
【機(jī)器學(xué)習(xí)】關(guān)于機(jī)器學(xué)習(xí)模型可解釋(XAI),再分享一招!
隨著時(shí)間的推移,學(xué)習(xí)模型變得越來(lái)越復(fù)雜,很難直觀地分析它們。人們經(jīng)常聽(tīng)說(shuō)機(jī)器學(xué)習(xí)模型是"黑匣子",從某種意義上說(shuō),它們可以做出很好的預(yù)測(cè),但我們無(wú)法理解這些預(yù)測(cè)背后的邏輯。這種說(shuō)法是正確的,因?yàn)榇蠖鄶?shù)數(shù)據(jù)科學(xué)家發(fā)現(xiàn)很難從模型中提取見(jiàn)解。然而,我們可以使用一些工具從復(fù)雜的機(jī)器學(xué)習(xí)模型中提取見(jiàn)解。
上一篇文章中我已分享了一篇文章:再見(jiàn)"黑匣子模型"!SHAP 可解釋 AI (XAI)實(shí)用指南來(lái)了!該篇文章主要介紹了關(guān)于回歸問(wèn)題的模型可解釋性。
本文是關(guān)于如何使用sklearn.tree.plot_tree ,來(lái)獲得模型可解釋性的方法說(shuō)明。決策樹(shù)本身就是一種可解釋的機(jī)器學(xué)習(xí)算法,廣泛應(yīng)用于線(xiàn)性和非線(xiàn)性模型的特征重要性。它是一個(gè)相對(duì)簡(jiǎn)單的模型,通過(guò)可視化樹(shù)很容易解釋。
import numpy as np
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pylab as plt
from sklearn import datasets, ensemble, model_selection
from sklearn.ensemble import RandomForestClassifier
在此示例中,我們將使用來(lái)自 sklearn 數(shù)據(jù)集的乳腺癌示例。這是一個(gè)簡(jiǎn)單的二進(jìn)制(惡性,良性)分類(lèi)問(wèn)題,從乳腺腫塊的細(xì)針抽吸(FNA)的數(shù)字化圖像計(jì)算特征,它們描述了圖像中細(xì)胞核的特征。
# import data and split
cancer = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = model_selection.train_test_split(cancer.data, cancer.target, random_state=0)
拆分?jǐn)?shù)據(jù)集進(jìn)行訓(xùn)練和測(cè)試后,使用tree.DecisionTreeClassifier() 建立分類(lèi)模型。
# model and fit
cls_t = tree.DecisionTreeClassifier()
cls_t.fit(X_train, y_train);
現(xiàn)在,為了對(duì)模型有一個(gè)基本的印象,我建議可視化特性的重要性。特征重要性的計(jì)算方法是通過(guò)節(jié)點(diǎn)到達(dá)該節(jié)點(diǎn)的概率加權(quán)節(jié)點(diǎn)雜質(zhì)的減少量。節(jié)點(diǎn)概率可以通過(guò)到達(dá)節(jié)點(diǎn)的樣本數(shù)除以樣本總數(shù)來(lái)計(jì)算。值越高,特征越重要。最重要的特征將在樹(shù)中更高。單個(gè)特征可以用于樹(shù)的不同分支,特征重要性則是其在減少雜質(zhì)方面的總貢獻(xiàn)。
importances = cls_t.feature_importances_
indices = np.argsort(importances)
features = cancer.feature_names
plt.title('Feature Importances')
j = 11# top j importance
plt.barh(range(j), importances[indices][len(indices)-j:], color='g', align='center')
plt.yticks(range(j), [features[i] for i in indices[len(indices)-j:]])
plt.xlabel('Relative Importance')
plt.show()
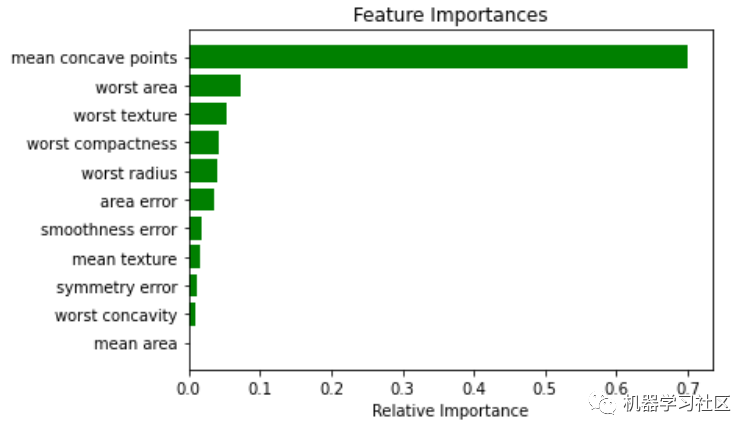
cls_t.feature_importances_
在這種情況下,僅使用前 13 個(gè)特征,未使用其他特征,表明它們的重要性是零。
讓我們將決策樹(shù)的前三層進(jìn)行可視化,max_depth=3。
# visualization
fig = plt.figure(figsize=(16, 8))
vis = tree.plot_tree(cls_t, feature_names = cancer.feature_names, class_names = ['Benign', 'Malignant'], max_depth=3, fontsize=9, proportion=True, filled=True, rounded=True)
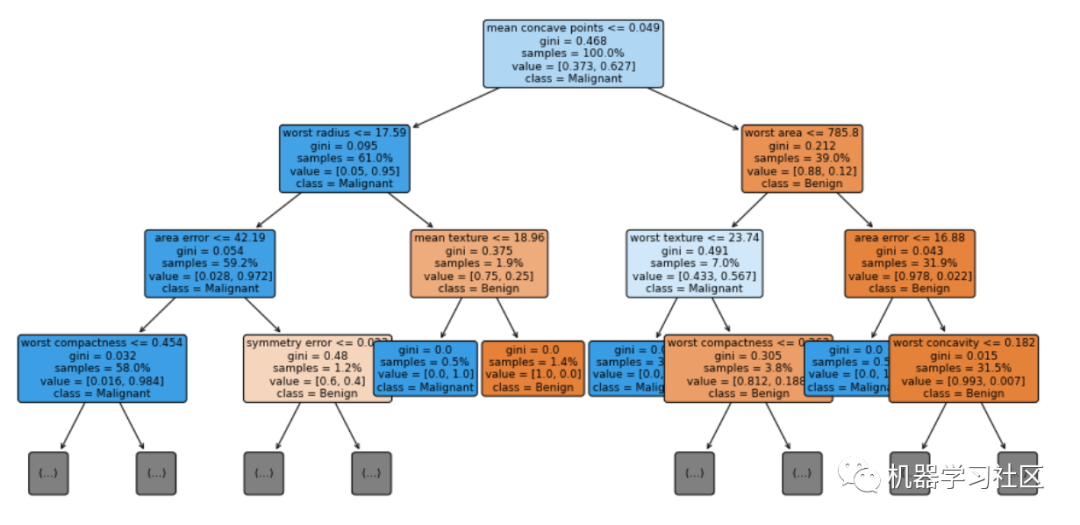
關(guān)于模型我們能了解到什么?
首先,我們可以看到每個(gè)決策級(jí)別使用的特性的名稱(chēng)和條件的拆分值。如果一個(gè)樣本滿(mǎn)足條件,那么它將轉(zhuǎn)到左分支,否則它將轉(zhuǎn)到右分支。
每個(gè)節(jié)點(diǎn)中的samples行顯示當(dāng)前節(jié)點(diǎn)中正在檢查的樣本數(shù)。如果proporty=True,則samples行中的數(shù)字以總數(shù)據(jù)集的%為單位。
每個(gè)節(jié)點(diǎn)中的值行告訴我們?cè)摴?jié)點(diǎn)中有多少個(gè)樣本屬于每個(gè)類(lèi),順序是當(dāng)比例=False時(shí),樣本的比例=True時(shí)。這就是為什么在每個(gè)節(jié)點(diǎn)中,value中的數(shù)字加起來(lái)等于value中顯示的數(shù)字,表示proportion=False,1表示proportion=True。
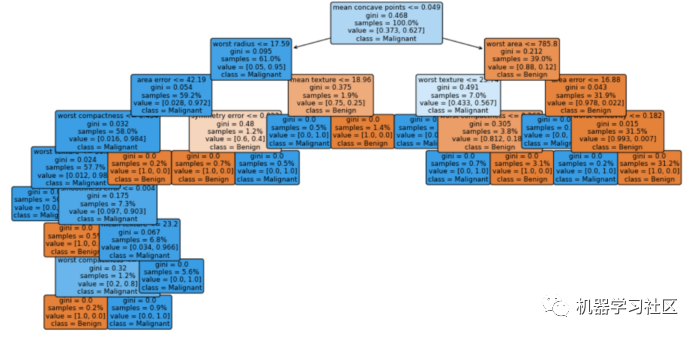
在類(lèi)行中我們可以看到節(jié)點(diǎn)的分類(lèi)結(jié)果。
基尼分?jǐn)?shù)是量化節(jié)點(diǎn)純度的度量,類(lèi)似于熵。基尼系數(shù)大于零意味著該節(jié)點(diǎn)中包含的樣本屬于不同的類(lèi)。在上圖中,葉子的基尼分?jǐn)?shù)為零,這意味著每個(gè)葉子中的樣本屬于一個(gè)類(lèi)。請(qǐng)注意,當(dāng)純度較高時(shí),節(jié)點(diǎn)/葉子的顏色較深。
決策樹(shù)代理模型
一種解釋“黑匣子”模型全局行為的流行方法是應(yīng)用全局代理模型。全局代理模型是一種可解釋的模型,經(jīng)過(guò)訓(xùn)練以近似黑盒模型的預(yù)測(cè)。我們可以通過(guò)解釋代理模型來(lái)得出關(guān)于黑盒模型的結(jié)論。通過(guò)使用更多機(jī)器學(xué)習(xí)解決機(jī)器學(xué)習(xí)可解釋性問(wèn)題!
訓(xùn)練代理模型是一種與模型無(wú)關(guān)的方法,因?yàn)樗恍枰P(guān)于黑盒模型內(nèi)部工作的任何信息,只需要訪(fǎng)問(wèn)數(shù)據(jù)和預(yù)測(cè)函數(shù)。這個(gè)想法是我們采用我們的“黑匣子”模型并使用它創(chuàng)建預(yù)測(cè)。然后我們根據(jù)“黑盒”模型和原始特征產(chǎn)生的預(yù)測(cè)訓(xùn)練一個(gè)透明模型。請(qǐng)注意,我們需要跟蹤代理模型與“黑盒”模型的近似程度,但這通常不容易確定。
隨機(jī)森林分類(lèi)器是一種常用的模型,用于解決決策樹(shù)模型往往存在的過(guò)擬合問(wèn)題。結(jié)果在測(cè)試集上具有更好的準(zhǔn)確性,但它是
clf = RandomForestClassifier(random_state=42, n_estimators=50, n_jobs=-1)
clf.fit(X_train, y_train);
使用模型創(chuàng)建預(yù)測(cè)(在本例中為 RandomForestClassifier)
predictions = clf.predict(X_train)
然后使用預(yù)測(cè)將數(shù)據(jù)擬合到?jīng)Q策樹(shù)分類(lèi)器。
cls_t = tree.DecisionTreeClassifier()
cls_t.fit(X_train, predictions);
可視化
# visualization
fig = plt.figure(figsize=(16, 8))
vis = tree.plot_tree(cls_t, feature_names = cancer.feature_names, class_names = ['Benign', 'Malignant'], max_depth=3, fontsize=9, proportion=True, filled=True, rounded=True)
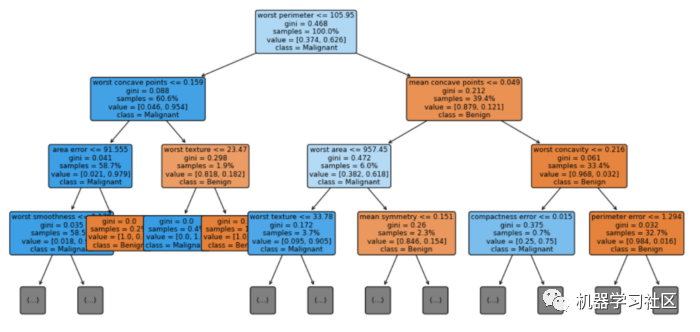 就是這樣!即使我們無(wú)法輕易理解森林中數(shù)百棵樹(shù)的外觀,我們也可以構(gòu)建一個(gè)淺層決策樹(shù),并希望了解森林的工作原理。
就是這樣!即使我們無(wú)法輕易理解森林中數(shù)百棵樹(shù)的外觀,我們也可以構(gòu)建一個(gè)淺層決策樹(shù),并希望了解森林的工作原理。
最后,測(cè)量代理模型復(fù)制黑盒模型預(yù)測(cè)的程度。衡量代理復(fù)制黑盒模型的好壞的一種方法是R平方度量。
cls_t.score(X_train, predictions)
提示
如果你使用 pycharm 創(chuàng)建模型,則可以使用 pickle 將其導(dǎo)出到j(luò)upyter notebook。
模型輸出:
import pickle
# dump information to that file
with open('model','wb') as outfile:
pickle.dump(cls_t, outfile)
模型導(dǎo)入:
import pickle
# load information from that file
with open('model','rb') as inputfile:
modell = pickle.load(inputfile)
概括
解釋“黑匣子”機(jī)器學(xué)習(xí)模型對(duì)于它們成功適用于許多現(xiàn)實(shí)世界問(wèn)題非常重要。sklearn.tree.plot_tree 是一個(gè)可視化工具,可以幫助我們理解模型。或者換句話(huà)說(shuō),機(jī)器(模型)從這些特征中學(xué)到了什么?它符合我們的期望嗎?我們能否通過(guò)使用有關(guān)問(wèn)題的領(lǐng)域知識(shí)添加更復(fù)雜的特征來(lái)幫助機(jī)器學(xué)習(xí)?使用決策樹(shù)可視化可以幫助我們直觀地評(píng)估模型的正確性,甚至可能對(duì)其進(jìn)行改進(jìn)。
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: