
10分鐘教你Python爬蟲(上)-- HTML和爬蟲基礎(chǔ)
新年快樂
各位看客老爺們,新年好。小瑋又來啦。這次給大家?guī)淼氖桥老x系列的第一課---HTML和爬蟲基礎(chǔ)。
在最開始的時候,我們需要先了解一下什么是爬蟲。簡單地來說呢,爬蟲就是一個可以自動登陸網(wǎng)頁獲取網(wǎng)頁信息的程序。
舉個例子來說,比如你想每天看到自己喜歡的新聞內(nèi)容,而不是各類新聞平臺給你推送的各種各樣的信息,你就可以寫一個爬蟲去爬取這些關(guān)鍵詞的內(nèi)容,使自己能夠按時獲得自己感興趣的內(nèi)容,等等。
總的來說,爬蟲能用來進行數(shù)據(jù)監(jiān)控,數(shù)據(jù)收集,信息整合,資源采集。
然后,我們一起來總結(jié)一下我們?yōu)g覽網(wǎng)頁的過程。
1.輸入網(wǎng)址
2.瀏覽器向DNS服務(wù)商發(fā)送請求?
3.找對相應(yīng)服務(wù)器?
4.服務(wù)器解析請求
5.服務(wù)器處理請求得到最終結(jié)果發(fā)出去?
6.瀏覽器解析返回的數(shù)據(jù)?
7.展示給用戶。
這些過程我們并不需要每個過程都十分了解,但是你需要知道在瀏覽服務(wù)器的過程之中,我們需要一個這樣的過程。下面給大家解釋一下每個步驟到底是干啥的。
第一步很容易,就不多說了。我們從第二步開始,因為我們是通過這個瀏覽器訪問這個網(wǎng)址,我們就需要向DNS服務(wù)商發(fā)送一個請求,簡單來說,當(dāng)我們輸入一個域名的時候,我們需要一個中間的人幫我們?nèi)シ治鲞@個網(wǎng)址對應(yīng)的是哪一個IP地址下的服務(wù)器,然后找到相應(yīng)的服務(wù)器,當(dāng)服務(wù)器接收到我們的請求時,服務(wù)器就會解析一下我們的請求,在解析了之后,會將最終的結(jié)果反饋給我們。
比如當(dāng)我們點擊支付,服務(wù)器會解析我們這個過程,然后把最終支付成功的結(jié)果反饋我們的瀏覽器,瀏覽器把這個數(shù)據(jù)進行渲染之后,再展示給我們。
下面我們再來分析一下域名的問題。讓我們來看看這個域名??
http://movie.douban.com/subject/4920389/?From=showing。這是我們打開豆瓣電影的某個電影以后,出現(xiàn)的網(wǎng)址。在這個網(wǎng)址里面,我們可以看到一級域名。怎么找到一級域名呢?很簡單,.com,.cn……之前的第一串單詞或者第一個單詞,就是我們的一級域名,在這個網(wǎng)址中,一級域名就是douban,那么douban的左邊是什么呢?沒錯,就是二級域名。
只要你擁有了一個一級域名,那么二級域名是隨便你設(shè)置的,這里很多小伙伴就會提問了,怎么才能有一個一級域名呢?其實也很簡單,只需要前往阿里云等網(wǎng)站就可以購買一個域名了。
所以,在這個位置,你要尤為注意,一級域名是獨一無二的,但是二級域名是可以任意的,所以騙子通常會在二級域名上動手腳,大家一定要關(guān)注這一點,小心上當(dāng)受騙。
??
那么后面的內(nèi)容是什么呢。/subject/4920389/?,其實類似文件夾一樣的東西,就是在我們二級域名以下的一些網(wǎng)址,那么問號以后是什么呢?就是一個網(wǎng)址參數(shù),如果我們前面的參數(shù)一樣,但是如果最后這個參數(shù)不一樣,有可能我們看到的網(wǎng)頁也不一樣。
介紹完了這個,我們來研究研究爬蟲的策略,主要分為兩個:
1. 從某個頁面開始不斷爬取頁面上的鏈接,主要分為深度優(yōu)先搜索和廣度優(yōu)先搜索兩種方法,這個不理解沒關(guān)系,在之后的數(shù)據(jù)結(jié)構(gòu)篇中我會給大家一一介紹
2. 觀察網(wǎng)址的規(guī)律,這個很簡單,而且也是我們最常用的方法。我們在這里舉一個例子。
http://xiaohua.zol.com.cn/lengxiaohua/2.htmlhttp://xiaohua.zol.com.cn/lengxiaohua/3.html
看到上面這兩個網(wǎng)址的差別了嗎?對,就只是lengxiaohua/后面的數(shù)字不一樣,那么如果我要實現(xiàn)一面一面的搜索網(wǎng)站內(nèi)容,怎么辦?是不是直接更改/后面的數(shù)字就可以了?沒錯,就是這么簡單。
然后,給大家介紹一下什么是前端什么是后端。簡單來說前端就是展示給我們看的,后端就是我們看不到的。
舉個例子來說,你在論壇想發(fā)一個帖子,首先是把數(shù)據(jù)傳給后端,后端進行一些相應(yīng)的判斷和處理,然后展示在前端給大家看,這就是前端和后端。
因為本篇推文我們的關(guān)注點是爬蟲,所以我們更多的是關(guān)注前端。
前端開發(fā)的工具,目前主流的是Chrome瀏覽器,當(dāng)然不是說別的瀏覽器不行這樣,因為現(xiàn)在大部分瀏覽器基本上都是從Chrome改造過來的,把Chrome的一些東西去掉,加上一些自己的東西這樣子,所以盡量用Chrome瀏覽器。
然后前端主要有三個重要方面,HTML,CSS,Javascript,下面我們來分別了解一下這三個方面。

HTML的全稱是HyperText Markup Language,它是一個網(wǎng)頁的最基本要素,沒有HTML,整個網(wǎng)頁根本就沒有辦法展示,通過標(biāo)記語言的方式來組織內(nèi)容(文字,圖片,視頻)等等。
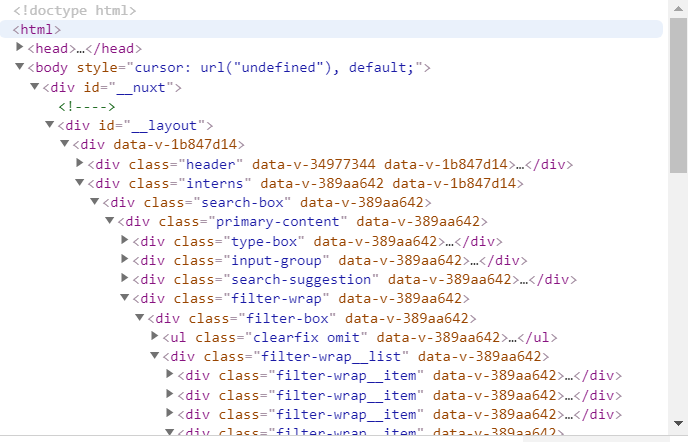
比方說我們要在某個位置插入一段文字,某個位置插入一段視頻這樣子,下面就是一個網(wǎng)頁的HTML,想要看一個網(wǎng)頁的HTML也很簡單,右鍵點擊頁面,選擇檢查或者檢查源代碼就可以看到了。
它一般分為head和body兩個部分,怎么分辨呢?也很簡單,,這些可以直接在網(wǎng)頁源代碼中看的見。一般來說head里面包括的內(nèi)容是我這個網(wǎng)頁的一些聲明,適合用什么方式瀏覽等等。
當(dāng)然了HTML里面最基本的段落, 這是一個段落 中還可以加一些屬性的東西,比如說 這樣子,這個位置就是我們在爬蟲中特別需要關(guān)注的地方,屬性可以有多種多樣的,這里列出來的是 類屬性。
這里列舉一些常用的HTML標(biāo)簽讓大家了解。
標(biāo)題:<h1>一級標(biāo)題h1>,<hn>n級標(biāo)簽hn>段落:<p>這是一個段落p>無序列表:<ul><li>Pythonli><li>C/C++li>ul>有序列表:把ul改為ol即可鏈接:<a href=“網(wǎng)址”>名稱a>
既然介紹了這么多,大家其實可以自己嘗試著去寫一個網(wǎng)頁。下面給出一個例子。
<html><head><meta charset=’utf-8’><meta http-equiv=’X-UA-Compatible’ content=’IE=edge,chrome=1’><title>小瑋的課堂title><meta name=’description’content=’’><meta name=’keywords’content=’’><link href=’’rel=’stylesheet’>head><body><h1>小瑋的課堂h1><p>歡迎來到小瑋的課堂p><a href=’xxxxxx’>小瑋課堂的官網(wǎng)a><img src=’html.png’>body>html>
先保存為index.html文件,然后再去寫即可。
然后就是下一個方面CSS,CSS就是指層疊樣式表(Cascading Style Sheets),它定義了一個網(wǎng)頁該如何顯示里面的元素,比如這個段落該靠在瀏覽器的左邊還是右邊,這段文字的字體,顏色,大小該是什么,這些方面都是由CSS定義。
那么如何建立一個CSS文件呢?新建一個文件,寫入以下內(nèi)容
p{color:blue;}
保存為index-style.css,和index.html保存在同一個目錄之下。當(dāng)然并不是說放在一起他們就一塊兒運行了,我們還需要進行一些別的處理。
我們回到html文件,在link href的位置進行一些修改。
<link href='index-style.css' rel='stylesheet'>大家可以把加入CSS和沒有加入CSS的html文件進行對比就知道區(qū)別在哪里了。CSS內(nèi)容里面的p其實是選擇器的意思,表示我們選擇了p標(biāo)簽,我們在后面的操作是針對所有p標(biāo)簽的,里面color是屬性,blue是屬性值。
當(dāng)然你還可以加入font-family:KaiTi,把字體進行修改,還有很多很多方面,大家可以多看看別的網(wǎng)頁的源代碼進行研究一下,特別推薦大家看一看蘋果的網(wǎng)頁源代碼,可以學(xué)到相當(dāng)多的東西。
然后我們再來看看id和class,這些都是屬性,id在每一個html文件中只能有一個,和身份證一樣,但是class可以有很多個。
那么基于這個我們就可以利用css進行各種各樣的個性操作啦。比如說#welcome-line{},在選擇器前加上#表示這個選擇了一個id,.link{},表示選擇了一個class。
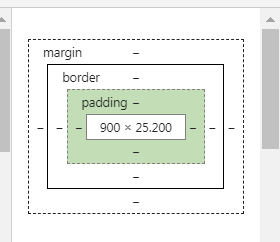
然后就是這個盒子模型,這個其實很容易理解,大家把鼠標(biāo)放在上面就可以知道這個是什么意思了,它表示的是邊界的意思。內(nèi)容和盒子邊框中間是padding,即內(nèi)邊距,邊框和邊框外其他元素之間是margin,即外邊距。
終于來到了最后的JavaScript,這個和Java可是沒有一點關(guān)系的啊,朋友們,這個是一款主要用于前端的一種編程語言,為網(wǎng)站提供動態(tài),交互的效果。
給大家舉一個例子。把鼠標(biāo)放在上面他會自動彈出一些東西,或者變顏色之類的都是JSP做的東西。
他和之前兩個方面的主要區(qū)別就是,他是一種嚴格意義上的編程語言。當(dāng)然,隨著技術(shù)的發(fā)展,JSP現(xiàn)在也慢慢用于后端的編寫了。
那么我們怎么寫一個JSP文件呢?新建一個文件,寫入以下內(nèi)容
var alertText='hello xiao wei'alert(alertText)
保存為index.js,和index.html放在同一個目錄下面,這兩句話是什么意思呢?第一行,我們用var定義了一個字符串,后面的alert(alertText)是可以在網(wǎng)頁彈出一個提示框,大家經(jīng)常進入一個網(wǎng)頁會彈出一個對話框,就是這個原理。
在JSP中大家可以使用if判斷語句,也可以定義函數(shù)等等,這里就不多介紹了。
到這里為止,差不多已經(jīng)把前端的知識給大家都介紹了一下,如果大家自己對這部分內(nèi)容感興趣,可以去深入的了解一下。
因為小瑋是個新手,這方面可能了解的不是很透徹,更加深入的就要看各位看客老爺自己了。那么了解完了這些知識,下一期我們就會正式進入爬蟲的實戰(zhàn)環(huán)節(jié)啦。期待下一次推文~
祝各位看客老爺新年快樂!
