
【機(jī)器學(xué)習(xí)基礎(chǔ)】關(guān)于異常檢測的分享!

作者信息
知乎微調(diào):https://www.zhihu.com/people/breaknever

內(nèi)容概括
1.什么是異常檢測?
2.異常檢測有什么具體應(yīng)用?
3.異常檢測的工具概覽?如何用10行Python代碼進(jìn)行異常檢測?
4.異常檢測算法概覽與主流模型介紹
5.面對各種各樣的模型,如何選擇和調(diào)參?
6.未來的異常檢測研究方向
7.異常檢測相關(guān)的資源匯總(書籍、講座、代碼、數(shù)據(jù)等)
異常檢測
什么是異常值、離群點(diǎn)(anomaly)?
異常一般指的是與標(biāo)準(zhǔn)值(或期待值)有偏離的樣本,也就是說跟絕大部分?jǐn)?shù)據(jù)“長的不一樣”。
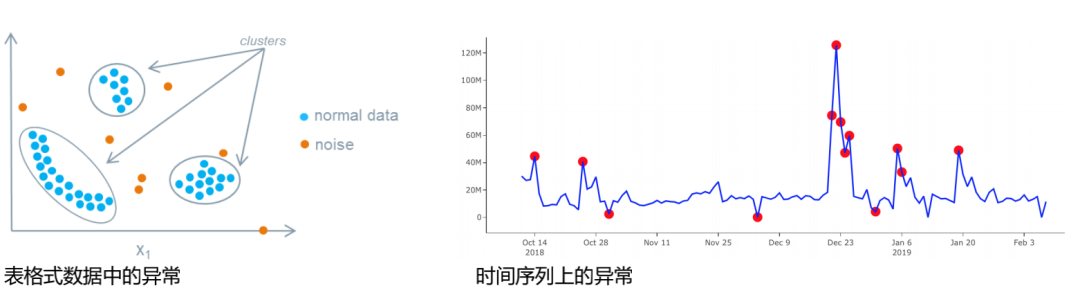
異常檢測的一些特點(diǎn):
1.異常不一定代表是“壞”的事情,但往往是“有價(jià)值”的事情,我們對異常的成因感興趣
2.異常檢測往往是在無監(jiān)督的模式下完成的—?dú)v史數(shù)據(jù)中沒有標(biāo)簽,我們不知道哪些數(shù)據(jù)是異常。因此無法用監(jiān)督學(xué)習(xí)去檢測。
異常檢測的應(yīng)用:
1.金融行業(yè)的反欺詐、信用卡詐騙檢測:把欺詐或者金融風(fēng)險(xiǎn)當(dāng)做異常
2.罕見病檢測:把罕見病當(dāng)做異常,比如檢測早發(fā)的阿茲海默癥
3.入侵檢測:把網(wǎng)絡(luò)流量中的入侵當(dāng)做異常
4.機(jī)器故障檢測:實(shí)時監(jiān)測發(fā)現(xiàn)或預(yù)測機(jī)械故障
5.圖結(jié)構(gòu)、群體檢測:比如檢測疫情的爆發(fā)點(diǎn)等
異常檢測的應(yīng)用
IntelControlFlag:
“基于10億條包含各種錯誤的未標(biāo)記生產(chǎn)質(zhì)量代碼的機(jī)器學(xué)習(xí)培訓(xùn),ControlFlag得以通過“異常檢測”技術(shù),對傳統(tǒng)編程模式展開篩查。無論使用的是哪種編程語言,它都能夠有效地識別代碼中可能導(dǎo)致任何錯誤的潛在異常。”
AmazonAWSCloudWatch:
“今天,我們將通過一項(xiàng)新功能增強(qiáng)CloudWatch,它將幫助您更有效地使用CloudWatch警報(bào)。…我們的用戶可以構(gòu)建自定義的控制面板,設(shè)置警報(bào)并依靠CloudWatch來提醒自己影響其應(yīng)用程序性能或可靠性的問題。”
Google:
“GoogleAnalytics(分析)會選擇一段時期的歷史數(shù)據(jù)來訓(xùn)練其預(yù)測模型。要檢測每天的異常情況,訓(xùn)練期為90天。要檢測每周的異常情況,訓(xùn)練期為32周。”
異常檢測的挑戰(zhàn)
1.大部分情況下是無監(jiān)督學(xué)習(xí),沒有標(biāo)簽信息可以使用
2.數(shù)據(jù)是極端不平衡的(異常點(diǎn)僅占總體數(shù)據(jù)的一小部分),建模難度大
3.檢測方法往往涉及到密度估計(jì),需要進(jìn)行大量的距離/相似度計(jì)算,運(yùn)算開銷大
4.在實(shí)際場景中往往需要實(shí)時檢測,這比離線檢測的技術(shù)難度更高
5.在實(shí)際場景中,我們常常需要同時處理很多案例,運(yùn)算開銷大
6.解釋性比較差,我們很難給出異常檢測的原因,尤其是在高維數(shù)據(jù)上。但業(yè)務(wù)方需要了解異常成因
7.在實(shí)際場景中,我們往往有一些檢測的歷史規(guī)則,如何與學(xué)習(xí)模型進(jìn)行整合
異常檢測工具
Python:
1.PyOD:超過30種算法,從經(jīng)典模型到深度學(xué)習(xí)模型一應(yīng)俱全,和sklearn的用法一致?
2.Scikit-Learn:包含了4種常見的算法,簡單易用
3.TODS:與PyOD類似,包含多種時間序列上的異常檢測算法
Java:
1.ELKI:EnvironmentforDevelopingKDD-ApplicationsSupportedbyIndex-Structures?
2.RapidMiner異常檢測擴(kuò)展
R:
1.outlierspackage
2.AnomalyDetection
用10行Python代實(shí)行異常檢測:

詳細(xì)介紹:https://zhuanlan.zhihu.com/p/58313521
異常檢測算法
異常檢測算法可以大致被分為:
1.線性模型(LinearModel):PCA
2.基于相似度的度量的算法(Proximity-basedModel):kNN,LOF,HBOS
3.基于概率的算法(ProbabilisticModel):COPOD
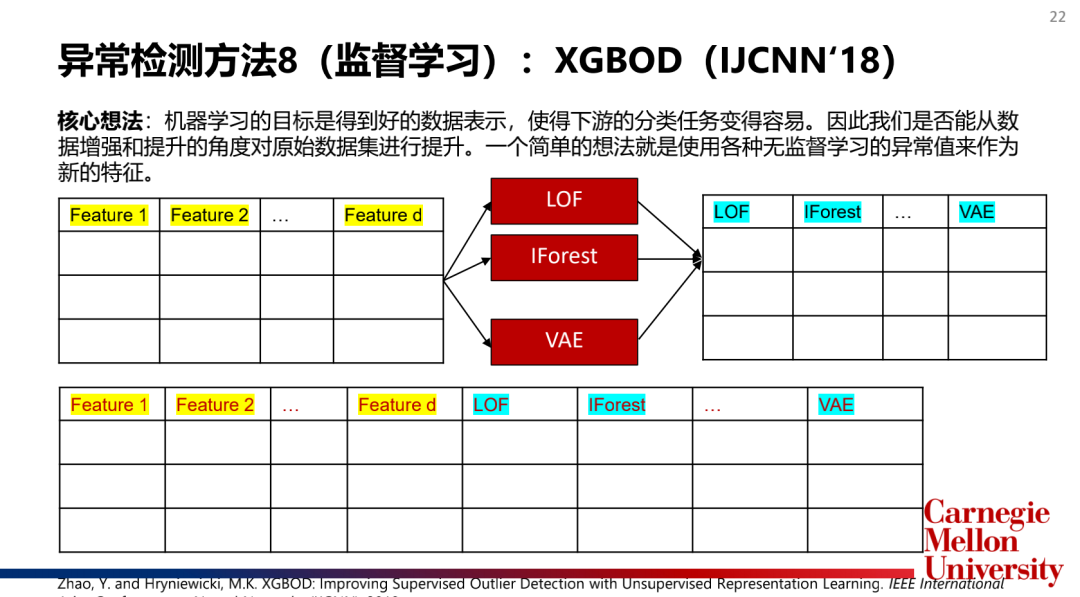
4.集成檢測算法(EnsembleModel):孤立森林(IsolationForest),XGBOD
5.神經(jīng)網(wǎng)絡(luò)算法(NeuralNetworks):自編碼器(AutoEncoder)
評估方法也不能簡單用準(zhǔn)確度(accuracy),因?yàn)閿?shù)據(jù)的極端不平衡
1.ROC-AUC曲線
2.Precision@Rankk:topk的精準(zhǔn)
3.AveragePrecision:平均精準(zhǔn)度
主流模型介紹:

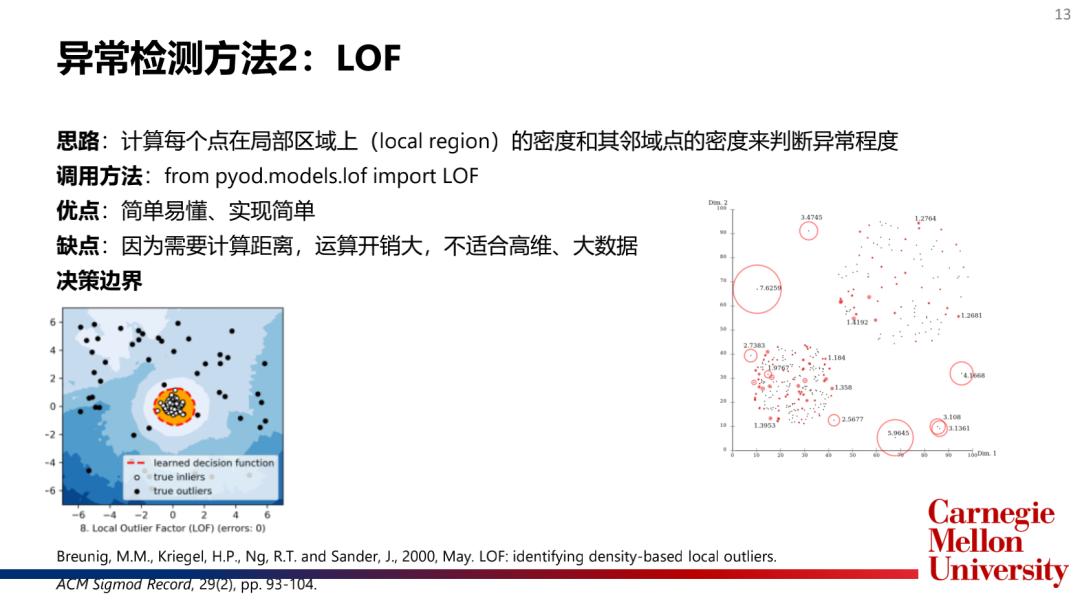
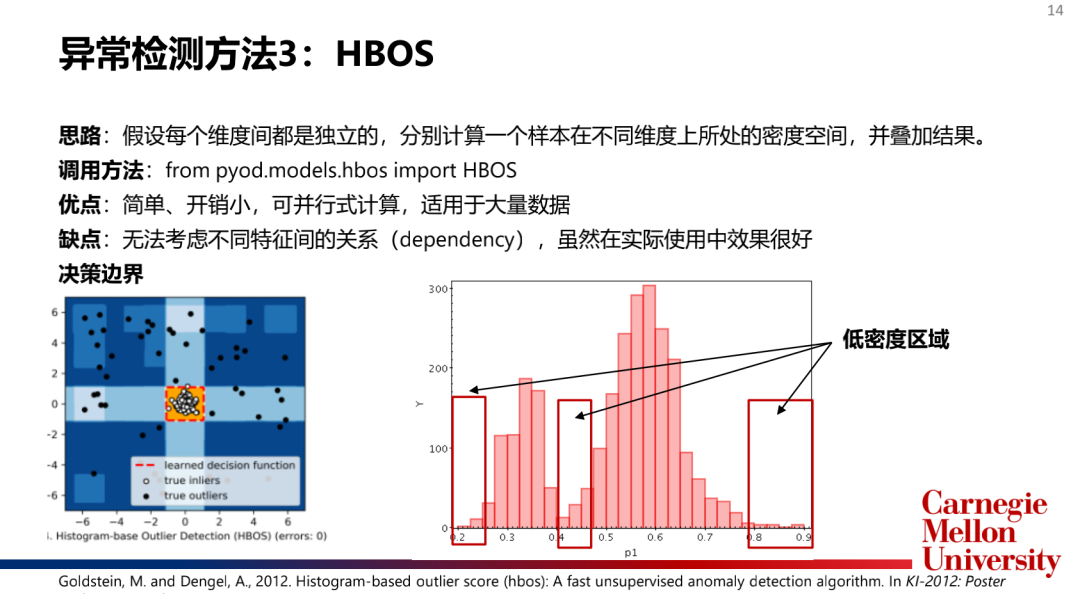
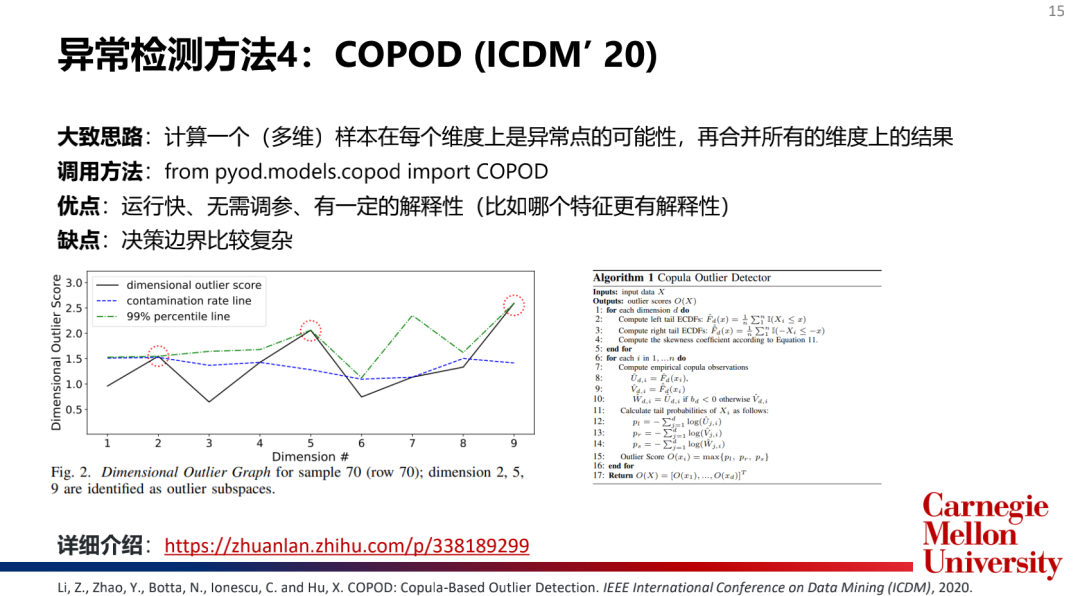
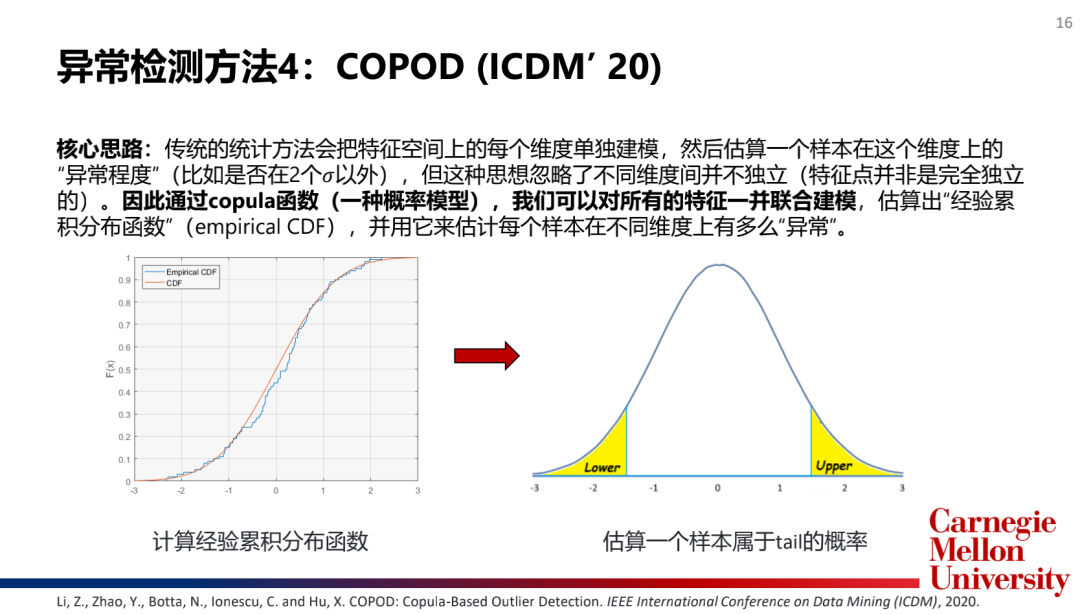

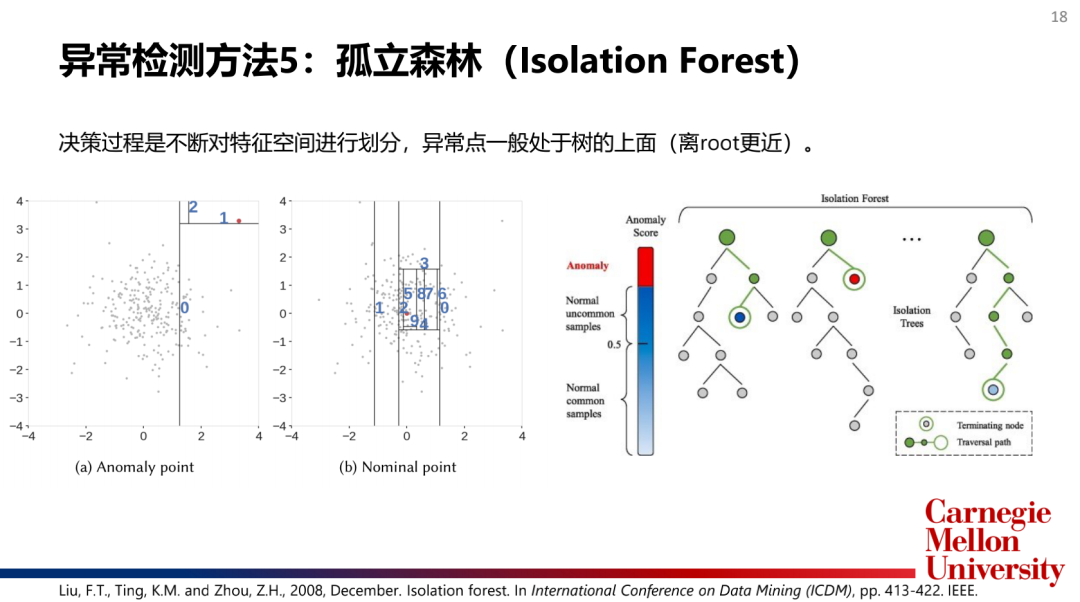

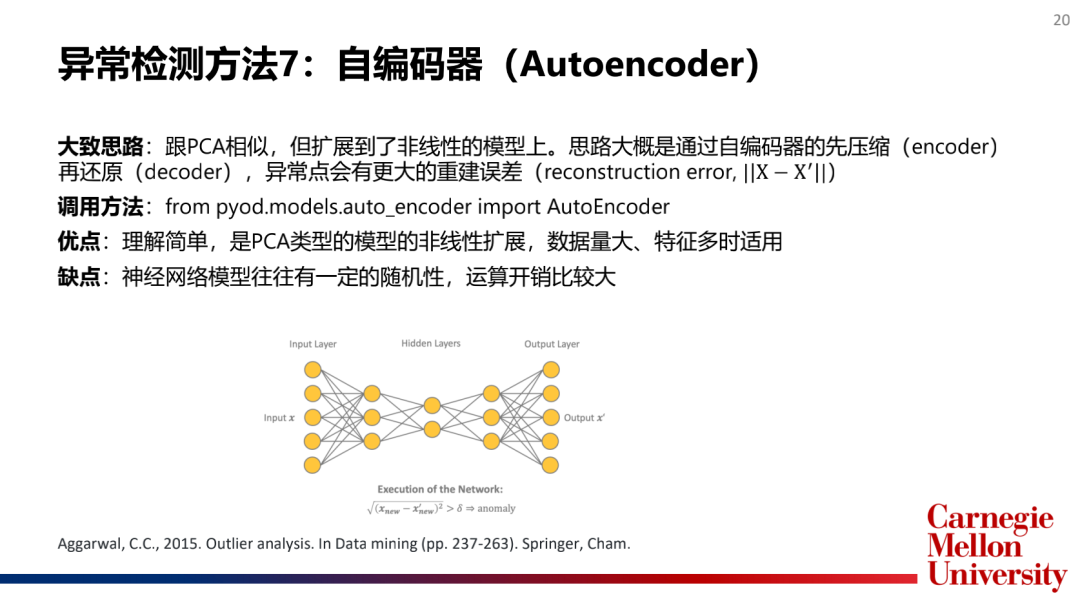
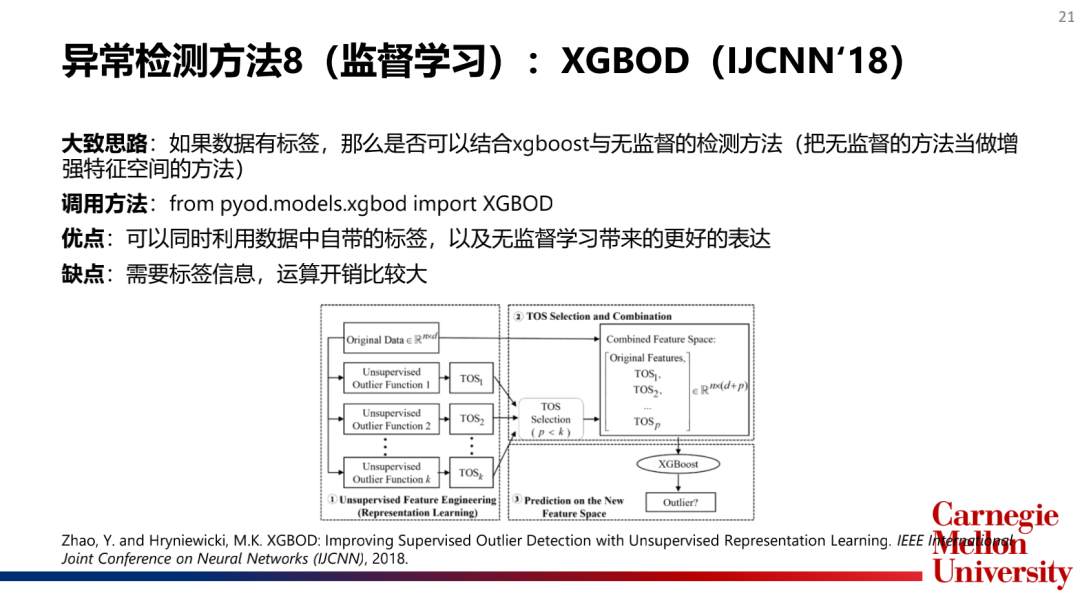
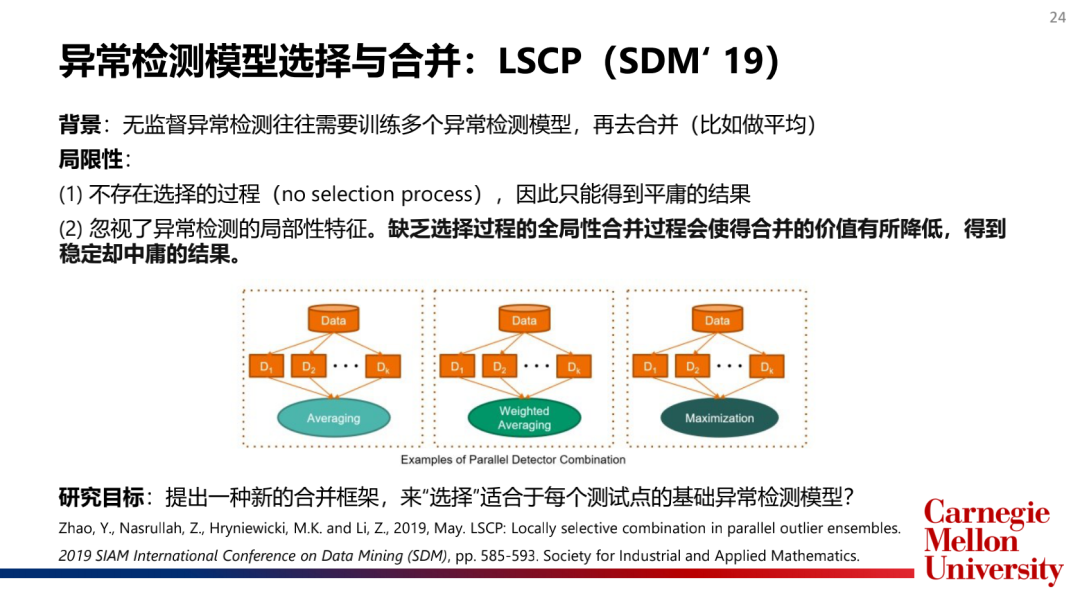
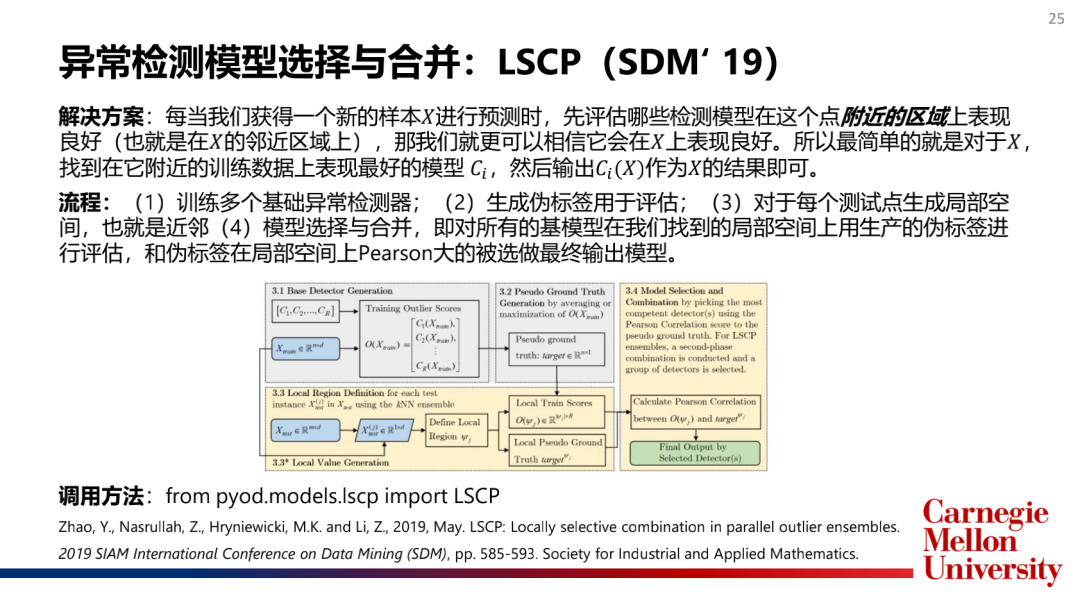
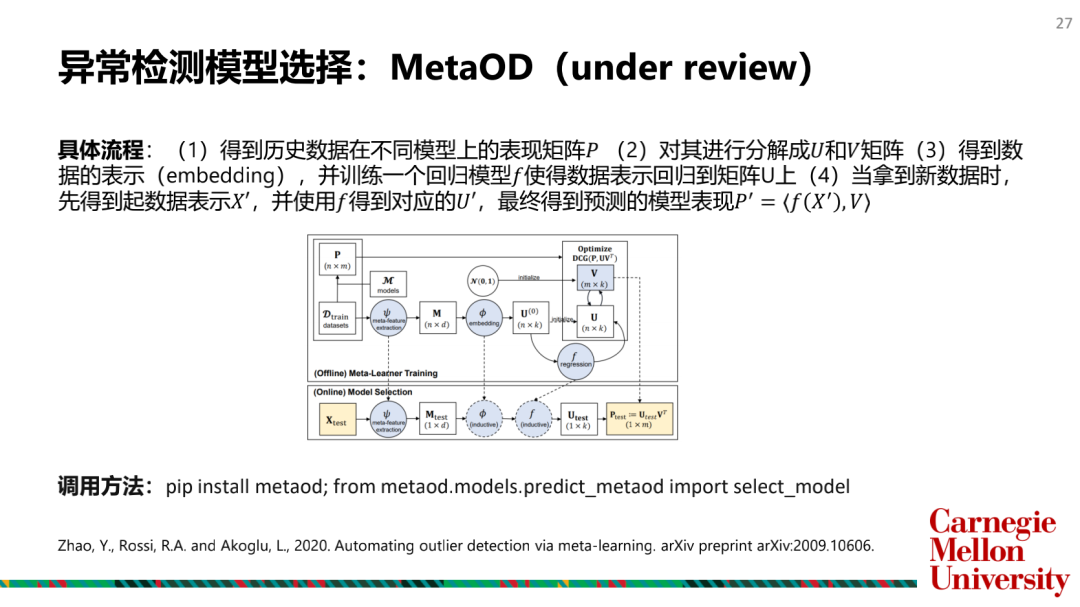
如何選擇和合并模型


異常檢測實(shí)踐中的技巧

異常檢測落地中的考量
1.不要嘗試一步到位用機(jī)器學(xué)習(xí)模型來代替?zhèn)鹘y(tǒng)模型
2.在理想情況下,應(yīng)該嘗試合并機(jī)器學(xué)習(xí)模型和基于規(guī)則的模型
3.可以嘗試用已有的規(guī)則模型去解釋異常檢測模型
異常檢測研究方向

本文視頻講解,PPT,趙越的異常檢測資源已匯總(書籍、講座、代碼、數(shù)據(jù)等)
第 1 步:掃碼關(guān)注「Datawhale」公眾號
第 2 步:回復(fù)關(guān)鍵詞?異常檢測?可獲取
往期精彩回顧
獲取本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群請掃碼: