
機器學習中的特征工程總結(jié)!
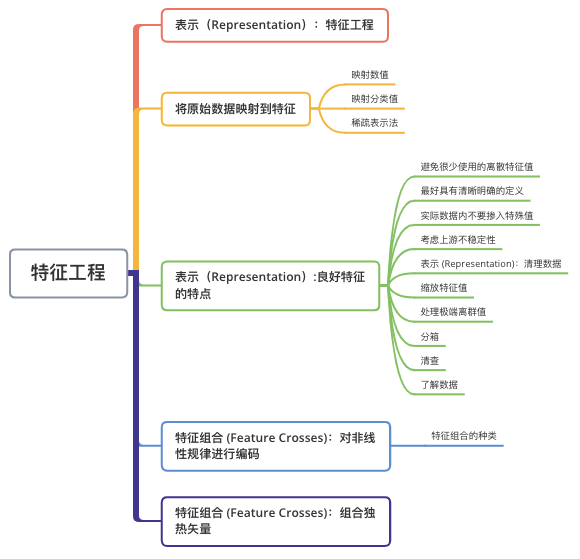
特征工程
傳統(tǒng)編程的關(guān)注點是代碼。在機器學習項目中,關(guān)注點變成了特征表示。也就是說,開發(fā)者通過添加和改善特征來調(diào)整模型。“Garbage in, garbage out”。對于一個機器學習問題,數(shù)據(jù)和特征往往決定了結(jié)果的上限,而模型、算法的選擇及優(yōu)化則是在逐步接近這個上限。特征工程,顧名思義,是指從原始數(shù)據(jù)創(chuàng)建特征的過程。
將原始數(shù)據(jù)映射到特征
許多機器學習模型都必須將特征表示為實數(shù)向量,因為特征值必須與模型權(quán)重相乘。
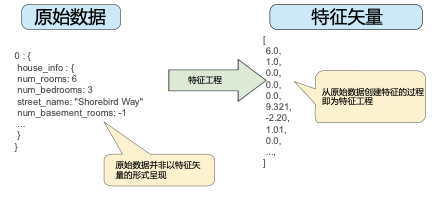
圖 1 左側(cè)表示來自輸入數(shù)據(jù)源的原始數(shù)據(jù),右側(cè)表示特征矢量,也就是組成數(shù)據(jù)集中樣本的浮點值集。特征工程指的是將原始數(shù)據(jù)轉(zhuǎn)換為特征矢量。進行特征工程預(yù)計需要大量時間。
映射數(shù)值
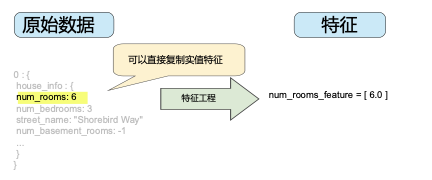
整數(shù)和浮點數(shù)據(jù)不需要特殊編碼,因為它們可以與數(shù)字權(quán)重相乘。如圖 2 所示,將原始整數(shù)值 6 轉(zhuǎn)換為特征值 6.0 并沒有多大的意義:
映射分類值
分類特征具有一組離散的可能值。例如,可能有一個名為 street_name 的特征,其中的選項包括:
{'Charleston Road', 'North Shoreline Boulevard', 'Shorebird Way','Rengstorff Avenue'}
由于模型不能將字符串與學習到的權(quán)重相乘,因此我們使用特征工程將字符串轉(zhuǎn)換為數(shù)字值。
要實現(xiàn)這一點,我們可以定義一個從特征值(我們將其稱為可能值的詞匯表)到整數(shù)的映射。世界上的每條街道并非都會出現(xiàn)在我們的數(shù)據(jù)集中,因此我們可以將所有其他街道分組為一個全部包羅的“其他”類別,稱為 OOV(out-of-vocabulary)分桶。
通過這種方法,我們可以按照以下方式將街道名稱映射到數(shù)字:
將 Charleston Road 映射到 0 將 North Shoreline Boulevard 映射到 1 將 Shorebird Way 映射到 2 將 Rengstorff Avenue 映射到 3 將所有其他街道 (OOV) 映射到 4
不過,如果我們將這些索引數(shù)字直接納入到模型中,將會造成一些可能存在問題的限制:
我們將學習適用于所有街道的單一權(quán)重。例如,如果我們學習到 street_name 的權(quán)重為 6,那么對于 Charleston Road,我們會將其乘以 0,對于 North Shoreline Boulevard 則乘以 1,對于 Shorebird Way 則乘以 2,依此類推。以某個使用 street_name 作為特征來預(yù)測房價的模型為例。根據(jù)街道名稱對房價進行線性調(diào)整的可能性不大,此外,這會假設(shè)你已根據(jù)平均房價對街道排序。我們的模型需要靈活地為每條街道學習不同的權(quán)重,這些權(quán)重將添加到利用其他特征估算的房價中。
我們沒有將 street_name 可能有多個值的情況考慮在內(nèi)。例如,許多房屋位于兩條街道的拐角處,因此如果模型包含單個索引,則無法在 street_name 值中對該信息進行編碼。
要去除這兩個限制,我們可以為模型中的每個分類特征創(chuàng)建一個二元向量來表示這些值,如下所述:
對于適用于樣本的值,將相應(yīng)向量元素設(shè)為 1。 將所有其他元素設(shè)為 0。
該向量的長度等于詞匯表中的元素數(shù)。當只有一個值為 1 時,這種表示法稱為獨熱編碼;當有多個值為 1 時,這種表示法稱為多熱編碼。
圖 3 所示為街道 Shorebird Way 的獨熱編碼。在此二元矢量中,代表 Shorebird Way 的元素的值為 1,而代表所有其他街道的元素的值為 0。
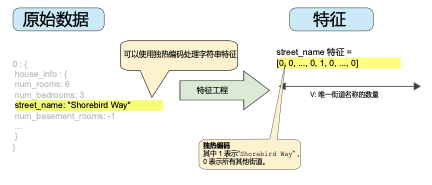
該方法能夠有效地為每個特征值(例如,街道名稱)創(chuàng)建布爾變量。采用這種方法時,如果房屋位于 Shorebird Way 街道上,則只有 Shorebird Way 的二元值為 1。因此,該模型僅使用 Shorebird Way 的權(quán)重。同樣,如果房屋位于兩條街道的拐角處,則將兩個二元值設(shè)為 1,并且模型將使用它們各自的權(quán)重。
稀疏表示法
假設(shè)數(shù)據(jù)集中有 100 萬個不同的街道名稱,你希望將其包含為 street_name 的值。如果直接創(chuàng)建一個包含 100 萬個元素的二元向量,其中只有 1 或 2 個元素為 ture,則是一種非常低效的表示法,在處理這些向量時會占用大量的存儲空間并耗費很長的計算時間。在這種情況下,一種常用的方法是使用稀疏表示法,其中僅存儲非零值。在稀疏表示法中,仍然為每個特征值學習獨立的模型權(quán)重,如上所述。
良好特征的特點
避免很少使用的離散特征值
良好的特征值應(yīng)該在數(shù)據(jù)集中出現(xiàn)大約 5 次以上。這樣一來,模型就可以學習該特征值與標簽是如何關(guān)聯(lián)的。也就是說,大量離散值相同的樣本可讓模型有機會了解不同設(shè)置中的特征,從而判斷何時可以對標簽很好地做出預(yù)測。
例如:house_type 特征可能包含大量樣本,其中它的值為 victorian:house_type: victorian;相反,如果某個特征的值僅出現(xiàn)一次或者很少出現(xiàn),則模型就無法根據(jù)該特征進行預(yù)測。例如,unique_house_id 就不適合作為特征,因為每個值只使用一次,模型無法從中學習任何規(guī)律:
unique_house_id: 8SK982ZZ1242Z
最好具有清晰明確的含義
每個特征對于項目中的任何人來說都應(yīng)該具有清晰明確的含義。例如,下面的房齡適合作為特征,可立即識別是以年為單位的房齡:
house_age: 27
相反,對于下方特征值的含義,除了創(chuàng)建它的工程師,其他人恐怕辨識不出:
house_age: 851472000
在某些情況下,混亂的數(shù)據(jù)(而不是糟糕的工程選擇)會導致含義不清晰的值。例如,以下 user_age 的來源沒有檢查值恰當與否:
user_age: 277
實際數(shù)據(jù)內(nèi)不要摻入特殊值
良好的浮點特征不包含超出范圍的異常斷點或特殊的值。例如,假設(shè)一個特征具有 0 到 1 之間的浮點值。那么,如下值是可以接受的:
quality_rating: 0.82
quality_rating: 0.37
不過,如果用戶沒有輸入 quality_rating,則數(shù)據(jù)集可能使用如下特殊值來表示不存在該值:
quality_rating: -1
為解決特殊值的問題,需將該特征轉(zhuǎn)換為兩個特征:
一個特征只存儲質(zhì)量評分,不含特殊值。 一個特征存儲布爾值,表示是否提供了 quality_rating。為該布爾值特征指定一個名稱,例如 is_quality_rating_defined。
考慮上游不穩(wěn)定性
特征的定義不應(yīng)隨時間發(fā)生變化。例如,下列值是有用的,因為城市名稱一般不會改變。(注意,我們?nèi)匀恍枰獙ⅰ?code style="font-size: 14px;word-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin: 0 2px;background-color: rgba(27,31,35,.05);font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(60, 112, 198);">br/sao_paulo”這樣的字符串轉(zhuǎn)換為獨熱矢量。)
city_id: "br/sao_paulo"
但收集由其他模型推理的值會產(chǎn)生額外成本。可能值“219”目前代表圣保羅,但這種表示在未來運行其他模型時可能輕易發(fā)生變化:
inferred_city_cluster: "219"
表示 (Representation):清理數(shù)據(jù)
蘋果樹結(jié)出的果子有品相上乘的,也有蟲蛀壞果。而高端便利店出售的蘋果是 100% 完美的水果。從果園到水果店之間,專門有人花費大量時間將壞蘋果剔除或給可以挽救的蘋果涂上一層薄薄的蠟。作為一名機器學習工程師,你將花費大量的時間挑出壞樣本并加工可以挽救的樣本。即使是非常少量的“壞蘋果”也會破壞掉一個大規(guī)模數(shù)據(jù)集。
縮放特征值
縮放是指將浮點特征值從自然范圍(例如 100 到 900)轉(zhuǎn)換為標準范圍(例如 0 到 1 或 -1 到 +1)。如果某個特征集只包含一個特征,則縮放可以提供的實際好處微乎其微或根本沒有。不過,如果特征集包含多個特征,則縮放特征可以帶來以下優(yōu)勢:
幫助梯度下降法更快速地收斂。 幫助避免“NaN 陷阱”。在這種陷阱中,模型中的一個數(shù)值變成 NaN(例如,當某個值在訓練期間超出浮點精確率限制時),并且模型中的所有其他數(shù)值最終也會因數(shù)學運算而變成 NaN。 幫助模型為每個特征確定合適的權(quán)重。如果沒有進行特征縮放,則模型會對范圍較大的特征投入過多精力。
你不需要對每個浮點特征進行完全相同的縮放。即使特征 A 的范圍是 -1 到 +1,同時特征 B 的范圍是 -3 到 +3,也不會產(chǎn)生什么惡劣的影響。不過,如果特征 B 的范圍是 5000 到 100000,你的模型會出現(xiàn)糟糕的響應(yīng)。
要縮放數(shù)值數(shù)據(jù),一種顯而易見的方法是將 [最小值,最大值] 以線性方式映射到較小的范圍,例如 [-1,+1]。另一種熱門的縮放策略是計算每個值的 Z 得分。Z 得分與距離均值的標準偏差相關(guān)。換言之:
scaledvalue "=("value"-"mean")/"stddev.
例如,給定以下條件:
均值 = 100 標準偏差 = 20 原始值 = 130
則:
scaled_value = (130 - 100) / 20
scaled_value = 1.5
使用 Z 得分進行縮放意味著,大多數(shù)縮放后的值將介于 -3 和 +3 之間,而少量值將略高于或低于該范圍。
處理極端離群值
下面的曲線圖表示的是加利福尼亞州住房數(shù)據(jù)集中稱為 roomsPerPerson 的特征。roomsPerPerson 值的計算方法是相應(yīng)地區(qū)的房間總數(shù)除以相應(yīng)地區(qū)的人口總數(shù)。該曲線圖顯示,在加利福尼亞州的絕大部分地區(qū),人均房間數(shù)為 1 到 2 間。不過,請看一下 x 軸。
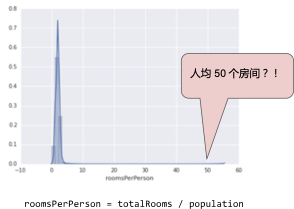
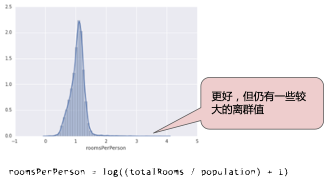
對數(shù)縮放可稍稍緩解這種影響,但仍然存在離群值這個大尾巴。我們來采用另一種方法。如果我們只是簡單地將 roomsPerPerson 的最大值“限制”為某個任意值(比如 4.0),會發(fā)生什么情況呢?
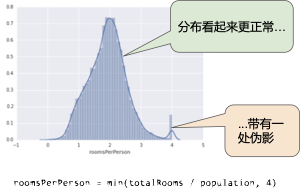
將特征值限制到 4.0 并不意味著我們會忽略所有大于 4.0 的值。而是說,所有大于 4.0 的值都將變成 4.0。這就解釋了 4.0 處的那個有趣的小峰值。盡管存在這個小峰值,但是縮放后的特征集現(xiàn)在依然比原始數(shù)據(jù)有用。
分箱
下面的曲線圖顯示了加利福尼亞州不同緯度的房屋相對普及率。注意集群 - 洛杉磯大致在緯度 34 處,舊金山大致在緯度 38 處。
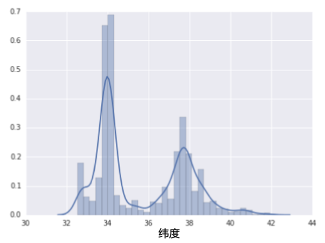
在數(shù)據(jù)集中,latitude 是一個浮點值。不過,在我們的模型中將 latitude 表示為浮點特征沒有意義。這是因為緯度和房屋價值之間不存在線性關(guān)系。例如,緯度 35 處的房屋并不比緯度 34 處的房屋貴 35/34(或更便宜)。但是,緯度或許能很好地預(yù)測房屋價值。為了將緯度變?yōu)橐豁棇嵱玫念A(yù)測指標,我們對緯度“分箱”,如下圖所示:
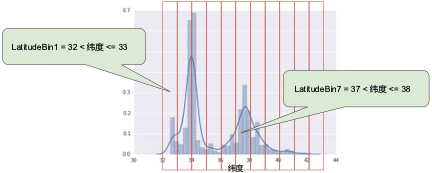
我們現(xiàn)在擁有 11 個不同的布爾值特征(LatitudeBin1、LatitudeBin2、…、LatitudeBin11),而不是一個浮點特征。擁有 11 個不同的特征有點不方便,因此我們將它們統(tǒng)一成一個 11 元素矢量。這樣做之后,我們可以將緯度 37.4 表示為:[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
分箱之后,我們的模型現(xiàn)在可以為每個緯度學習完全不同的權(quán)重。
為了簡單起見,我們在緯度樣本中使用整數(shù)作為分箱邊界。如果我們需要更精細的解決方案,我們可以每隔 1/10 個緯度拆分一次分箱邊界。添加更多箱可讓模型從緯度 37.4 處學習和維度 37.5 處不一樣的行為,但前提是每 1/10 個緯度均有充足的樣本可供學習。
另一種方法是按分位數(shù)分箱,這種方法可以確保每個桶內(nèi)的樣本數(shù)量是相等的。按分位數(shù)分箱完全無需擔心離群值。
清查
截至目前,我們假定用于訓練和測試的所有數(shù)據(jù)都是值得信賴的。在現(xiàn)實生活中,數(shù)據(jù)集中的很多樣本是不可靠的,原因有以下一種或多種:
缺失值。例如,有人忘記為某個房屋的年齡輸入值。 重復(fù)樣本。例如,服務(wù)器錯誤地將同一條記錄上傳了兩次。 不良標簽。例如,有人錯誤地將一顆橡樹的圖片標記為楓樹。 不良特征值。例如,有人輸入了多余的位數(shù),或者溫度計被遺落在太陽底下。
一旦檢測到存在這些問題,你通常需要將相應(yīng)樣本從數(shù)據(jù)集中移除,從而“修正”不良樣本。要檢測缺失值或重復(fù)樣本,你可以編寫一個簡單的程序。檢測不良特征值或標簽可能會比較棘手。
除了檢測各個不良樣本之外,你還必須檢測集合中的不良數(shù)據(jù)。直方圖是一種用于可視化集合中數(shù)據(jù)的很好機制。此外,收集如下統(tǒng)計信息也會有所幫助:
最大值和最小值 均值和中間值 標準偏差 考慮生成離散特征的最常見值列表。例如, country:uk的樣本數(shù)是否符合你的預(yù)期?language:jp是否真的應(yīng)該作為你數(shù)據(jù)集中的最常用語言?
了解數(shù)據(jù)
遵循以下規(guī)則:
記住你預(yù)期的數(shù)據(jù)狀態(tài)。 確認數(shù)據(jù)是否滿足這些預(yù)期(或者你可以解釋為何數(shù)據(jù)不滿足預(yù)期)。 仔細檢查訓練數(shù)據(jù)是否與其他來源(例如信息中心)的數(shù)據(jù)一致。
像處理任何任務(wù)關(guān)鍵型代碼一樣謹慎處理你的數(shù)據(jù)。良好的機器學習依賴于良好的數(shù)據(jù)。
特征組合:對非線性規(guī)律進行編碼
在圖 9 和圖 10 中,我們做出如下假設(shè):
藍點代表生病的樹。 橙點代表健康的樹。
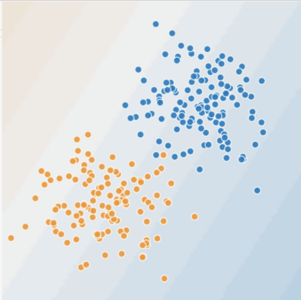
你可以畫一條線將生病的樹與健康的樹清晰地分開嗎?當然可以。這是個線性問題。這條線并不完美。有一兩棵生病的樹可能位于“健康”一側(cè),但你畫的這條線可以很好地做出預(yù)測。
現(xiàn)在,我們來看看下圖:
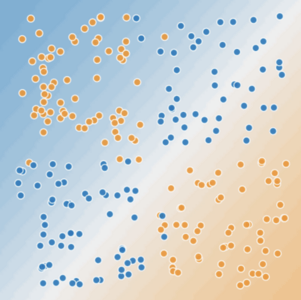
你可以畫一條直線將生病的樹與健康的樹清晰地分開嗎?不,你做不到。這是個非線性問題。你畫的任何一條線都不能很好地預(yù)測樹的健康狀況。
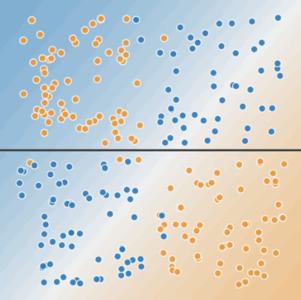
要想解決圖 10 所示的非線性問題,可以創(chuàng)建一個特征組合。特征組合是指通過將兩個或多個輸入特征相乘來對特征空間中的非線性規(guī)律進行編碼的合成特征。“cross”(組合)這一術(shù)語來自 cross product(向量積)。我們通過將x1與 x2組合來創(chuàng)建一個名為 x3的特征組合:
我們像處理任何其他特征一樣來處理這個新建的x3特征組合。線性公式變?yōu)椋?/p>
線性算法可以算出 w3的權(quán)重,就像算出 w1 和 w2 的權(quán)重一樣。換言之,雖然 w3 表示非線性信息,但你不需要改變線性模型的訓練方式來確定 w3的值。
特征組合的種類
我們可以創(chuàng)建很多不同種類的特征組合。例如:
[A X B]:將兩個特征的值相乘形成的特征組合。 [A x B x C x D x E]:將五個特征的值相乘形成的特征組合。 [A x A]:對單個特征的值求平方形成的特征組合。
通過采用隨機梯度下降法,可以有效地訓練線性模型。因此,在使用擴展的線性模型時輔以特征組合一直都是訓練大規(guī)模數(shù)據(jù)集的有效方法。
特征組合:組合獨熱矢量
到目前為止,我們已經(jīng)重點介紹了如何對兩個單獨的浮點特征進行特征組合。在實踐中,機器學習模型很少會組合連續(xù)特征。不過,機器學習模型卻經(jīng)常組合獨熱特征矢量,將獨熱特征矢量的特征組合視為邏輯連接。例如,假設(shè)我們具有以下兩個特征:國家/地區(qū)和語言。對每個特征進行獨熱編碼會生成具有二元特征的矢量,這些二元特征可解讀為 country=USA, country=France 或 language=English, language=Spanish。然后,如果你對這些獨熱編碼進行特征組合,則會得到可解讀為邏輯連接的二元特征,如下所示:
country:usa AND language:spanish
再舉一個例子,假設(shè)你對緯度和經(jīng)度進行分箱,獲得單獨的 5 元素特征矢量。例如,指定的緯度和經(jīng)度可以表示如下:
binned_latitude = [0, 0, 0, 1, 0] binned_longitude = [0, 1, 0, 0, 0]
假設(shè)你對這兩個特征矢量創(chuàng)建了特征組合:
binned_latitude X binned_longitude
此特征組合是一個 25 元素獨熱矢量(24 個 0 和 1 個 1)。該組合中的單個 1 表示緯度與經(jīng)度的特定連接。然后,你的模型就可以了解到有關(guān)這種連接的特定關(guān)聯(lián)性。
假設(shè)我們更粗略地對緯度和經(jīng)度進行分箱,如下所示:
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
20 < lat <= 30
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]
針對這些粗略分箱創(chuàng)建特征組合會生成具有以下含義的合成特征:
binned_latitude_X_longitude(lat, lon) = [
0 < lat <= 10 AND 0 < lon <= 15
0 < lat <= 10 AND 15 < lon <= 30
10 < lat <= 20 AND 0 < lon <= 15
10 < lat <= 20 AND 15 < lon <= 30
20 < lat <= 30 AND 0 < lon <= 15
20 < lat <= 30 AND 15 < lon <= 30
]
現(xiàn)在,假設(shè)我們的模型需要根據(jù)以下兩個特征來預(yù)測狗主人對狗狗的滿意程度:
行為類型behavior type(吠叫、啜泣、依偎等) 時段time of day
如果我們根據(jù)這兩個特征構(gòu)建以下特征組合:
[behavior type X time of day]
我們最終獲得的預(yù)測能力將遠遠超過任一特征單獨的預(yù)測能力。例如,如果狗狗在下午 5 點主人下班回來時(快樂地)叫喊,可能表示對主人滿意度的正面預(yù)測結(jié)果。如果狗狗在凌晨 3 點主人熟睡時(也許痛苦地)哀叫,可能表示對主人滿意度的強烈負面預(yù)測結(jié)果。
線性學習器可以很好地擴展到大量數(shù)據(jù)。對大規(guī)模數(shù)據(jù)集使用特征組合是學習高度復(fù)雜模型的一種有效策略。神經(jīng)網(wǎng)絡(luò)可提供另一種策略。