
面試官:ConcurrentHashMap為什么放棄了分段鎖?
什么是分段鎖
我們都知道 HashMap 是一個線程不安全的類,多線程環(huán)境下,使用 HashMap 進(jìn)行put操作會引起死循環(huán),導(dǎo)致CPU利用率接近100%,所以如果你的并發(fā)量很高的話,所以是不推薦使用 HashMap 的。
而我們所知的,HashTable 是線程安全的,但是因?yàn)?HashTable 內(nèi)部使用的 synchronized 來保證線程的安全,所以,在多線程情況下,HashTable 雖然線程安全,但是他的效率也同樣的比較低下。
所以就出現(xiàn)了一個效率相對來說比 HashTable 高,但是還比 HashMap 安全的類,那就是 ConcurrentHashMap,而 ConcurrentHashMap 在 JDK8 中卻放棄了使用分段鎖,為什么呢?那他之后是使用什么來保證線程安全呢?我們今天來看看。
什么是分段鎖?
其實(shí)這個分段鎖很容易理解,既然其他的鎖都是鎖全部,那分段鎖是不是和其他的不太一樣,是的,他就相當(dāng)于把一個方法切割成了很多塊,在單獨(dú)的一塊上鎖的時候,其他的部分是不會上鎖的,也就是說,這一段被鎖住,并不影響其他模塊的運(yùn)行,分段鎖如果這樣理解是不是就好理解了,我們先來看看 JDK7 中的 ConcurrentHashMap 的分段鎖的實(shí)現(xiàn)。
在 JDK7 中 ConcurrentHashMap 底層數(shù)據(jù)結(jié)構(gòu)是數(shù)組加鏈表,這也是之前阿粉說過的 JDK7和 JDK8 中 HashMap 不同的地方,源碼送上。
//初始總?cè)萘浚J(rèn)16
static final int DEFAULT_INITIAL_CAPACITY = 16;
//加載因子,默認(rèn)0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//并發(fā)級別,默認(rèn)16
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
}
在阿粉貼上的上面的源碼中,有Segment<K,V>,這個類才是真正的的主要內(nèi)容, ConcurrentHashMap 是由 Segment 數(shù)組結(jié)構(gòu)和 HashEntry 數(shù)組結(jié)構(gòu)組成.
我們看到了 Segment<K,V>,而他的內(nèi)部,又有HashEntry數(shù)組結(jié)構(gòu)組成. Segment 繼承自 RentrantLock 在這里充當(dāng)?shù)氖且粋€鎖,而在其內(nèi)部的 HashEntry 則是用來存儲鍵值對數(shù)據(jù).
圖就像下面這個樣子
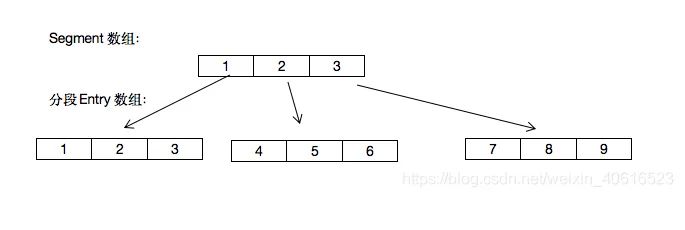
也就是說,一個Segment里包含一個HashEntry數(shù)組,每個HashEntry是一個鏈表結(jié)構(gòu)的元素,當(dāng)需要put元素的時候,并不是對整個hashmap進(jìn)行加鎖,而是先通過hashcode來知道他要放在哪一個分段中,然后對這個分段進(jìn)行加鎖。
最后也就出現(xiàn)了,如果不是在同一個分段中的 put 數(shù)據(jù),那么 ConcurrentHashMap 就能夠保證并行的 put ,也就是說,在并發(fā)過程中,他就是一個線程安全的 Map 。
為什么 JDK8 舍棄掉了分段鎖呢?
這時候就有很多人關(guān)心了,說既然這么好用,為啥在 JDK8 中要放棄使用分段鎖呢?
這就要我們來分析一下為什么要用 ConcurrentHashMap ,
1.線程安全。
2.相對高效。
因?yàn)樵?JDK7 中 Segment 繼承了重入鎖ReentrantLock,但是大家有沒有想過,如果說每個 Segment 在增長的時候,那你有沒有考慮過這時候鎖的粒度也會在不斷的增長。
而且前面阿粉也說了,一個Segment里包含一個HashEntry數(shù)組,每個鎖控制的是一段,那么如果分成很多個段的時候,這時候加鎖的分段還是不連續(xù)的,是不是就會造成內(nèi)存空間的浪費(fèi)。
所以問題一出現(xiàn)了,分段鎖在某些特定的情況下是會對內(nèi)存造成影響的,什么情況呢?我們倒著推回去就知道:
1.每個鎖控制的是一段,當(dāng)分段很多,并且加鎖的分段不連續(xù)的時候,內(nèi)存空間的浪費(fèi)比較嚴(yán)重。
大家都知道,并發(fā)是什么樣子的,就相當(dāng)于百米賽跑,你是第一,我是第二這種形式,同樣的,線程也是這樣的,在并發(fā)操作中,因?yàn)榉侄捂i的存在,線程操作的時候,爭搶同一個分段鎖的幾率會小很多,既然小了,那么應(yīng)該是優(yōu)點(diǎn)了,但是大家有沒有想過如果這一分塊的分段很大的時候,那么操作的時間是不是就會變的更長了。
所以第二個問題出現(xiàn)了:
2.如果某個分段特別的大,那么就會影響效率,耽誤時間。
所以,這也是為什么在 JDK8 不在繼續(xù)使用分段鎖的原因。
既然我們說到這里了,我們就來聊一下這個時間和空間的概念,畢竟很多面試官總是喜歡問時間復(fù)雜度,這些看起來有點(diǎn)深奧的東西,但是如果你自己想想,用自己的話說出來,是不是就沒有那么難理解了。
什么是時間復(fù)雜度
百度百科是這么說的:
在計(jì)算機(jī)科學(xué)中,時間復(fù)雜性,又稱時間復(fù)雜度,算法的時間復(fù)雜度是一個函數(shù),它定性描述該算法的運(yùn)行時間,
這是一個代表算法輸入值的字符串的長度的函數(shù)。時間復(fù)雜度常用大O符號表述,不包括這個函數(shù)的低階項(xiàng)和首項(xiàng)系數(shù)
其實(shí)面試官問這個 時間復(fù)雜度 無可厚非,因?yàn)槿绻阕鳛橐粋€公司的領(lǐng)導(dǎo),如果手底下的兩個員工,交付同樣的功能提測,A交付的代碼,運(yùn)行時間50s,內(nèi)存占用12M,B交付的代碼,運(yùn)行時間110s,內(nèi)存占用50M 的時候,你會選擇哪個員工提交的代碼?
A 還是 B 這個答案一目了然,當(dāng)然,我們得先把 Bug 這種因素排除掉,沒有任何質(zhì)疑,肯定選 A 員工提交的代碼,因?yàn)檫\(yùn)行時間快,內(nèi)存占用量小,那肯定的優(yōu)先考慮。
那么既然我們知道這個代碼都和時間復(fù)雜度有關(guān)系了,那么面試官再問這樣的問題,你還覺得有問題么?
答案也很肯定,沒問題,你計(jì)算不太熟,但是也需要了解。
我們要想知道這個時間復(fù)雜度,那么就把我們的程序拉出來運(yùn)行一下,看看是什么樣子的,我們先從循環(huán)入手,
for(i=1; i<=n; i++)
{
j = i;
j++;
}
它的時間復(fù)雜度是什么呢?上面百度百科說用大O符號表述,那么實(shí)際上它的時間復(fù)雜度就是 O(n),這個公式是什么意思呢?
線性階 O(n),也就是說,我們上面寫的這個最簡單的算法的時間趨勢是和 n 掛鉤的,如果 n 變得越來越大,那么相對來說,你的時間花費(fèi)的時間也就越來越久,也就是說,我們代碼中的 n 是多大,我們的代碼就要循環(huán)多少遍。這樣說是不是就很簡單了?
關(guān)于時間復(fù)雜度,阿粉以后會給大家說,話題跑遠(yuǎn)了,我們回來,繼續(xù)說,JDK8 的 ConcurrentHashMap 既然不使用分段鎖了,那么他使用的是什么呢?
JDK8 的 ConcurrentHashMap 使用的是什么?
從上面的分析中,我們得出了 JDK7 中的 ConcurrentHashMap 使用的是 Segment 和 HashEntry,而在 JDK8 中 ConcurrentHashMap 就變了,阿粉現(xiàn)在這里給大家把這個拋出來,我們再分析, JDK8 中的 ConcurrentHashMap 使用的是 synchronized 和 CAS 和 HashEntry 和紅黑樹。
聽到這里的時候,我們是不是就感覺有點(diǎn)類似,HashMap 是不是也是使用的紅黑樹來著?有這個感覺就對了,
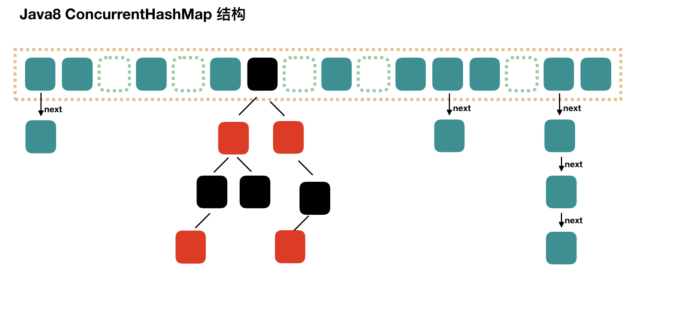
ConcurrentHashMap 和 HashMap 一樣,使用了紅黑樹,而在 ConcurrentHashMap 中則是取消了Segment分段鎖的數(shù)據(jù)結(jié)構(gòu),取而代之的是Node數(shù)組+鏈表+紅黑樹的結(jié)構(gòu)。
為什么要這么做呢?
因?yàn)檫@樣就實(shí)現(xiàn)了對每一行數(shù)據(jù)進(jìn)行加鎖,減少并發(fā)沖突。
實(shí)際上我們也可以這么理解,就是在 JDK7 中,使用的是分段鎖,在 JDK8 中使用的是 “讀寫鎖” 畢竟采用了 CAS 和 Synchronized 來保證線程的安全。
我們來看看源碼:
//第一次put 初始化 Node 數(shù)組
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果相應(yīng)位置的Node還未初始化,則通過CAS插入相應(yīng)的數(shù)據(jù)
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
...
//如果該節(jié)點(diǎn)是TreeBin類型的節(jié)點(diǎn),說明是紅黑樹結(jié)構(gòu),則通過putTreeVal方法往紅黑樹中插入節(jié)點(diǎn)
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
//如果binCount不為0,說明put操作對數(shù)據(jù)產(chǎn)生了影響,如果當(dāng)前鏈表的個數(shù)達(dá)到8個,則通過treeifyBin方法轉(zhuǎn)化為紅黑樹,如果oldVal不為空,說明是一次更新操作,返回舊值
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
addCount(1L, binCount);
return null;
}
put 的方法有點(diǎn)太長了,阿粉就截取了部分代碼,大家莫怪,如果大家有興趣,大家可以去對比一下去 JDK7 和 JDK8 中尋找不同的東西,這樣親自動手才能收獲到更多不是么?
文章參考
《百度百科-時間復(fù)雜度》