市場總監(jiān)。前CSDN內(nèi)容運營副總編,關(guān)注云計算、大數(shù)據(jù)、人工智能、區(qū)塊鏈等技術(shù)領(lǐng)域,對云計算、網(wǎng)絡(luò)技術(shù)、網(wǎng)絡(luò)存儲有深刻認(rèn)識。擁有豐富的媒體從業(yè)經(jīng)驗和專業(yè)的網(wǎng)絡(luò)安全技術(shù)功底,具有超過15年的企業(yè)級IT市場傳播、推廣、宣傳和寫作經(jīng)驗,撰寫過多篇在業(yè)界具有一定影響力的文章。
本文摘編自《云原生數(shù)據(jù)中臺:架構(gòu)、方法論與實踐》,經(jīng)出版方授權(quán)發(fā)布。

