
手寫中文文本識(shí)別:一種無需切分標(biāo)注的方法

一、背景
二、方法
2.1 算法框架
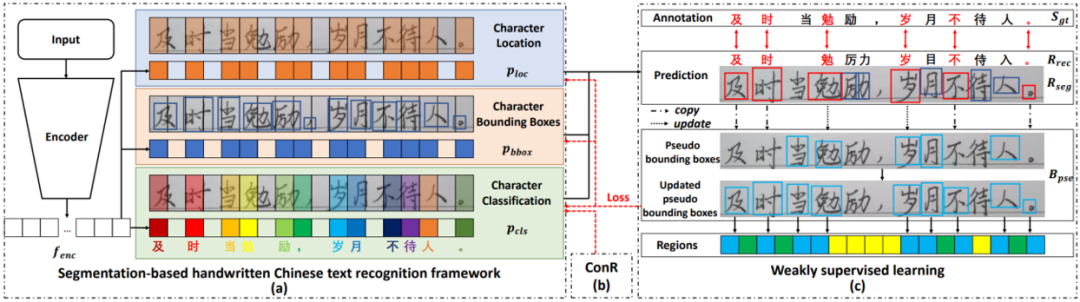 圖1 方法的整體結(jié)構(gòu)圖
圖1 方法的整體結(jié)構(gòu)圖該方法的整體框架如圖1所示。輸入的文本圖片(或聯(lián)機(jī)數(shù)據(jù)的脫機(jī)表示形式)經(jīng)過編碼器后分為三個(gè)分支,分別預(yù)測(cè)字符定位、字符邊界框和字符類別。因?yàn)樯鲜鼍W(wǎng)絡(luò)通過全卷積的方式實(shí)現(xiàn),所以無法建模上下文語(yǔ)義信息。因此,訓(xùn)練過程中,通過語(yǔ)義正則化(ConR)引導(dǎo)網(wǎng)絡(luò)在提取的特征中建模上下文信息。最后,文章提出的弱監(jiān)督學(xué)習(xí)方法通過合成數(shù)據(jù)和巧妙的偽標(biāo)注更新以及模型優(yōu)化方式,做到無需人工標(biāo)注真實(shí)數(shù)據(jù)的字符邊界框即可訓(xùn)練模型預(yù)測(cè)文本的單字切分和識(shí)別結(jié)果,極大地降低了模型實(shí)際落地的成本。
2.2 基于切分的手寫中文文本識(shí)別網(wǎng)絡(luò)
 圖2 基于切分的手寫中文文本識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)圖
圖2 基于切分的手寫中文文本識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)圖基于切分的手寫中文文本識(shí)別網(wǎng)絡(luò)的結(jié)構(gòu)借鑒了參考文獻(xiàn)[1]中提出的模型。模型輸入首先經(jīng)過多個(gè)殘差模塊提取特征,再分為三路分別得到字符邊界框分支的特征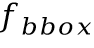 ,字符定位分支的特征
,字符定位分支的特征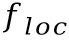 和字符分類分支的特征
和字符分類分支的特征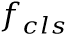 。這些特征的高度均為1,寬度均為
。這些特征的高度均為1,寬度均為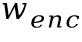 。基于每個(gè)分支的特征,再通過卷積層預(yù)測(cè)出字符邊界框坐標(biāo)
。基于每個(gè)分支的特征,再通過卷積層預(yù)測(cè)出字符邊界框坐標(biāo) ,字符定位置信度
,字符定位置信度 和字符分類概率
和字符分類概率 。結(jié)合這些預(yù)測(cè)結(jié)果,通過設(shè)置置信度閾值和NMS操作,即可得到每個(gè)字符的邊界框和類別,進(jìn)而得到整個(gè)文本行的識(shí)別結(jié)果。
。結(jié)合這些預(yù)測(cè)結(jié)果,通過設(shè)置置信度閾值和NMS操作,即可得到每個(gè)字符的邊界框和類別,進(jìn)而得到整個(gè)文本行的識(shí)別結(jié)果。
2.3 語(yǔ)義正則化

如上節(jié)中的圖2所示,識(shí)別模型采用全卷積網(wǎng)絡(luò)的形式實(shí)現(xiàn),缺少CTC/Attention方法中常采用的BLSTM層,因而無法獲取上下文的關(guān)聯(lián)信息。因此,如圖3所示,文章提出了語(yǔ)義正則化方法。
在訓(xùn)練過程中,該方法于字符分類特征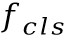 之上添加額外的兩層BLSTM層和字符分類層,新的字符分類結(jié)果同樣計(jì)算交叉熵?fù)p失
之上添加額外的兩層BLSTM層和字符分類層,新的字符分類結(jié)果同樣計(jì)算交叉熵?fù)p失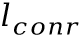 ,增加在原網(wǎng)絡(luò)的總損失上。因?yàn)锽LSTM可以建模全局的上下文關(guān)聯(lián),所以通過梯度回傳,可以引導(dǎo)字符分類特征
,增加在原網(wǎng)絡(luò)的總損失上。因?yàn)锽LSTM可以建模全局的上下文關(guān)聯(lián),所以通過梯度回傳,可以引導(dǎo)字符分類特征 嵌入上下文信息。
嵌入上下文信息。
在推理過程中,刪除額外的BLSTM層和字符分類層,采用原有的直接基于字符分類特征的分類結(jié)果。因?yàn)锽LSTM層無法并行運(yùn)算,前向效率較低,所以這樣的推理方式保持了原有的全卷積結(jié)構(gòu)的高推理速度。實(shí)驗(yàn)證明,采用BLSTM前后的分類結(jié)果的識(shí)別指標(biāo)差距極小,進(jìn)一步印證了字符分類特征可以學(xué)習(xí)到類似BLSTM建模后的上下文信息。
2.4 弱監(jiān)督學(xué)習(xí)
弱監(jiān)督學(xué)習(xí)的流程如圖1(c)所示。模型首先采用簡(jiǎn)單的合成數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,使得模型具有一定的定位和識(shí)別字符的能力,然后再采用僅有文本標(biāo)注的真實(shí)數(shù)據(jù)進(jìn)行訓(xùn)練,流程如下:
(1)對(duì)于真實(shí)數(shù)據(jù),模型預(yù)測(cè)出多個(gè)字符的邊界框和識(shí)別結(jié)果。文章中觀察到,識(shí)別正確的字符通常預(yù)測(cè)的邊界框也較為準(zhǔn)確。因此通過計(jì)算識(shí)別結(jié)果和標(biāo)注文本的編輯距離,得出兩者中字符的對(duì)應(yīng)關(guān)系,進(jìn)一步得到識(shí)別正確的字符(紅色的字符)。
(2)采用正確識(shí)別的字符的邊界框(紅色的邊界框)對(duì)偽邊界框標(biāo)注進(jìn)行更新。如果現(xiàn)有的偽邊界框標(biāo)注中已經(jīng)存在該字符的偽標(biāo)注,則將偽邊界框標(biāo)注更新為現(xiàn)有的偽邊界框和新預(yù)測(cè)的邊界框的加權(quán)和(權(quán)重基于二者的置信度計(jì)算),反之則將新預(yù)測(cè)的邊界框直接復(fù)制為偽邊界框。
三、實(shí)驗(yàn)
3.1 數(shù)據(jù)集
實(shí)驗(yàn)采用的真實(shí)數(shù)據(jù)集包括脫機(jī)手寫中文數(shù)據(jù)集CASIA-HWDB、聯(lián)機(jī)手寫中文數(shù)據(jù)集CASIA-OLHWDB、ICDAR2013比賽測(cè)試集(包含脫機(jī)和聯(lián)機(jī)數(shù)據(jù))、復(fù)雜場(chǎng)景手寫中文數(shù)據(jù)集SCUT-HCCDoc和場(chǎng)景中文數(shù)據(jù)集ReCTS。
實(shí)驗(yàn)采用的合成數(shù)據(jù)使用簡(jiǎn)單的將單字?jǐn)?shù)據(jù)拼接在白色背景上的方法,無需復(fù)雜的數(shù)據(jù)合成和渲染算法,如圖4所示。對(duì)于CASIA-HWDB和CASIA-OLHWDB,采用獨(dú)立于文本行數(shù)據(jù)的同分布單字?jǐn)?shù)據(jù)進(jìn)行合成。對(duì)于SCUT-HCCDoc和ReCTS,采用字體文件和白色背景進(jìn)行簡(jiǎn)單地合成。

3.2 ICDAR2013脫機(jī)比賽測(cè)試集。
該方法在ICDAR2013脫機(jī)比賽測(cè)試集上的實(shí)驗(yàn)結(jié)果如表1所示,可視化結(jié)果如圖5所示。
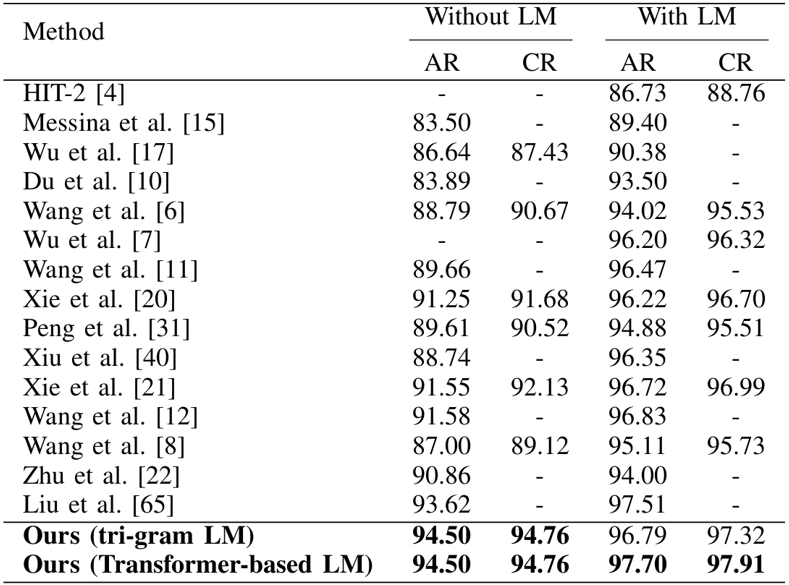
 圖5 ICDAR2013脫機(jī)比賽測(cè)試集可視化結(jié)果
圖5 ICDAR2013脫機(jī)比賽測(cè)試集可視化結(jié)果3.3 ICDAR2013聯(lián)機(jī)比賽測(cè)試集
該方法在ICDAR2013聯(lián)機(jī)比賽測(cè)試集上的實(shí)驗(yàn)結(jié)果如表2所示,可視化結(jié)果如圖6所示。
表2 ICDAR2013聯(lián)機(jī)比賽測(cè)試集實(shí)驗(yàn)結(jié)果
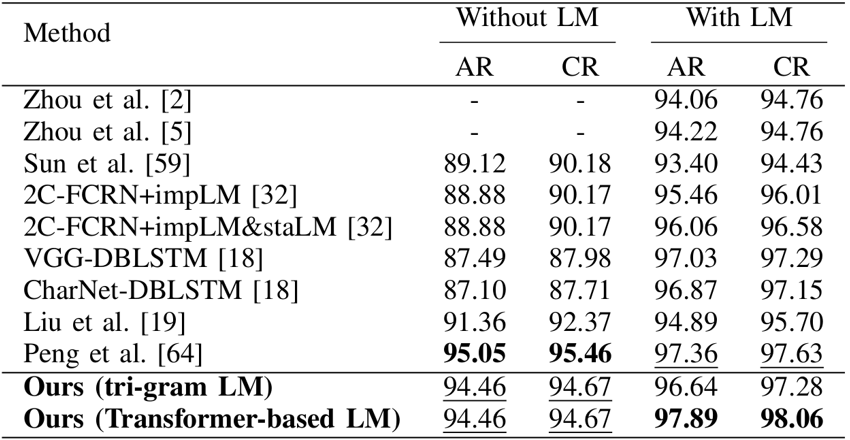
 圖6 ICDAR2013聯(lián)機(jī)比賽測(cè)試集可視化結(jié)果
圖6 ICDAR2013聯(lián)機(jī)比賽測(cè)試集可視化結(jié)果3.4 SCUT-HCCDoc數(shù)據(jù)集
該方法在SCUT-HCCDoc數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果如表3所示,可視化結(jié)果如圖7所示。
表3 SCUT-HCCDoc數(shù)據(jù)集實(shí)驗(yàn)結(jié)果

 圖7 SCUT-HCCDoc數(shù)據(jù)集可視化結(jié)果
圖7 SCUT-HCCDoc數(shù)據(jù)集可視化結(jié)果3.5 ReCTS數(shù)據(jù)集
該方法在ReCTS數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果如表4所示,可視化結(jié)果如圖8所示
表4 ReCTS數(shù)據(jù)集實(shí)驗(yàn)結(jié)果


3.6 與CTC/Attention方法的比較
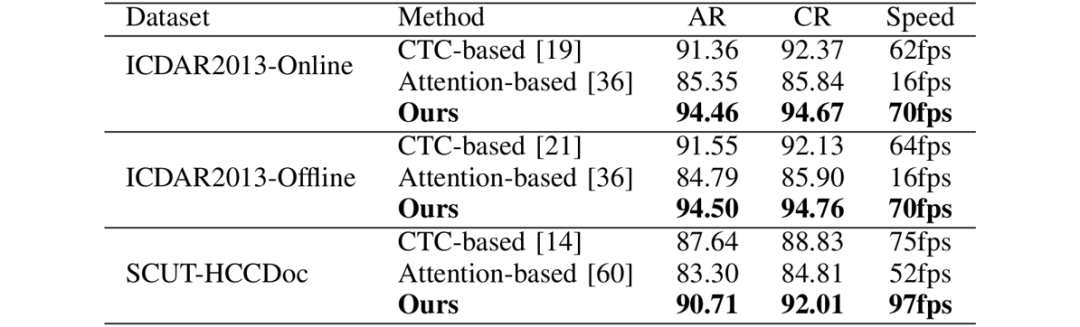
該方法與CTC/Attention方法在精度和速度上的比較如表5所示。可以看出,該方法在精度和速度上均由于目前流行的CTC/Attention方法。
表5 與CTC/Attention方法的在精度和速度上的比較
四、總結(jié)及討論
五、相關(guān)資源
論文地址:https://ieeexplore.ieee.org/document/9695187
參考文獻(xiàn)
[1]Dezhi Peng, et al. “A fast and accurate fully convolutional network for end-to-end handwritten Chinese text segmentation and recognition.” Proceedings of International Conference on Document Analysis and Recognition. 2019.
撰稿:彭德智
編排:高 學(xué)
審校:殷 飛
發(fā)布:金連文
免責(zé)聲明:(1)本文僅代表撰稿者觀點(diǎn),撰稿者不一定是原文作者,其個(gè)人理解及總結(jié)不一定準(zhǔn)確及全面,論文完整思想及論點(diǎn)應(yīng)以原論文為準(zhǔn)。(2)本文觀點(diǎn)不代表本公眾號(hào)立場(chǎng)。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有美顏、三維視覺、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群
個(gè)人微信(如果沒有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2022 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
