
一文學會爬蟲技巧
前言
作為冷數(shù)據(jù)啟動和豐富數(shù)據(jù)的重要工具,爬蟲在業(yè)務(wù)發(fā)展中承擔著重要的作用,我們業(yè)務(wù)在發(fā)展過程中積累了不少爬蟲使用的經(jīng)驗,在此分享給大家,希望能對之后的業(yè)務(wù)發(fā)展提供一些技術(shù)選型方向上的思路,以更好地促進業(yè)務(wù)發(fā)展
我們將會從以下幾點來分享我們的經(jīng)驗
爬蟲的應(yīng)用場景 爬蟲的技術(shù)選型 實戰(zhàn)詳解:復雜場景下的爬蟲解決方案 爬蟲管理平臺
爬蟲的應(yīng)用場景
在生產(chǎn)上,爬蟲主要應(yīng)用在以下幾種場景
搜索引擎,Google,百度這種搜索引擎公司每天啟動著無數(shù)的爬蟲去抓取網(wǎng)頁信息,才有了我們使用搜索引擎查詢資料的便捷,全面,高效 冷數(shù)據(jù)啟動時豐富數(shù)據(jù)的主要工具,新業(yè)務(wù)開始時,由于剛起步,所以沒有多少數(shù)據(jù),此時就需要爬取其他平臺的數(shù)據(jù)來填充我們的業(yè)務(wù)數(shù)據(jù),比如說如果我們想做一個類似大眾點評這樣的平臺,一開始沒有商戶等信息,就需要去爬取大眾,美團等商家的信息來填充數(shù)據(jù) 數(shù)據(jù)服務(wù)或聚合的公司,比如天眼查,企查查,西瓜數(shù)據(jù)等等 提供橫向數(shù)據(jù)比較,聚合服務(wù),比如說電商中經(jīng)常需要有一種比價系統(tǒng),從各大電商平臺,如拼多多,淘寶,京東等抓取同一個商品的價格信息,以給用戶提供最實惠的商品價格,這樣就需要從各大電商平臺爬取信息。 黑產(chǎn),灰產(chǎn),風控等,比如我們要向某些資金方申請授信,在資金方這邊首先要部署一道風控,來看你的個人信息是否滿足授信條件,這些個人信息通常是某些公司利用爬蟲技術(shù)在各個渠道爬取而來的,當然了這類場景還是要慎用,不然正應(yīng)了那句話「爬蟲用的好,監(jiān)控進得早」
爬蟲的技術(shù)選型
接下來我們就由淺入深地為大家介紹爬蟲常用的幾種技術(shù)方案
簡單的爬蟲
說起爬蟲,大家可能會覺得技術(shù)比較高深,會立刻聯(lián)想到使用像 Scrapy 這樣的爬蟲框架,這類框架確實很強大,那么是不是一寫爬蟲就要用框架呢?非也!要視情況而定,如果我們要爬取的接口返回的只是很簡單,固定的結(jié)構(gòu)化數(shù)據(jù)(如JSON),用 Scrapy 這類框架的話有時無異于殺雞用牛刀,不太經(jīng)濟!
舉個簡單的例子,業(yè)務(wù)中有這么一個需求:需要抓取育學園中準媽媽從「孕4周以下」~「孕36個月以上」每個階段的數(shù)據(jù)

對于這種請求,bash 中的 curl 足堪大任!
首先我們用 charles 等抓包工具抓取此頁面接口數(shù)據(jù),如下

通過觀察,我們發(fā)現(xiàn)請求的數(shù)據(jù)中只有 month 的值(代表孕幾周)不一樣,所以我們可以按以下思路來爬取所有的數(shù)據(jù):
1、 找出所有「孕4周以下」~「孕36個月以上」對應(yīng)的 month 的值,構(gòu)建一個 month 數(shù)組 2、 構(gòu)建一個以 month 值為變量的 curl 請求,在 charles 中 curl 請求我們可以通過如下方式來獲取
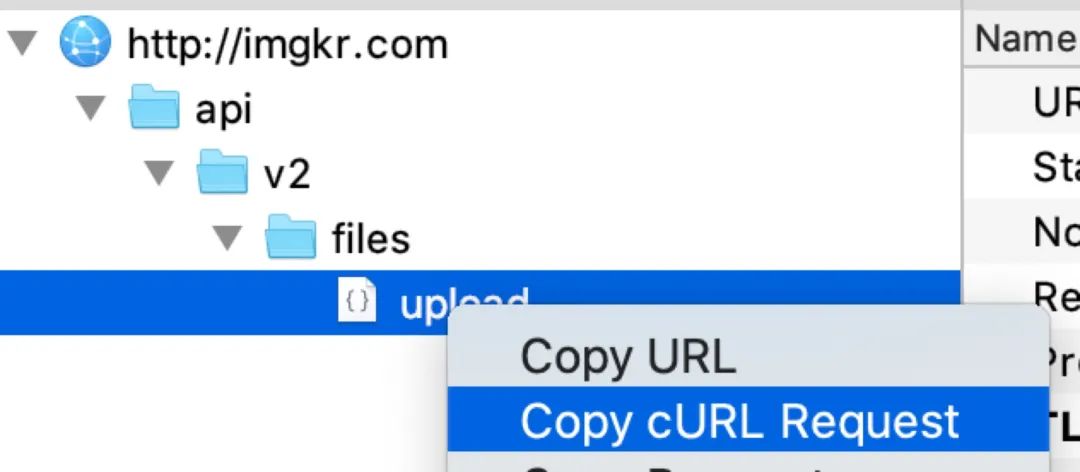
3、 依次遍歷步驟 ?1 中的 ?month,每遍歷一次,就用步驟 2 中的 curl 和 month 變量構(gòu)建一個請求并執(zhí)行,將每次的請求結(jié)果保存到一個文件中(對應(yīng)每個孕期的 month 數(shù)據(jù)),這樣之后就可以對此文件中的數(shù)據(jù)進行解析分析。
示例代碼如下,為了方便演示,中間 curl 代碼作了不少簡化,大家明白原理就好
#!/bin/bash
##?獲取所有孕周對應(yīng)的?month,這里為方便演示,只取了兩個值
month=(21?24)
##?遍歷所有?month,組裝成?curl?請求
for?month?in?${month[@]};
do
????curl?-H?'Host:?yxyapi2.drcuiyutao.com'?
????-H?'clientversion:?7.14.1'?
????????...
????-H?'birthday:?2018-08-07?00:00:00'??
????--data?"body=month%22%3A$month"??##?month作為變量構(gòu)建?curl?請求
????--compressed?'http://yxyapi2.drcuiyutao.com/yxy-api-gateway/api/json/tools/getBabyChange'?>?$var.log?##?將?curl?請求結(jié)果輸出到文件中以便后續(xù)分析
done
前期我們業(yè)務(wù)用 PHP 的居多,不少爬蟲請求都是在 PHP 中處理的,在 PHP 中我們也可以通過調(diào)用 libcurl 來模擬 bash 中的 curl 請求,比如業(yè)務(wù)中有一個需要抓取每個城市的天氣狀況的需求,就可以用 PHP 調(diào)用 curl,一行代碼搞定!

看了兩個例子,是否覺得爬蟲不過如此,沒錯,業(yè)務(wù)中很多這種簡單的爬蟲實現(xiàn)可以應(yīng)付絕大多數(shù)場景的需求!
腦洞大開的爬蟲解決思路
按以上介紹的爬蟲思路可以解決日常多數(shù)的爬蟲需求,但有時候我們需要一些腦洞大開的思路,簡單列舉兩個
1、 去年運營同學給了一個天貓精選的有關(guān)奶粉的 url 的鏈接
https://m.tmall.com/mblist/de_9n40_AVYPod5SU93irPS-Q.html,他們希望能提取此文章的信息,同時找到天貓精選中所有提到奶粉關(guān)鍵字的文章并提取其內(nèi)容, 這就需要用到一些搜索引擎的高級技巧了, 我們注意到,天貓精選的 url 是以以下形式構(gòu)成的
https://m.tmall.com/mblist/de_?+?每篇文章獨一無二的簽名
利用搜索引擎技巧我們可以輕松搞定運營的這個需求
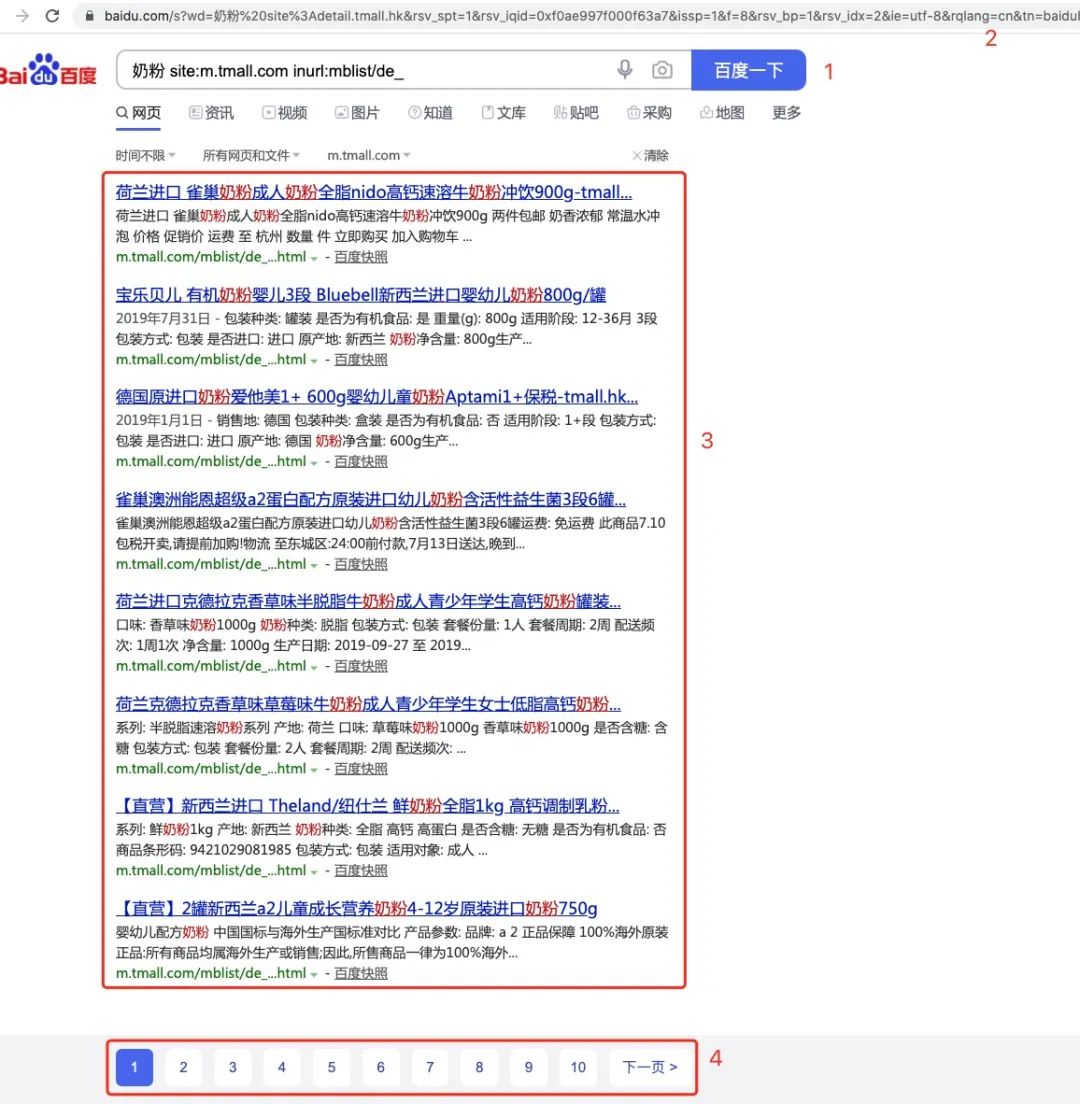
對照圖片,步驟如下:
首先我們用在百度框輸入高級查詢語句「奶粉 site:m.tmall.com inurl:mblist/de_」,點擊搜索,就會顯示出此頁中所有天貓精選中包含奶粉的文章 title 注意地址欄中瀏覽器已經(jīng)生成了搜索的完整 url,拿到這個 url 后,我們就可以去請求此 url,此時會得到上圖中包含有 3, 4 這兩塊的 html 文件 拿到步驟 2 中獲取的 html 文件后,在區(qū)域 3 每一個標題其實對應(yīng)著一個 url(以 ..... )的形式存在,根據(jù)正則表達式就可以獲取每個標題對應(yīng)的 url,再請求這些 url 即可獲取對應(yīng)的文章信息。 同理,拿到步驟 2 中獲取的 html 文件后,我們可以獲取區(qū)域 4 每一頁對應(yīng)的 url,再依次請求這些 url,然后重復步驟 2,即可獲取每一頁天貓精選中包含有奶粉的文章
通過這種方式我們也巧妙地實現(xiàn)了運營的需求,這種爬蟲獲取的數(shù)據(jù)是個 html 文件,不是 JSON 這些結(jié)構(gòu)化數(shù)據(jù),我們需要從 html 中提取出相應(yīng)的 url 信息(存在 標簽里),可以用正則,也可以用 xpath 來提取。
比如 html 中有如下 div 元素
<div?id="test1">大家好!div>
可以用以下的 xpath 來提取
data?=?selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把「大家好!」提取出來,需要注意的是在這種場景中,「依然不需要使用 Scrapy 這種復雜的框架」,在這種場景下,由于數(shù)據(jù)量不大,使用單線程即可滿足需求,在實際生產(chǎn)上我們用 php 實現(xiàn)即可滿足需求
2、 某天運營同學又提了一個需求,想爬取美拍的視頻
通過抓包我們發(fā)現(xiàn)美拍每個視頻的 url 都很簡單,輸入到瀏覽器查看也能正常看視頻,于是我們想當然地認為直接通過此 url 即可下載視頻,但實際我們發(fā)現(xiàn)此 url 是分片的(m3u8,為了優(yōu)化加載速度而設(shè)計的一種播放多媒體列表的檔案格式),下載的視頻不完整,后來我們發(fā)現(xiàn)打開`http://www.flvcd.com/`網(wǎng)站
輸入美拍地址轉(zhuǎn)化一下就能拿到完整的視頻下載地址

「如圖示:點擊「開始GO!」后就會開始解析視頻地址并拿到完整的視頻下載地址」
進一步分析這個「開始GO!」按鈕對應(yīng)的請求是「http://www.flvcd.com/parse.php?format=&kw= + 視頻地址」,所以只要拿到美拍的視頻地址,再調(diào)用 flvcd 的視頻轉(zhuǎn)換請求即可拿到完整的視頻下載地址,通過這種方式我們也解決了無法拿到美拍完整地址的問題。
復雜的爬蟲設(shè)計
上文我們要爬取的數(shù)據(jù)相對比較簡單, 數(shù)據(jù)屬于拿來即用型,實際上我們要爬取的數(shù)據(jù)大部分是非結(jié)構(gòu)化數(shù)據(jù)(html 網(wǎng)頁等),需要對這些數(shù)據(jù)做進一步地處理(爬蟲中的數(shù)據(jù)清洗階段),而且每個我們爬取的數(shù)據(jù)中也很有可能包含著大量待爬取網(wǎng)頁的 url,也就是說需要有 url 隊列管理,另外請求有時候還需求登錄,每個請求也需要添加 Cookie,也就涉及到 Cookie 的管理,在這種情況下考慮 Scrapy 這樣的框架是必要的!不管是我們自己寫的,還是類似 Scrapy 這樣的爬蟲框架,基本上都離不開以下模塊的設(shè)計
url 管理器
網(wǎng)頁(HTML)下載器, 對應(yīng) Python 中的urllib2, requests等庫
(HTML)解析器,主要有兩種方式來解析
下圖詳細解釋了各個模塊之間是如何配合使用的
正則表達式 以css, xpath為代表的結(jié)構(gòu)化解析(即將文檔以DOM樹的形式重新組織,通過查找獲取節(jié)點進而提取數(shù)據(jù)的方式), Python中的 html.parser,BeautifulSoup,lxml 皆是此類范疇
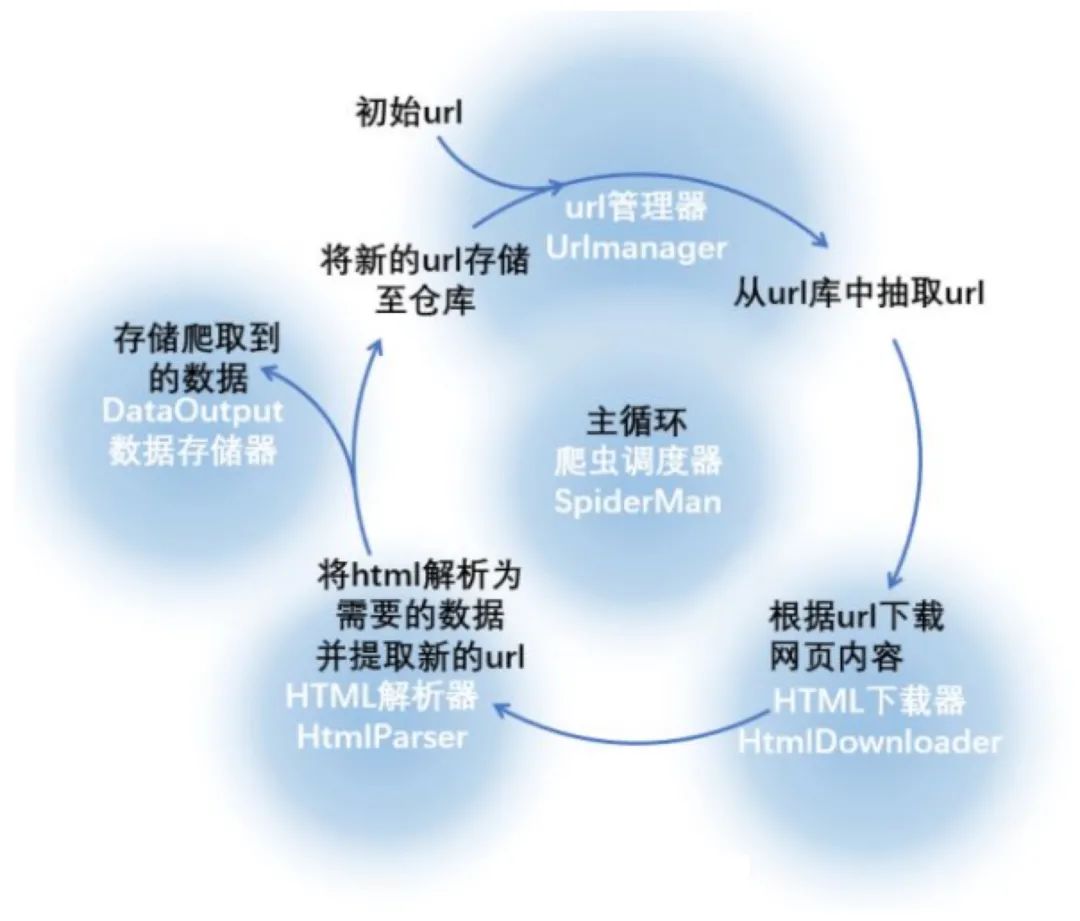
首先調(diào)度器會詢問 url 管理器是否有待爬取的 url 如果有,則獲取出其中的 url 傳給下載器進行下載 下載器下載完內(nèi)容后會將其傳給解析器做進一步的數(shù)據(jù)清洗,這一步除了會提取出有價值的數(shù)據(jù),還會提取出待爬取的URL以作下一次的爬取 調(diào)度器將待爬取的URL放到URL管理器里,將有價值的數(shù)據(jù)入庫作后續(xù)的應(yīng)用 以上過程會一直循環(huán),直到再無待爬取URL
可以看到,像以上的爬蟲框架,如果待爬取 URL 很多,要下載,解析,入庫的工作就很大(比如我們有個類似大眾點評的業(yè)務(wù),需要爬取大眾點評的數(shù)據(jù),由于涉及到幾百萬量級的商戶,評論等爬取,數(shù)據(jù)量巨大!),就會涉及到多線程,分布式爬取,用 PHP 這種單線程模型的語言來實現(xiàn)就不合適了,Python 由于其本身支持多線程,協(xié)程等特性,來實現(xiàn)這些比較復雜的爬蟲設(shè)計就綽綽有余了,同時由于 Python 簡潔的語法特性,吸引了一大波人寫了很多成熟的庫,各種庫拿來即用,很是方便,大名鼎鼎的 Scrapy 框架就是由于其豐富的插件,易用性俘獲了大批粉絲,我們的大部分爬蟲業(yè)務(wù)都是用的scrapy來實現(xiàn)的,所以接下來我們就簡要介紹一下 Scrapy,同時也來看看一個成熟的爬蟲框架是如何設(shè)計的。
我們首先要考慮一下爬蟲在爬取數(shù)據(jù)過程中會可能會碰到的一些問題,這樣才能明白框架的必要性以后我們自己設(shè)計框架時該考慮哪些點
url 隊列管理:比如如何防止對同一個 url 重復爬取(去重),如果是在一臺機器上可能還好,如果是分布式爬取呢 Cookie 管理:有一些請求是需要帳號密碼驗證的,驗證之后需要用拿到的 Cookie 來訪問網(wǎng)站后續(xù)的頁面請求,如何緩存住 Cookie 以便后續(xù)進一步的操作 多線程管理:前面說了如果待爬取URL很多的話,加載解析的工作是很大的,單線程爬取顯然不可行,那如果用多線程的話,管理又是一件大麻煩 User-Agent 與動態(tài)代理的管理: 目前的反爬機制其實也是比較完善的,如果我們用同樣的UA,同樣的IP不節(jié)制地連續(xù)對同一個網(wǎng)站多次請求,很可能立馬被封, 此時我們就需要使用 random-ua ,動態(tài)代理來避免被封 動態(tài)生成數(shù)據(jù)的爬取:一般通過 GET 請求獲取的網(wǎng)頁數(shù)據(jù)是包含著我們需要的數(shù)據(jù)的,但有些數(shù)據(jù)是通過 Ajax 請求動態(tài)生成,這樣的話該如何爬取 DEBUG 爬蟲管理平臺: 爬蟲任務(wù)多時,如何查看和管理這些爬蟲的狀態(tài)和數(shù)據(jù)
從以上的幾個點我們可以看出寫一個爬蟲框架還是要費不少功夫的,幸運的是,scrapy 幫我們幾乎完美地解決了以上問題,讓我們只要專注于寫具體的解析入庫邏輯即可, 來看下它是如何實現(xiàn)以上的功能點的
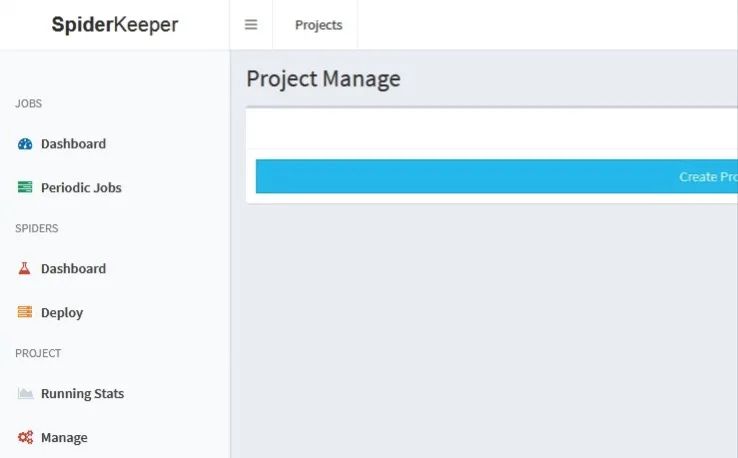
url 隊列管理: 使用 scrapy-redis 插件來做 url 的去重處理,利用 redis 的原子性可以輕松處理url重復問題 Cookie管理: 只要做一次登錄校驗,就會緩存住Cookie,在此后的請求中自動帶上此Cookie,省去了我們自己管理的煩惱 多線程管理: 只要在中間件中指定線程次數(shù) CONCURRENT_REQUESTS = 3,scrapy就可以為我們自己管理多線程操作,無需關(guān)心任何的線程創(chuàng)建毀滅生命周期等復雜的邏輯User-Agent與動態(tài)代理的管理: 使用 random-useragent插件為每一次請求隨機設(shè)置一個UA,使用螞蟻(mayidaili.com)等代理為每一個請求頭都加上proxy這樣我們的 UA 和 IP 每次就基本都不一樣了,避免了被封的窘境動態(tài)數(shù)據(jù)(通過 ajax 等生成)爬取: 使用 Selenium + PhantomJs來抓取抓動態(tài)數(shù)據(jù)DEBUG: 如何有效測試爬取數(shù)據(jù)是否正確非常重要,一個不成熟的框架很可能在我們每次要驗證用 xpath,正則等獲取數(shù)據(jù)是否正確時每一次都會重新去下載網(wǎng)頁,效率極低,但Scray-Shell 提供了很友好的設(shè)計,它會先下載網(wǎng)頁到內(nèi)存里,然后你在 shell 做各種 xpath 的調(diào)試,直到測試成功! 使用 SpiderKeeper+Scrapyd 來管理爬蟲, GUI 操作,簡單易行
可以看到 Scrapy 解決了以上提到的主要問題,在爬取大量數(shù)據(jù)時能讓我們專注于寫爬蟲的業(yè)務(wù)邏輯,無須關(guān)注 Cookie 管理,多線程管理等細節(jié),極大地減輕了我們的負擔,很容易地做到事半功倍!
(注意! Scrapy 雖然可以使用 Selenium + PhantomJs 來抓取動態(tài)數(shù)據(jù),但隨著 Google 推出的 puppeter 的橫空出世,PhantomJs 已經(jīng)停止更新了,因為 Puppeter 比 PhantomJS 強大太多,所以如果需要大量地抓取動態(tài)數(shù)據(jù),需要考慮性能方面的影響,Puppeter 這個 Node 庫絕對值得一試,Google 官方出品,強烈推薦)
理解了 Scrapy 的主要設(shè)計思路與功能,我們再來看下如何用 Scrapy 來開發(fā)我們某個音視頻業(yè)務(wù)的爬蟲項目,來看一下做一個音視頻爬蟲會遇到哪些問題
音視頻爬蟲實戰(zhàn)
一、先從幾個方面來簡單介紹我們音視頻爬蟲項目的體系
1、四個主流程
爬取階段 資源處理(包括音頻,視頻,圖片下載及處理) 正式入庫 后處理階段(類似去水印)
2、目前支持的功能點
各類視頻音頻站點的爬取(喜馬拉雅,愛奇藝,優(yōu)酷,騰訊,兒歌點點等) 主流視頻音頻站點的內(nèi)容同步更新(喜馬拉雅,優(yōu)酷) 視頻去水印(視頻 logo) 視頻截圖(視頻內(nèi)容無封面) 視頻轉(zhuǎn)碼適配(flv 目前客戶端不支持)
3、體系流程分布圖
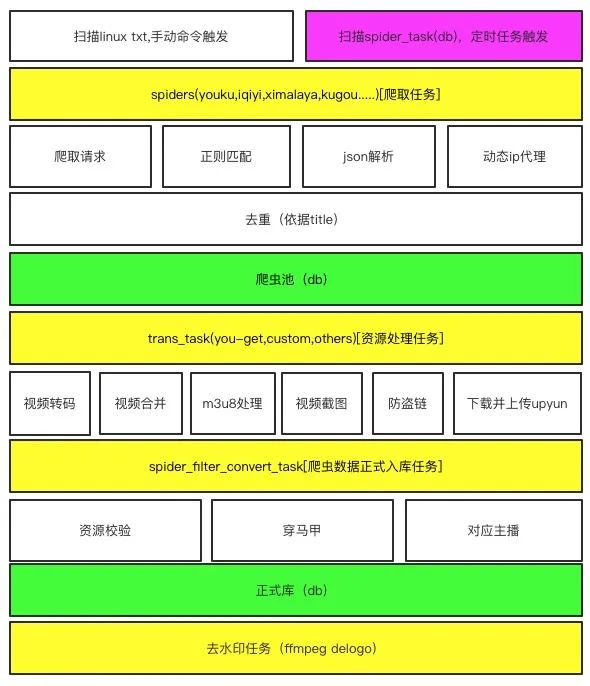
二、分步來講下細節(jié)
1. 爬蟲框架的技術(shù)選型
說到爬蟲,大家應(yīng)該會很自然與 python 劃上等號,所以我們的技術(shù)框架就從 python 中比較脫穎而出的三方庫選。scrapy 就是非常不錯的一款。相信很多其他做爬蟲的小伙伴也都體驗過這個框架。
那么說說這個框架用了這么久感受最深的幾個優(yōu)點:
request 觸發(fā)底層采用的是 python 自帶的 yied 協(xié)程,可以節(jié)省內(nèi)容的同時,回調(diào)式的編程方式也顯得優(yōu)雅舒適 對于 html 內(nèi)容的高效篩選處理能力,selecter 的 xpath 真的很好用 由于迭代時間已經(jīng)很長了,具備了很完善的擴展 api,例如:middlewares 就可以全局 hook 很多事件點,動態(tài) ip 代理就可以通過 hook request_start 實現(xiàn)
2. 爬蟲池 db 的設(shè)計
爬蟲池 db 對于整個爬取鏈路來說是非常重要的關(guān)鍵存儲節(jié)點,所以在早教這邊也是經(jīng)歷了很多次的字段更迭。
最初我們的爬蟲池 db 表只是正式表的一份拷貝,存儲內(nèi)容完全相同,在爬取完成后,copy 至正式表,然后就失去相應(yīng)的關(guān)聯(lián)。這時候的爬蟲池完全就是一張草稿表,里面有很多無用的數(shù)據(jù)。
后來發(fā)現(xiàn)運營需要看爬蟲的具體來源,這時候爬蟲池里面即沒有網(wǎng)站源鏈接,也無法根據(jù)正式表的專輯 id 對應(yīng)到爬蟲池的數(shù)據(jù)內(nèi)容。所以,爬蟲池 db 做出了最重要的一次改動。首先是建立爬蟲池數(shù)據(jù)與爬取源站的關(guān)聯(lián),即source_link 與 source_from 字段,分別代表內(nèi)容對應(yīng)的網(wǎng)站原鏈接以及來源聲明定義。第二步則是建立爬蟲池內(nèi)容與正式庫內(nèi)容的關(guān)聯(lián),為了不影響正式庫數(shù)據(jù),我們添加 target_id 對應(yīng)到正式庫的內(nèi)容 id 上。此時,就可以滿足告知運營爬取內(nèi)容具體來源的需求了。
后續(xù)運營則發(fā)現(xiàn),在大量的爬蟲數(shù)據(jù)中篩選精品內(nèi)容需要一些源站數(shù)據(jù)的參考值,例如:源站播放量等,此時爬蟲池db 和正式庫 db 存儲內(nèi)容正式分化,爬蟲池不再只是正式庫的一份拷貝,而是代表源站的一些參考數(shù)據(jù)以及正式庫的一些基礎(chǔ)數(shù)據(jù)。
而后來的同步更新源站內(nèi)容功能,也是依賴這套關(guān)系可以很容易的實現(xiàn)。
整個過程中,最重要的是將本來毫無關(guān)聯(lián)的 ?「爬取源站內(nèi)容」 、 ?「爬蟲池內(nèi)容」 、 「正式庫內(nèi)容」 三個區(qū)塊關(guān)聯(lián)起來。
3. 為什么會產(chǎn)生資源處理任務(wù)
本來的話,資源的下載以及一些處理應(yīng)該是在爬取階段就可以一并完成的,那么為什么會單獨產(chǎn)生資源處理這一流程。
首先,第一版的早教爬蟲體系里面確實沒有這一單獨的步驟,是在scrapy爬取過程中串行執(zhí)行的。但是后面發(fā)現(xiàn)的缺點是:
scrapy 自帶的 download pipe 不太好用,而且下載過程中并不能并行下載,效率較低 由于音視頻文件較大,合并資源會有各種不穩(wěn)定因素,有較大概率出現(xiàn)下載失敗。失敗后會同步丟失掉爬取信息。 串行執(zhí)行的情況下,會失去很多擴展性,重跑難度大。
針對以上的問題,我們增加了爬蟲表中的中間態(tài),即資源下載失敗的狀態(tài),但保留已爬取的信息。然后,增加獨立的資源處理任務(wù),采用 python 的多線程進行資源處理。針對這些失敗的內(nèi)容,會定時跑資源處理任務(wù),直到成功為止。(當然一直失敗的,就需要開發(fā)根據(jù)日志排查問題了)
4. 說說為什么水印處理不放在資源處理階段,而在后處理階段(即正式入庫后)
首先需要了解我們?nèi)ニ〉脑硎怯?ffmpeg 的 delogo 功能,該功能不像轉(zhuǎn)換視頻格式那樣只是更改封裝。它需要對整個視頻進行重新編碼,所以耗時非常久,而且對應(yīng)于 cpu 的占用也很大。
基于以上,如果放在資源處理階段,會大大較低資源轉(zhuǎn)移至 upyun 的效率,而且光優(yōu)酷而言就有不止 3 種水印類型,對于整理規(guī)則而言就是非常耗時的工作了,這個時間消耗同樣會降低爬取工作的進行。而首先保證資源入庫,后續(xù)進行水印處理,一方面,運營可以靈活控制上下架,另一方面,也是給了開發(fā)人員足夠的時間去整理規(guī)則,還有就是,水印處理出錯時,還存在源視頻可以恢復。
5. 如何去除圖片水印
不少爬蟲抓取的圖片是有水印的,目前沒發(fā)現(xiàn)完美的去水印方法,可使用的方法:
原始圖片查找,一般網(wǎng)站都會保存原始圖和加水印圖,如果找不到原始鏈接就沒辦法 裁剪法,由于水印一般是在圖片邊角,如果對于被裁減的圖片是可接受的,可以將包含水印部分直接按比例裁掉 使用 opencv 庫處理,調(diào)用 opencv 這種圖形庫進行圖片類似PS的圖片修復,產(chǎn)生的效果也差不多,遇到復雜圖形修復效果不好。
三、遇到的問題和解決方案
資源下載階段經(jīng)常出現(xiàn)中斷或失敗等問題【方案:將資源下載及相關(guān)處理從爬取過程中獨立出來,方便任務(wù)重跑】 雖然是不同平臺,但是重復資源太多,特別是視頻網(wǎng)站【方案:資源下載前根據(jù)title匹配,完全匹配則過濾,省下了多余的下載時間消耗】 大量爬取過程中,會遇到ip被封的情況【方案:動態(tài) ip 代理】 大型視頻網(wǎng)站資源獲取規(guī)則頻繁替換(加密,視頻切割,防盜鏈等),開發(fā)維護成本高【方案:you-get 三方庫,該庫支持大量的主流視頻網(wǎng)站的爬取,大大減少開發(fā)維護成本】 app相關(guān)爬取被加密【方案:反編譯】 優(yōu)酷和騰訊視頻會有 logo【方案:ffmpeg delogo 功能】 爬過來的內(nèi)容沒有主播關(guān)聯(lián)像盜版【方案:在內(nèi)容正式入庫時,給內(nèi)容穿上主播馬甲】 爬取源站內(nèi)容仍在更新中,但是我們的平臺內(nèi)容無法更新【方案:db 存入原站鏈接,根據(jù)差異性進行更新】 類似優(yōu)酷,愛奇藝等主流視頻網(wǎng)站的專輯爬取任務(wù)媒介存于服務(wù)器文本文件中,并需開發(fā)手動命令觸發(fā),耗費人力【方案:整合腳本邏輯,以 db 為媒介,以定時任務(wù)檢測觸發(fā)】 運營需要添加一些類似原站播放量等的數(shù)據(jù)到運營后臺顯示,作為審核,加精,置頂?shù)炔僮鞯囊罁?jù)【方案:之前爬蟲表在將數(shù)據(jù)導入正式表后失去關(guān)聯(lián),現(xiàn)在建立起關(guān)聯(lián),在爬蟲表添加爬蟲原站相關(guān)數(shù)據(jù)字段】 由于自己的很多資源是爬過來的,所以資源的安全性和反扒就顯得很重要,那么怎么保證自己資源在接口吐出后仍然安全【方案:upyun的防盜鏈空間,該空間下的資源地址有相應(yīng)的時效性】 接口中沒有媒體文件相關(guān)信息,而自己平臺需要,例如:時長【方案:ffmpeg 支持的媒體文件解析】 下載后的視頻很多在客戶端無法播放【方案:在資源上傳 upyun 前,進行格式和碼率驗證,不符合則進行相應(yīng)的轉(zhuǎn)碼】
四、最后做下總結(jié)
對于我們視頻的音視頻爬蟲代碼體系,不一定能通用于所有的業(yè)務(wù)線,但是同類問題的思考與解決方案確是可以借鑒與應(yīng)用于各個業(yè)務(wù)線的,相信項目主對大家會有不少啟發(fā)
爬蟲管理平臺
當爬蟲任務(wù)變得很多時,ssh+crontab 的方式會變得很麻煩, 需要一個能隨時查看和管理爬蟲運行狀況的平臺,
SpiderKeeper+Scrapyd 目前是一個現(xiàn)成的管理方案,提供了不錯的UI界面。功能包括:
1.爬蟲的作業(yè)管理:定時啟動爬蟲進行數(shù)據(jù)抓取,隨時啟動和關(guān)閉爬蟲任務(wù)
2.爬蟲的日志記錄:爬蟲運行過程中的日志記錄,可以用來查詢爬蟲的問題
3.爬蟲運行狀態(tài)查看:運行中的爬蟲和爬蟲運行時長查看
總結(jié)
從以上的闡述中,我們可以簡單地總結(jié)一下爬蟲的技術(shù)選型
如果是結(jié)構(gòu)化數(shù)據(jù)(JSON 等),我們可以使用 curl,PHP 這些單線程模塊的語言來處理即可 如果是非結(jié)構(gòu)化數(shù)據(jù)(html 等),此時 bash 由于無法處理這類數(shù)據(jù),需要用正則, xpath 來處理,可以用 php, BeautifulSoup 來處理,當然這種情況僅限于待爬取的 url 較少的情況 如果待爬取的 url 很多,單線程無法應(yīng)付,就需要多線程來處理了,又或者需要 Cookie 管理,動態(tài) ip 代理等,這種情況下我們就得考慮 scrapy 這類高性能爬蟲框架了
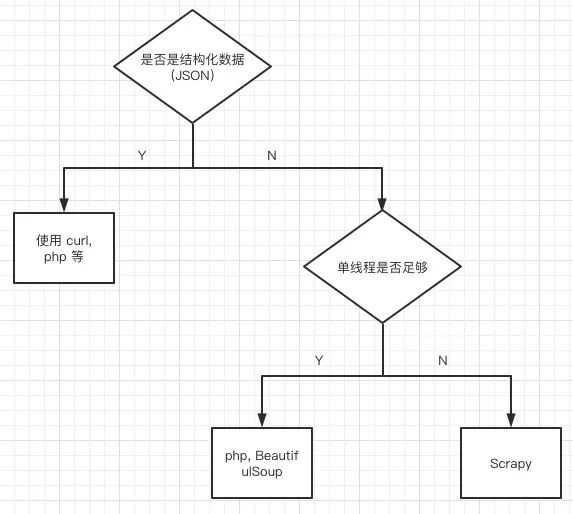
根據(jù)業(yè)務(wù)場景的復雜度選擇相應(yīng)的技術(shù)可以達到事半功倍的效果。我們在技術(shù)選型時一定要考慮實際的業(yè)務(wù)場景。
完
? ? ? ?
 ???
???覺得不錯,點個在看~
