
【ICLR2021】CoCon:一種自監(jiān)督的可控文本生成方法
ICLR2021的論文《CoCon:A Self-Supervised Approachfor Controlled Text Generation》,提出一種用文本去指導(dǎo)文本生成的無監(jiān)督方法,是follow了CTRL和PPLM的后續(xù)工作。作者設(shè)計(jì)了一個(gè)叫做CoCon的模塊,插入transformer中,CoCon結(jié)構(gòu)和正常的transformer encoder一樣。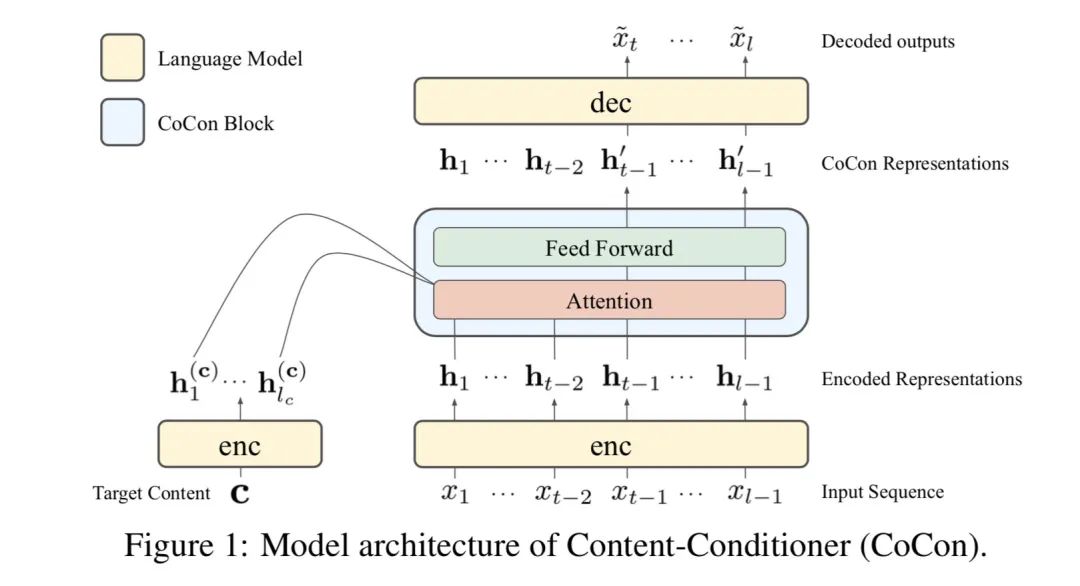
在生成文本時(shí),假設(shè)是我們想要的內(nèi)容,即control部分,c的長度為,句子長度為,被劃分為和兩個(gè)部分,我們使用和去預(yù)測部分。具體做法如下:
首先用一個(gè)transformer encoder分別編碼和,得到了各自的特征和,然后將他們送入CoCon模塊通過self-attention融合,將的Key和Value concat到的Key和Value前面,Query不變,依舊來自于
經(jīng)過feed-forward layer后得到了我們要的包含c的信息的隱變量,普通的transformer就是得到了,然后就當(dāng)作memory輸入decoder去指導(dǎo)文本生成了,CoCon這一步就是把和 concat起來再經(jīng)過一個(gè)transformer encoder,得到了我們要的
decoder的生成過程作者寫的讓我稍微有些困惑,生成的時(shí)候并不是使用,而是把和 concat起來去生成,不知道為什么不直接用去生成。
當(dāng)我們有多個(gè)想要的內(nèi)容時(shí),也就是有多個(gè)c,可以把它們一起concat起來,即
訓(xùn)練的過程作者使用了4個(gè)loss,首先把長度為的句子分為兩個(gè)部分,,,
第一個(gè)是重構(gòu)loss,讓,然后讓模型condition on 和去生成
第二個(gè)是叫做Null Content Loss,,模型只condition on ,讓模型學(xué)會生成流暢的句子
第三個(gè)Cycle loss我覺得是本文最大亮點(diǎn),不過這個(gè)cycle思想應(yīng)該在以前的很多工作中都有了,作者選出兩個(gè)句子和,, ,先讓模型根據(jù)和去生成句子
然后讓模型根據(jù)和去生成句子,loss cycle的目的是要使其接近
這塊理解起來還是有點(diǎn)繞的,首先的生成過程,那么我們是希望的內(nèi)容能包含的信息,同時(shí)要和的銜接保持流暢,接著使用和生成,那么我們希望既能包含的信息,又要和銜接流暢,而又因?yàn)?span style="cursor:pointer;">包含的信息,因此應(yīng)該既包含的信息,又能和銜接流暢,那它不就應(yīng)該是生成了嗎?!因此就是計(jì)算和相差多大。作者在這里的intuition是:在現(xiàn)實(shí)中給出提示文本,可能的銜接文本是非常多的,因此我們希望通過給模型一個(gè),去生成包含的信息且能和銜接流暢的。
最后一個(gè)loss是adversarial loss,因?yàn)檫@在其他工作中經(jīng)常被用,希望模型生成的文本盡可能與真實(shí)文本接近
的參數(shù)為
最后整個(gè)模型的訓(xùn)練是
用來控制每個(gè)loss的權(quán)重。
作者的實(shí)驗(yàn)基于GPT-2,數(shù)據(jù)選用了openai提供的用GPT-2生成的句子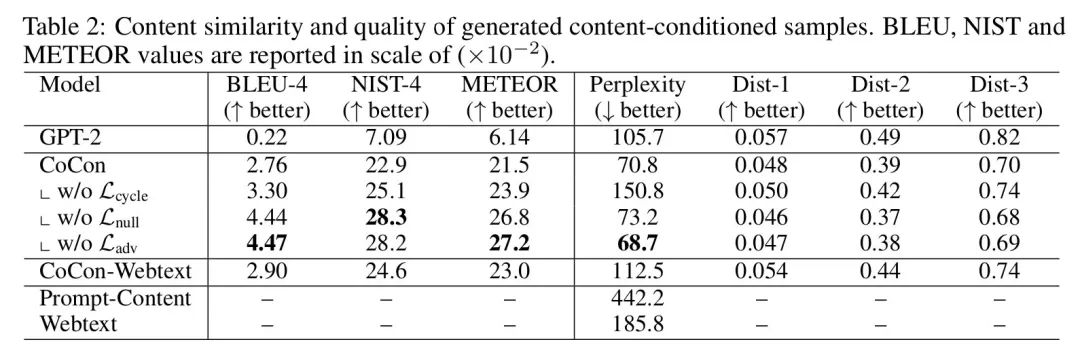
sentiment和topic classifier用了一個(gè)在kaggle數(shù)據(jù)集上訓(xùn)練得到的分類器,發(fā)現(xiàn)CoCon生成的句子能更好地控制topic和sentiment
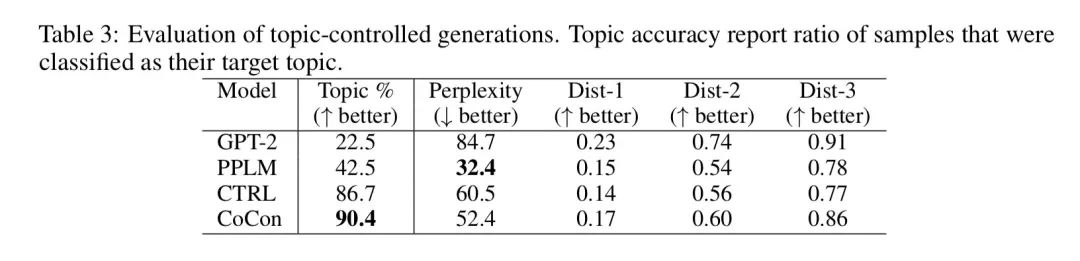
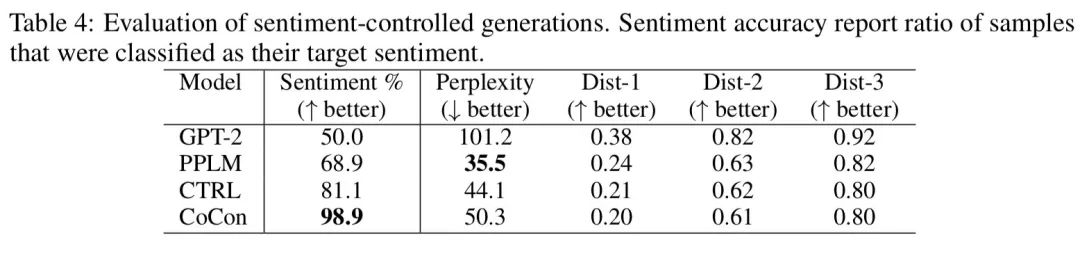
稍微有些遺憾的是作者還沒有開源代碼,不過ICLR2021才放榜不久,也許后續(xù)作者們會補(bǔ)上代碼吧。
如果你有什么疑問或想法,歡迎留言交流~
點(diǎn)擊閱讀原文可查看原論文