
SQL 進階技巧(下)
點擊關注上方“SQL數(shù)據(jù)庫開發(fā)”,
設為“置頂或星標”,第一時間送達干貨
上文我們簡述了 SQL 的一些進階技巧,一些朋友覺得不過癮,我們繼續(xù)來下篇,再送你 10 個技巧
一、 使用延遲查詢優(yōu)化 limit [offset], [rows]
經(jīng)常出現(xiàn)類似以下的 SQL 語句:
SELECT?*?FROM?film?LIMIT?100000,?10
offset 特別大!
這是我司出現(xiàn)很多慢 SQL 的主要原因之一,尤其是在跑任務需要分頁執(zhí)行時,經(jīng)常跑著跑著 offset 就跑到幾十萬了,導致任務越跑越慢。
LIMIT 能很好地解決分頁問題,但如果 offset 過大的話,會造成嚴重的性能問題,原因主要是因為 MySQL 每次會把一整行都掃描出來,掃描 offset 遍,找到 offset 之后會拋棄 offset 之前的數(shù)據(jù),再從 offset 開始讀取 10 條數(shù)據(jù),顯然,這樣的讀取方式問題。
可以通過延遲查詢的方式來優(yōu)化
假設有以下 SQL,有組合索引(sex, rating)
SELECT??FROM?profiles?where?sex='M'?order?by?rating?limit?100000,?10;
則上述寫法可以改成如下寫法
SELECT??
??FROM?profiles?
inner?join
(SELECT?id?form?FROM?profiles?where?x.sex='M'?order?by?rating?limit?100000,?10)
as?x?using(id);
這里利用了覆蓋索引的特性,先從覆蓋索引中獲取 100010 個 id,再丟充掉前 100000 條 id,保留最后 10 個 id 即可,丟掉 100000 條 id 不是什么大的開銷,所以這樣可以顯著提升性能
二、 利用 LIMIT 1 取得唯一行
數(shù)據(jù)庫引擎只要發(fā)現(xiàn)滿足條件的一行數(shù)據(jù)則立即停止掃描,,這種情況適用于只需查找一條滿足條件的數(shù)據(jù)的情況
三、 注意組合索引,要符合最左匹配原則才能生效
假設存在這樣順序的一個聯(lián)合索引“col_1, col_2, col_3”。這時,指定條件的順序就很重要。
○?SELECT?*?FROM?SomeTable?WHERE?col_1?=?10?AND?col_2?=?100?AND?col_3?=?500;
○?SELECT?*?FROM?SomeTable?WHERE?col_1?=?10?AND?col_2?=?100?;
×?SELECT?*?FROM?SomeTable?WHERE?col_2?=?100?AND?col_3?=?500?;
前面兩條會命中索引,第三條由于沒有先匹配 col_1,導致無法命中索引, 另外如果無法保證查詢條件里列的順序與索引一致,可以考慮將聯(lián)合索引 拆分為多個索引。
四、使用 LIKE 謂詞時,只有前方一致的匹配才能用到索引(最左匹配原則)
×?SELECT?*?FROM?SomeTable?WHERE?col_1?LIKE?'%a';
×?SELECT?*?FROM?SomeTable?WHERE?col_1?LIKE?'%a%';
○?SELECT?*?FROM?SomeTable?WHERE?col_1?LIKE?'a%';
上例中,只有第三條會命中索引,前面兩條進行后方一致或中間一致的匹配無法命中索引
五、 簡單字符串表達式
模型字符串可以使用 _ 時, 盡可能避免使用 %, 假設某一列上為 char(5)
不推薦
SELECT?
????first_name,?
????last_name,
????homeroom_nbr
??FROM?Students
?WHERE?homeroom_nbr?LIKE?'A-1%';
推薦
SELECT?first_name,?last_name
homeroom_nbr
??FROM?Students
?WHERE?homeroom_nbr?LIKE?'A-1__';?--模式字符串中包含了兩個下劃線
六、盡量使用自增 id 作為主鍵
比如現(xiàn)在有一個用戶表,有人說身份證是唯一的,也可以用作主鍵,理論上確實可以,不過用身份證作主鍵的話,一是占用空間相對于自增主鍵大了很多,二是很容易引起頻繁的頁分裂,造成性能問題(什么是頁分裂,請參考這篇文章)
主鍵選擇的幾個原則:自增,盡量小,不要對主鍵進行修改
七、在無 WHERE 條件下要計算表的行數(shù),優(yōu)先使用?count(*)
優(yōu)先使用以下語句來統(tǒng)計行數(shù), innoDB?5.6之后已經(jīng)對此語句進行了優(yōu)化
SELECT?COUNT(*)?FROM?SomeTable
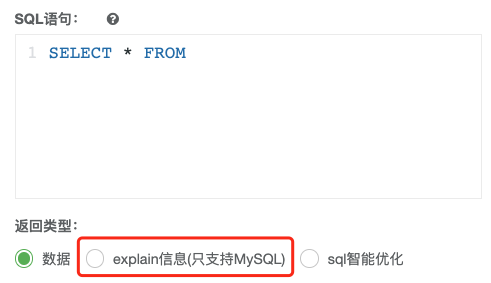
按照效率排序的話,count(字段) 八、避免使用 SELECT * ,盡量利用覆蓋索引來優(yōu)化性能 SELECT * 會提取出一整行的數(shù)據(jù),如果查詢條件中用的是組合索引進行查找,還會導致回表(先根據(jù)組合索引找到葉子節(jié)點,再根據(jù)葉子節(jié)點上的主鍵回表查詢一整行),降低性能,而如果我們所要的數(shù)據(jù)就在組合索引里,只需讀取組合索引列,這樣網(wǎng)絡帶寬將大大減少,假設有組合索引列 (col_1, col_2) 推薦用 不推薦用 九、 如有必要,使用 force index() 強制走某個索引 業(yè)務團隊曾經(jīng)出現(xiàn)類似以下的慢 SQL 查詢 post_id 也加了索引,理論上走 post_id 索引會很快查詢出來,但實現(xiàn)了通過 EXPLAIN 發(fā)現(xiàn)走的卻是 id 的索引(這里隱含了一個常見考點,在多個索引的情況下, MySQL 會如何選擇索引),而 id > 0 這個查詢條件沒啥用,直接導致了全表掃描, 所以在有多個索引的情況下一定要慎用,可以使用 force index 來強制走某個索引,以這個例子為例,可以強制走 post_id 索引,效果立桿見影。 這種由于表中有多個索引導致 MySQL 誤選索引造成慢查詢的情況在業(yè)務中也是非常常見,一方面是表索引太多,另一方面也是由于 SQL 語句本身太過復雜導致, 針對本例這種復雜的 SQL 查詢,其實用 ElasticSearch 搜索引擎來查找更合適,有機會到時出一篇文章說說。 十、 使用 EXPLAIN 來查看 SQL 執(zhí)行計劃 上個點說了,可以使用 EXPLAIN 來分析 SQL 的執(zhí)行情況,如怎么發(fā)現(xiàn)上文中的最左匹配原則不生效呢,執(zhí)行 「EXPLAIN + SQL 語句」可以發(fā)現(xiàn) key 為 None ,說明確實沒有命中索引 我司在提供 SQL 查詢的同時,也貼心地加了一個 EXPLAIN 功能及 sql 的優(yōu)化建議,建議各大公司效仿 ^_^,如圖示 十一、 批量插入,速度更快 當需要插入數(shù)據(jù)時,批量插入比逐條插入性能更高 推薦用 不推薦用 批量插入 SQL 執(zhí)行效率高的主要原因是合并后日志量 MySQL 的 binlog 和 innodb 的事務讓日志減少了,降低日志刷盤的數(shù)據(jù)量和頻率,從而提高了效率 十二、 慢日志 SQL 定位 前面我們多次說了 SQL 的慢查詢,那么該怎么定位這些慢查詢 SQL 呢,主要用到了以下幾個參數(shù) 這幾個參數(shù)一定要配好,再根據(jù)每條慢查詢對癥下藥,像我司每天都會把這些慢查詢提取出來通過郵件給形式發(fā)送給各個業(yè)務團隊,以幫忙定位解決 業(yè)務生產(chǎn)中可能還有很多 CASE 導致了慢查詢,其實細細品一下,都會發(fā)現(xiàn)這些都和 MySQL 索引的底層數(shù)據(jù) B+ 樹 有莫大的關系,強烈建議大家看一下我的另一篇介紹 B+ 樹的文章,好評如潮!相信大家看了之后,以上出現(xiàn)的問題會有一個更深層次的理解,掌握底層,以不變應萬變! 巨人的肩膀 https://plu.one/mysql/2018/10/18/mysql-deffered-join/ https://blog.csdn.net/u012674931/article/details/52711137SELECT?col_1,?col_2?
??FROM?SomeTable?
?WHERE?col_1?=?xxx?AND?col_2?=?xxxSELECT?*
??FROM?SomeTable?
?WHERE?col_1?=?xxx?AND??col_2?=?xxxSELECT?*
??FROM??SomeTable
?WHERE?`status`?=?0
???AND?`gmt_create`?>?1490025600
???AND?`gmt_create`?1490630400
???AND?`id`?>?0
???AND?`post_id`?IN?('67778',?'67811',?'67833',?'67834',?'67839',?'67852',?'67861',?'67868',?'67870',?'67878',?'67909',?'67948',?'67951',?'67963',?'67977',?'67983',?'67985',?'67991',?'68032',?'68038'/*...?omitted?480?items?...*/)
order?by?id?asc?limit?200;
--?批量插入
INSERT?INTO?TABLE?(id,?user_id,?title)?VALUES?(1,?2,?'a'),(2,3,'b');INSERT?INTO?TABLE?(id,?user_id,?title)?VALUES?(1,?2,?'a');
INSERT?INTO?TABLE?(id,?user_id,?title)?VALUES?(2,3,'b');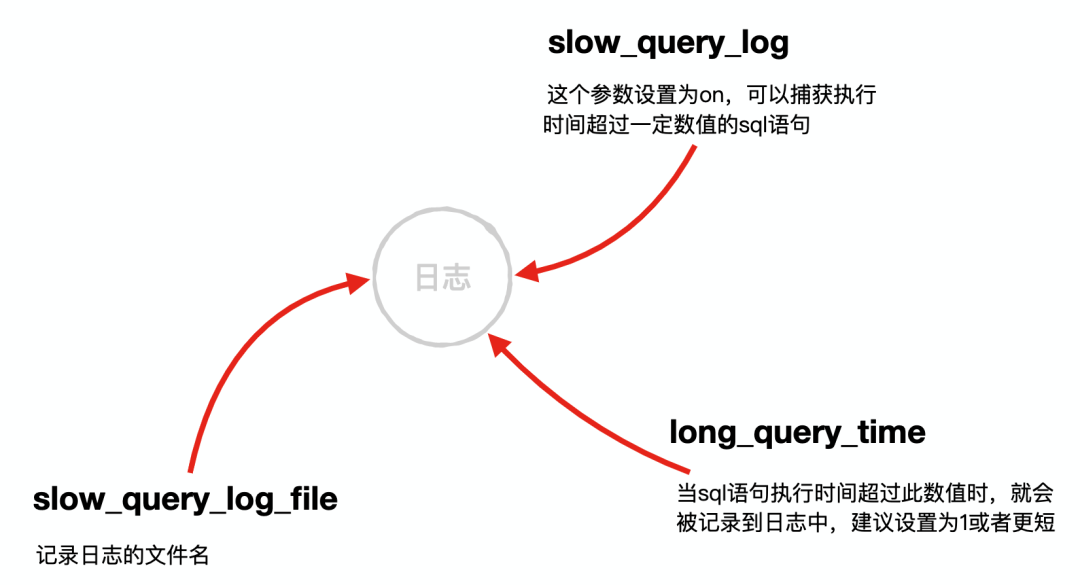
總結
我是岳哥,最后給大家分享我寫的SQL兩件套:《SQL基礎知識第二版》和《SQL高級知識第二版》的PDF電子版。里面有各個語法的解釋、大量的實例講解和批注等等,非常通俗易懂,方便大家跟著一起來實操。
有需要的讀者可以下載學習,在下面的公眾號「數(shù)據(jù)前線」(非本號)后臺回復關鍵字:SQL,就行
數(shù)據(jù)前線 ——End——
后臺回復關鍵字:1024,獲取一份精心整理的技術干貨
后臺回復關鍵字:進群,帶你進入高手如云的交流群。
推薦閱讀
