來源:Open AI
編輯:小勻 Priscilla
【新智元導讀】剛剛,OpenAI 發(fā)布Codex的改進版本,將把API以私有測試版的形式發(fā)布。Codex是可以將自然語言轉(zhuǎn)換為代碼的AI系統(tǒng),也就是那個為 GitHub Copilot提供「馬達」的模型。口頭命令令AI生成代碼的時代到來了。
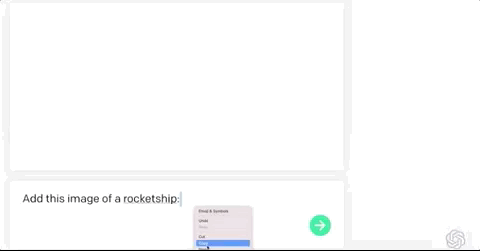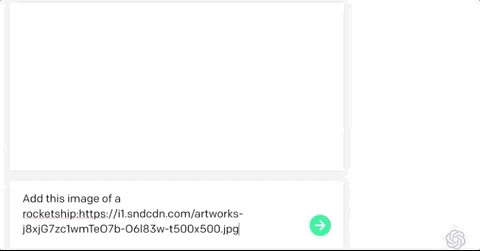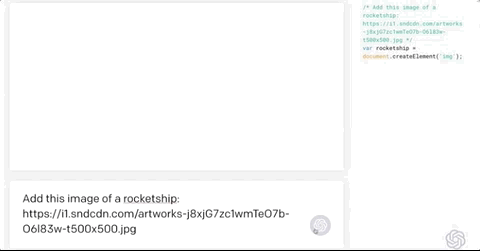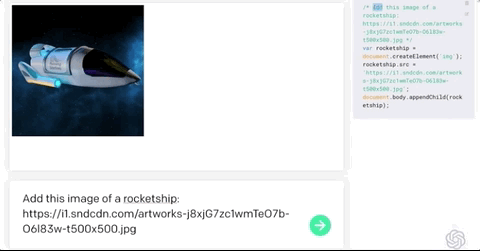
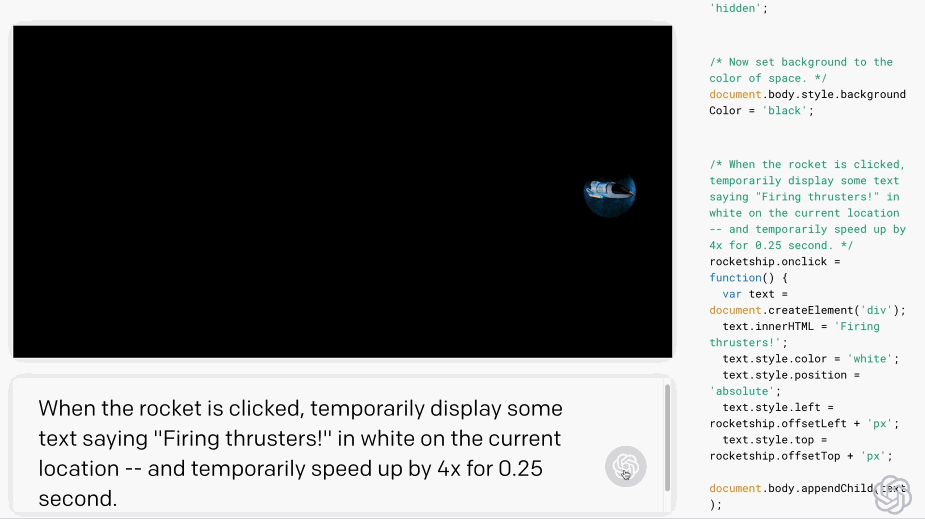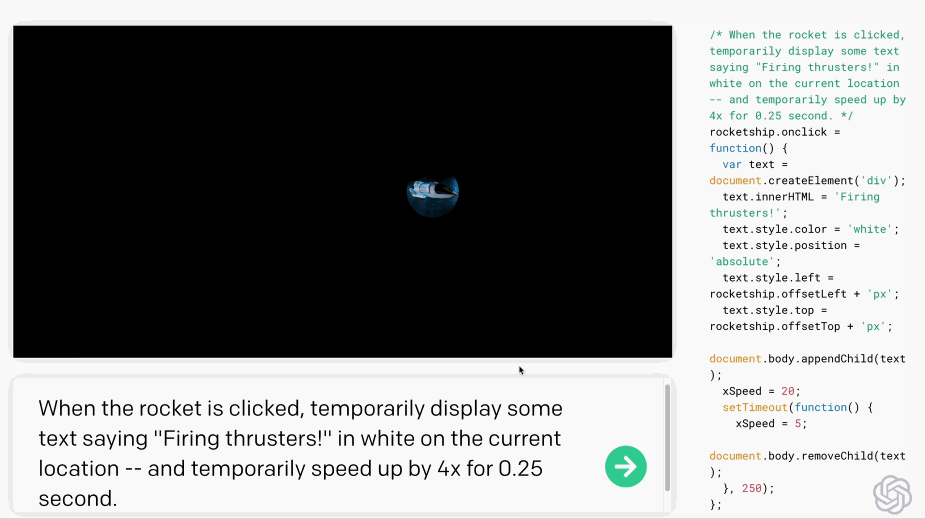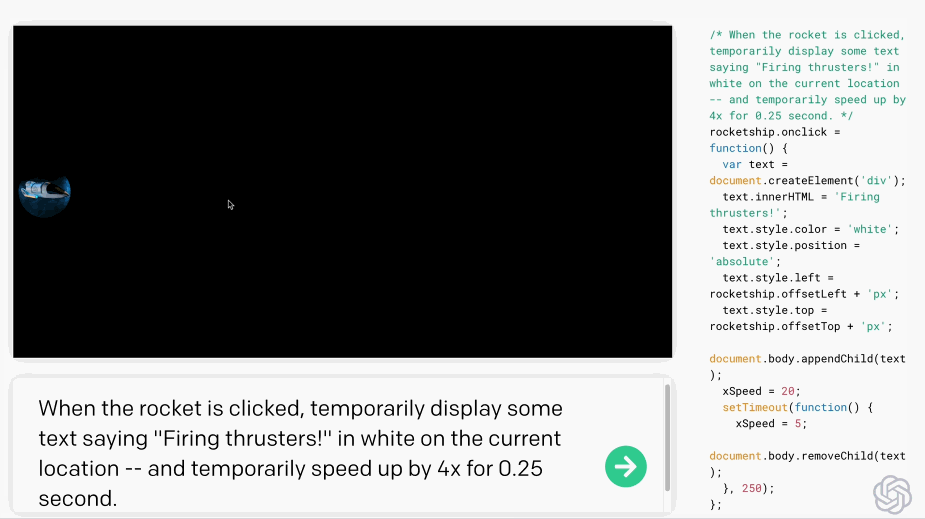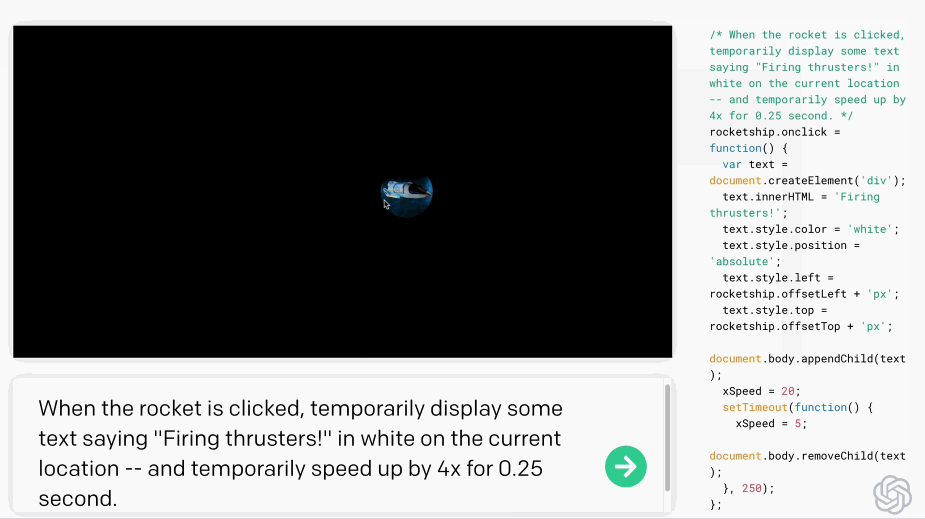
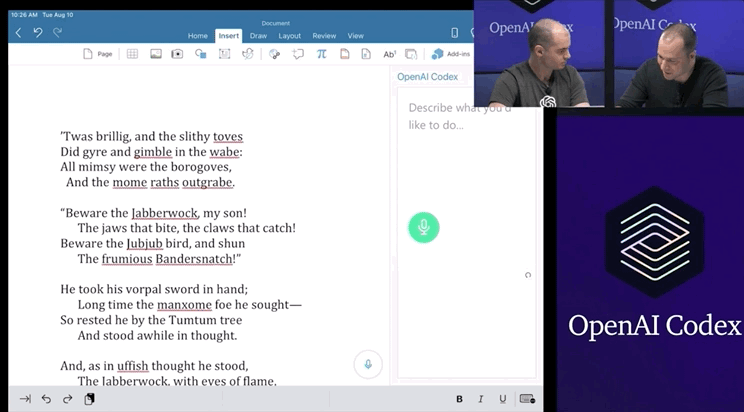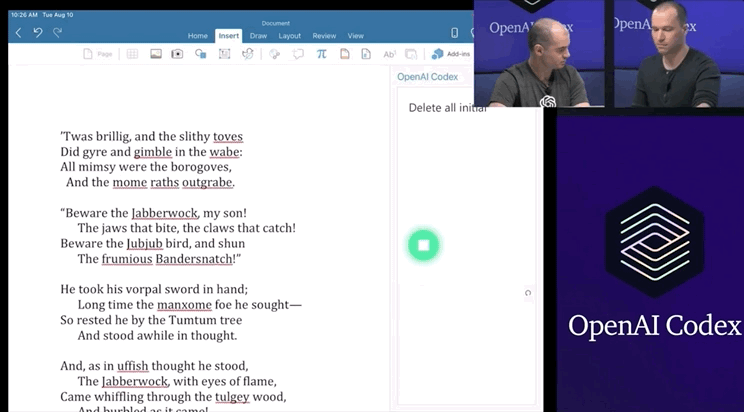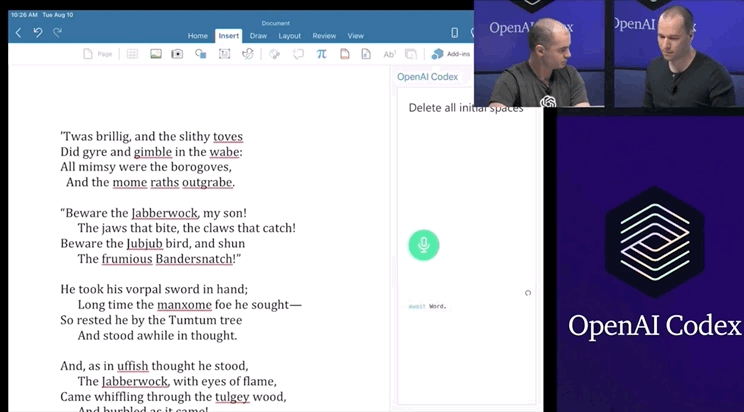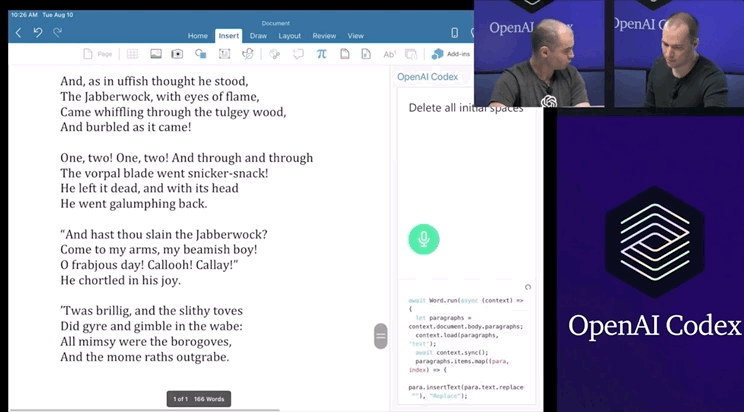
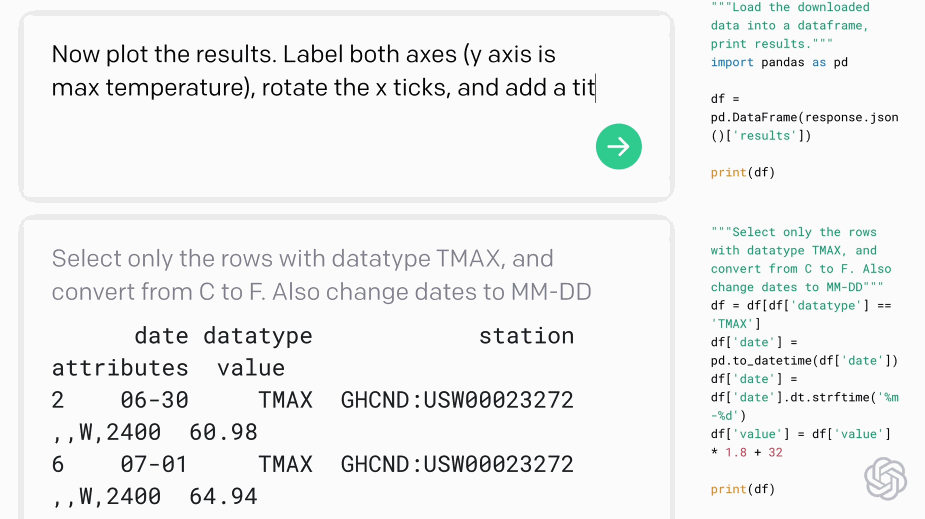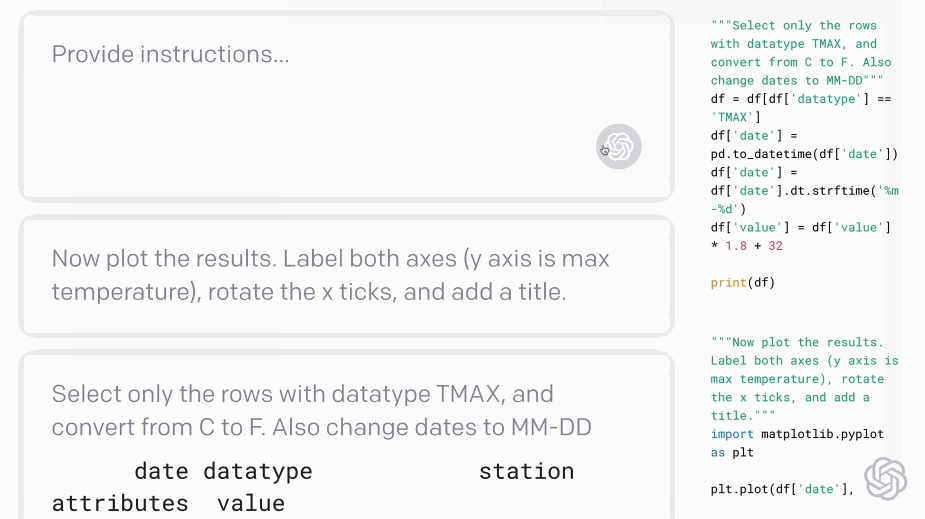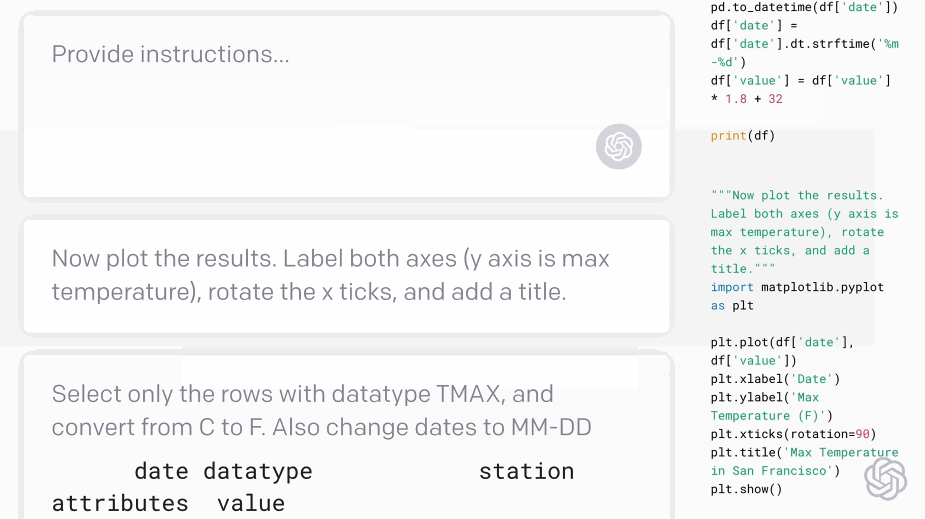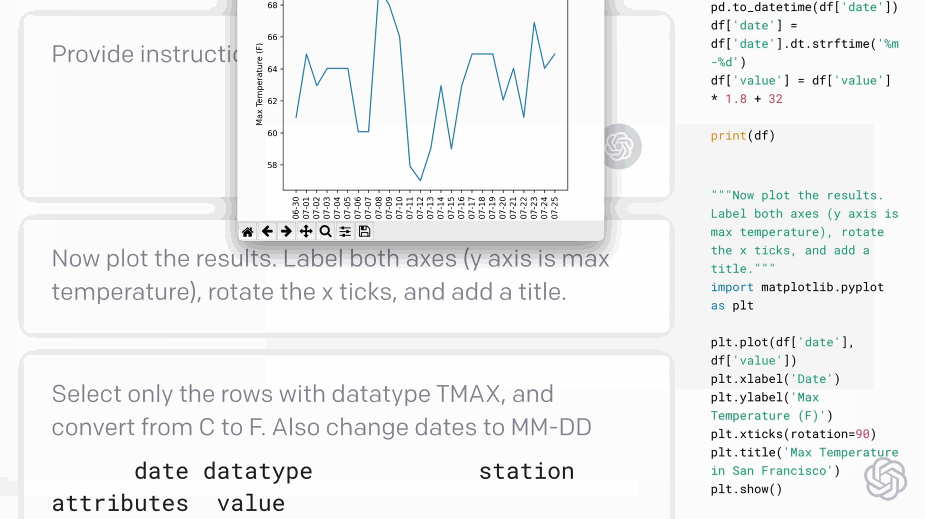
只要你對這個AI發(fā)號施令,它就會將英語翻譯成代碼。add this image of a rocketship隨后,你的雙手離開鍵盤,AI會自動編程,這張火箭照片就被添加進來了:這就是OpenAI發(fā)布的一種新機器學習工具——Codex,可以將英語翻譯成代碼。哦對了,Codex也正是為GitHub Copilot提供動力的模型。剛剛,OpenAI發(fā)布了Codex的改進版本,API以私有測試版的形式發(fā)布出來,可以將自然語言轉(zhuǎn)換為代碼的AI系統(tǒng)。從GPT-3到DALL·E,不久前大熱的Copilot(背后也依賴Open AI的技術),OpenAI這是要徹底「砸了」程序員的飯碗嗎?然而,OpenAI的CTO和聯(lián)合創(chuàng)始人Greg Brockman則表示:「它消除了程序員繁瑣的工作。」
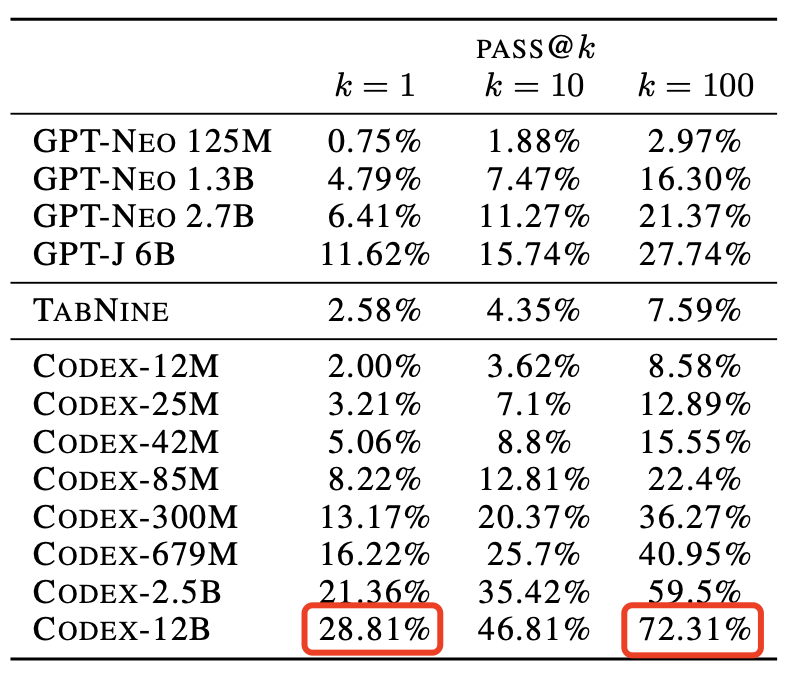
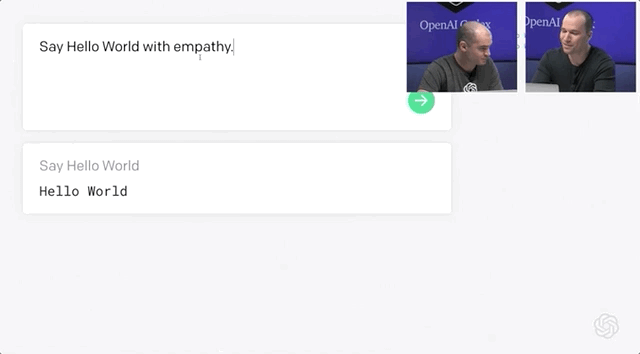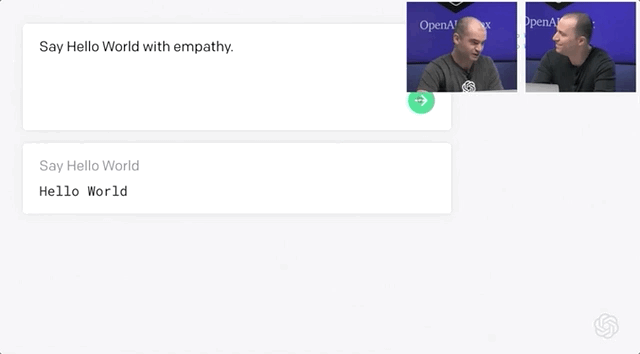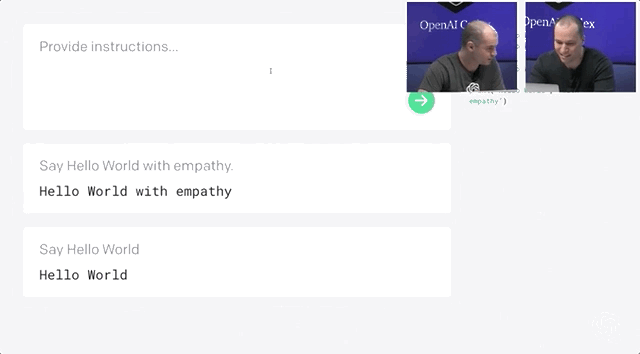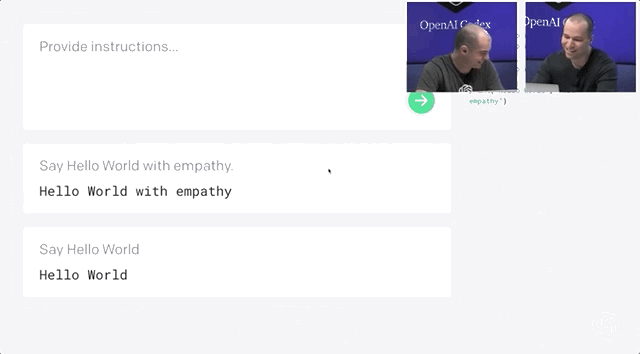
Codex不僅能夠收到指令后自行編程,還能夠開發(fā)個小游戲。問題不大,Open AI和微軟合作出了一個Word插件。研究人員用APPS數(shù)據(jù)集來測量不同語言模型的編碼挑戰(zhàn)能力。APPS含有5000次訓練和5000次代碼問題的測試。測試結(jié)果顯示,120億參數(shù)版的Codex能夠?qū)?/span>28.81%的問題給出正確答案。準確率遠遠超過「前浪」GPT-Neo和GPT-J。經(jīng)過不斷修正,最終Codex-12B的準確率提升到了72.31%!二、將這些小片段映射到現(xiàn)有的代碼中,不管它是一個庫、一個函數(shù)還是一個API。Codex的目的是讓編碼員在第一部分上花費更多時間,而不是第二部分。畢竟,大量的代碼都是在重復或直接抄襲別人之前所做的事情。當然,它可以是創(chuàng)造性的,但沒有人會在做基本的事情時發(fā)揮他們的想象力,比如部署一個網(wǎng)絡服務器來測試一點代碼。比如部署 Web 服務器來測試一些代碼。布羅克曼用一條簡單的線做到了這一點——「創(chuàng)建一個說明這一點的網(wǎng)頁」。利用Codex,一秒鐘后,就有十幾行JavaScript以完全標準的方式做了這件事。上面說了Codex不少優(yōu)點,可以幫助用戶使用新的代碼庫,減少上下文切換。但Open AI也承認,Codex還有許多不足之處。它的訓練集上有數(shù)十億行代碼,包括來自GitHub的Python代碼。多有經(jīng)驗的開發(fā)人員也不會遇到這么多代碼啊!但就算有這么多行代碼的訓練,計算機科學的學生可能比Codex-12B更能解決問題。比如Codex演示人員下了一個指令:Say Hello World with empathy除此之外,Open AI很實誠地在論文的預印本中指出Codex的其它缺點:因為互聯(lián)網(wǎng)上的訓練集或多或少帶有種族歧視,經(jīng)過訓練后的Codex也會帶有偏見。Codex的出現(xiàn)會對程序員的就業(yè)市場產(chǎn)生沖擊。大規(guī)模參數(shù)量還會產(chǎn)生大量碳足跡。目前Open AI Codex還處于私測階段,后續(xù)會繼續(xù)擴大規(guī)模。參考資料:
https://www.twitch.tv/videos/1114111652
https://arxiv.org/abs/2107.03374
https://openai.com/blog/openai-codex/#helloworld